DynamicPTQ: Mitigating Activation Quantization Collapse via Residual-Stream Dynamics
Pith reviewed 2026-06-27 10:34 UTC · model grok-4.3
The pith
DynamicPTQ raises activation precision to 8 bits only in layers where residual-stream phase changes dominate 4-bit scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
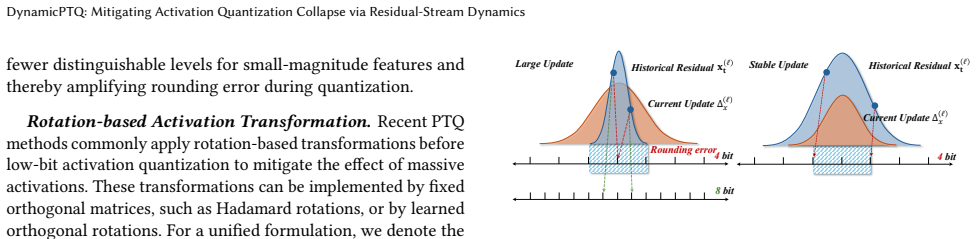
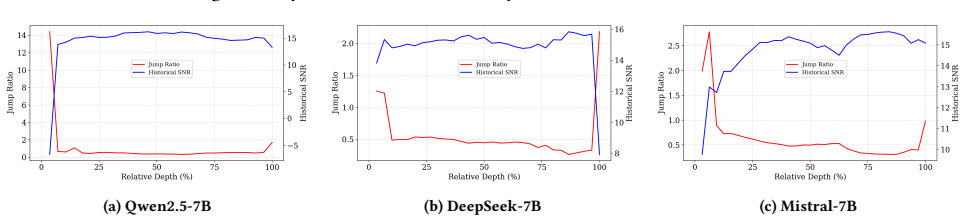
Massive activations emerge and disappear in a phase-wise pattern across network depth, triggering large residual changes. These changes cause newly injected layer-wise updates to dominate the 4-bit quantization scale and weaken historical residual information. Static transformation-based smoothing cannot fully resolve the resulting dynamic instability. DynamicPTQ therefore identifies quantization-sensitive layers from residual-stream dynamics and assigns 8-bit activation precision only to those layers, keeping weights, KV caches, and remaining activations at 4 bits.
What carries the argument
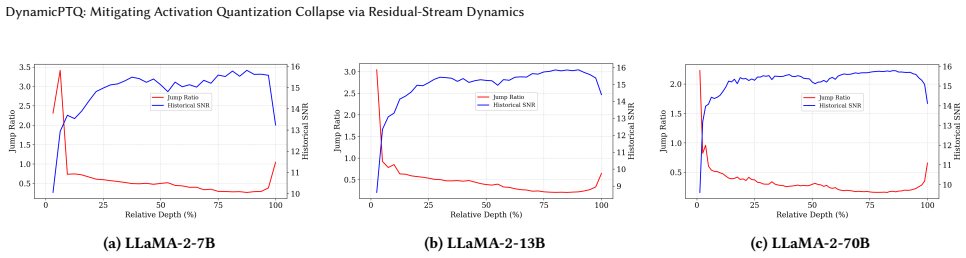
Jump Ratio and Historical Feature SNR, which measure the sudden appearance of massive activations and the dominance of new updates over retained historical features in the residual stream.
If this is right
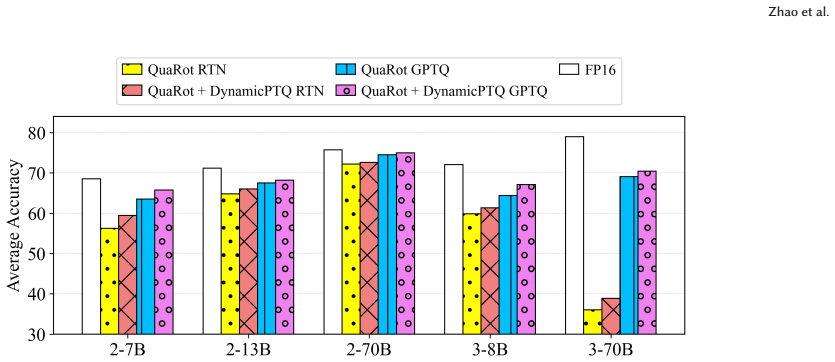
- Integration with QuaRot, SpinQuant, or FlatQuant yields consistent perplexity reductions under W4A4KV4.
- Zero-shot QA accuracy rises on both LLaMA-2 and LLaMA-3 models.
- Throughput improves by a factor of 1.05 to 1.07 with only modest added memory.
- The policy supplies a direct route to robust low-bit inference without full retraining.
Where Pith is reading between the lines
- The same residual metrics could be used to decide bit widths during training rather than only after training.
- Hardware schedulers might switch activation precision on the fly by tracking Jump Ratio across successive batches.
- Similar phase detection might apply to other dynamic-range problems such as KV-cache eviction or activation sparsity.
Load-bearing premise
Phase-wise residual-stream changes, rather than static per-layer statistics, are the main driver of activation quantization collapse and can be corrected by raising precision only in the affected layers.
What would settle it
Measuring whether layers flagged by high Jump Ratio or low Historical Feature SNR produce the largest activation quantization error, and whether restricting 8-bit precision to exactly those layers recovers the reported perplexity gains while uniform 4-bit or uniform 8-bit baselines do not.
Figures

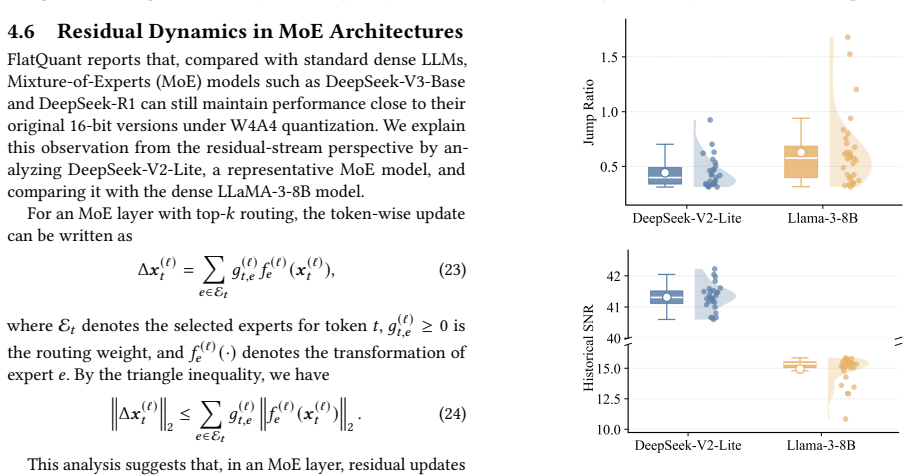
read the original abstract
Post-training quantization (PTQ) is essential for efficient large language model inference, but reliably quantizing activations remains challenging when weights, activations, and KV caches are all quantized to 4-bit precision. A key difficulty lies in massive activations, whose extreme values dominate the activation range and amplify quantization errors. State-of-the-art methods mainly mitigate massive activations through transformation-based smoothing, such as orthogonal rotations and affine scaling, but overlook the cross-layer dynamics of the residual stream. In this paper, we show that massive activations emerge and disappear in a phase-wise pattern across network depth, triggering large residual changes. These changes cause newly injected layer-wise updates to dominate the 4-bit quantization scale and weaken historical residual information. To characterize this behavior, we introduce Jump Ratio and Historical Feature SNR. This suggests that static transformation-based smoothing cannot fully resolve dynamic quantization instability caused by cross-layer residual changes. Based on this analysis, we propose DynamicPTQ, a Dynamic Post-Training Quantization policy for phase-aware mixed-precision activation quantization. DynamicPTQ identifies quantization-sensitive layers from residual-stream dynamics and assigns 8-bit activation precision only to these layers, while keeping weights, KV caches, and other activations in 4-bit precision. It can be directly integrated with strong PTQ baselines such as QuaRot, SpinQuant, and FlatQuant. Experiments on LLaMA-2 and LLaMA-3 show that DynamicPTQ consistently improves perplexity and zero-shot QA performance under W4A4KV4 quantization, while achieving 1.05 to 1.07 times throughput improvement with modest memory overhead. These results demonstrate a practical path toward robust low-bit LLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that massive activations emerge and disappear in a phase-wise pattern across LLM layers, causing dynamic residual-stream changes that lead to quantization instability under W4A4KV4 settings. Static smoothing methods (e.g., rotations and scaling in QuaRot/SpinQuant/FlatQuant) are insufficient because they overlook these cross-layer dynamics. The authors introduce two new metrics—Jump Ratio and Historical Feature SNR—to characterize the behavior, and propose DynamicPTQ, a mixed-precision policy that identifies sensitive layers via these metrics and elevates only their activations to 8 bits while keeping weights, KV caches, and other activations at 4 bits. Experiments on LLaMA-2 and LLaMA-3 report consistent gains in perplexity and zero-shot QA when DynamicPTQ is integrated with the baselines, plus 1.05–1.07× throughput with modest memory cost.
Significance. If the central claim holds after proper controls, the work offers a targeted, low-overhead way to mitigate activation quantization collapse by exploiting residual-stream phase dynamics rather than uniform or purely magnitude-based fixes. The explicit compatibility with multiple strong PTQ baselines and the reported throughput numbers are concrete strengths that could influence practical low-bit inference pipelines.
major comments (2)
- [Experiments] Experiments section: the manuscript reports perplexity and QA gains from DynamicPTQ but contains no ablation that assigns the extra 8-bit activations to randomly chosen layers or to layers selected solely by per-layer activation magnitude (the statistic already used by smoothing baselines). Without this control it is impossible to isolate whether the residual-stream metrics (Jump Ratio, Historical Feature SNR) add predictive power beyond simply giving extra bits to some layers. This directly bears on the claim that phase-wise dynamics are the primary driver missed by static methods.
- [Method] Method / metric definitions: Jump Ratio and Historical Feature SNR are introduced to capture phase-wise residual changes, yet the text provides neither explicit equations for their computation nor quantitative evidence (e.g., correlation plots or regression against observed quantization error) that they predict instability better than existing activation-range statistics. This absence undermines verification that the metrics are load-bearing for the proposed policy.
minor comments (1)
- [Abstract] Abstract and experimental description: the claimed 1.05–1.07× throughput improvement is stated without specifying the hardware platform, batch size, or exact baseline configuration, which is needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental validation and metric clarity. We address each major comment below and will revise the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports perplexity and QA gains from DynamicPTQ but contains no ablation that assigns the extra 8-bit activations to randomly chosen layers or to layers selected solely by per-layer activation magnitude (the statistic already used by smoothing baselines). Without this control it is impossible to isolate whether the residual-stream metrics (Jump Ratio, Historical Feature SNR) add predictive power beyond simply giving extra bits to some layers. This directly bears on the claim that phase-wise dynamics are the primary driver missed by static methods.
Authors: We agree that the requested ablations are necessary to isolate the contribution of the residual-stream metrics. In the revision we will add experiments that compare DynamicPTQ's metric-driven layer selection against (i) random layer selection and (ii) selection based solely on per-layer activation magnitude (the statistic already employed by the smoothing baselines). These controls will be reported on the same LLaMA-2 and LLaMA-3 models and W4A4KV4 setting, allowing direct assessment of whether the proposed metrics provide predictive value beyond magnitude-based or random allocation. revision: yes
-
Referee: [Method] Method / metric definitions: Jump Ratio and Historical Feature SNR are introduced to capture phase-wise residual changes, yet the text provides neither explicit equations for their computation nor quantitative evidence (e.g., correlation plots or regression against observed quantization error) that they predict instability better than existing activation-range statistics. This absence undermines verification that the metrics are load-bearing for the proposed policy.
Authors: We will add the explicit mathematical definitions of both Jump Ratio and Historical Feature SNR to the revised manuscript. We will also include quantitative supporting evidence in the form of correlation plots and regression analyses that relate these metrics to observed per-layer quantization error, demonstrating their relationship to instability beyond standard activation-range statistics used by prior smoothing methods. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's chain consists of empirical observation of residual-stream patterns, definition of Jump Ratio and Historical Feature SNR from those observations, a heuristic policy selecting layers for 8-bit activations, and experimental validation on LLaMA models when combined with external baselines (QuaRot, SpinQuant, FlatQuant). No equation or claim reduces by construction to a fitted parameter, self-referential definition, or self-citation; the metrics and policy are presented as derived from data rather than presupposing the performance outcome. This is the normal self-contained case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Massive activations emerge and disappear in a phase-wise pattern across network depth and trigger large residual changes that dominate 4-bit quantization scales.
invented entities (2)
-
Jump Ratio
no independent evidence
-
Historical Feature SNR
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pash- mina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hens- man. 2024. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems37 (2024), 100213–100240
2024
-
[3]
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al . 2020. Piqa: Reasoning about physical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 7432–7439
2020
-
[4]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems35 (2022), 30318–30332
2022
-
[7]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. 2024. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems37 (2024), 1270–1303
2024
-
[12]
Naman Jain, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Livecodebench: Holistic and contamination free evaluation of large language models for code. InInternational Conference on Learning Representations, Vol. 2025. 58791– 58831
2025
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timo- thée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems6 (2024), 87–100
2024
- [16]
-
[17]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. 2025. Spinquant: Llm quantization with learned rotations. In International Conference on Learning Representations, Vol. 2025. 92009–92032
2025
-
[19]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. 2020. Up or down? adaptive rounding for post-training quantization. InInternational conference on machine learning. PMLR, 7197– 7206
2020
-
[21]
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. 2016. The LAMBADA dataset: Word prediction requiring a broad discourse context. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers). 1525–1534
2016
- [22]
-
[23]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[24]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman
-
[25]
Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi
-
[27]
Winogrande: An adversarial winograd schema challenge at scale. Commun. ACM64, 9 (2021), 99–106
2021
-
[28]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Gao Peng, Yu Qiao, and Ping Luo. 2024. Omniquant: Omnidirectionally calibrated quantization for large language models. In International Conference on Learning Representations, Vol. 2024. 45472–45496
2024
-
[29]
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. 2024. Massive activations in large language models.arXiv preprint arXiv:2402.17762(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [30]
-
[31]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning. PMLR, 38087–38099
2023
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al . 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. 2022. Zeroquant: Efficient and affordable post-training quantization for large-scale transformers.Advances in neural information processing systems35 (2022), 27168–27183
2022
-
[35]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi
-
[36]
InProceedings of the 57th annual meeting of the association for computational linguistics
Hellaswag: Can a machine really finish your sentence?. InProceedings of the 57th annual meeting of the association for computational linguistics. 4791–4800
-
[37]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-bit quantization for efficient and accurate llm serving.Proceedings of Machine Learning and Systems6 (2024), 196–209
2024
-
[38]
Yue Zheng, Yuhao Chen, Bin Qian, Xiufang Shi, Yuanchao Shu, and Jiming Chen. 2025. A Review on Edge Large Language Models: Design, Execution, and Applications. arXiv:2410.11845 [cs.DC] https://arxiv.org/abs/2410.11845 Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.