Artifact-Conditioned Interval Diagnostics for Flow-Matching Neural Posterior Estimation in a Controlled Gravitational-Wave Benchmark
Pith reviewed 2026-06-27 08:14 UTC · model grok-4.3
The pith
Soft artifact-aware rescaling cuts frequency-mask calibration error from 0.1195 to 0.0672 in a gravitational-wave benchmark but is not uniformly better than raw intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the 1024-bin controlled binary-black-hole benchmark, a single global scale fitted on mixed calibration data gives MA90CE = 0.1195 on frequency-mask cases, while soft LAIR lowers the same error to 0.0672; however, soft LAIR is not uniformly better than the raw FMPE intervals. A 40-seed LAIR audit and six-checkpoint FMPE training-seed audit confirm the frequency-mask behavior is reproducible. The artifact classifier recognizes frequency masks and PSD mismatch reliably but shows low glitch recall. Marginal coverage must be read together with posterior width, geometry, and likelihood-based diagnostics.
What carries the argument
Soft learned artifact-aware interval rescaling (LAIR), which trains a classifier on artifact labels and uses its soft predictions to rescale marginal credible intervals in an artifact-conditioned way.
If this is right
- Global rescaling fitted on mixed data transfers poorly to frequency-mask cases.
- Soft LAIR improves calibration error specifically for frequency masks and PSD mismatch.
- The artifact classifier detects frequency masks and PSD mismatch reliably but has low recall for glitches.
- Marginal interval calibration must be interpreted together with posterior width, geometry, and likelihood diagnostics.
- LAIR functions best as an artifact-structured interval diagnostic rather than a substitute for posterior validation.
Where Pith is reading between the lines
- If real detector data show similar frequency-dependent artifacts, conditioning interval adjustments on predicted artifact type could help isolate which data-quality issues drive miscalibration.
- Enhancing glitch detection accuracy would be a direct way to broaden LAIR's coverage to the full range of artifacts.
- Benchmarks that jointly track coverage, posterior geometry, and likelihood consistency may be needed to decide when any single rescaling method is sufficient.
Load-bearing premise
The synthetic glitches, frequency masks, and PSD mismatch created for the benchmark are representative enough of real gravitational-wave data-quality artifacts that the observed calibration differences will generalize.
What would settle it
On real LIGO/Virgo strain data containing actual frequency masks or PSD mismatch, applying soft LAIR produces no reduction in marginal calibration error relative to raw FMPE intervals.
Figures







read the original abstract
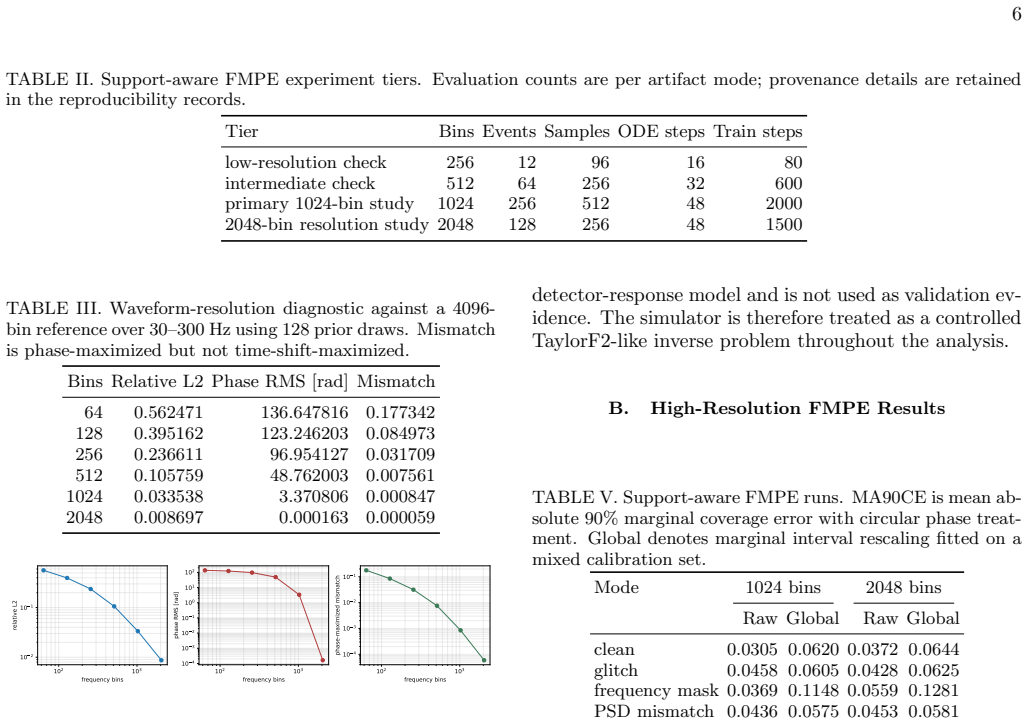
Calibration checks for neural posterior estimators in gravitational-wave inference should remain interpretable when observations contain data-quality artifacts. We study marginal interval calibration in a controlled frequency-domain binary-black-hole benchmark with synthetic glitches, frequency masks, and power-spectral-density mismatch. The posterior sampler is a support-aware conditional flow-matching estimator with a circular representation of coalescence phase. We compare raw marginal credible intervals with global rescaling, oracle artifact-stratified rescaling, hard predicted-label rescaling, and soft learned artifact-aware interval rescaling (LAIR). In the 1024-bin evaluation, a single global scale fitted on mixed calibration data transfers poorly to frequency-mask cases, giving MA90CE = 0.1195. Soft LAIR lowers the corresponding error to 0.0672, but it is not uniformly better than the raw FMPE intervals. A 40-seed LAIR audit and a six-checkpoint FMPE training-seed audit show that the frequency-mask behavior is not a single-split artifact. The classifier recognizes frequency masks and PSD mismatch reliably, while glitch recall remains low. Waveform-resolution tests, PyCBC/LAL TaylorF2 backend checks, prior and Gaussian baselines, and controlled-likelihood reference-posterior probes indicate that marginal coverage must be read together with posterior width, geometry, and likelihood-based diagnostics. In this benchmark, LAIR is therefore best viewed as an artifact-structured interval diagnostic rather than as a substitute for posterior validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in a controlled frequency-domain binary-black-hole benchmark incorporating synthetic glitches, frequency masks, and PSD mismatch, a support-aware conditional flow-matching posterior estimator yields marginal credible intervals whose calibration can be improved by artifact-aware rescaling methods. Specifically, a single global scale fitted on mixed data gives MA90CE = 0.1195 on frequency-mask cases, while soft learned artifact-aware interval rescaling (LAIR) reduces this to 0.0672; however LAIR is not uniformly superior to the raw FMPE intervals. The authors support this with 40-seed LAIR and six-checkpoint FMPE audits, classifier performance on artifact types, and multiple sanity checks (waveform resolution, PyCBC/LAL backends, prior/Gaussian baselines, controlled-likelihood probes), concluding that LAIR functions best as an artifact-structured diagnostic rather than a replacement for full posterior validation.
Significance. If the benchmark results hold, the work supplies a concrete, interpretable diagnostic for marginal interval calibration under realistic data-quality artifacts in gravitational-wave neural posterior estimation. The explicit scoping to the controlled setting, the demonstration that global rescaling transfers poorly while artifact-conditioned rescaling improves selected cases, and the insistence on reading marginal coverage together with width/geometry/likelihood diagnostics are all constructive. The multiple-seed audits and explicit baseline comparisons add reproducibility and falsifiability to the central numerical claims.
minor comments (2)
- Abstract: the precise definition of MA90CE (mean absolute 90 % credible-interval error) and the exact construction of the 1024-bin evaluation set are not stated; a one-sentence definition or forward reference to the methods section would improve immediate readability.
- The manuscript would benefit from a short table summarizing the four rescaling strategies (global, oracle-stratified, hard-label, soft LAIR) together with their MA90CE values on each artifact class; this would make the comparative claim in the abstract easier to verify at a glance.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of the manuscript and for recommending minor revision. The assessment correctly identifies the controlled benchmark scope, the non-uniform performance of LAIR versus raw intervals, the role of multi-seed audits, and the positioning of LAIR as a diagnostic rather than a replacement for full posterior validation. No major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper reports empirical results from a controlled benchmark comparing interval calibration methods (global rescaling, oracle, hard/soft LAIR) on synthetic gravitational-wave data with artifacts. No load-bearing derivation, fitted parameter renamed as prediction, or self-citation chain is present; MA90CE values are direct measurements against explicit baselines, and the central claim is scoped to the benchmark with explicit caveats on generalization and the need for complementary diagnostics. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Its importance-sampling correction also illus- trates how an amortized proposal can be checked against a likelihood
Position relative to DINGO, FMPE, and likelihood-corrected neural inference DINGO is the closest established neural posterior- estimation benchmark family for gravitational-wave in- ference. Its importance-sampling correction also illus- trates how an amortized proposal can be checked against a likelihood. The present work does not implement that correcti...
-
[2]
DINGO-style conditional flows show that amortized density estimators can produce rapid compact-binary posterior samples
Model-family choice: discrete flows, flow matching, and score-based diffusion Discrete normalizing flows are the established neural- density baseline for gravitational-wave parameter estima- tion. DINGO-style conditional flows show that amortized density estimators can produce rapid compact-binary posterior samples. The RealNVP baseline below tests this d...
-
[3]
The inverse transform maps samples back into the physical prior in- terval
Support-Aware Transforms For each bounded scalar parameter x ∈ [ℓ, u], the model uses z = x − ℓ u − ℓ , y = log z 1 − z , with numerical clipping before the logit. The inverse transform maps samples back into the physical prior in- terval. This keeps decoded M, q, dL, and tc samples inside the prior support. Unless stated otherwise, inter- val rescaling f...
-
[4]
The model target is therefore y(θ) = (logit M, logit q, logit dL, cos ϕc, sin ϕc, logit tc)
Circular Phase Treatment Coalescence phase is embedded as (cos ϕc, sin ϕc) during training and decoded with atan2 modulo 2 π. The model target is therefore y(θ) = (logit M, logit q, logit dL, cos ϕc, sin ϕc, logit tc) . The phase coordinates are decoded after normalization by rϕ = q u2 ϕ + v2 ϕ, where (uϕ, vϕ) is the generated phase embedding. The impleme...
-
[5]
A base sample z0 is drawn from a standard Gaus- sian
Conditional Flow Matching Let x denote the observation and y the support-aware target. A base sample z0 is drawn from a standard Gaus- sian. Conditional flow matching trains a time-dependent vector field vφ(z, t, x) using the straight-line interpolation zt = (1 − t)z0 + ty, with target velocity y − z0. The objective is L(φ) = Ex,y,z0,t h ∥vφ(zt, t, x) − (...
-
[6]
Global rescaling fits one scale factor per param- eter on calibration data and applies it to all evaluation intervals
Marginal Interval Rescaling Raw posterior samples define the marginal credible in- tervals. Global rescaling fits one scale factor per param- eter on calibration data and applies it to all evaluation intervals. Oracle artifact-stratified rescaling fits one scale per artifact and parameter, then uses the true artifact la- bel. Predicted-label rescaling rep...
-
[7]
Its channels are detector real and imaginary components plus the mask
Artifact Classifier and LAIR The artifact classifier is a one-dimensional convolu- tional network over the frequency axis. Its channels are detector real and imaginary components plus the mask. Let pψ(a | x) be the classifier probability for artifact class a. LAIR fits scale factors sa,k for artifact class a and pa- rameter k on calibration data. The soft...
-
[8]
A prior-only baseline asks how often the truth falls in cen- tral prior intervals
Baselines Two baselines contextualize the coverage results. A prior-only baseline asks how often the truth falls in cen- tral prior intervals. A diagonal Gaussian posterior base- line gives a simple parametric approximation in the 256- bin smoke setting. Low MA90CE for either baseline does not imply an accurate posterior; it can also reflect broad intervals
-
[9]
The primary scalar metric is mean absolute 90% marginal coverage error, MA90CE = 1 K KX k=1 |ˆck(0.9) − 0.9|
Metrics For nominal level α, the empirical marginal coverage for parameter k is ˆck(α) = 1 N NX i=1 1{θtrue i,k ∈ I α i,k}. The primary scalar metric is mean absolute 90% marginal coverage error, MA90CE = 1 K KX k=1 |ˆck(0.9) − 0.9|. We also track normalized mean absolute error, bias, pos- terior widths, and coverage curves. Event-bootstrap in- tervals re...
2048
- [10]
- [11]
- [12]
-
[13]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, arXiv preprint arXiv:2210.02747 (2022), arXiv:2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [14]
-
[15]
Validating Bayesian infer- ence algorithms with simulation-based calibration.arXiv:1804.06788
S. Talts, M. Betancourt, D. Simpson, A. Vehtari, and A. Gelman, arXiv preprint arXiv:1804.06788 (2018), arXiv:1804.06788
-
[16]
Sampling- based accuracy testing of posterior estimators for general inference, 2023
P. Lemos, A. Coogan, Y. Hezaveh, and L. Perreault- Levasseur, arXiv preprint arXiv:2302.03026 (2023), arXiv:2302.03026
-
[17]
Bilby: A user-friendly Bayesian inference library for gravitational-wave astronomy
G. Ashton, M. Huebner, P. D. Lasky, et al. , The As- trophysical Journal Supplement Series 241, 27 (2019), arXiv:1811.02042
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
C. M. Biwer, C. D. Capano, S. De, M. Cabero, D. A. Brown, A. H. Nitz, and V. Raymond, Publications of the Astronomical Society of the Pacific 131, 024503 (2019), arXiv:1807.10312
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
Wette, SoftwareX 12, 100634 (2020), arXiv:2012.09552
K. Wette, SoftwareX 12, 100634 (2020), arXiv:2012.09552
-
[20]
V. Raymond, S. Al-Shammari, and A. G¨ ottel, arXiv preprint arXiv:2406.03935 (2024), arXiv:2406.03935
- [21]
-
[22]
The LIGO Scientific Collaboration, The Virgo Col- laboration, and The KAGRA Collaboration, The As- trophysical Journal Supplement Series 267, 29 (2023), arXiv:2302.03676
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
The LIGO Scientific Collaboration, The Virgo Collabo- ration, and The KAGRA Collaboration, arXiv preprint arXiv:2605.27090 (2026), arXiv:2605.27090
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.