Re-evaluating Confidence Remasking in Masked Diffusion Language Models
Pith reviewed 2026-06-27 10:23 UTC · model grok-4.3
The pith
Post-hoc confidence remasking brings little-to-no benefit over unmasking alone in masked diffusion language models under standard short-block decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
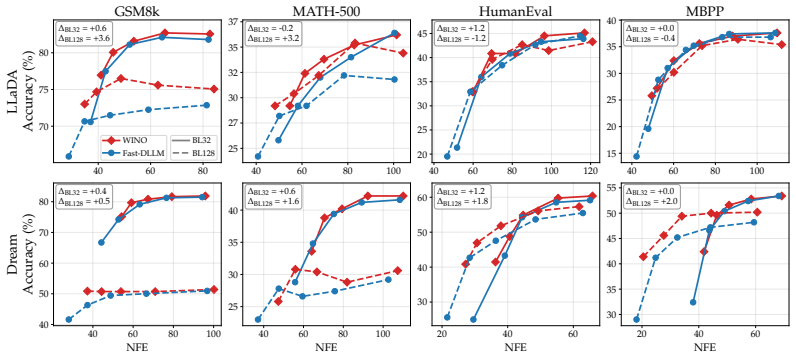
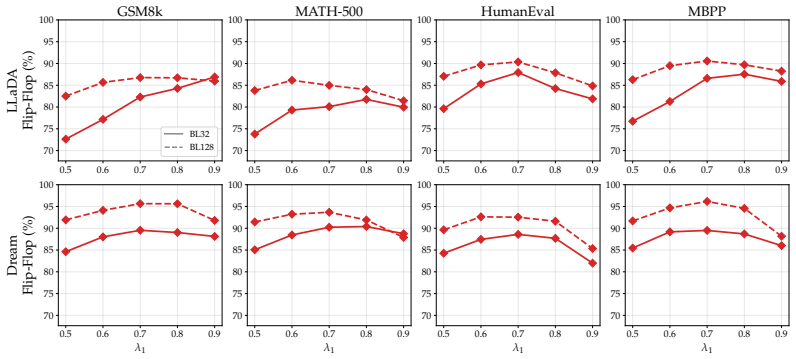
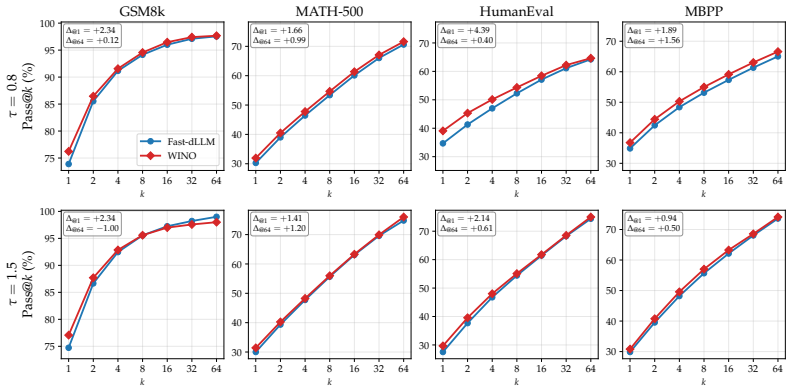
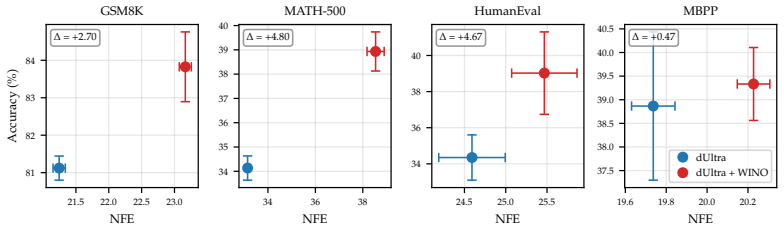
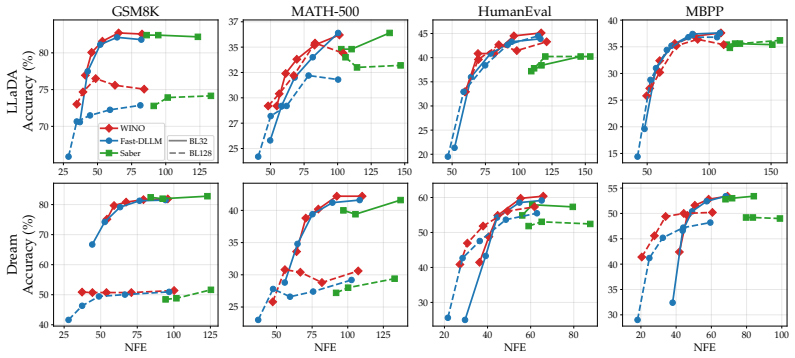
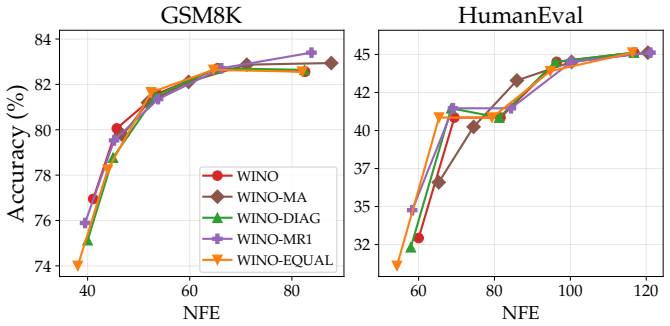
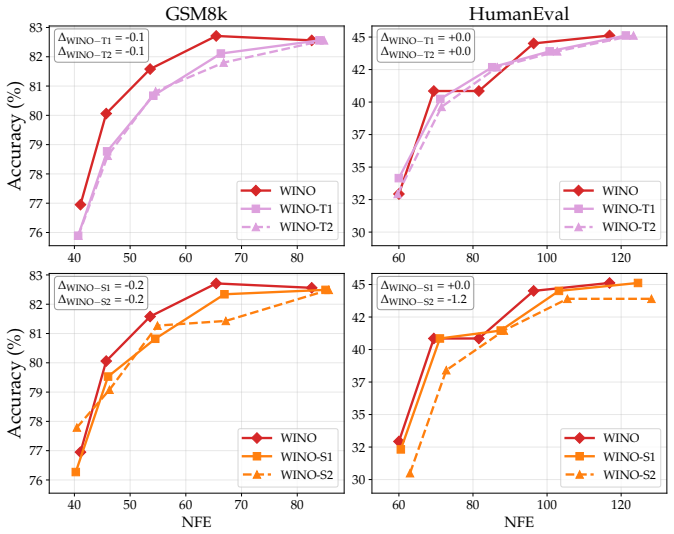
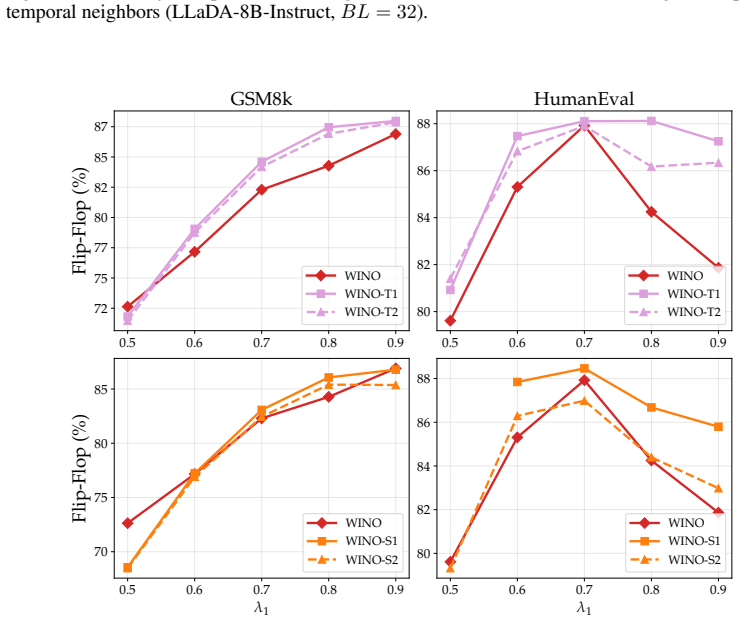
The paper establishes that under standard decoding settings with shorter block lengths, the representative post-hoc remasking method WINO brings little-to-no benefit over confidence-based unmasking alone. When the evaluation is extended to non-greedy decoding, confidence-based remasking mitigates some errors caused by increased stochasticity but also exacerbates the diversity collapse already observed with unmasking. Overall the benefits of post-hoc confidence-based remasking are highly setting-dependent.
What carries the argument
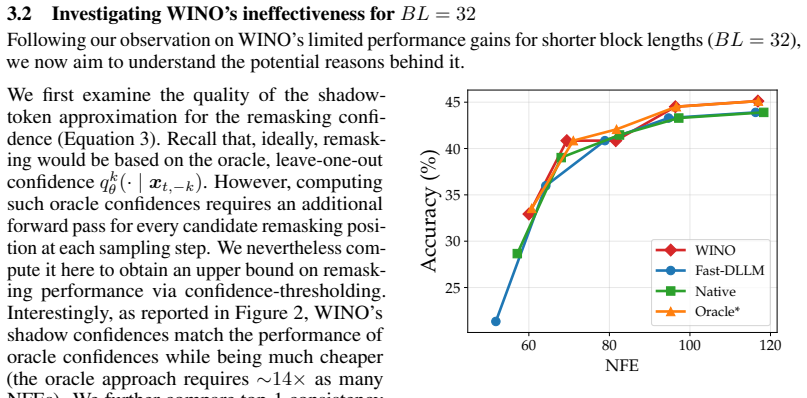
The post-hoc confidence remasking procedure in WINO, which selectively remasks low-confidence tokens after initial unmasking to enable correction within the masked diffusion process.
If this is right
- Benefits of post-hoc confidence-based remasking are highly setting-dependent.
- Standard short-block evaluations may underestimate or overestimate the value of remasking methods.
- Non-greedy decoding creates a trade-off in which remasking reduces some errors while worsening output diversity.
- More comprehensive evaluation frameworks are required that test multiple block lengths and sampling strategies.
Where Pith is reading between the lines
- If practical deployments commonly use longer blocks, the reported lack of benefit may not hold and further targeted experiments would be warranted.
- The observed diversity collapse points to a need for remasking variants that preserve variety rather than only correcting low-confidence tokens.
- Replication studies of this kind suggest that future self-correction techniques for non-autoregressive models should be validated across a broader range of inference regimes from the outset.
Load-bearing premise
The shorter block lengths and standard decoding regimes used in the re-evaluation are the ones that matter for practical deployment of masked diffusion language models.
What would settle it
An experiment that applies WINO remasking at longer block lengths or under different sampling schedules and records consistent gains in quality or accuracy over unmasking alone.
Figures

read the original abstract
Masked diffusion language models (dLLMs) have recently emerged as a competitive alternative to autoregressive language models, with the promise of faster inference via parallel token generation. A notable limitation of the masked formulation, however, is that once a token has been unmasked it can no longer be revised, leaving dLLMs vulnerable to early sampling mistakes. To address this, a growing body of work has sought to extend masked dLLMs with self-correcting (remasking) capabilities. One appealing subset of these methods does so in a training-free, post-hoc manner based on token confidences, with encouraging early reported results. In this work, we revisit the empirical evaluation of a representative post-hoc remasking method, WINO [Hong et al., 2026], and find that under standard decoding settings (shorter block lengths) it brings little-to-no benefit over confidence-based unmasking alone [Wu et al., 2025]. Extending the evaluation to non-greedy decoding, we find that while confidence-based remasking can mitigate errors introduced by increased stochasticity to some extent, it also exacerbates the diversity collapse previously reported for confidence-based unmasking. Overall, our results show that the benefits of post-hoc confidence-based remasking are highly setting-dependent, underscoring the need for a more comprehensive evaluation framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript re-evaluates the training-free post-hoc confidence remasking method WINO for masked diffusion language models. It reports that, under standard shorter-block decoding regimes, WINO yields little-to-no improvement over plain confidence-based unmasking (Wu et al., 2025). In non-greedy regimes, remasking partially mitigates stochastic errors but worsens the diversity collapse previously observed with confidence-based unmasking; overall benefits are described as highly setting-dependent.
Significance. If the empirical comparisons hold, the work usefully tempers optimism about post-hoc remasking and underscores the sensitivity of dLLM performance claims to block length and sampling choices. The direct, controlled experimental design (no fitted parameters or circular derivations) is a strength.
major comments (2)
- [Abstract / Experiments] The abstract states that benefits are 'highly setting-dependent' and that shorter blocks are 'standard,' yet the manuscript must specify the exact block lengths tested, the rationale for calling them standard, and results for longer blocks that may be used in practice; without this, the scope of the 'little-to-no benefit' claim cannot be assessed.
- [Results] The claim of 'little-to-no benefit' and the diversity-collapse exacerbation require quantitative support (effect sizes, variance across runs, statistical tests) and explicit confirmation that baselines from Wu et al. (2025) and Hong et al. (2026) were replicated exactly, including any hyper-parameters.
minor comments (2)
- [Experiments] Clarify whether multiple-testing correction was applied across the reported decoding regimes and metrics.
- [Results] Add a table or figure that directly juxtaposes WINO versus the confidence-unmasking baseline on the same axes for each regime.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / Experiments] The abstract states that benefits are 'highly setting-dependent' and that shorter blocks are 'standard,' yet the manuscript must specify the exact block lengths tested, the rationale for calling them standard, and results for longer blocks that may be used in practice; without this, the scope of the 'little-to-no benefit' claim cannot be assessed.
Authors: We agree that the abstract and experiments section would benefit from greater precision on this point. The revised manuscript will explicitly list the block lengths evaluated in our experiments and provide the rationale for designating them as standard, grounded in the block sizes commonly reported in the dLLM literature for balancing parallelism and generation quality. Regarding results on longer blocks, our re-evaluation was scoped to the shorter-block regimes that constitute the standard setting in which post-hoc remasking methods have been previously claimed to help; we will add an explicit discussion noting that performance under longer blocks remains an open question and may differ, while observing that new experiments on longer blocks lie outside the scope of the current controlled re-evaluation. revision: partial
-
Referee: [Results] The claim of 'little-to-no benefit' and the diversity-collapse exacerbation require quantitative support (effect sizes, variance across runs, statistical tests) and explicit confirmation that baselines from Wu et al. (2025) and Hong et al. (2026) were replicated exactly, including any hyper-parameters.
Authors: We will strengthen the results section by adding quantitative support for the claims, including effect sizes, run-to-run variance, and statistical tests where appropriate. We also confirm that the baselines were replicated exactly as described in the cited works, with identical hyper-parameters; the revised manuscript will include an explicit statement to this effect together with any additional implementation details needed for reproducibility. revision: yes
Circularity Check
No significant circularity detected
full rationale
This paper is a purely empirical re-evaluation that compares post-hoc confidence remasking (WINO) against baseline confidence-based unmasking via direct experiments on block lengths and decoding regimes. No derivations, first-principles predictions, fitted parameters renamed as outputs, or load-bearing self-citations appear in the text. All claims reduce to reported experimental measurements against external prior work, with the paper itself qualifying results by reference to specific settings; the analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Sub- ham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregres- sive and diffusion language models.arXiv preprint arXiv:2503.09573,
-
[2]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In M. Ranzato, A. Beygelz- imer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neu- ral Information Processing Systems, volume 34, pages 17981–17993. Curran Associates, Inc., 2021a. UR...
Pith/arXiv arXiv 2021
-
[3]
URL https://arxiv.org/abs/2602.21472. Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b. arXiv preprint arXiv:2512.15745,
-
[4]
Tiwei Bie, Maosong Cao, Xiang Cao, Bingsen Chen, Fuyuan Chen, Kun Chen, Lun Du, Daozhuo Feng, Haibo Feng, Mingliang Gong, et al. Llada2. 1: Speeding up text diffusion via token editing. arXiv preprint arXiv:2602.08676,
-
[5]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman
URL https://proceedings.neurips.cc/paper_files/paper/2022/file/ b5b528767aa35f5b1a60fe0aaeca0563-Paper-Conference.pdf. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11315–11325,
2022
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
-
[7]
Dmax: Aggressive parallel decoding for dllms.arXiv preprint arXiv:2604.08302,
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. Dmax: Aggressive parallel decoding for dllms.arXiv preprint arXiv:2604.08302,
-
[8]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[9]
Yihong Dong, Zhaoyu Ma, Xue Jiang, Zhiyuan Fan, Jiaru Qian, Yongmin Li, Jianha Xiao, Zhi Jin, Rongyu Cao, Binhua Li, et al. Saber: An efficient sampling with adaptive acceleration and backtracking enhanced remasking for diffusion language model.arXiv preprint arXiv:2510.18165,
-
[10]
Zemin Huang, Yuhang Wang, Zhiyang Chen, and Guo-Jun Qi
URL https://proceedings.neurips.cc/paper_files/paper/2021/file/ 67d96d458abdef21792e6d8e590244e7-Paper.pdf. Zemin Huang, Yuhang Wang, Zhiyang Chen, and Guo-Jun Qi. Don’t settle too early: Self-reflective remasking for diffusion language models.arXiv preprint arXiv:2509.23653,
arXiv 2021
-
[11]
Learning unmasking policies for diffusion language models.arXiv preprint arXiv:2512.09106,
Metod Jazbec, Theo X Olausson, Louis Béthune, Pierre Ablin, Michael Kirchhof, João Monteiro, Victor Turrisi, Jason Ramapuram, and Marco Cuturi. Learning unmasking policies for diffusion language models.arXiv preprint arXiv:2512.09106,
-
[12]
Fine-tuning masked diffusion for provable self-correction.arXiv preprint arXiv:2510.01384, 2025a
Jaeyeon Kim, Seunggeun Kim, Taekyun Lee, David Z Pan, Hyeji Kim, Sham Kakade, and Sitan Chen. Fine-tuning masked diffusion for provable self-correction.arXiv preprint arXiv:2510.01384, 2025a. Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions.arX...
-
[13]
Zanlin Ni, Shenzhi Wang, Yang Yue, Tianyu Yu, Weilin Zhao, Yeguo Hua, Tianyi Chen, Jun Song, Cheng Yu, Bo Zheng, et al. The flexibility trap: Why arbitrary order limits reasoning potential in diffusion language models.arXiv preprint arXiv:2601.15165,
-
[14]
Large language diffusion models.arXiv preprint arXiv:2502.09992,
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
-
[15]
11 Theo X Olausson, Metod Jazbec, Xi Wang, Armando Solar-Lezama, Christian A Naesseth, Stephan Mandt, and Eric Nalisnick. A tale of two temperatures: Simple, efficient, and diverse sampling from diffusion language models.arXiv preprint arXiv:2604.09921,
-
[16]
Your absorbing discrete diffusion secretly models the conditional dis- tributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional dis- tributions of clean data. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, edi- tors,International Conference on Learning Representations, volume 2025, pages 64972– 65009,
2025
-
[17]
Subham Sekhar Sahoo, Marianne Arriola, Aaron Gokaslan, Edgar Mariano Marroquin, Alexander M Rush, Yair Schiff, Justin T Chiu, and V olodymyr Kuleshov
URL https://proceedings.iclr.cc/paper_files/paper/2025/file/ a365e37c18fb91af547a2f0012a89e98-Paper-Conference.pdf. Subham Sekhar Sahoo, Marianne Arriola, Aaron Gokaslan, Edgar Mariano Marroquin, Alexander M Rush, Yair Schiff, Justin T Chiu, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InICML 2024 Workshop on Efficient a...
2025
-
[18]
URLhttps://openreview.net/forum?id=DdU9gP4EXW. Yair Schiff, Omer Belhasin, Roy Uziel, Guanghan Wang, Marianne Arriola, Gilad Turok, Michael Elad, and V olodymyr Kuleshov. Learn from your mistakes: Self-correcting masked diffusion models.arXiv preprint arXiv:2602.11590,
-
[19]
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838,
-
[20]
Generalized interpolating discrete diffusion.arXiv preprint arXiv:2503.04482,
Dimitri V on Rütte, Janis Fluri, Yuhui Ding, Antonio Orvieto, Bernhard Schölkopf, and Thomas Hofmann. Generalized interpolating discrete diffusion.arXiv preprint arXiv:2503.04482,
-
[21]
ml/posts/why-diffusion-language-models-are-the-future/
URL https://dimitri. ml/posts/why-diffusion-language-models-are-the-future/. Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307,
-
[22]
Generalized discrete diffusion with self-correction.arXiv preprint arXiv:2603.02230,
Linxuan Wang, Ziyi Wang, Yikun Bai, Wei Deng, Guang Lin, and Qifan Song. Generalized discrete diffusion with self-correction.arXiv preprint arXiv:2603.02230,
-
[23]
URLhttps://arxiv.org/abs/2505.22618. Yanzheng Xiang, Lan Wei, Yizhen Yao, Qinglin Zhu, Hanqi Yan, Chen Jin, Philip Alexander Teare, Dandan Zhang, Lin Gui, Amrutha Saseendran, et al. Stop the flip-flop: Context-preserving verification for fast revocable diffusion decoding.arXiv preprint arXiv:2602.06161,
-
[24]
Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
-
[25]
Introspective diffusion language models.arXiv preprint arXiv:2604.11035,
Yifan Yu, Yuqing Jian, Junxiong Wang, Zhongzhu Zhou, Donglin Zhuang, Xinyu Fang, Sri Yana- mandra, Xiaoxia Wu, Qingyang Wu, Shuaiwen Leon Song, et al. Introspective diffusion language models.arXiv preprint arXiv:2604.11035,
-
[26]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216,
-
[27]
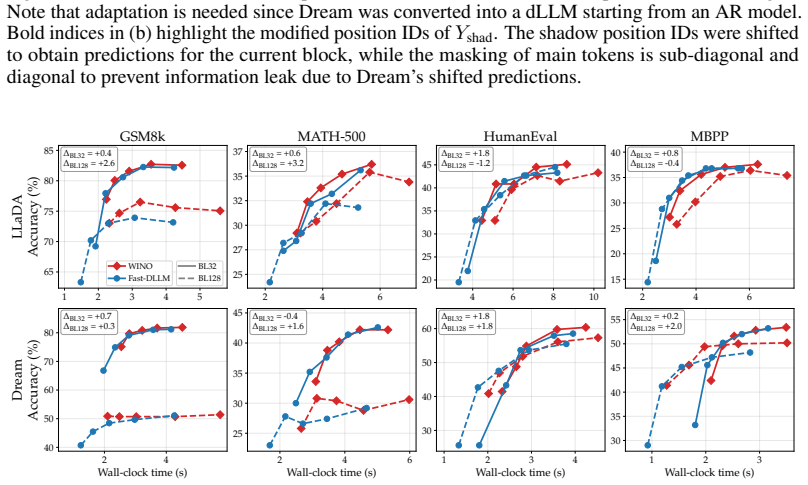
0 1 2 3 4 5 6 7 8 2 3 4 Y left Y curr Y right Y shad Pos ID 0 1 2 3 4 5 6 7 8 2 3 4 (b) Adaption for Dream-7B model [Ye et al., 2025]
12 A Additional Figures 0 1 2 3 4 5 6 7 8 3 4 5 Y left Y curr Y right Y shad Pos ID 0 1 2 3 4 5 6 7 8 3 4 5 (a) WINO attention mask and position IDs for LLaDA-8B [Nie et al., 2025]. 0 1 2 3 4 5 6 7 8 2 3 4 Y left Y curr Y right Y shad Pos ID 0 1 2 3 4 5 6 7 8 2 3 4 (b) Adaption for Dream-7B model [Ye et al., 2025]. Figure 6: WINO attention masks and posit...
2025
-
[28]
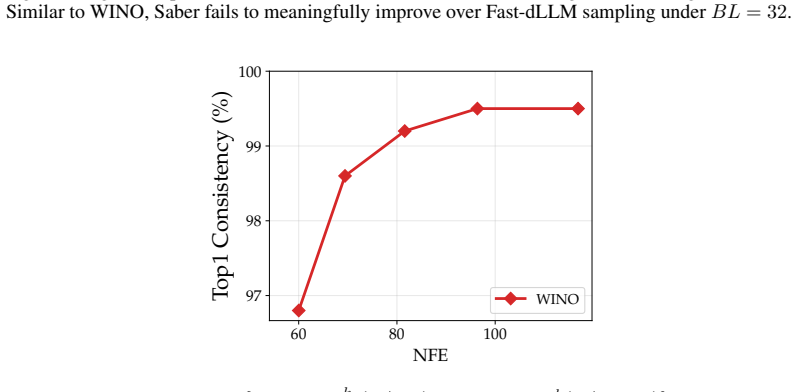
Notably, the consistency rate is very high ( >97% ) across all five λ1 thresholds
60 80 100 NFE 97 98 99 100Top1 Consistency (%) WINO Figure 9: Consistency rate ( {arg maxv qks θ (v| ˜xt) = arg max v qk θ (v|x t,−k)}) of the highest confidence tokens between the shadow and oracle predicted tokenswithoutremasking ( λ2 = 0 , LLaDA-8B-Instruct, HumanEval, BL= 32 ). Notably, the consistency rate is very high ( >97% ) across all five λ1 thr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.