Formalizing and Mitigating Structural Distortion in LLM Attention for Graph Reasoning
Pith reviewed 2026-06-27 04:04 UTC · model grok-4.3
The pith
Rotary embeddings cause attention decay between graph-adjacent nodes forced far apart in linearized sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
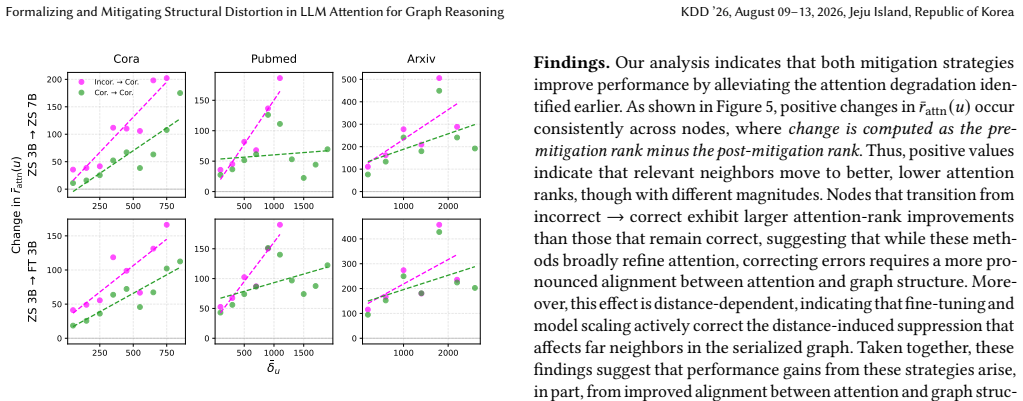
Rotary positional embeddings turn graph linearization into bandwidth-dependent attention decay, suppressing attention between graph-adjacent nodes that are forced far apart in the serialized sequence. GaLA biases attention toward graph-adjacent nodes while preserving the LLM's sequential inductive biases.
What carries the argument
Graph-aligned Language Attention (GaLA), an inference-time attention bias that increases scores for graph neighbors identified from the input graph.
If this is right
- Performance on text-attributed graph benchmarks improves while adding almost no inference overhead.
- LLM-based graph reasoning can shift focus from prompt engineering toward attention realignment.
- The distortion created by serialization plus rotary embeddings is presented as a correctable bottleneck rather than an inherent limit.
- GaLA works by preserving the original model's sequential inductive biases.
Where Pith is reading between the lines
- The same decay pattern could appear in other ordered structures such as molecular graphs or parse trees once they are serialized.
- GaLA might be adapted to other positional embedding families beyond rotary ones.
- The method assumes the graph structure is known at inference time and supplied as input.
- Testing whether the bias correction remains effective when graphs contain cycles or high-degree nodes would be a direct next measurement.
Load-bearing premise
The primary performance degradation in LLM graph reasoning stems from the interaction of rotary embeddings with linearization order rather than from prompt design, model scale, or tokenization choices.
What would settle it
A controlled test that varies only the linearization order or replaces rotary embeddings and shows the performance gap disappears without any attention bias would falsify the distortion claim.
Figures



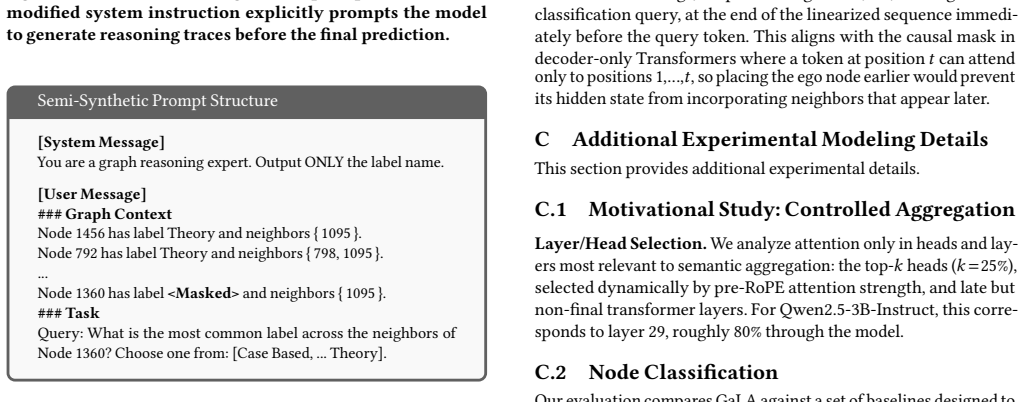

read the original abstract
Large Language Models (LLMs) have shown promise for reasoning over Text-Attributed Graphs (TAGs). However, applying LLMs to graphs requires linearizing their structure into sequences, introducing distortion rooted in the graph bandwidth problem. While this distortion has been shown to degrade performance, it is often attributed to prompt design or model scale, leaving the underlying mechanism unclear. In this work, we show \textit{how} rotary positional embeddings turn graph linearization into bandwidth-dependent attention decay, suppressing attention between graph-adjacent nodes that are forced far apart in the serialized sequence. This shifts the focus of LLM-based graph reasoning from prompt engineering and scaling toward correcting attention misalignment. Motivated by this analysis, we propose \textbf{G}raph-\textbf{a}ligned \textbf{L}anguage \textbf{A}ttention (\textbf{GaLA}), a lightweight, inference-time modification for LLMs. GaLA biases attention toward graph-adjacent nodes while preserving the LLM's sequential inductive biases. Across TAG benchmarks, GaLA improves performance with negligible overhead, demonstrating that distortion is a correctable bottleneck in LLM-based graph reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that rotary positional embeddings cause bandwidth-dependent attention decay when graphs are linearized into sequences for LLMs on Text-Attributed Graphs, suppressing attention between graph-adjacent nodes placed far apart in the sequence. This mechanism is positioned as the root cause of performance degradation (distinct from prompt design or scale), and the authors introduce GaLA, an inference-time attention bias toward graph neighbors that yields gains on TAG benchmarks with negligible overhead.
Significance. If the RoPE-linearization mechanism is shown to be primary and GaLA's improvements are attributable to it, the work supplies a concrete, low-cost correction for a structural bottleneck in LLM graph reasoning and could redirect research emphasis toward attention alignment rather than prompt engineering or scaling.
major comments (1)
- [Experiments] The experiments do not isolate whether the RoPE-linearization interaction is the dominant degradation driver. No ablations are reported that hold linearization order fixed while varying positional embedding type (RoPE versus absolute embeddings) or that optimize serialization for low bandwidth; without these controls the claim that this interaction, rather than prompt design, tokenization, or model scale, is primary remains unverified and is load-bearing for the motivation and conclusions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental isolation. We address the concern point by point below and outline planned revisions.
read point-by-point responses
-
Referee: The experiments do not isolate whether the RoPE-linearization interaction is the dominant degradation driver. No ablations are reported that hold linearization order fixed while varying positional embedding type (RoPE versus absolute embeddings) or that optimize serialization for low bandwidth; without these controls the claim that this interaction, rather than prompt design, tokenization, or model scale, is primary remains unverified and is load-bearing for the motivation and conclusions.
Authors: We agree that the current experiments lack the precise controls needed to fully isolate the RoPE-linearization interaction as the dominant factor. Section 3 provides a theoretical derivation showing bandwidth-dependent attention decay that is specific to rotary embeddings (via the angle rotation formula), which does not apply identically to absolute embeddings. Empirical results then show GaLA recovers performance by counteracting this decay. However, we did not report ablations that fix serialization order while swapping embedding types or that explicitly optimize for minimal bandwidth. In revision we will add these ablations, including RoPE versus absolute positional embeddings under identical linearization and a low-bandwidth serialization baseline, to strengthen verification that the interaction is primary rather than attributable to prompt design, tokenization, or scale. revision: yes
Circularity Check
No circularity; derivation chain self-contained with no reductions to fits or self-citations
full rationale
The provided abstract and description contain no equations, parameter fits, or derivations that reduce the claimed RoPE-linearization mechanism to a quantity defined by the same data or by self-citation. The central claim is presented as an observational analysis motivating GaLA, without any self-definitional, fitted-input, or uniqueness-imported steps visible. No load-bearing self-citations or ansatzes are quoted. This matches the default expectation that most papers exhibit no circularity when no explicit reduction can be exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Federico Barbero, Alex Vitvitskyi, Christos Perivolaropoulos, Razvan Pascanu, and Petar Veličković. 2025. Round and Round We Go! What makes Rotary Positional Encodings useful?. InThe Thirteenth International Conference on Learning Representations (ICLR)
2025
-
[2]
Andrei Broder, Ravi Kumar, Farzin Maghoul, Prabhakar Raghavan, Sridhar Rajagopalan, Raymie Stata, Andrew Tomkins, and Janet Wiener. 2000. Graph structure in the Web.Computer Networks33, 1 (2000), 309–320
2000
-
[3]
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. 2024. LLaGA: large language and graph assistant. In41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 306, 15 pages
2024
-
[4]
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, and Jiliang Tang. 2024. Exploring the Potential of Large Language Models (LLMs)in Learning on Graphs.SIGKDD Explor. Newsl.25, 2 (March 2024), 42–61
2024
-
[5]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. What Does BERT Look at? An Analysis of BERT’s Attention. InProceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Association for Computational Linguistics, 276–286
2019
-
[6]
Cuthill and J
E. Cuthill and J. McKee. 1969. Reducing the bandwidth of sparse symmetric matri- ces. InProceedings of the 1969 24th National Conference (ACM ’69). ACM, 157–172
1969
-
[7]
Vijay Prakash Dwivedi and Xavier Bresson. 2021. A Generalization of Transformer Networks to Graphs.AAAI Workshop on Deep Learning on Graphs: Methods and Applications(2021)
2021
-
[8]
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. 2024. Talk like a graph: Encoding graphs for large language models. InInternational Conference on Learning Representations (ICLR)
2024
- [9]
-
[10]
Yoav Goldberg. 2016. A primer on neural network models for natural language processing.J. Artif. Int. Res.57, 1 (Sept. 2016), 345–420
2016
-
[11]
Zhong Guan, Likang Wu, Hongke Zhao, Ming He, and Jianping Fan. 2025. At- tention Mechanisms Perspective: Exploring LLM Processing of Graph-Structured Data. InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). PMLR, 20612–20639. https://proceedings.mlr.press/v267/guan25e.html
2025
-
[12]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., 1025–1035
2017
-
[13]
Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. 2024. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning. InInternational Conference on Learning Representations (ICLR)
2024
-
[14]
Zhongmou He, Jing Zhu, Shengyi Qian, Joyce Chai, and Danai Koutra. 2025. LinkGPT: Leveraging Large Language Models for Enhanced Link Prediction in Text-Attributed Graphs. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM). ACM, 843–853
2025
-
[15]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations (ICLR)
2022
-
[16]
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, and Liang Zhao. 2025. GRAG: Graph Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics: NAACL 2025. ACL, 4145–4157
2025
- [17]
-
[18]
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. 2024. Understanding the planning of LLM agents: A survey. arXiv:2402.02716 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [19]
-
[20]
Pengcheng Jiang, Cao Xiao, Zifeng Wang, Parminder Bhatia, Jimeng Sun, and Jiawei Han. 2024. TriSum: Learning Summarization Ability from Large Language Models with Structured Rationale. InNorth American Chapter of the Association for Computational Linguistics. https://aclanthology.org/2024.naacl-long.154/
2024
-
[21]
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. 2023. The impact of positional encoding on length generalization in transformers. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Article 1082, 37 pages
2023
-
[22]
Jiho Kim, Yeonsu Kwon, Yohan Jo, and Edward Choi. 2023. KG-GPT: A General Framework for Reasoning on Knowledge Graphs Using Large Language Models. InFindings of the Association for Computational Linguis- tics: EMNLP 2023. Association for Computational Linguistics, 9410–9421. https://aclanthology.org/2023.findings-emnlp.631/
2023
-
[23]
Thomas N Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InInternational Conference on Learning Representations (ICLR)
2017
- [24]
-
[25]
Linden, B
G. Linden, B. Smith, and J. York. 2003. Amazon.com recommendations: item-to-item collaborative filtering.IEEE Internet Computing7, 1 (2003), 76–80
2003
-
[26]
Yixin Liu, Kejian Shi, Katherine He, Longtian Ye, Alexander Fabbri, Pengfei Liu, Dragomir Radev, and Arman Cohan. 2024. On Learning to Summarize with Large Language Models as References. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). ...
2024
-
[27]
Zheyuan Liu, Xiaoxin He, Yijun Tian, and Nitesh V. Chawla. 2024. Can we Soft Prompt LLMs for Graph Learning Tasks?. InCompanion Proceedings of the ACM Web Conference 2024 (WWW ’24). ACM, 481–484. doi:10.1145/3589335.3651476
-
[28]
Donald Loveland, Yao-An Yang, and Danai Koutra. 2026. Glance for Context: Learning When to Leverage LLMs for Node-Aware GNN-LLM Fusion. InThe Fourteenth International Conference on Learning Representations (ICLR)
2026
-
[29]
Donald Loveland, Jiong Zhu, Mark Heimann, Benjamin Fish, Michael T Schaub, and Danai Koutra. 2024. On performance discrepancies across local homophily levels in graph neural networks. InLearning on Graphs Conference. PMLR, 6–1
2024
-
[30]
Jiaji Ma, Puja Trivedi, and Danai Koutra. 2026. GRAPHTEXTACK: A Realistic Black-Box Node Injection Attack on LLM-Enhanced GNNs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 24244–24252
2026
-
[31]
Yuchun Miao, Sen Zhang, Liang Ding, Yuqi Zhang, Lefei Zhang, and Dacheng Tao
-
[32]
InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol
The Energy Loss Phenomenon in RLHF: A New Perspective on Mitigating Reward Hacking. InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). PMLR, 44076–44105
-
[33]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. InAdvances in Neural Information Processing Systems, Vol. 26
2013
-
[34]
Galileo Mark Namata, Ben London, Lise Getoor, , and Bert Huang. 2012. Query-Driven Active Surveying for Collective Classification. InInternational Workshop on Mining and Learning with Graphs
2012
-
[35]
M. E. J. Newman. 2001. The structure of scientific collaboration networks. Proceedings of the National Academy of Sciences98, 2 (2001), 404–409
2001
-
[36]
Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. 2016. Learning Convolutional Neural Networks for Graphs. InProceedings of The 33rd Interna- tional Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 48). PMLR, 2014–2023. https://proceedings.mlr.press/v48/niepert16.html
2016
-
[37]
Ladislav Rampášek, Mikhail Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. 2022. Recipe for a General, Powerful, Scalable Graph Transformer.Advances in Neural Information Processing Systems35 (2022)
2022
-
[38]
Mathieu Ravaut, Aixin Sun, Nancy Chen, and Shafiq Joty. 2024. On Context Utilization in Summarization with Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2764–2781. https://aclanthology.org/2024.acl-long.153/
2024
-
[39]
Franz Rendl, Renata Sotirov, and Christian Truden. 2021. Lower bounds for the bandwidth problem.Computers and Operations Research135 (2021), 105422
2021
-
[40]
Prithviraj Sen, Galileo Mark Namata, Mustafa Bilgic, Lise Getoor, Brian Gallagher, and Tina Eliassi-Rad. 2008. Collective Classification in Network Data.AI Magazine 29, 3 (2008), 93–106
2008
- [41]
-
[42]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. RoFormer: Enhanced transformer with Rotary Position Embedding. Neurocomput.568, C (Feb. 2024), 12 pages
2024
-
[43]
Yuanfu Sun, Zhengnan Ma, Yi Fang, Jing Ma, and Qiaoyu Tan. 2025. GraphICL: Unlocking Graph Learning Potential in LLMs through Structured Prompt Design. InFindings of the Association for Computational Linguistics: NAACL 2025. ACL, 2440–2459
2025
-
[44]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. GraphGPT: Graph Instruction Tuning for Large Language Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). ACM, 491–500
2024
-
[45]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., 6000–6010
2017
-
[46]
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. ACL, 5797–5808
2019
-
[47]
Kuansan Wang, Zhihong Shen, Chiyuan Huang, Chieh-Han Wu, Yuxiao Dong, and Anshul Kanakia. 2020. Microsoft Academic Graph: When experts are not enough.Quantitative Science Studies1, 1 (02 2020), 396–413. Formalizing and Mitigating Structural Distortion in LLM Attention for Graph Reasoning KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea
2020
- [48]
-
[49]
Rossi, Namyong Park, Nesreen K
Yu Wang, Ryan A. Rossi, Namyong Park, Nesreen K. Ahmed, Danai Koutra, Franck Dernoncourt, and Tyler Derr. 2025. Demystifying the Power of Large Language Models in Graph Generation. InFindings of the Association for Computational Linguistics: NAACL 2025 (Findings of ACL). ACL, 8174–8189
2025
- [50]
-
[51]
Yujun Yan, Milad Hashemi, Kevin Swersky, Yaoqing Yang, and Danai Koutra
-
[52]
In2022 IEEE International Conference on Data Mining (ICDM)
Two Sides of the Same Coin: Heterophily and Oversmoothing in Graph Convolutional Neural Networks. In2022 IEEE International Conference on Data Mining (ICDM). 1287–1292
-
[53]
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. 2024. Language is All a Graph Needs. InFindings of the Association for Computational Linguistics: EACL 2024. ACL, 1955–1973
2024
-
[54]
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. 2021. Do Transformers Really Perform Badly for Graph Representation?. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., 28877–28888
2021
-
[55]
Yuxin You, Zhen Liu, Xiangchao Wen, Yongtao Zhang, and Wei Ai. 2025. Large language models meet graph neural networks: a perspective of graph mining. Mathematics13, 7 (2025), 1147
2025
-
[56]
Songlin Yu, Nian Ran, and Jianjun Liu. 2024. Large-language models: The game- changers for materials science research.Artificial Intelligence Chemistry2, 2 (2024), 100076. https://www.sciencedirect.com/science/article/pii/S2949747724000344
2024
-
[57]
Mengmei Zhang, Mingwei Sun, Peng Wang, Shen Fan, Yanhu Mo, Xiaoxiao Xu, Hong Liu, Cheng Yang, and Chuan Shi. 2024. GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks. InProceedings of the ACM Web Conference 2024(Singapore, Singapore)(WWW ’24). ACM, 1003–1014
2024
-
[58]
Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Pan, and Lidong Bing. 2024. Sentiment Analysis in the Era of Large Language Models: A Reality Check. InFindings of the Association for Computational Linguistics: NAACL 2024. Association for Computational Linguistics, 3881–3906
2024
-
[59]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[60]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. arXiv:2506.05176 [cs.CL] https://arxiv.org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv
- [61]
- [62]
-
[63]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, and Qing Li. 2024. Recommender Sys- tems in the Era of Large Language Models (LLMs).IEEE Transactions on Knowledge and Data Engineering36, 11 (Nov. 2024), 6889–6907. doi:10.1109/tkde.2024.3392335 A Theoretical Analysis A.1 Derivation of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.