Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
Pith reviewed 2026-06-27 07:09 UTC · model grok-4.3
The pith
On-policy distillation yields sparse coordinate updates that avoid principal weight directions even with dense teacher supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
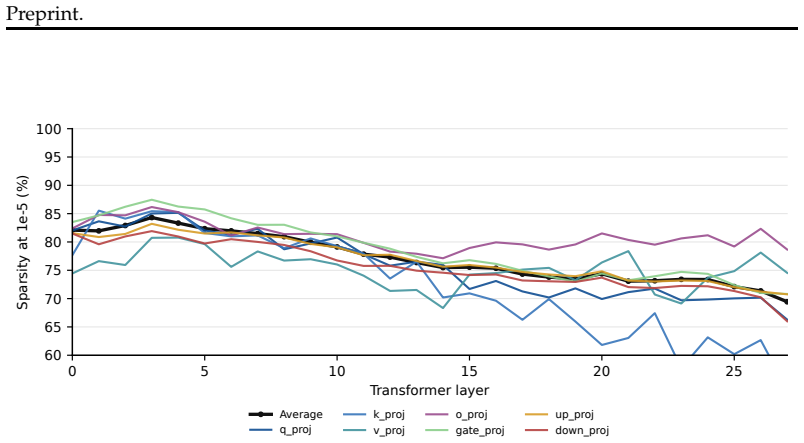
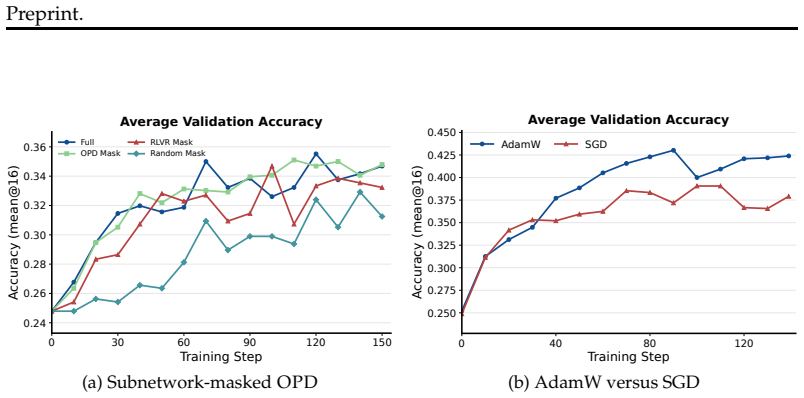
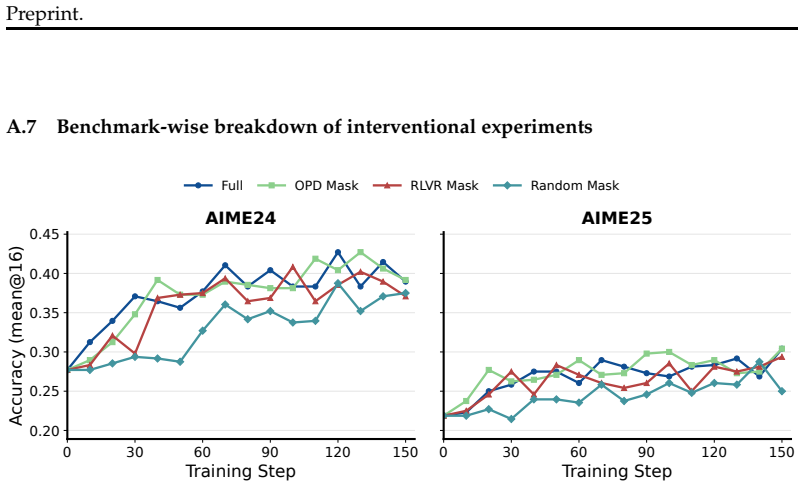
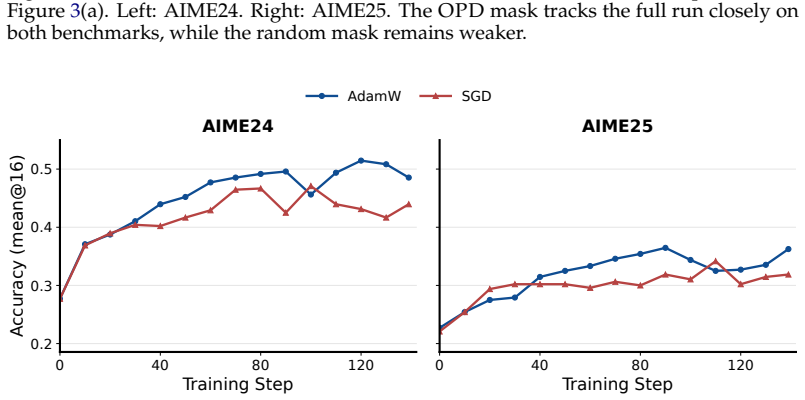
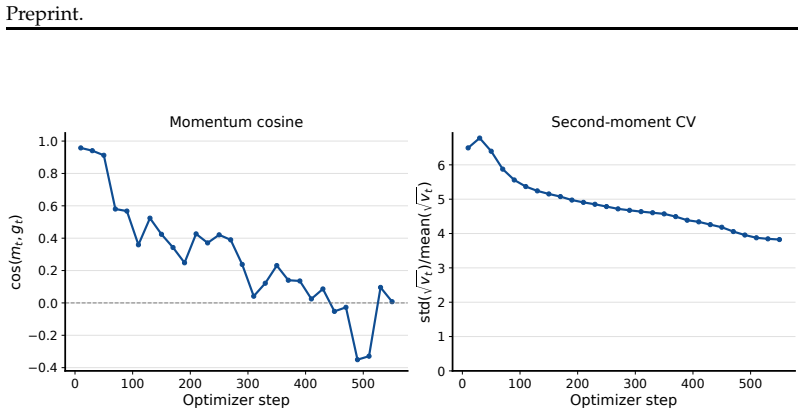
Across several language and vision-language model pairs, on-policy distillation produces coordinate-sparse updates that are distributed across layers and usually FFN-heavy. These updates are numerically full-rank but spectrally concentrated; they lie mostly away from the principal singular subspaces of the source weights and fall disproportionately on coordinates where the source weights are close to zero. Training only the discovered subnetwork recovers nearly the same performance as full OPD. The sparsity-inducing SGD optimizer underperforms AdamW because dense teacher supervision preserves heterogeneous coordinate-wise gradient scales where adaptive scaling remains useful.
What carries the argument
Coordinate sparsity combined with spectral concentration of the parameter updates away from principal singular subspaces.
If this is right
- Training only the sparse subnetwork identified by the update locations recovers nearly full OPD performance.
- AdamW remains preferable to plain SGD under dense supervision because it handles heterogeneous gradient scales.
- Updates consistently avoid the principal singular subspaces of the original weights.
- Updates land disproportionately on coordinates where source weights are near zero.
Where Pith is reading between the lines
- The observed sparsity pattern could be used to design cheaper post-training pipelines that update only a small fraction of parameters from the start.
- Similar geometric signatures may appear in other forms of on-policy alignment or preference optimization beyond distillation.
- Inspecting the magnitude and direction of early updates might allow early detection of whether a distillation run will succeed without completing the full schedule.
Load-bearing premise
The sparsity and geometric patterns observed in the selected language and vision-language model pairs generalize beyond the specific models, tasks, and training setups examined.
What would settle it
Observing dense, full-rank updates that fill the principal singular subspaces of the source weights when the same OPD procedure is run on a new model family or task would falsify the claim that OPD retains on-policy geometric signatures.
Figures

read the original abstract
On-policy distillation (\textsc{OPD}) has recently become a prominent post-training recipe as it combines two desirable ingredients: on-policy student trajectories and dense teacher supervision, yet how this hybrid changes a model's parameters remains unclear. Across several language and vision-language model pairs and use cases, our analysis yields two main findings. On sparsity, \textsc{OPD}-style updates are small and coordinate-sparse. They are distributed across layers and are usually FFN-heavy. This sparse structure is operationally useful: training only the discovered subnetwork recovers nearly the same performance as full \textsc{OPD}. However, the sparsity-inducing SGD optimizer underperforms AdamW in our optimizer ablation, likely because dense teacher supervision preserves heterogeneous coordinate-wise gradient scales where AdamW's adaptive scaling remains useful. On geometry, the updates are numerically full-rank but spectrally concentrated; they lie mostly away from the principal singular subspaces of the source weights and fall disproportionately on coordinates where the source weights are close to zero. These findings suggest that dense teacher supervision does not turn \textsc{OPD} into ordinary dense parameter rewriting; instead, \textsc{OPD} retains important geometric signatures of on-policy post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes parameter updates under on-policy distillation (OPD) across several language and vision-language model pairs. It reports that OPD produces small, coordinate-sparse updates that are distributed across layers and FFN-heavy; these updates are numerically full-rank but spectrally concentrated, lie away from the principal singular subspaces of the source weights, and disproportionately affect coordinates where source weights are near zero. An optimizer ablation finds that the sparsity-inducing SGD underperforms AdamW. The central interpretation is that dense teacher supervision does not convert OPD into ordinary dense rewriting but preserves geometric signatures of on-policy post-training. Training only the discovered sparse subnetwork is claimed to recover nearly the same performance as full OPD.
Significance. If the reported sparsity patterns and geometric signatures hold and generalize, the work would provide a mechanistic explanation for OPD's behavior and could guide the design of sparse or subnetwork-based post-training procedures that retain on-policy benefits while reducing compute.
major comments (2)
- [Abstract] Abstract: the claim that 'training only the discovered subnetwork recovers nearly the same performance as full OPD' is presented without any quantitative metrics, error bars, dataset details, or exclusion criteria, so the degree of support for the operational usefulness of the sparse structure cannot be assessed.
- [Abstract] Abstract: the central interpretation that OPD 'retains important geometric signatures of on-policy post-training' rests on patterns observed in a handful of model pairs; no results or discussion address whether the coordinate-sparsity, FFN-heavy distribution, spectral concentration, or near-zero-weight preference persist under different scales, architectures, or task distributions, which is load-bearing for the claim that the patterns are not artifacts of the chosen setups.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'training only the discovered subnetwork recovers nearly the same performance as full OPD' is presented without any quantitative metrics, error bars, dataset details, or exclusion criteria, so the degree of support for the operational usefulness of the sparse structure cannot be assessed.
Authors: We agree that the abstract would benefit from additional quantitative detail to support this claim. The full manuscript reports specific performance metrics on the evaluated benchmarks and datasets, including comparisons between full OPD and subnetwork training. We will revise the abstract to incorporate key quantitative results (e.g., relative performance recovery percentages), reference the datasets, and note any error bars or exclusion criteria from our experiments. revision: yes
-
Referee: [Abstract] Abstract: the central interpretation that OPD 'retains important geometric signatures of on-policy post-training' rests on patterns observed in a handful of model pairs; no results or discussion address whether the coordinate-sparsity, FFN-heavy distribution, spectral concentration, or near-zero-weight preference persist under different scales, architectures, or task distributions, which is load-bearing for the claim that the patterns are not artifacts of the chosen setups.
Authors: We acknowledge that our analysis covers a selection of model pairs and that we do not present explicit experiments testing persistence across arbitrary scales, architectures, or task distributions. The interpretation is based on the consistent patterns observed in the reported setups. We will add a discussion paragraph qualifying the empirical scope of the findings and noting that broader validation would strengthen the claim that the signatures are not setup-specific artifacts. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivation chain
full rationale
The paper reports direct experimental observations on sparsity (coordinate-sparse, FFN-heavy updates) and geometry (spectrally concentrated, away from principal subspaces, on near-zero weights) of OPD updates in language and vision-language models. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing claims appear in the provided text. All central claims rest on measured patterns from the experiments themselves, with no reduction to inputs by construction. This is a standard non-circular empirical analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pp. 21246–21263,
2024
-
[2]
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer
URLhttps://arxiv.org/abs/2502.13923. Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28,
-
[3]
URLhttps://arxiv.org/abs/2510.00553. DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence,
-
[4]
Chongyu Fan, Gaowen Liu, Mingyi Hong, Ramana Rao Kompella, and Sijia Liu
URLhttps://huggingface.co/deepseek-ai/DeepSeek-V4-Pro. Chongyu Fan, Gaowen Liu, Mingyi Hong, Ramana Rao Kompella, and Sijia Liu. Rethinking muon beyond pretraining: Spectral failures and high-pass remedies for vla and rlvr.arXiv preprint arXiv:2605.19282,
-
[5]
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, train- able neural networks.arXiv preprint arXiv:1803.03635,
-
[6]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, volume 2024, pp. 32694–32717,
2024
-
[7]
Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178,
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178,
-
[8]
10 Preprint. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[9]
Justrl: Scaling a 1.5 b llm with a simple rl recipe.arXiv preprint arXiv:2512.16649,
Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, et al. Justrl: Scaling a 1.5 b llm with a simple rl recipe.arXiv preprint arXiv:2512.16649,
-
[10]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531,
-
[11]
Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
-
[12]
Rein- forcement learning via self-distillation.arXiv preprint arXiv:2601.20802,
Jonas H ¨ubotter, Frederike L¨ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Rein- forcement learning via self-distillation.arXiv preprint arXiv:2601.20802,
-
[13]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089,
-
[14]
Yoon Kim and Alexander M Rush
URL https://kellerjordan.github.io/posts/muon/. Yoon Kim and Alexander M Rush. Sequence-level knowledge distillation. InProceedings of the 2016 conference on empirical methods in natural language processing, pp. 1317–1327,
2016
-
[15]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[16]
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distilla- tion of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016,
-
[17]
Muon is scalable for llm training.arXiv preprint arXiv:2502.16982,
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982,
-
[18]
Parameter-efficient orthogonal finetuning via butterfly factorization
Weiyang Liu, Zeju Qiu, Yao Feng, Yuliang Xiu, Yuxuan Xue, Longhui Yu, Haiwen Feng, Zhen Liu, Juyeon Heo, Songyou Peng, et al. Parameter-efficient orthogonal finetuning via butterfly factorization. InInternational Conference on Learning Representations, volume 2024, pp. 38317–38350,
2024
-
[19]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
-
[20]
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng
11 Preprint. Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. Reinforcement learning finetunes small subnetworks in large language models.Advances in Neural Information Processing Systems, 38:132119–132138, 2026a. Sagnik Mukherjee, Lifan Yuan, Pavan Jayasinha, Dilek Hakkani-T ¨ur, and Hao Peng. Do we need adam? surprisingly strong and sparse...
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
doi: 10.64434/tml.20250929. https://thinkingmachines.ai/blog/lora/. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.64434/tml.20250929
-
[22]
Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259,
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259,
-
[23]
A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
-
[24]
Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
-
[25]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
-
[26]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[27]
On-policy context distillation for language models.arXiv preprint arXiv:2602.12275,
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275,
-
[28]
Glm-5: from vibe coding to agentic engineer- ing.arXiv preprint arXiv:2602.15763,
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineer- ing.arXiv preprint arXiv:2602.15763,
-
[29]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
-
[30]
The path not taken: Rlvr provably learns off the principals.arXiv preprint arXiv:2511.08567,
Hanqing Zhu, Zhenyu Zhang, Hanxian Huang, DiJia Su, Zechun Liu, Jiawei Zhao, Igor Fedorov, Hamed Pirsiavash, Zhizhou Sha, Jinwon Lee, et al. The path not taken: Rlvr provably learns off the principals.arXiv preprint arXiv:2511.08567,
-
[31]
12 Preprint. A Appendix A.1 Related work On-policy distillation.Early OPD formulations emphasize the exposure-mismatch prob- lem in offline distillation and train the student on its own sampled trajectories with dense teacher feedback (Agarwal et al., 2024; Gu et al., 2024). Recent work shows that this idea has become a practical post-training component f...
2024
-
[32]
Both OPD styles differ from SEQKD by training on student-generated trajectories, and differ from RLVR by replacing sparse scalar rewards with dense teacher-derived feedback
Thus, if k1 is detached and −k1(a; c) is used as the policy- gradient advantage, the score-function loss LPG(a; c) =sg[k 1(a; c)]logπ θ(a|c) has gradient k1(a; c)∇θ logπ θ(a|c) , giving an unbiased single-sample estimator of the reverse-KL gra- dient up to practical modifications such as clipping, off-policy importance ratios, and advantage normalization....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.