H\"older++: Improving the Quality-Coherence Trade-off in Multimodal VAEs
Pith reviewed 2026-06-27 07:03 UTC · model grok-4.3
The pith
Hölder++ uses exact Hölder pooling, shared-private representations, and hierarchical inference to improve the quality-coherence trade-off in multimodal VAEs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
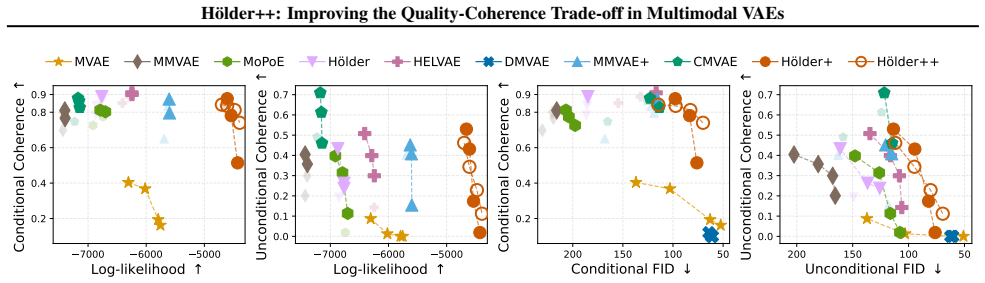
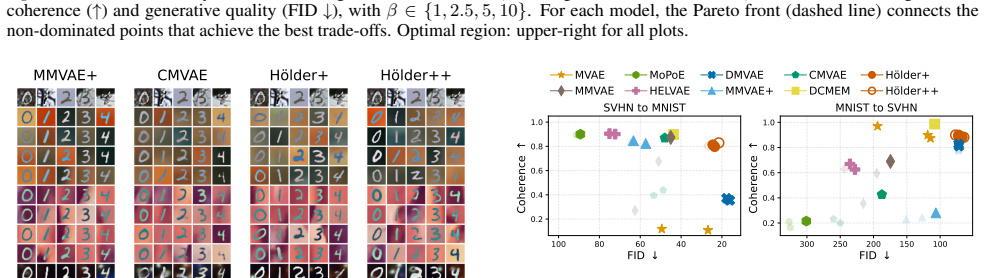
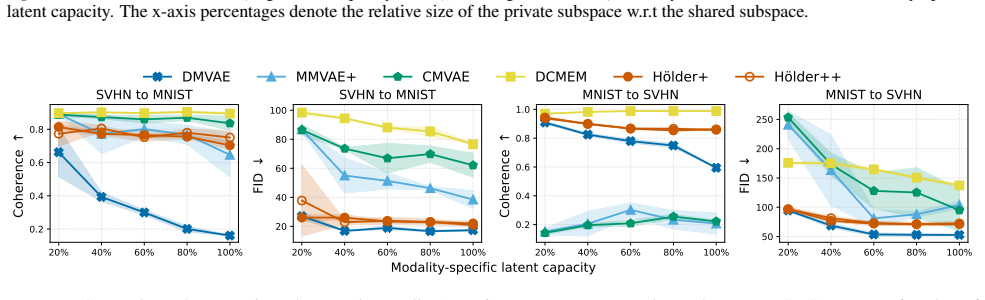
By replacing approximated Hölder pooling with its exact implementation, modeling explicit shared and private representations, and applying hierarchical inference, Hölder++ achieves better generative quality and coherence simultaneously in multimodal VAEs, while producing more structured latent spaces and informative shared representations for downstream tasks.
What carries the argument
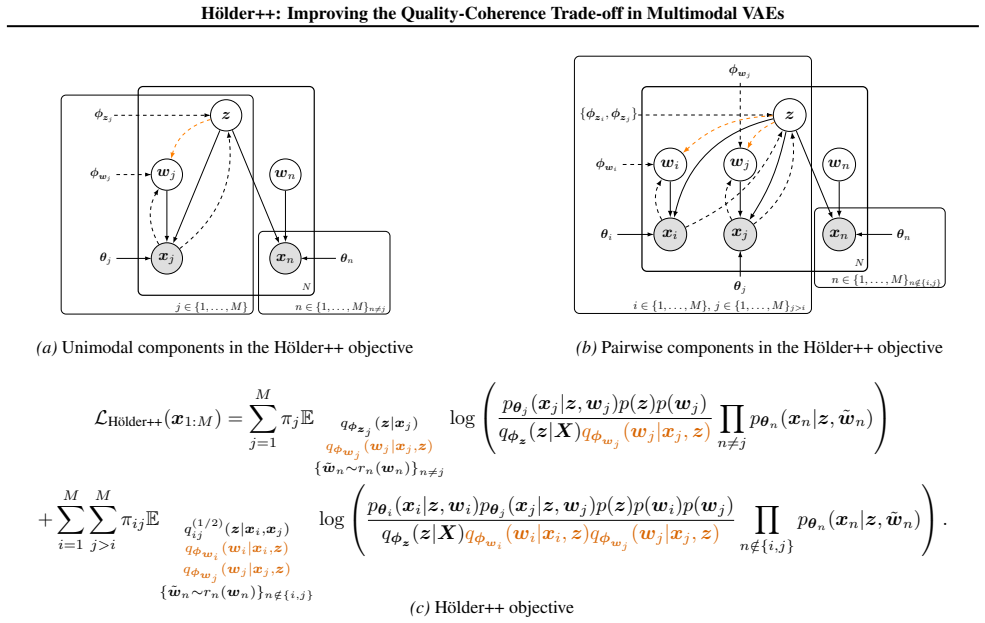
Exact Hölder pooling as the aggregation method for combining multimodal information, combined with shared-plus-private latent factorization and hierarchical inference for disentanglement.
If this is right
- Improved balance between realistic diverse samples and cross-modal semantic consistency.
- More structured latent spaces that better separate shared and private factors.
- Shared representations that perform well on downstream tasks.
- Consistent outperformance on the quality-coherence trade-off metric.
Where Pith is reading between the lines
- Exact Hölder pooling could be applied to other multimodal generative frameworks beyond VAEs to similar effect.
- The hierarchical inference structure might scale effectively to models with more than two modalities.
- Downstream task performance suggests potential for using the shared latents in transfer learning scenarios.
Load-bearing premise
That implementing exact Hölder pooling together with shared and private representations plus hierarchical inference will lead to measurable improvements in the quality-coherence trade-off and disentanglement.
What would settle it
Running the same experiments and finding no improvement or a worse trade-off in quality-coherence metrics for Hölder++ versus the approximated Hölder or MMVAE+ baselines would falsify the central claim.
Figures







read the original abstract
Existing approaches for multimodal variational autoencoders (VAEs) face a trade-off between generative quality and coherence-i.e., they struggle to generate realistic and diverse samples that, at the same time, are semantically consistent across modalities. A recent work shows that using a simple approximation to H\"older pooling as an aggregation method improves coherence over the SOTA MMVAE+, despite assuming a single shared representation across all modalities. Yet, it slightly compromises sample diversity. Inspired by this insight, we propose H\"older++, a novel multimodal VAE that improves the generative quality-coherence trade-off through: (i) the first implementation of H\"older pooling without any approximation for multimodal VAEs; (ii) an extended architecture that models distinct shared and private (i.e., modality-specific) representations (H\"older+); and (iii) hierarchical inference that further enhances the disentanglement between the shared and private representations (H\"older++). Our experiments corroborate that H\"older++ consistently improves the generative quality-coherence trade-off, yields more structured latent spaces, and learns shared representations that are informative for downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hölder++, a multimodal VAE architecture that (i) implements exact (non-approximated) Hölder pooling for the first time in this setting, (ii) extends the model to separate shared and private (modality-specific) latent representations (Hölder+), and (iii) adds hierarchical inference to improve disentanglement (Hölder++). It claims these changes together yield consistent improvements in the generative quality-coherence trade-off over prior MMVAE+ baselines, more structured latent spaces, and shared representations that are useful for downstream tasks.
Significance. If the empirical results hold after proper controls, the work would offer a concrete architectural recipe for balancing sample quality and cross-modal coherence in multimodal VAEs, with the exact Hölder pooling step being a potentially reusable technical contribution. The incremental variants (Hölder, Hölder+, Hölder++) provide a natural testbed for isolating the value of each mechanism.
major comments (2)
- [Experiments] Experiments section: the reported gains for Hölder++ are presented as incremental over Hölder and Hölder+, yet no ablation holds total capacity and architecture fixed while toggling only the pooling operator (exact Hölder vs. its approximation) or only the shared+private split. Without these controls, improvements cannot be confidently attributed to the claimed mechanisms rather than added parameters or hierarchical depth, directly testing the central claim that the combination produces measurable quality-coherence gains.
- [Method] Method section (description of Hölder pooling): the paper states it provides the first exact (non-approximated) implementation, but does not include a derivation or complexity analysis showing how the exact operator is computed tractably inside the VAE ELBO; if the implementation still relies on any Monte-Carlo or variational approximation for the pooling step, the distinction from prior work is weakened.
minor comments (2)
- [Abstract] Abstract: the notation "H"older" contains an escaped quote that should be rendered as the proper umlaut character throughout the manuscript.
- [Abstract] The abstract claims downstream-task informativeness of the shared representations but does not specify which tasks or metrics are used; this should be stated explicitly when the results are presented.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We will revise the manuscript to strengthen the experimental controls and provide additional methodological details as requested.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported gains for Hölder++ are presented as incremental over Hölder and Hölder+, yet no ablation holds total capacity and architecture fixed while toggling only the pooling operator (exact Hölder vs. its approximation) or only the shared+private split. Without these controls, improvements cannot be confidently attributed to the claimed mechanisms rather than added parameters or hierarchical depth, directly testing the central claim that the combination produces measurable quality-coherence gains.
Authors: We agree that the current set of experiments does not include ablations that hold total model capacity and architecture fixed while isolating only the pooling operator or the shared-private split. In the revised manuscript we will add these controls (e.g., by matching parameter counts across variants and reporting results for exact Hölder vs. approximated pooling under identical architectures) to better attribute the observed gains to the proposed mechanisms. revision: yes
-
Referee: [Method] Method section (description of Hölder pooling): the paper states it provides the first exact (non-approximated) implementation, but does not include a derivation or complexity analysis showing how the exact operator is computed tractably inside the VAE ELBO; if the implementation still relies on any Monte-Carlo or variational approximation for the pooling step, the distinction from prior work is weakened.
Authors: The exact (non-approximated) Hölder pooling is obtained via a closed-form expression for the Hölder mean that is substituted directly into the joint ELBO; this step does not introduce additional Monte-Carlo sampling beyond the standard reparameterized latent sampling already present in the VAE. To make this explicit we will insert a short derivation of the exact operator together with a complexity analysis (showing the pooling remains O(1) per sample) in the revised Method section. revision: yes
Circularity Check
No circularity: empirical architecture proposal with no derivations
full rationale
The paper proposes Hölder++ as an incremental multimodal VAE architecture relying on exact (non-approximated) Hölder pooling, shared+private latents, and hierarchical inference. All claims are framed as experimental outcomes rather than closed-form derivations or predictions. No equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the abstract or described content. The work is therefore self-contained against external benchmarks with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Importance Weighted Autoencoders
Burda, Y ., Grosse, R., and Salakhutdinov, R. Importance weighted autoencoders.arXiv preprint arXiv:1509.00519,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In3rd International Conference on Learn- ing Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings,
2015
-
[3]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Lee, M. and Pavlovic, V . Private-Shared Disentangled Mul- timodal V AE for Learning of Hybrid Latent Representa- tions.arXiv preprint arXiv:2012.13024,
-
[5]
Deep Variational Canonical Correlation Analysis
Wang, W., Yan, X., Lee, H., and Livescu, K. Deep Vari- ational Canonical Correlation Analysis.arXiv preprint arXiv:1610.03454,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Wesego, D. and Rooshenas, P. Multimodal elbo with diffu- sion decoders.arXiv preprint arXiv:2408.16883, 2024a. Wesego, D. and Rooshenas, P. Score-based multimodal au- toencoder.Transactions on Machine Learning Research, 2024b. Wolff, J., Krishnan, R. G., Ruff, L., Morshuis, J. N., Klein, T., Nakajima, S., and Nabi, M. Hierarchical multi- modal variational...
-
[7]
12 A.2 Lower-bound guarantee of the H ¨older+ and H¨older++ objectives
11 H¨older++: Improving the Quality-Coherence Trade-off in Multimodal V AEs Supplementary Material Table of Contents A Proofs 12 A.1 Derivations of H ¨older, H¨older+, and H¨older++ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 A.2 Lower-bound guarantee of the H ¨older+ and H¨older++ objectives . . . . . . . . . . . . . . . . . . . . ...
2026
-
[8]
pθj(xj|z,w j)p(wj) qϕwj (wj|xj,z) # ≥E qϕwj (wj |xj ,z)
introduces auxiliary distributions over private latent variables for unobserved modalities when estimating cross-modal reconstruction terms. Concretely, when z is sampled from expert j, we draw wj ∼q ϕwj (wj|xj) for the observed modality and draw ˜wn ∼r n(wn) for each modalityn̸=j. The resulting objective can be written as LMMVAE+(x1:M) = 1 M MX j=1 E qϕz...
2023
-
[9]
provides atightervariational lower bound than the ELBO in Eq. (5) by using a properly weighted multi-sample importance estimator, given by LIWAE(x1:M) =E z1:K ∼qΦ(z|x1:M) " log KX k=1 1 K pΘ(X,z k) qΦ(zk|X) # ,(15) with K is the number of samples. In multimodal V AEs, IWAE estimator is often preferred because it typically yields higher-entropy variational...
2019
-
[10]
log KX k=1 1 K pΘ(X,z k) qΦ(zk|X) # + MX i=1 MX j>i πijEz1:K ∼q(1/2) ij (z|xi,xj)
over theMmodalities as follows LMoE IWAE(x1:M) = 1 M MX j=1 Ez1:K ∼qϕj (z|xj) " log KX k=1 1 K pΘ(X,z k) qΦ(zk|X) # , which is a valid ELBO. In our case, under a H ¨older mixture with α= 0.5 in Eq. (6), we extend LIWAE in Eq. (15) via stratified sampling over theMmodalities to obtainL H¨ older IWAE as follows LH¨older IW AE(x1:M) = MX j=1 πjEz1:K ∼qϕj (z|...
2017
-
[11]
on NVIDIA A100-PCIE-80GB GPUs. Following prior work, we weight the KL term in the ELBO by a coefficient β (Higgins et al., 2017), i.e., βKL(qΦ(z|X)∥p(z)) , and select β via cross-validation over {1.0,2.5,5.0,10.0} for PolyMNIST and {1.0,2.5,5.0} for MNIST-SVHN, CUBICC, and CelebAMask-HQ. For DCMEM, we choose the method-specific parameter α over {0.1,0.5,1...
2017
-
[12]
For MMV AE+, CMV AE, H¨older+, and H¨older++, we use shared and modality-specific subspaces of 32 dimensions each. We train MMV AE, MMV AE+, and CMV AE withK= 1 for 150, 150, 250 epochs, respectively, and batch size 256, whereas H¨older+ and H¨older++ are trained with a multi-sample objective with K= 10 for 50 epochs and batch size32. For CMV AE, we set t...
2026
-
[13]
18 H¨older++: Improving the Quality-Coherence Trade-off in Multimodal V AEs CUBICC.The encoder and decoder architectures follow Palumbo et al
Finally, all models are trained with batch size 100 and learning rate 5e−4.Note that, for this dataset, we do not rescale likelihood terms by modality dimensionality; instead, we set the likelihood weights to50.0for MNIST and1.0for SVHN. 18 H¨older++: Improving the Quality-Coherence Trade-off in Multimodal V AEs CUBICC.The encoder and decoder architecture...
2024
-
[14]
0.0501 0.1940 0.2884 CMV AE (K=
1940
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.