RepNN: Tackling spectral bias in deep neural networks via parameter reparameterization
Pith reviewed 2026-06-27 04:24 UTC · model grok-4.3
The pith
Reparameterizing weights and biases in the first hidden layer lets DNNs adaptively scale frequencies to capture high oscillations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
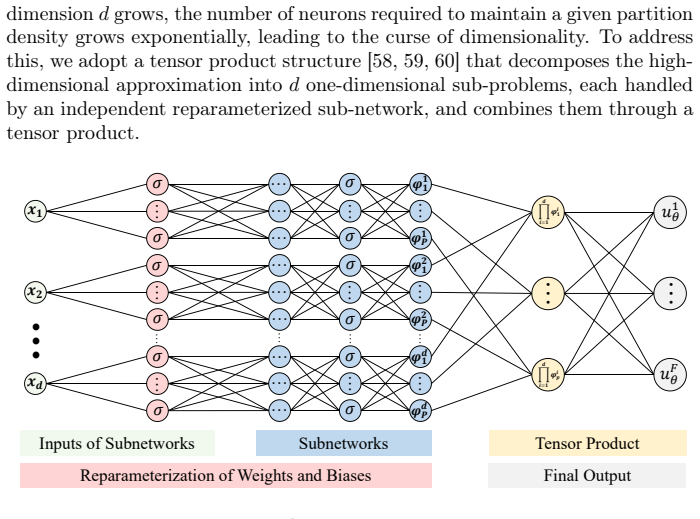
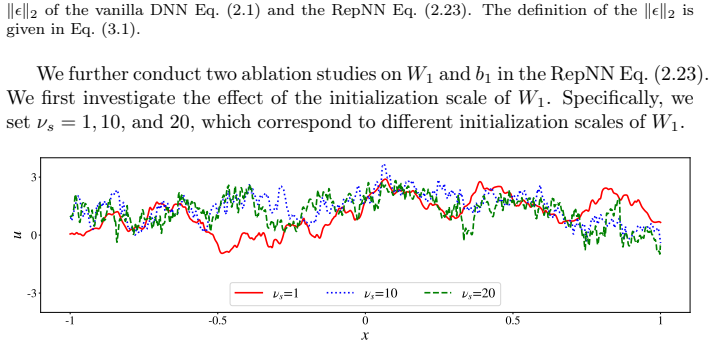
RepNN reparameterizes the weights and biases in the first hidden layer of a DNN (ReLU or tanh). This reparameterization directly controls the initial slope scale and supplies a suitable distribution of initial partition points. Treating the reparameterized parameters as trainable enables the network to perform adaptive frequency scaling throughout training. The authors also supply quantitative bounds on output and slope magnitudes to guide initialization of the reparameterized model.
What carries the argument
Reparameterization of the weights and biases in the first hidden layer, which sets initial slope scale and partition-point distribution so that frequency scaling becomes adaptive during training.
If this is right
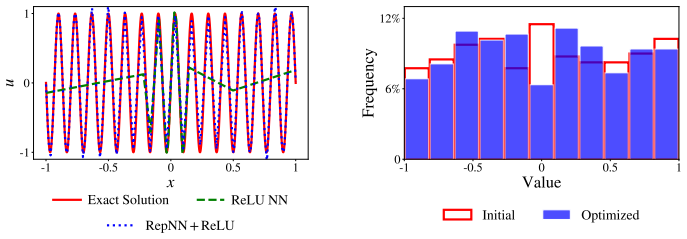
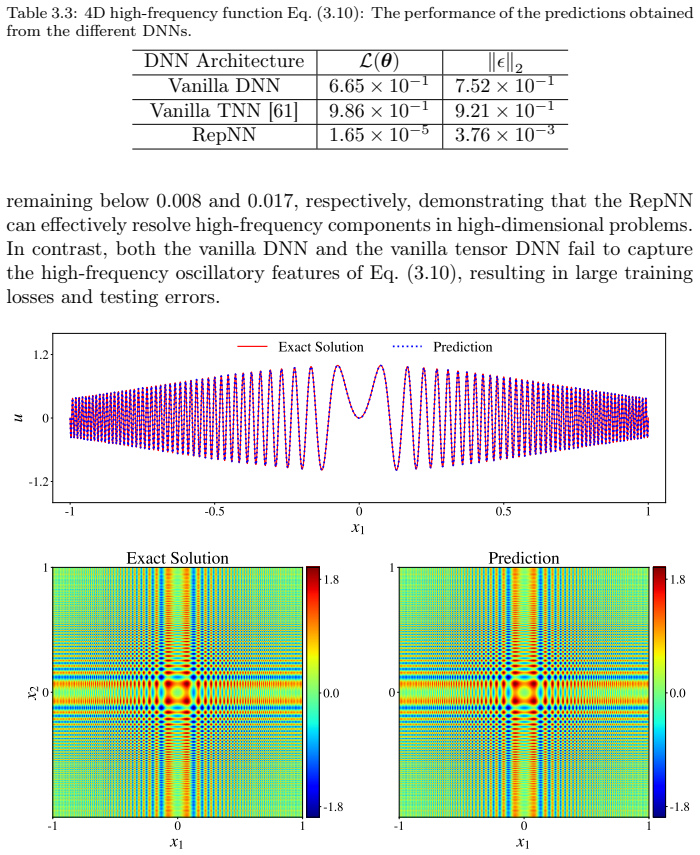
- RepNN raises accuracy on one- and four-dimensional multiscale function approximation tasks.
- When used inside PINNs it improves both forward and inverse solutions of PDEs that contain rapid oscillations.
- It raises accuracy on operator-learning tasks such as earthquake modeling with real data.
- The added cost is only slight compared with a standard DNN of the same size.
- The same reparameterization works for both ReLU and tanh activations.
Where Pith is reading between the lines
- The same first-layer reparameterization might be applied to other activations or combined with Fourier-feature input encodings.
- Adaptive frequency scaling could reduce the need for manual frequency tuning in scientific machine-learning workflows.
- If the two factors identified here truly dominate, similar reparameterizations applied to later layers might further mitigate residual bias.
- The initialization bounds derived for the reparameterized layer could be used to set hyperparameters in other frequency-aware architectures.
Load-bearing premise
The initial slope scale and partition-point distribution that cause failure in shallow ReLU nets are also the dominant sources of spectral bias that remain in deeper networks and multiscale scientific tasks.
What would settle it
A side-by-side experiment in which RepNN and a vanilla DNN are trained on the same high-frequency target function and RepNN shows no accuracy gain would falsify the central claim.
Figures














read the original abstract
Deep neural networks (DNNs) have achieved remarkable success in scientific computing, yet they often suffer from spectral bias in capturing oscillatory and multiscale behaviors. In this study, we investigate this limitation by examining the failure of shallow ReLU neural networks in fitting high-frequency functions. This observation identifies two important factors in resolving rapid oscillations: the initial slope scale and the distribution of partition points induced by the networks. Motivated by this analysis, we propose RepNN, a reparameterized neural network model with activation ReLU or tanh designed for high-frequency and multiscale problems. The key idea is to reparameterize the weights and biases in the first hidden layer, which enables effective control of the initial slope scale and provides an appropriate distribution of the initial partition points. Furthermore, treating the reparameterized weights and biases as trainable parameters allows the DNN to achieve adaptive frequency scaling during training. In addition, we derive quantitative estimates for the output and slope magnitudes of the reparameterized DNN to guide the initialization of the proposed method. Numerical experiments, including multiscale one- and four-dimensional function approximations, forward and inverse PDE problems in combination with physics-informed neural networks (PINNs), and operator learning for an earthquake problem using real data, demonstrate that RepNN improves the predicted accuracy of vanilla DNNs in capturing highly oscillatory features with slightly additional computational cost. These results indicate that RepNN provides an effective and flexible approach for overcoming spectral bias and applying DNNs to multiscale problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that analyzing the failure of shallow ReLU networks on high-frequency targets reveals two key factors (initial slope scale and partition-point distribution); reparameterizing only the first hidden layer's weights and biases as trainable parameters (RepNN, with ReLU or tanh) controls these factors, enables adaptive frequency scaling, and overcomes spectral bias. Quantitative initialization estimates are derived, and the approach is tested on multiscale 1D/4D function approximation, forward/inverse PINN PDE problems, and real-data operator learning for an earthquake problem, showing accuracy gains over vanilla DNNs at modest extra cost.
Significance. If the central claim holds, RepNN supplies a simple, low-overhead architectural change that improves DNN performance on oscillatory and multiscale scientific tasks without altering network depth or requiring new activations. The experiments span synthetic functions, PINNs, and real-data operator learning, which would strengthen its relevance for physics-informed and data-driven modeling if the first-layer reparameterization is shown to remain rate-limiting in the deeper architectures actually employed.
major comments (2)
- [§2] §2 (shallow-network failure analysis): the motivation rests on identifying initial slope scale and partition-point distribution as the dominant causes of spectral bias in shallow ReLU nets, yet the subsequent RepNN construction and all reported experiments use deeper networks; no diagnostic (e.g., layer-wise frequency spectra or ablation of first-layer vs. later-layer contributions) is supplied to verify that these two first-layer quantities remain the rate-limiting step once depth increases, as opposed to NTK spectrum or composition effects in deeper layers.
- [§3] §3 (RepNN definition and adaptive scaling claim): the assertion that treating the reparameterized first-layer parameters as trainable 'allows the DNN to achieve adaptive frequency scaling during training' is not accompanied by any intermediate verification (e.g., evolution of effective frequencies or slope magnitudes) in the deeper PINN and operator-learning architectures; without such evidence the extrapolation from the shallow-case diagnosis remains untested.
minor comments (1)
- [Abstract, §4] The abstract and §4 would benefit from explicit statement of network depths, widths, and hyper-parameter selection protocol used in the PINN and operator-learning experiments to allow reproduction of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which highlight important aspects of the motivation and empirical validation. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§2] §2 (shallow-network failure analysis): the motivation rests on identifying initial slope scale and partition-point distribution as the dominant causes of spectral bias in shallow ReLU nets, yet the subsequent RepNN construction and all reported experiments use deeper networks; no diagnostic (e.g., layer-wise frequency spectra or ablation of first-layer vs. later-layer contributions) is supplied to verify that these two first-layer quantities remain the rate-limiting step once depth increases, as opposed to NTK spectrum or composition effects in deeper layers.
Authors: We agree that the failure analysis in §2 is conducted on shallow ReLU networks while the experiments employ deeper architectures. The first-layer reparameterization is motivated by the observation that this layer controls the initial slope scale and partition-point distribution, which subsequent layers then compose. However, the manuscript does not include explicit layer-wise diagnostics or ablations to confirm that the first layer remains rate-limiting in deeper networks. In the revised version we will add an ablation study isolating the first-layer contribution and include layer-wise frequency content analysis on representative deeper-network experiments to address this point. revision: yes
-
Referee: [§3] §3 (RepNN definition and adaptive scaling claim): the assertion that treating the reparameterized first-layer parameters as trainable 'allows the DNN to achieve adaptive frequency scaling during training' is not accompanied by any intermediate verification (e.g., evolution of effective frequencies or slope magnitudes) in the deeper PINN and operator-learning architectures; without such evidence the extrapolation from the shallow-case diagnosis remains untested.
Authors: The adaptive-frequency-scaling claim follows directly from making the reparameterized first-layer weights and biases trainable, which permits them to adjust during optimization. The current manuscript presents only end-point accuracy improvements rather than intermediate trajectories of effective frequencies or slopes. We acknowledge that this leaves the dynamic adaptation mechanism less directly verified in the deeper architectures. In revision we will include plots or tables tracking the evolution of the reparameterized parameters (and derived effective frequencies) for selected PINN and operator-learning cases to provide the requested intermediate verification. revision: yes
Circularity Check
Reparameterization is an explicit architectural change with trainable parameters; no reduction to inputs by construction
full rationale
The derivation begins with an analysis of shallow ReLU failure modes (initial slope scale and partition-point distribution), then introduces a reparameterization of the first hidden layer whose weights/biases are explicitly treated as trainable. This construction does not equate any claimed prediction or frequency-scaling result to a fitted constant or self-citation by the paper's own equations; the adaptive behavior arises from gradient-based optimization on the new parameters rather than definitional equivalence. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation appear in the abstract or described chain. The central claim therefore remains independent of its inputs and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Failure of shallow ReLU networks on high-frequency functions is primarily due to initial slope scale and distribution of partition points.
Reference graph
Works this paper leans on
-
[1]
Yu, et al., The deep ritz method: a deep learning-based numerical al- gorithm for solving variational problems, Communications in Mathematics and Statistics 6 (1) (2018) 1–12
B. Yu, et al., The deep ritz method: a deep learning-based numerical al- gorithm for solving variational problems, Communications in Mathematics and Statistics 6 (1) (2018) 1–12
2018
-
[2]
Z. Hu, K. Shukla, G. E. Karniadakis, K. Kawaguchi, Tackling the curse of dimensionality with physics-informed neural networks, Neural Networks 176 (2024) 106369.doi:10.1016/j.neunet.2024.106369
-
[3]
Z. Li, N. Kovachki, K. Azizzadenesheli, et al., Fourier neural operator for parametric partial differential equations (2021).arXiv:2010.08895
Pith/arXiv arXiv 2021
-
[5]
L. Lu, P. Jin, G. Pang, et al., Learning nonlinear operators via deeponet based on the universal approximation theorem of operators, Nature machine intelligence 3 (3) (2021) 218–229.doi:10.1038/ s42256-021-00302-5
2021
-
[6]
F. M. Amin, D. W. Abueidda, P. Pantidis, M. E. Mobasher, I-fenn with deeponets: Accelerating simulations in coupled multiphysics problems, Computer Methods in Applied Mechanics and Engineering 451 (2026) 118645.doi:10.1016/j.cma.2025.118645
-
[7]
C. Song, Y. Wang, Simulating seismic multifrequency wavefields with the fourier feature physics-informed neural network, Geophysical Journal In- ternational 232 (3) (2022) 1503–1514.doi:10.1093/gji/ggac399
-
[8]
H. Geng, C. Song, U. bin Waheed, C. Liu, Seismic first-arrival traveltime simulation based on reciprocity-constrained pinn, Journal of Applied Geo- physics 243 (2025) 105967.doi:10.1016/j.jappgeo.2025.105967
-
[9]
Zanardi, S
I. Zanardi, S. Venturi, M. Panesi, Adaptive physics-informed neural op- erator for coarse-grained non-equilibrium flows, Scientific Reports 13 (1) (2023) 15497
2023
-
[10]
S. Zhang, C. Zhang, B. Wang, Crk-pinn: A physics-informed neu- ral network for solving combustion reaction kinetics ordinary differential equations, Combustion and Flame 269 (2024) 113647.doi:10.1016/j. combustflame.2024.113647
work page doi:10.1016/j 2024
-
[11]
J. Zheng, H. Hu, J. Huang, B. Zhao, H. Huang, Cf-deeponet: Deep opera- tor neural networks for solving compressible flows, Aerospace Science and Technology 163 (2025) 110329.doi:10.1016/j.ast.2025.110329. 37
-
[12]
Z. Zhang, K. Shukla, Z. Wang, et al., Turbulence closure in reynolds- averaged navier–stokes and flow inference around a cylinder using physics- informed neural networks and sparse experimental data, Journal of Fluid Mechanics 1034 (2026) A16.doi:10.1017/jfm.2026.11471
-
[13]
Rahaman, A
N. Rahaman, A. Baratin, D. Arpit, et al., On the spectral bias of neural networks, in: K. Chaudhuri, R. Salakhutdinov (Eds.), Proceedings of the 36th International Conference on Machine Learning, Vol. 97 of Proceedings of Machine Learning Research, PMLR, 2019, pp. 5301–5310
2019
-
[15]
T. Luo, Z. Ma, Z.-Q. J. Xu, Y. Zhang, Theory of the frequency principle for general deep neural networks (2019).arXiv:1906.09235
Pith/arXiv arXiv 2019
-
[16]
Z.-Q. J. Xu, Y. Zhang, T. Luo, Overview frequency principle/spectral bias in deep learning, Communications on Applied Mathematics and Computa- tion 7 (3) (2025) 827–864
2025
-
[17]
S. Khodakarami, V. Oommen, N. A. Daryakenari, M. Beekenkamp, G. E. Karniadakis, Spectral bias in physics-informed and operator learning: Analysis and mitigation guidelines, arXiv:2602.19265 (2026)
arXiv 2026
-
[18]
W. Cai, X. Li, L. Liu, A phase shift deep neural network for high frequency approximation and wave problems, SIAM Journal on Scientific Computing 42 (5) (2020) A3285–A3312.doi:10.1137/19M1310050
-
[19]
Y. Kim, S. Kim, I. Seo, B. Shin, Phase-shifted adversarial training, in: R. J. Evans, I. Shpitser (Eds.), Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, Vol. 216 of Proceedings of Machine Learning Research, PMLR, 2023, pp. 1068–1077
2023
-
[20]
Hu, Neutron resonance cross sections evaluation based on the phase shift deep neural network, in: EPJ Web of Conferences, Vol
Z. Hu, Neutron resonance cross sections evaluation based on the phase shift deep neural network, in: EPJ Web of Conferences, Vol. 302, EDP Sciences, 2024, p. 07002
2024
-
[21]
Tancik, P
M. Tancik, P. Srinivasan, B. Mildenhall, et al., Fourier features let networks learn high frequency functions in low dimensional domains, Advances in Neural Information Processing Systems 33 (2020) 7537–7547
2020
-
[22]
Z. Liu, W. Cai, Z. J. Xu, Multi-scale deep neural network (mscalednn) for solving poisson-boltzmann equation in complex domains, Communications in Computational Physics 28 (5) (2020) 1970–2001.doi:10.4208/cicp. OA-2020-0179. 38
-
[23]
S. Wang, H. Wang, P. Perdikaris, On the eigenvector bias of fourier fea- ture networks: From regression to solving multi-scale pdes with physics- informed neural networks, Computer Methods in Applied Mechanics and Engineering 384 (2021) 113938.doi:10.1016/j.cma.2021.113938
-
[24]
Y. Wang, Y. Yao, J. Guo, Z. Gao, A practical pinn framework for multi- scale problems with multi-magnitude loss terms, Journal of Computational Physics 510 (2024) 113112.doi:10.1016/j.jcp.2024.113112
-
[25]
J. Huang, R. You, T. Zhou, Frequency-adaptive multi-scale deep neural networks, Computer Methods in Applied Mechanics and Engineering 437 (2025) 117751.doi:10.1016/j.cma.2025.117751
-
[26]
X. Feng, T. Tang, X. Wan, T. Zhou, Overcoming spectral bias via cross- attention (2025).arXiv:2512.18586
arXiv 2025
-
[27]
Y. Chen, B. Dong, J. Xu, Meta-mgnet: Meta multigrid networks for solv- ing parameterized partial differential equations, Journal of Computational Physics 455 (2022) 110996.doi:10.1016/j.jcp.2022.110996
-
[28]
Zhang, A
E. Zhang, A. Kahana, A. Kopaničáková, et al., Blending neural operators and relaxation methods in pde numerical solvers, Nature Machine Intelli- gence 6 (11) (2024) 1303–1313
2024
-
[29]
Z. Aldirany, R. Cottereau, M. Laforest, S. Prudhomme, Multi-level neu- ral networks for accurate solutions of boundary-value problems, Com- puter Methods in Applied Mechanics and Engineering 419 (2024) 116666. doi:10.1016/j.cma.2023.116666
-
[30]
X.-A. Li, Z.-Q. J. Xu, L. Zhang, Subspace decomposition based dnn algo- rithm for elliptic type multi-scale pdes, Journal of Computational Physics 488 (2023) 112242.doi:10.1016/j.jcp.2023.112242
-
[31]
S. Li, Y. Xia, Y. Liu, Q. Liao, A deep domain decomposition method based on fourier features, Journal of Computational and Applied Mathematics 423 (2023) 114963.doi:10.1016/j.cam.2022.114963
-
[32]
S. Wang, S. Sankaran, X. Fan, et al., Simulating three-dimensional turbu- lence with physics-informed neural networks (2025).arXiv:2507.08972
arXiv 2025
-
[33]
Z. Li, Y. Wang, H. Liu, et al., Solving the boltzmann equation with a neural sparse representation, SIAM Journal on Scientific Computing 46 (2) (2024) C186–C215.doi:10.1137/23M1558227
-
[34]
Y. Chen, D. Wang, D. Feng, et al., Three-dimensional spatiotemporal wind fieldreconstructionbasedonlidarandmulti-scalepinn, AppliedEnergy377 (2025) 124577.doi:10.1016/j.apenergy.2024.124577
-
[35]
N. Chen, S. Wang, R. Ma, et al., Enforcing hidden physics in physics- informed neural networks (2025).arXiv:2511.14348. 39
arXiv 2025
-
[36]
P. Xie, Y. Liu, C. Liu, et al., Simultaneous suppression of seismic random and erratic noise using pinn with high-frequency preservation, Journal of Geophysics and Engineering 22 (6) (2025) 1796–1808
2025
-
[37]
Sitzmann, J
V. Sitzmann, J. Martel, A. Bergman, et al., Implicit neural representa- tions with periodic activation functions, Advances in Neural Information Processing Systems 33 (2020) 7462–7473
2020
-
[38]
Q. Hong, J. W. Siegel, Q. Tan, J. Xu, On the activation function depen- dence of the spectral bias of neural networks, arXiv:2208.04924 (2022)
arXiv 2022
-
[39]
Q. Huang, M. Fang, D. Cheng, et al., Sparse-regularized high-frequency enhanced neural network for solving high-frequency problems, Journal of Computational Physics 523 (2025) 113676.doi:10.1016/j.jcp.2024. 113676
- [40]
-
[41]
J. Huang, R. You, T. Zhou, Frequency-adaptive tensor neural networks for high-dimensional multi-scale problems (2025).arXiv:2508.15198
Pith/arXiv arXiv 2025
-
[42]
S. Wang, H. Wang, J. H. Seidman, P. Perdikaris, Random weight factor- ization improves the training of continuous neural representations (2022). arXiv:2210.01274
arXiv 2022
-
[43]
X. Xiong, K. Lu, Z. Zhang, et al., High-frequency flow field super-resolution via physics-informed hierarchical adaptive fourier feature networks, Physics of Fluids 37 (9) (2025) 097111.doi:10.1063/5.0286561
-
[44]
Y. Tang, L. Huang, L. Wu, X. Meng, Multiscale lubrication simulation based on fourier feature networks with trainable frequency (2024).arXiv: 2405.12638
arXiv 2024
-
[45]
A.Khademi, S.Dufour, Physics-informedneuralnetworkswithtrainablesi- nusoidal activation functions for approximating the solutions of the navier- stokes equations, Computer Physics Communications 314 (2025) 109672. doi:10.1016/j.cpc.2025.109672
-
[46]
Y. Liu, H. Gu, X. Yu, P. Qin, Diminishing spectral bias in physics-informed neural networks using spatially-adaptive fourier feature encoding, Neural Networks 182 (2025) 106886.doi:10.1016/j.neunet.2024.106886
-
[47]
B.-Y. Hou, Y.-L. Bai, X.-T. Jing, C. lin Huang, Fourier feature-enhanced multi-layer residual stacking network: A novel multiscale modeling ap- proach for physics-informed neural networks, Neural Networks 195 (2026) 108247.doi:10.1016/j.neunet.2025.108247
-
[48]
J. He, L. Li, J. Xu, C. Zheng, Relu deep neural networks and linear finite elements, Journal of Computational Mathematics 38 (3) (2020) 502–527. 40
2020
-
[49]
K. He, X. Zhang, S. Ren, J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, in: Proceedings of the IEEE international conference on computer vision, 2015, pp. 1026–1034
2015
-
[50]
Glorot, Y
X. Glorot, Y. Bengio, Understanding the difficulty of training deep feed- forward neural networks, in: Proceedings of the thirteenth international conference on artificial intelligence and statistics, JMLR Workshop and Conference Proceedings, 2010, pp. 249–256
2010
-
[51]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization (2017). arXiv:1412.6980
Pith/arXiv arXiv 2017
-
[52]
R. H. Byrd, P. Lu, J. Nocedal, C. Zhu, A limited memory algorithm for bound constrained optimization, SIAM Journal on Scientific Computing 16 (5) (1995) 1190–1208.doi:10.1137/0916069
-
[53]
I. Babuska, B. A. Szabo, I. N. Katz, The p-version of the finite element method, SIAM Journal on Numerical Analysis 18 (3) (1981) 515–545.doi: 10.1137/0718033
-
[54]
J. Chen, X. Xiao, X. Feng, D. Sheen, A level set immersed finite element method for parabolic problems on surfaces with moving interfaces, Journal of Computational Physics 531 (2025) 113939.doi:10.1016/j.jcp.2025. 113939
-
[55]
T. Cheng, L. Ju, Z. Qiao, X. Zhang, Generalized transferable neural networks for steady-state partial differential equations, arXiv preprint arXiv:2604.03020 (2026)
Pith/arXiv arXiv 2026
-
[56]
T. Tang, J. Yang, Y. Zhao, Y. Zhao, Structured first-layer initializa- tion pre-training techniques to accelerate training process based onε- rank, Communications in Computational Physics 40 (1) (2026) 61–87. doi:10.4208/cicp.OA-2025-0185
-
[57]
M. Raissi, P. Perdikaris, G. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems in- volving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707.doi:10.1016/j.jcp.2018.10.045
-
[58]
Novikov, D
A. Novikov, D. Podoprikhin, A. Osokin, D. P. Vetrov, Tensorizing neural networks, Advances in neural information processing systems 28 (2015)
2015
-
[59]
E. Newman, L. Horesh, H. Avron, M. Kilmer, Stable tensor neural networks for rapid deep learning (2018).arXiv:1811.06569
Pith/arXiv arXiv 2018
-
[60]
Y. Wang, Z. Lin, Y. Liao, et al., Solving high-dimensional partial differen- tial equations using tensor neural network and a posteriori error estimators, Journal of Scientific Computing 101 (3) (2024) 67. 41
2024
-
[61]
Y. Wang, H. Xie, Tensor neural network and its numerical integration, Journal of Computational Mathematics 42 (2024) 1714–1742.doi:10. 4208/jcm.2307-m2022-0233
2024
-
[62]
Q. Ma, X. Jiang, J. Jia, Regularized numerical method for the space- fractional logarithmic klein-gordon equation, Computers&Mathematics with Applications 203 (2026) 41–55.doi:10.1016/j.camwa.2025.11.025
-
[63]
S. Wang, Y. Teng, P. Perdikaris, Understanding and mitigating gradient flow pathologies in physics-informed neural networks, SIAM Journal on Sci- entific Computing 43 (5) (2021) A3055–A3081.doi:10.1137/20M1318043
-
[64]
F. Ren, S. Wang, P.-Z. Zhuang, et al., General fourier feature physics- informed extreme learning machine (gff-pielm) for high-frequency pdes (2025).arXiv:2510.12293
arXiv 2025
-
[65]
Y. Yang, F. Wang, Adaptive-distribution randomized neural networks for pdes: A low-dimensional distribution-learning framework (2026).arXiv: 2604.23999
Pith/arXiv arXiv 2026
-
[66]
P. Zhao, R. Wang, T. Wu, Y. Xu, The adaptive solution of high-frequency helmholtz equations via multi-grade deep learning (2026).arXiv:2602. 20719
2026
-
[67]
T. A. Driscoll, N. Hale, L. N. Trefethen, Chebfun guide (2014)
2014
-
[68]
L. Liu, K. Nath, W. Cai, A causality-deeponet for causal responses of linear dynamical systems, Communications in Computational Physics 35 (2024) 1194–1228.doi:10.4208/cicp.OA-2023-0078
-
[69]
N. Vyas, D. Morwani, R. Zhao, et al., Soap: Improving and stabilizing shampoo using adam for language modeling, in: Y. Yue, A. Garg, N. Peng, F. Sha, R. Yu (Eds.), International Conference on Learning Representa- tions, Vol. 2025, 2025, pp. 93423–93444
2025
-
[70]
Q. Lin, C. Zhang, X. Meng, Z. Guo, Monte carlo physics-informed neural networks for multiscale heat conduction via phonon boltzmann transport equation, Journal of Computational Physics 542 (2025) 114364.doi:10. 1016/j.jcp.2025.114364. 42
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.