LongSpike: Fractional Order Spiking State Space Models for Efficient Long Sequence Learning
Pith reviewed 2026-06-27 07:25 UTC · model grok-4.3
The pith
Fractional-order state-space models in spiking networks capture long-range dependencies more effectively than first-order SNNs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
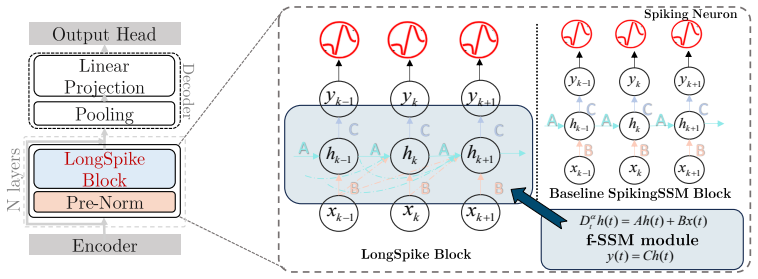
LongSpike shows that embedding fractional-order state-space modeling into spiking neurons produces hierarchical long-memory kernels that overcome the memoryless constraint of integer-order dynamics, yielding higher accuracy on long-sequence tasks while preserving sparse synaptic computation and supporting efficient parallel training.
What carries the argument
fractional-order State-Space Modeling (f-SSM) integrated into spiking neuron state transitions to supply long-memory kernels in a discretizable, parallelizable form
If this is right
- SNNs become competitive with non-spiking sequence models on tasks requiring long context.
- Sparse computation and event-driven execution remain intact across the evaluated benchmarks.
- Parallel training via the state-space formulation scales to large text and speech datasets.
- The same fractional extension can be applied to other sequential modalities without altering the spiking sparsity property.
Where Pith is reading between the lines
- If the discretization exactly preserves fractional memory properties, the same structure could be tested on even longer contexts or continuous-time control tasks.
- The approach suggests a route to combine neuromorphic hardware constraints with classical control-theory memory models.
- Adaptive selection of fractional order per layer might further improve performance without extra parameters.
Load-bearing premise
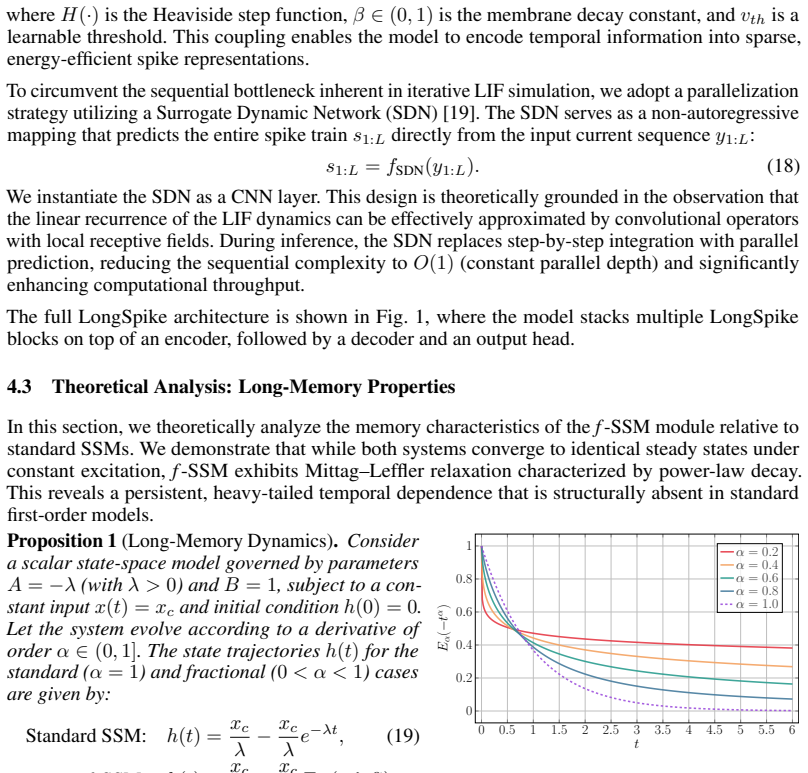
Fractional-order operators can be discretized into an efficient parallel state-space form without approximation errors that remove the claimed long-memory benefit or the sparse spiking energy savings.
What would settle it
An experiment in which the discretized LongSpike model either matches or underperforms first-order SNN baselines on Long Range Arena accuracy or exhibits dense rather than sparse synaptic activity due to discretization artifacts.
Figures
read the original abstract
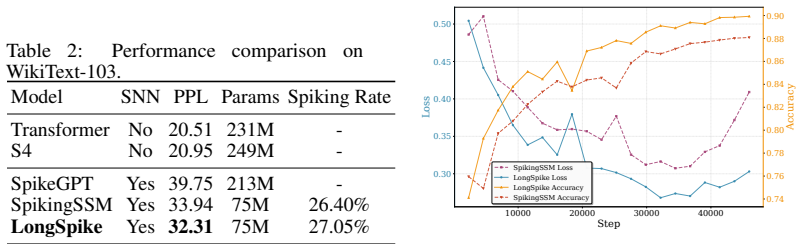
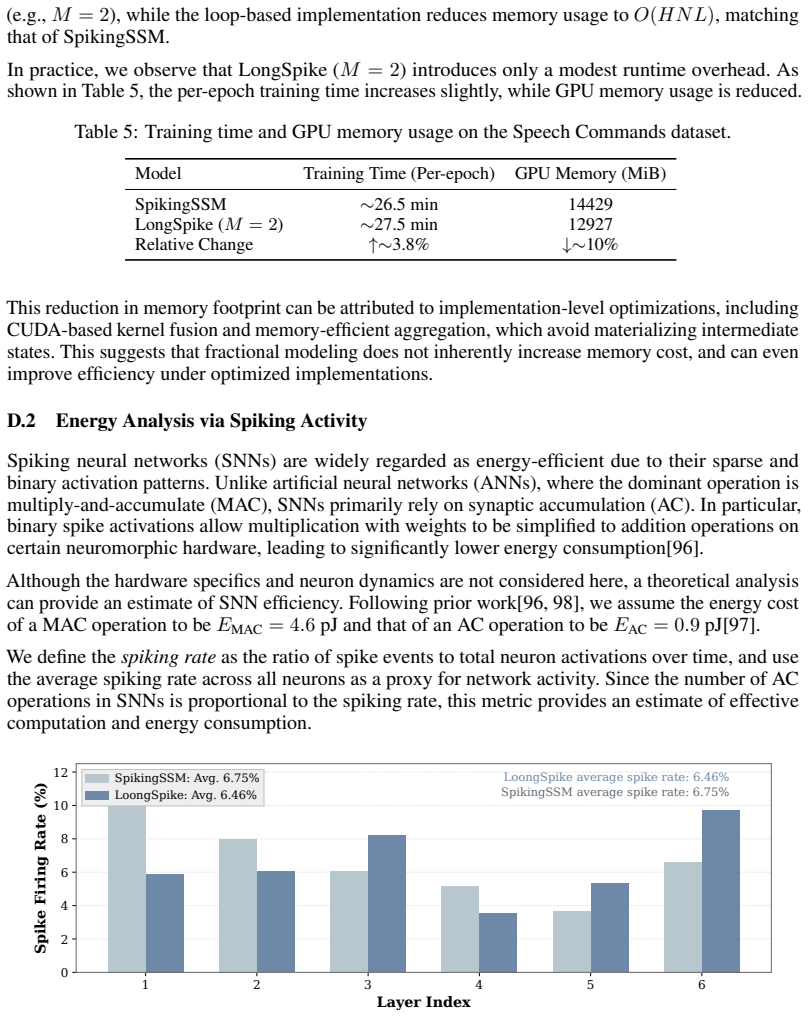
Spiking Neural Networks (SNNs) are well-regarded for their biological plausibility and energy efficiency in processing sequential data. However, dominant SNN architectures typically rely on first-order Ordinary Differential Equations (ODEs) to govern neuronal state transitions. This first-order assumption imposes a "memoryless" bottleneck, limiting the model's capacity to capture the complex, long-range dependencies inherent in long-sequence tasks. In this work, we propose LongSpike, a novel SNN framework that integrates fractional-order State-Space Modeling, or f-SSM, from control theory into the spiking domain. By extending traditional integer-order SSMs to the fractional-calculus regime, LongSpike enables the hierarchical integration of neuronal dynamics with long-memory kernels. To mitigate the computational overhead and parallelization challenges typically associated with fractional operators, we leverage a state-space formulation that supports efficient, parallel training. Empirical evaluations on challenging benchmarks, including Long Range Arena (LRA), large-scale WikiText-103, and Speech Commands, demonstrate that LongSpike outperforms state-of-the-art SNNs in accuracy while preserving sparse synaptic computation. The code is available at https://github.com/xinruihe389-commits/LongSpike.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LongSpike, an SNN architecture that replaces first-order ODE neuronal dynamics with fractional-order state-space models (f-SSM) drawn from control theory. The central claim is that the resulting long-memory kernels enable superior capture of long-range dependencies on LRA, WikiText-103, and Speech Commands while retaining the sparse, event-driven computation of spiking networks; a state-space reformulation is asserted to permit efficient parallel training.
Significance. If the discretization of the fractional operators can be shown to preserve non-local memory without collapsing to first-order behavior or incurring prohibitive approximation error, the work would provide a concrete route to long-context SNNs that remain biologically motivated and energy-efficient. The public code release is a positive factor for reproducibility.
major comments (2)
- [§3] §3 (f-SSM discretization): the manuscript asserts that fractional-order operators are recast into a parallelizable state-space recurrence, yet supplies neither the explicit discretization formula, truncation error bounds, nor a proof that the resulting kernel retains the claimed power-law memory tail on sequence lengths typical of LRA and WikiText-103. Without this analysis the long-memory advantage over standard first-order SNNs remains unverified.
- [§4] §4 (experiments): the reported accuracy gains lack error bars, ablation on the fractional order α, statistical significance tests, or direct comparison against non-spiking fractional SSM baselines. Consequently the claim that LongSpike “outperforms state-of-the-art SNNs while preserving sparse synaptic computation” rests on uninspectable evidence.
minor comments (2)
- Notation for the fractional derivative and the state-space matrices should be introduced once with explicit definitions rather than assumed from control-theory literature.
- The abstract states empirical superiority but the main text should move the key implementation details (discretization scheme, parallel scan algorithm) from the appendix into the primary narrative.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested analysis and experimental details, which will strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§3] §3 (f-SSM discretization): the manuscript asserts that fractional-order operators are recast into a parallelizable state-space recurrence, yet supplies neither the explicit discretization formula, truncation error bounds, nor a proof that the resulting kernel retains the claimed power-law memory tail on sequence lengths typical of LRA and WikiText-103. Without this analysis the long-memory advantage over standard first-order SNNs remains unverified.
Authors: We agree that the discretization details are essential for verifying the long-memory property. In the revised manuscript we will supply the explicit discretization formula for the fractional-order operators, derive truncation error bounds, and include an analysis (with supporting derivation) showing that the resulting kernel retains its power-law memory tail on sequence lengths matching those in the LRA and WikiText-103 benchmarks. This will directly substantiate the claimed advantage over first-order SNNs. revision: yes
-
Referee: [§4] §4 (experiments): the reported accuracy gains lack error bars, ablation on the fractional order α, statistical significance tests, or direct comparison against non-spiking fractional SSM baselines. Consequently the claim that LongSpike “outperforms state-of-the-art SNNs while preserving sparse synaptic computation” rests on uninspectable evidence.
Authors: We acknowledge that the experimental results would be more convincing with these additions. In the revision we will report error bars computed over multiple independent runs, present an ablation study on the fractional order α, include statistical significance tests for the reported accuracy improvements, and add direct comparisons against non-spiking fractional SSM baselines. These changes will render the supporting evidence fully inspectable and will clarify the contribution of the spiking component. revision: yes
Circularity Check
No circularity: derivation relies on external fractional calculus and empirical benchmarks
full rationale
The abstract and description present LongSpike as integrating fractional-order operators from control theory into spiking SSMs, with a state-space formulation enabling parallel training, followed by evaluation on independent public benchmarks (LRA, WikiText-103, Speech Commands). No equations, self-citations, or fitted parameters are quoted that reduce the claimed long-memory advantage or performance gains to a definitional equivalence or input fit. The discretization step is asserted as solving overhead without shown reduction to prior results by construction, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- fractional order alpha
axioms (1)
- domain assumption Fractional differential operators admit stable discrete-time state-space realizations suitable for parallel training.
Reference graph
Works this paper leans on
-
[1]
Bidirectional recurrent neural networks.IEEE transactions on Signal Processing, 45(11):2673–2681, 1997
Mike Schuster and Kuldip K Paliwal. Bidirectional recurrent neural networks.IEEE transactions on Signal Processing, 45(11):2673–2681, 1997
1997
-
[2]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational conference on machine learning, pages 1310–1318. Pmlr, 2013
2013
-
[3]
Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
1997
-
[4]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling.arXiv preprint arXiv:1412.3555, 2014
Pith/arXiv arXiv 2014
-
[5]
Networks of spiking neurons: the third generation of neural network models
Wolfgang Maass. Networks of spiking neurons: the third generation of neural network models. Neural networks, 10(9):1659–1671, 1997
1997
-
[6]
Spiking neural networks.International journal of neural systems, 19(04):295–308, 2009
Samanwoy Ghosh-Dastidar and Hojjat Adeli. Spiking neural networks.International journal of neural systems, 19(04):295–308, 2009
2009
-
[7]
Training deep spiking neural networks using backpropagation.Frontiers in neuroscience, 10:508, 2016
Jun Haeng Lee, Tobi Delbruck, and Michael Pfeiffer. Training deep spiking neural networks using backpropagation.Frontiers in neuroscience, 10:508, 2016
2016
-
[8]
Spatio-temporal backpropagation for training high-performance spiking neural networks.Frontiers in neuroscience, 12:331, 2018
Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. Spatio-temporal backpropagation for training high-performance spiking neural networks.Frontiers in neuroscience, 12:331, 2018
2018
-
[9]
Training spiking neural networks using lessons from deep learning.Proceedings of the IEEE, 111(9):1016–1054, 2023
Jason K Eshraghian, Max Ward, Emre Neftci, Xinxin Wang, Gregor Lenz, Girish Dwivedi, Mohammed Bennamoun, Doo Seok Jeong, and Wei D Lu. Training spiking neural networks using lessons from deep learning.Proceedings of the IEEE, 111(9):1016–1054, 2023
2023
-
[10]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[11]
Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768, 2020
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768, 2020
Pith/arXiv arXiv 2006
-
[12]
Reformer: The efficient transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020
Pith/arXiv arXiv 2001
-
[13]
Longformer: The long-document transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020. 10
Pith/arXiv arXiv 2004
-
[14]
Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33: 1474–1487, 2020
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33: 1474–1487, 2020
2020
-
[15]
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021
Pith/arXiv arXiv 2021
-
[16]
On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
2022
-
[17]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First conference on language modeling, 2024
2024
-
[18]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
Pith/arXiv arXiv 2024
-
[19]
Spikingssms: Learning long sequences with sparse and parallel spiking state space models
Shuaijie Shen, Chao Wang, Renzhuo Huang, Yan Zhong, Qinghai Guo, Zhichao Lu, Jianguo Zhang, and Luziwei Leng. Spikingssms: Learning long sequences with sparse and parallel spiking state space models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20380–20388, 2025
2025
-
[20]
Spiking structured state space model for monaural speech enhancement
Yu Du, Xu Liu, and Yansong Chua. Spiking structured state space model for monaural speech enhancement. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 766–770. IEEE, 2024
2024
-
[21]
Spikebert: A language spikformer learned from bert with knowledge distillation.Neural Networks, page 108482, 2025
Changze Lv, Tianlong Li, Weiming Qiao, Xiaohua Wang, Muling Wu, Wenhao Liu, Shihan Dou, Xiaoqing Zheng, and Xuanjing Huang. Spikebert: A language spikformer learned from bert with knowledge distillation.Neural Networks, page 108482, 2025
2025
-
[22]
elsevier, 1998
Igor Podlubny.Fractional differential equations: an introduction to fractional derivatives, fractional differential equations, to methods of their solution and some of their applications, volume 198. elsevier, 1998
1998
-
[23]
The infinite state approach: Origin and necessity.Computers & Mathematics with Applications, 66(5):892–907, 2013
Jean-Claude Trigeassou, Nezha Maamri, and Alain Oustaloup. The infinite state approach: Origin and necessity.Computers & Mathematics with Applications, 66(5):892–907, 2013
2013
-
[24]
Stability results for fractional differential equations with applications to control processing
Denis Matignon. Stability results for fractional differential equations with applications to control processing. InComputational engineering in systems applications, volume 2, pages 963–968. Lille, France, 1996
1996
-
[25]
Stability of discrete fractional order state-space systems.Journal of Vibration and Control, 14(9-10):1543–1556, 2008
Andrzej Dzieli´nski and Dominik Sierociuk. Stability of discrete fractional order state-space systems.Journal of Vibration and Control, 14(9-10):1543–1556, 2008
2008
-
[26]
The analysis of fractional differential equations
Diethelm Kai. The analysis of fractional differential equations. an application-oriented exposi- tion using differential operators of caputo type.Lecture Notes in Mathematics, 2004
2004
-
[27]
World Scientific, 2012
Dumitru Baleanu, Kai Diethelm, Enrico Scalas, and Juan J Trujillo.Fractional calculus: models and numerical methods, volume 3. World Scientific, 2012
2012
-
[28]
Fractional-order spiking neural network
Chengjie Ge, Yufeng Peng, Zihao Li, Qiyu Kang, Xueyang Fu, Xuhao Li, Qixin Zhang, Junhao Ren, and Zheng-Jun Zha. Fractional-order spiking neural network. InProc. Int. Conf. Learn. Representations, 2026
2026
-
[29]
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
Pith/arXiv arXiv 2023
-
[30]
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635, 2023
Pith/arXiv arXiv 2023
-
[31]
Diagonal state spaces are as effective as structured state spaces.Advances in neural information processing systems, 35:22982–22994, 2022
Ankit Gupta, Albert Gu, and Jonathan Berant. Diagonal state spaces are as effective as structured state spaces.Advances in neural information processing systems, 35:22982–22994, 2022. 11
2022
-
[32]
Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks
Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Processing Magazine, 36(6):51–63, 2019
2019
-
[33]
Rui-Jie Zhu, Qihang Zhao, Guoqi Li, and Jason K Eshraghian. Spikegpt: Generative pre-trained language model with spiking neural networks.arXiv preprint arXiv:2302.13939, 2023
arXiv 2023
-
[34]
Zeyu Liu, Gourav Datta, Anni Li, and Peter Anthony Beerel. Lmuformer: Low complexity yet powerful spiking model with legendre memory units.arXiv preprint arXiv:2402.04882, 2024
arXiv 2024
-
[35]
Legendre memory units: Continuous-time representation in recurrent neural networks.Advances in neural information processing systems, 32, 2019
Aaron V oelker, Ivana Kaji´c, and Chris Eliasmith. Legendre memory units: Continuous-time representation in recurrent neural networks.Advances in neural information processing systems, 32, 2019
2019
-
[36]
Learning long sequences in spiking neural networks
Matei-Ioan Stan and Oliver Rhodes. Learning long sequences in spiking neural networks. Scientific Reports, 14(1):21957, 2024
2024
-
[37]
P-spikessm: Harnessing probabilistic spiking state space models for long-range dependency tasks
Malyaban Bal and Abhronil Sengupta. P-spikessm: Harnessing probabilistic spiking state space models for long-range dependency tasks. International Conference on Representation Learning (ICLR) 2025, 2025
2025
-
[38]
World Scientific, 2022
Francesco Mainardi.Fractional calculus and waves in linear viscoelasticity: an introduction to mathematical models. World Scientific, 2022
2022
-
[39]
Neural variable-order fractional differential equation networks
Wenjun Cui, Qiyu Kang, Xuhao Li, Kai Zhao, Wee Peng Tay, Weihua Deng, and Yidong Li. Neural variable-order fractional differential equation networks. InProc. AAAI Conference on Artificial Intelligence, Philadelphia, USA, Feb. 2025
2025
-
[40]
Neural fractional attention differential equations
Qiyu Kang, Wenjun Cui, Xuhao Li, Yuxin Ma, Xueyang Fu, Wee Peng Tay, Yidong Li, and Zheng-Jun Zha. Neural fractional attention differential equations. InAdvances in Neural Information Processing Systems, San Diego, USA, Dec. 2025
2025
-
[41]
Unleashing the potential of fractional calculus in graph neural networks with FROND
Qiyu Kang, Kai Zhao, Qinxu Ding, Feng Ji, Xuhao Li, Wenfei Liang, Yang Song, and Wee Peng Tay. Unleashing the potential of fractional calculus in graph neural networks with FROND. In Proc. International Conference on Learning Representations, 2024
2024
-
[42]
Coupling graph neural networks with fractional order continuous dynamics: A robustness study
Qiyu Kang, Kai Zhao, Yang Song, Yihang Xie, Yanan Zhao, Sijie Wang, Rui She, and Wee Peng Tay. Coupling graph neural networks with fractional order continuous dynamics: A robustness study. InProc. AAAI Conference on Artificial Intelligence, Vancouver, Canada, Feb. 2024
2024
-
[43]
Generative fractional diffusion models.Advances in Neural Information Processing Systems, 37:25469–25509, 2024
Gabriel Nobis, Maximilian Springenberg, Marco Aversa, Michael Detzel, Rembert Daems, Roderick Murray-Smith, Shinichi Nakajima, Sebastian Lapuschkin, Stefano Ermon, Tolga Birdal, et al. Generative fractional diffusion models.Advances in Neural Information Processing Systems, 37:25469–25509, 2024
2024
-
[44]
Neuronal spike timing adaptation described with a fractional leaky integrate-and-fire model.PLoS computational biology, 10(3): e1003526, 2014
Wondimu Teka, Toma M Marinov, and Fidel Santamaria. Neuronal spike timing adaptation described with a fractional leaky integrate-and-fire model.PLoS computational biology, 10(3): e1003526, 2014
2014
-
[45]
Yabin Deng, Bijing Liu, Zenan Huang, Xiaojie Liu, Shan He, Qiuhong Li, and Donghui Guo. Fractional spiking neuron: Fractional leaky integrate-and-fire circuit described with dendritic fractal model.IEEE Transactions on Biomedical Circuits and Systems, 16(6):1375–1386, 2022
2022
-
[46]
Kai Diethelm.The analysis of fractional differential equations: an application-oriented exposition using differential operators of Caputo type, volume 2004. Lect. Notes Math., 2010
2004
-
[47]
Daniel Y Fu, Tri Dao, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher Ré. Hungry hungry hippos: Towards language modeling with state space models.arXiv preprint arXiv:2212.14052, 2022
arXiv 2022
-
[48]
Some models of neuronal variability.Biophysical journal, 7(1):37–68, 1967
Richard B Stein. Some models of neuronal variability.Biophysical journal, 7(1):37–68, 1967
1967
-
[49]
Distributed-order fractional graph operating network.Advances in Neural Information Processing Systems, 37:103442–103475, 2024
Kai Zhao, Xuhao Li, Qiyu Kang, Feng Ji, Qinxu Ding, Yanan Zhao, Wenfei Liang, and Wee Peng Tay. Distributed-order fractional graph operating network.Advances in Neural Information Processing Systems, 37:103442–103475, 2024. 12
2024
-
[50]
Fast evaluation of the caputo fractional derivative and its applications to fractional diffusion equations.Communications in Computational Physics, 21(3):650–678, 2017
Shidong Jiang, Jiwei Zhang, Qian Zhang, and Zhimin Zhang. Fast evaluation of the caputo fractional derivative and its applications to fractional diffusion equations.Communications in Computational Physics, 21(3):650–678, 2017
2017
-
[51]
Long range arena: A benchmark for efficient transformers.arXiv preprint arXiv:2011.04006, 2020
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A benchmark for efficient transformers.arXiv preprint arXiv:2011.04006, 2020
arXiv 2011
-
[52]
Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
Pith/arXiv arXiv 2016
-
[53]
Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv preprint arXiv:1804.03209, 2018
Pith/arXiv arXiv 2018
-
[54]
Fundamentals of recurrent neural network (rnn) and long short-term memory (lstm) network.Physica D: Nonlinear Phenomena, 404:132306, 2020
Alex Sherstinsky. Fundamentals of recurrent neural network (rnn) and long short-term memory (lstm) network.Physica D: Nonlinear Phenomena, 404:132306, 2020
2020
-
[55]
On the vanishing and exploding gradient problem in gated recurrent units.IFAC-PapersOnLine, 53(2):1243–1248, 2020
Alexander Rehmer and Andreas Kroll. On the vanishing and exploding gradient problem in gated recurrent units.IFAC-PapersOnLine, 53(2):1243–1248, 2020
2020
-
[56]
Academic Press, 1999
Igor Podlubny.Fractional Differential Equations. Academic Press, 1999
1999
-
[57]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[58]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[59]
Loihi: A neuromorphic manycore processor with on-chip learning.Ieee Micro, 38(1):82–99, 2018
Mike Davies, Narayan Srinivasa, Tsung-Han Lin, Gautham Chinya, Yongqiang Cao, Sri Harsha Choday, Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain, et al. Loihi: A neuromorphic manycore processor with on-chip learning.Ieee Micro, 38(1):82–99, 2018
2018
-
[60]
Long short-term memory rnn.arXiv preprint arXiv:2105.06756, 2021
Christian Bakke Vennerød, Adrian Kjærran, and Erling Stray Bugge. Long short-term memory rnn.arXiv preprint arXiv:2105.06756, 2021
arXiv 2021
-
[61]
Optically tunable electrical oscillations in oxide-based memristors for neuromorphic computing
Shimul Kanti Nath, Sujan Kumar Das, Sanjoy Kumar Nandi, Chen Xi, Camilo Verbel Marquez, Armando Rúa, Mutsunori Uenuma, Zhongrui Wang, Songqing Zhang, Rui-Jie Zhu, et al. Optically tunable electrical oscillations in oxide-based memristors for neuromorphic computing. Advanced Materials, 36(25):2400904, 2024
2024
-
[62]
Convolutional sequence to sequence learning
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. Convolutional sequence to sequence learning. InInternational conference on machine learning, pages 1243–
-
[63]
Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[64]
Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240): 1–113, 2023
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240): 1–113, 2023
2023
-
[65]
Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. Samba: Simple hybrid state space models for efficient unlimited context language modeling.arXiv preprint arXiv:2406.07522, 2024
arXiv 2024
-
[66]
Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887, 2024
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887, 2024. 13
Pith/arXiv arXiv 2024
-
[67]
Xingrun Xing, Zheng Liu, Shitao Xiao, Boyan Gao, Yiming Liang, Wanpeng Zhang, Haokun Lin, Guoqi Li, and Jiajun Zhang. Efficientllm: Scalable pruning-aware pretraining for architecture-agnostic edge language models.arXiv preprint arXiv:2502.06663, 2025
arXiv 2025
-
[68]
Spikingbert: Distilling bert to train spiking language models using implicit differentiation
Malyaban Bal and Abhronil Sengupta. Spikingbert: Distilling bert to train spiking language models using implicit differentiation. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 10998–11006, 2024
2024
-
[69]
Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425, 2022
Zhaokun Zhou, Yuesheng Zhu, Chao He, Yaowei Wang, Shuicheng Yan, Yonghong Tian, and Li Yuan. Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425, 2022
arXiv 2022
-
[70]
Spikformer v2: Join the high accuracy club on imagenet with an snn ticket
Zhaokun Zhou, Kaiwei Che, Wei Fang, Keyu Tian, Yuesheng Zhu, Shuicheng Yan, Yonghong Tian, and Li Yuan. Spikformer v2: Join the high accuracy club on imagenet with an snn ticket. arXiv preprint arXiv:2401.02020, 2024
arXiv 2024
-
[71]
Spikingminilm: energy-efficient spiking transformer for natural language understanding
Jiayu Zhang, Jiangrong Shen, Zeke Wang, Qinghai Guo, Rui Yan, Gang Pan, and Huajin Tang. Spikingminilm: energy-efficient spiking transformer for natural language understanding. Science China Information Sciences, 67(10):200406, 2024
2024
-
[72]
Xingrun Xing, Zheng Zhang, Ziyi Ni, Shitao Xiao, Yiming Ju, Siqi Fan, Yequan Wang, Jiajun Zhang, and Guoqi Li. Spikelm: Towards general spike-driven language modeling via elastic bi-spiking mechanisms.arXiv preprint arXiv:2406.03287, 2024
arXiv 2024
-
[73]
Xingrun Xing, Boyan Gao, Zheng Zhang, David A Clifton, Shitao Xiao, Li Du, Guoqi Li, and Jiajun Zhang. Spikellm: Scaling up spiking neural network to large language models via saliency-based spiking.arXiv preprint arXiv:2407.04752, 2024
arXiv 2024
-
[74]
Yan Zhong, Ruoyu Zhao, Chao Wang, Qinghai Guo, Jianguo Zhang, Zhichao Lu, and Luziwei Leng. Spike-ssm: A sparse, precise, and efficient spiking state space model for long sequences learning.arXiv preprint arXiv:2410.17268, 2024
arXiv 2024
-
[75]
Yangfan Hu, Qian Zheng, Guoqi Li, Huajin Tang, and Gang Pan. Toward large-scale spiking neu- ral networks: A comprehensive survey and future directions.arXiv preprint arXiv:2409.02111, 2024
arXiv 2024
-
[76]
Mobile edge intelligence for large language models: A contemporary survey.IEEE Communications Surveys & Tutorials, 2025
Guanqiao Qu, Qiyuan Chen, Wei Wei, Zheng Lin, Xianhao Chen, and Kaibin Huang. Mobile edge intelligence for large language models: A contemporary survey.IEEE Communications Surveys & Tutorials, 2025
2025
-
[77]
Cheng Kevin Qu, Andrew Ly, and Pulin Gong. Fractional neural attention for efficient multiscale sequence processing.arXiv preprint arXiv:2511.10208, 2025
arXiv 2025
-
[78]
Parallelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
2024
-
[79]
Metala: Unified optimal linear approximation to softmax attention map
Yuhong Chou, Man Yao, Kexin Wang, Yuqi Pan, Rui-Jie Zhu, Jibin Wu, Yiran Zhong, Yu Qiao, Bo Xu, and Guoqi Li. Metala: Unified optimal linear approximation to softmax attention map. Advances in Neural Information Processing Systems, 37:71034–71067, 2024
2024
-
[80]
Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.