RCAP: Robust, Class-Aware, Probabilistic Dynamic Dataset Pruning
Pith reviewed 2026-06-27 10:10 UTC · model grok-4.3
The pith
RCAP prunes training data to 10 percent while improving accuracy over full-data training on class-imbalanced datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
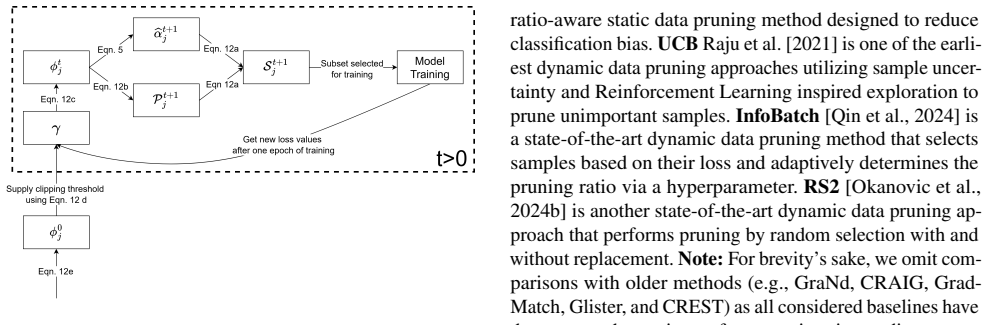
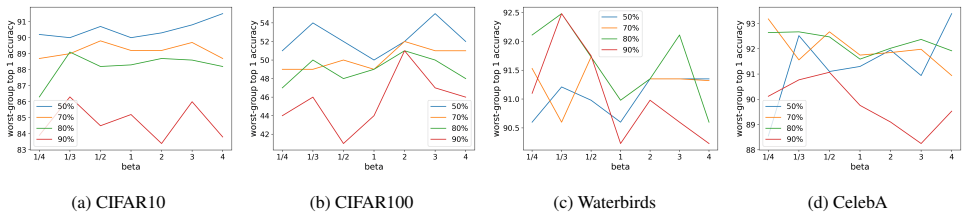
RCAP applies a closed-form solution to estimate the fraction of samples to be included in the training subset for each individual class. This fraction is adaptively adjusted in every epoch using class-wise aggregated loss. Thereafter, it employs an adaptive sampling strategy that prioritizes samples having high loss for populating the class-wise subsets. The method consistently outperforms state-of-the-art dataset pruning methods and achieves superior worst-group accuracy at all pruning rates.
What carries the argument
Closed-form per-class inclusion fraction derived from class-wise aggregated loss, followed by within-class selection of highest-loss samples.
If this is right
- On class-imbalanced datasets, 10 percent data selected by RCAP yields more than 1 percent higher performance than full-data training.
- RCAP delivers an average 8.69 times training speedup across the evaluated settings.
- Worst-group accuracy remains stronger than competing pruning methods at every tested pruning rate on both balanced and imbalanced data.
- The same per-class fraction and high-loss sampling approach works for training from scratch, transfer learning, and fine-tuning.
Where Pith is reading between the lines
- The loss-driven per-class fraction might generalize to regression or structured prediction if loss can be aggregated meaningfully per group.
- By design the method may reduce fairness gaps because it explicitly guards worst-group performance rather than average accuracy alone.
- Adopting RCAP in large-scale training runs could lower energy use while preserving or raising final model quality on long-tail data.
- The stability of the closed-form fraction estimator could be checked by measuring how much the per-class ratios fluctuate across epochs on new imbalance ratios.
Load-bearing premise
Class-wise aggregated loss gives a stable signal for deciding how many samples each class needs and selecting the highest-loss samples inside each class reliably protects worst-group accuracy.
What would settle it
Training an identical model on an imbalanced dataset with the 10 percent subset chosen by RCAP produces lower worst-group accuracy than training on the full dataset.
Figures

read the original abstract
Dynamic data pruning techniques aim to reduce computational cost while minimizing information loss by periodically selecting representative subsets of input data during model training. However, existing methods often struggle to maintain strong worst-group accuracy, particularly at high pruning rates, across balanced and imbalanced datasets. To address this challenge, we propose RCAP, a Robust, Class-Aware, Probabilistic dynamic dataset pruning algorithm for classification tasks. RCAP applies a closed-form solution to estimate the fraction of samples to be included in the training subset for each individual class. This fraction is adaptively adjusted in every epoch using class-wise aggregated loss. Thereafter, it employs an adaptive sampling strategy that prioritizes samples having high loss for populating the class-wise subsets. We evaluate RCAP on six diverse datasets ranging from class-balanced to highly imbalanced using five distinct models across three training paradigms: training from scratch, transfer learning, and fine-tuning. Our approach consistently outperforms state-of-the-art dataset pruning methods, achieving superior worst-group accuracy at all pruning rates. Remarkably, with only $10\%$ data, RCAP delivers $>1\%$ improvement in performance on class-imbalanced datasets compared to full data training while providing an average $8.69\times$ speedup. The code can be accessed at https://github.com/atif-hassan/RCAP-dynamic-dataset-pruning
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RCAP, a dynamic dataset pruning method for classification that computes per-class inclusion fractions via a closed-form expression driven by class-wise aggregated loss (updated each epoch) and then samples the highest-loss examples within each class. It reports superior worst-group accuracy compared to prior pruning methods on six datasets (balanced to highly imbalanced) using five models and three training paradigms, with the headline result that 10% data yields >1% gain over full-data training on imbalanced sets together with an 8.69× average speedup.
Significance. If the reported gains and robustness properties are reproducible, the work would be significant for efficient training of classifiers under class imbalance, where maintaining worst-group performance is critical. The combination of dynamic, class-aware pruning with a closed-form adjustment is a potentially useful engineering contribution.
major comments (3)
- Abstract / Method description: The central adaptive mechanism—a closed-form per-class inclusion fraction based on class-wise aggregated loss followed by intra-class high-loss sampling—is described only at a high level. No equation, derivation, or pseudocode is supplied, preventing assessment of whether the adjustment is robust to label noise or outlier-dominated minority-class losses.
- Evaluation: The manuscript provides no information on how worst-group accuracy is computed, whether train/validation/test splits were fixed prior to pruning, the presence or absence of error bars, or any ablation isolating the contribution of the high-loss sampling rule versus the fraction computation.
- Results: The headline claim that 10% data yields >1% improvement over full-data training rests on the untested assumption that class-wise loss is a stable signal for setting inclusion fractions; without sensitivity analysis or ablation under controlled imbalance and noise levels, the load-bearing empirical result cannot be verified.
minor comments (1)
- Abstract: The phrase 'closed-form solution' is used without reference to the actual expression or the assumptions under which it is derived.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to improve methodological clarity and evaluation transparency. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: Abstract / Method description: The central adaptive mechanism—a closed-form per-class inclusion fraction based on class-wise aggregated loss followed by intra-class high-loss sampling—is described only at a high level. No equation, derivation, or pseudocode is supplied, preventing assessment of whether the adjustment is robust to label noise or outlier-dominated minority-class losses.
Authors: We agree that the current description is high-level. The revised manuscript will include the explicit closed-form equation for the per-class fraction (derived from a class-balanced loss minimization objective), its step-by-step derivation, and Algorithm 1 pseudocode. This addition will enable direct evaluation of robustness properties. revision: yes
-
Referee: Evaluation: The manuscript provides no information on how worst-group accuracy is computed, whether train/validation/test splits were fixed prior to pruning, the presence or absence of error bars, or any ablation isolating the contribution of the high-loss sampling rule versus the fraction computation.
Authors: We will add a new subsection in Experiments that explicitly defines worst-group accuracy (min accuracy over classes), states that splits were fixed before pruning, reports mean ± std over 5 seeds, and presents an ablation separating the fraction computation from high-loss sampling. revision: yes
-
Referee: Results: The headline claim that 10% data yields >1% improvement over full-data training rests on the untested assumption that class-wise loss is a stable signal for setting inclusion fractions; without sensitivity analysis or ablation under controlled imbalance and noise levels, the load-bearing empirical result cannot be verified.
Authors: The multi-dataset results (balanced to highly imbalanced) provide empirical support for the loss-driven adaptation. We nevertheless agree that explicit sensitivity analysis is warranted and will add controlled experiments varying noise levels and imbalance ratios to the revision. revision: yes
Circularity Check
No circularity: RCAP presents an independent algorithmic construction
full rationale
The paper introduces RCAP as a novel dynamic pruning method that computes per-class inclusion fractions via a closed-form expression driven by class-wise aggregated loss, followed by intra-class high-loss sampling. No equations, predictions, or central claims are shown to reduce by construction to fitted parameters defined from the target data, nor do they rely on load-bearing self-citations or imported uniqueness results. The derivation chain consists of an explicit algorithmic proposal whose validity is assessed through external empirical evaluation across datasets and models, rendering the contribution self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Class-wise aggregated loss is a reliable and stable proxy for determining how many samples from that class should be retained
- domain assumption Prioritizing high-loss samples within each class preserves worst-group accuracy better than uniform or random selection
Reference graph
Works this paper leans on
-
[1]
S., Daruwalla, K., and Lipasti, M
Accelerating deep learning with dynamic data pruning , author=. arXiv preprint arXiv:2111.12621 , year=
-
[2]
The Twelfth International Conference on Learning Representations , year =
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning , author =. The Twelfth International Conference on Learning Representations , year =
-
[3]
The Twelfth International Conference on Learning Representations , year=
InfoBatch: Lossless Training Speed Up by Unbiased Dynamic Data Pruning , author=. The Twelfth International Conference on Learning Representations , year=
-
[4]
Advances in neural information processing systems , volume=
Deep learning on a data diet: Finding important examples early in training , author=. Advances in neural information processing systems , volume=
-
[5]
The Eleventh International Conference on Learning Representations,
Shuo Yang and Zeke Xie and Hanyu Peng and Min Xu and Mingming Sun and Ping Li , title =. The Eleventh International Conference on Learning Representations,. 2023 , timestamp =
2023
-
[6]
2024 , doi =
Xin Zhang and Jiawei Du and Yunsong Li and Weiying Xie and Joey Tianyi Zhou , title =. 2024 , doi =
2024
-
[7]
Forty-first International Conference on Machine Learning,
Shuo Yang and Zhe Cao and Sheng Guo and Ruiheng Zhang and Ping Luo and Shengping Zhang and Liqiang Nie , title =. Forty-first International Conference on Machine Learning,. 2024 , timestamp =
2024
-
[8]
Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence , pages =
Chen, Yutian and Welling, Max and Smola, Alex , title =. Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence , pages =. 2010 , isbn =
2010
-
[9]
6th International Conference on Learning Representations,
Ozan Sener and Silvio Savarese , title =. 6th International Conference on Learning Representations,. 2018 , timestamp =
2018
-
[10]
Proceedings of the 37th International Conference on Machine Learning,
Samarth Sinha and Han Zhang and Anirudh Goyal and Yoshua Bengio and Hugo Larochelle and Augustus Odena , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , timestamp =
2020
-
[11]
Computer Vision -
Sharat Agarwal and Himanshu Arora and Saket Anand and Chetan Arora , title =. Computer Vision -. 2020 , doi =
2020
-
[12]
Proceedings of the 26th Annual International Conference on Machine Learning,
Max Welling , title =. Proceedings of the 26th Annual International Conference on Machine Learning,. 2009 , doi =
2009
-
[13]
8th International Conference on Learning Representations,
Cody Coleman and Christopher Yeh and Stephen Mussmann and Baharan Mirzasoleiman and Peter Bailis and Percy Liang and Jure Leskovec and Matei Zaharia , title =. 8th International Conference on Learning Representations,. 2020 , timestamp =
2020
-
[14]
arXiv preprint arXiv:2107.04984 , year=
Svp-cf: Selection via proxy for collaborative filtering data , author=. arXiv preprint arXiv:2107.04984 , year=
-
[15]
2024 , doi =
Muyang He and Shuo Yang and Tiejun Huang and Bo Zhao , title =. 2024 , doi =
2024
-
[16]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing,
Puria Radmard and Yassir Fathullah and Aldo Lipani , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing,. 2021 , doi =
2021
-
[17]
Adversarial Active Learning for Deep Networks: a Margin Based Approach
Melanie Ducoffe and Fr. Adversarial Active Learning for Deep Networks: a Margin Based Approach , journal =. 2018 , eprinttype =. 1802.09841 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Active Learning by Acquiring Contrastive Examples , booktitle =
Katerina Margatina and Giorgos Vernikos and Lo. Active Learning by Acquiring Contrastive Examples , booktitle =. 2021 , doi =
2021
-
[19]
Active Bias: Training More Accurate Neural Networks by Emphasizing High Variance Samples , booktitle =
Haw. Active Bias: Training More Accurate Neural Networks by Emphasizing High Variance Samples , booktitle =. 2017 , timestamp =
2017
-
[20]
Gordon , title =
Mariya Toneva and Alessandro Sordoni and Remi Tachet des Combes and Adam Trischler and Yoshua Bengio and Geoffrey J. Gordon , title =. 7th International Conference on Learning Representations,. 2019 , timestamp =
2019
-
[21]
Bilmes and Jure Leskovec , title =
Baharan Mirzasoleiman and Jeff A. Bilmes and Jure Leskovec , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , timestamp =
2020
-
[22]
Iyer , title =
KrishnaTeja Killamsetty and Durga Sivasubramanian and Ganesh Ramakrishnan and Abir De and Rishabh K. Iyer , title =. Proceedings of the 38th International Conference on Machine Learning,. 2021 , timestamp =
2021
-
[23]
Iyer , title =
KrishnaTeja Killamsetty and Xujiang Zhao and Feng Chen and Rishabh K. Iyer , title =. Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual , pages =. 2021 , timestamp =
2021
-
[24]
Iyer , title =
KrishnaTeja Killamsetty and Durga Sivasubramanian and Ganesh Ramakrishnan and Rishabh K. Iyer , title =. Thirty-Fifth. 2021 , doi =
2021
-
[25]
Iyer and Ninad Khargoankar and Jeff A
Rishabh K. Iyer and Ninad Khargoankar and Jeff A. Bilmes and Himanshu Asanani , title =. Algorithmic Learning Theory, 16-19 March 2021, Virtual Conference, Worldwide , series =. 2021 , timestamp =
2021
-
[26]
Vishal Kaushal and Suraj Kothawade and Ganesh Ramakrishnan and Jeff A. Bilmes and Rishabh K. Iyer , title =. CoRR , volume =. 2021 , eprinttype =. 2103.00128 , timestamp =
-
[27]
Nikolakakis and Amin Karbasi and Dionysios S
Patrik Okanovic and Roger Waleffe and Vasilis Mageirakos and Konstantinos E. Nikolakakis and Amin Karbasi and Dionysios S. Kalogerias and Nezihe Merve G. Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning , booktitle =. 2024 , timestamp =
2024
-
[28]
Fadhel Ayed and Soufiane Hayou , title =. Trans. Mach. Learn. Res. , volume =. 2023 , timestamp =
2023
-
[29]
Artem Vysogorets and Kartik Ahuja and Julia Kempe , title =. CoRR , volume =. 2024 , doi =. 2404.05579 , timestamp =
-
[30]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[31]
Ziwei Liu and Ping Luo and Xiaogang Wang and Xiaoou Tang , title =. 2015. 2015 , doi =
2015
-
[32]
Shiori Sagawa and Pang Wei Koh and Tatsunori B. Hashimoto and Percy Liang , title =. CoRR , volume =. 2019 , eprinttype =. 1911.08731 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[33]
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. 2016. 2016 , doi =
2016
-
[34]
Samuel G. M. TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation , booktitle =. 2021 , doi =
2021
-
[35]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,. 2021 , timestamp =
2021
-
[36]
International Conference on Machine Learning,
Alec Radford and Jong Wook Kim and Tao Xu and Greg Brockman and Christine McLeavey and Ilya Sutskever , title =. International Conference on Machine Learning,. 2023 , timestamp =
2023
-
[37]
Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
Alexei Baevski and Yuhao Zhou and Abdelrahman Mohamed and Michael Auli , title =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[38]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , booktitle =. 2020 , timestamp =
2020
-
[39]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[40]
OpenAI , title =. CoRR , volume =. 2023 , doi =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Prioritized Training on Points that are Learnable, Worth Learning, and not yet Learnt , booktitle =
S. Prioritized Training on Points that are Learnable, Worth Learning, and not yet Learnt , booktitle =. 2022 , timestamp =
2022
-
[42]
Large Batch Training of Convolutional Networks
Large batch training of convolutional networks , author=. arXiv preprint arXiv:1708.03888 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Reddi and Jonathan Hseu and Sanjiv Kumar and Srinadh Bhojanapalli and Xiaodan Song and James Demmel and Kurt Keutzer and Cho
Yang You and Jing Li and Sashank J. Reddi and Jonathan Hseu and Sanjiv Kumar and Srinadh Bhojanapalli and Xiaodan Song and James Demmel and Kurt Keutzer and Cho. Large Batch Optimization for Deep Learning: Training. 8th International Conference on Learning Representations,. 2020 , timestamp =
2020
-
[44]
Forty-first International Conference on Machine Learning,
Xiaobo Xia and Jiale Liu and Shaokun Zhang and Qingyun Wu and Hongxin Wei and Tongliang Liu , title =. Forty-first International Conference on Machine Learning,. 2024 , timestamp =
2024
-
[45]
2023 , doi =
Bo Zhao and Hakan Bilen , title =. 2023 , doi =
2023
-
[46]
Efros and Jun
George Cazenavette and Tongzhou Wang and Antonio Torralba and Alexei A. Efros and Jun. Dataset Distillation by Matching Training Trajectories , booktitle =. 2022 , doi =
2022
-
[47]
Core-set Sampling for Efficient Neural Architecture Search , journal =
Jae. Core-set Sampling for Efficient Neural Architecture Search , journal =. 2021 , eprinttype =. 2107.06869 , timestamp =
-
[48]
2019 , volume =
Tan, Mingxing and Le, Quoc , booktitle =. 2019 , volume =
2019
-
[49]
The Eleventh International Conference on Learning Representations,
Haizhong Zheng and Rui Liu and Fan Lai and Atul Prakash , title =. The Eleventh International Conference on Learning Representations,. 2023 , timestamp =
2023
-
[50]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[51]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Van Horn, Grant and Mac Aodha, Oisin and Song, Yang and Cui, Yin and Sun, Chen and Shepard, Alex and Adam, Hartwig and Perona, Pietro and Belongie, Serge , title =. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[52]
Le , title =
Mingxing Tan and Quoc V. Le , title =. Proceedings of the 38th International Conference on Machine Learning,. 2021 , timestamp =
2021
-
[53]
2022 , doi =
Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo , title =. 2022 , doi =
2022
-
[54]
Bovik and Yinxiao Li , title =
Zhengzhong Tu and Hossein Talebi and Han Zhang and Feng Yang and Peyman Milanfar and Alan C. Bovik and Yinxiao Li , title =. Computer Vision -. 2022 , doi =
2022
-
[55]
Girshick and Kaiming He and Piotr Doll
Ilija Radosavovic and Raj Prateek Kosaraju and Ross B. Girshick and Kaiming He and Piotr Doll. Designing Network Design Spaces , booktitle =. 2020 , doi =
2020
-
[56]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Rethinking vision transformers for mobilenet size and speed , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[57]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[58]
Proceedings of the 30th International Conference on Machine Learning , pages =
On the importance of initialization and momentum in deep learning , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , volume =
2013
-
[59]
7th International Conference on Learning Representations,
Sanjeev Arora and Nadav Cohen and Noah Golowich and Wei Hu , title =. 7th International Conference on Learning Representations,. 2019 , timestamp =
2019
-
[60]
Cambridge UP , year=
Convex optimization , author=. Cambridge UP , year=
-
[61]
International Conference on Learning Representations , year=
SGDR: Stochastic Gradient Descent with Warm Restarts , author=. International Conference on Learning Representations , year=
-
[62]
Online Batch Selection for Faster Training of Neural Networks
Ilya Loshchilov and Frank Hutter , title =. CoRR , volume =. 2015 , url =. 1511.06343 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[63]
Prioritized Experience Replay , booktitle =
Tom Schaul and John Quan and Ioannis Antonoglou and David Silver , editor =. Prioritized Experience Replay , booktitle =. 2016 , url =
2016
-
[64]
Angela H. Jiang and Daniel L. Accelerating Deep Learning by Focusing on the Biggest Losers , journal =. 2019 , url =. 1910.00762 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.