Expanding SPHERE-JEPA: A Family of Statistical Regularizers for the Hypersphere
Pith reviewed 2026-06-27 01:57 UTC · model grok-4.3
The pith
Analytically integrating random projections turns sliced hypersphere regularizers into deterministic MMD, KSD and KL objectives that stabilize SSL training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
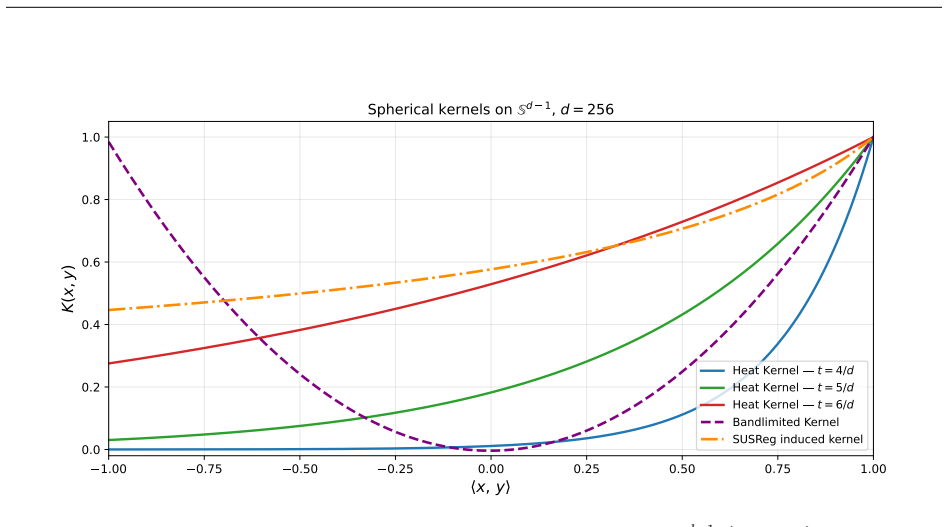
Analytically integrating the random projections that underlie sliced regularizers recovers the continuous uniform objective on the hypersphere as a deterministic maximum mean discrepancy. This equivalence motivates the construction of full-dimensional MMD, kernel Stein discrepancy, and Kullback-Leibler objectives equipped with rotationally invariant kernels obtained from heat or bandlimited spectral filters. The resulting regularizers remove projection-induced gradient variance, produce more stable optimization trajectories, and yield measurable gains over stochastic sliced baselines on ImageNet and Galaxy10, while the choice of divergence determines whether the learned latent space organize
What carries the argument
Deterministic full-dimensional MMD obtained by exact integration of random projections, extended to KSD and KL with rotationally invariant spectral kernels (Heat and Bandlimited).
If this is right
- Training becomes more stable because projection sampling variance is eliminated from the gradients.
- Convergence occurs in fewer epochs on both ImageNet and Galaxy10.
- MMD and KSD regularizers induce locally clustered organization in the latent space.
- The continuous KL divergence induces fine-grained instance separation instead of clustering.
- Performance gains are consistent across the two evaluated datasets when the deterministic objectives replace sliced ones.
Where Pith is reading between the lines
- The same integration technique could be applied to other sliced discrepancies on manifolds beyond the hypersphere.
- Task-specific selection of the divergence (clustered versus separated geometry) may improve transfer performance without changing the encoder architecture.
- Hybrid objectives that combine MMD and KL terms could be tested to balance local clustering with global separation.
Load-bearing premise
The closed-form integration of the random projections exactly recovers the continuous uniform objective on the sphere without new biases or artifacts that would change downstream gradients.
What would settle it
A controlled experiment on a known uniform distribution on the sphere in which the deterministic MMD gradients produce measurably higher variance or slower convergence than the sliced version.
Figures




read the original abstract
In Self-Supervised Learning (SSL), preventing representation collapse by explicitly enforcing a uniform distribution on the unit hypersphere has proven to be effective. However, current frameworks typically rely on sliced statistical regularizers such as SIGReg (used in LeJEPA) and SUSReg (used in SPHERE-JEPA), which approximate this continuous objective via Monte Carlo sampling along random 1D directions. This stochasticity injects projection variance into the training gradients, destabilizing optimization, and hindering convergence. In this work, we first show that analytically integrating out these random projections natively yields a deterministic Maximum Mean Discrepancy (MMD), bypassing the variance of sliced methods. Motivated by this equivalence, we formulate full-dimensional objectives for MMD, Kernel Stein Discrepancy (KSD), and Kullback-Leibler (KL) divergence directly on the sphere to enforce a uniform distribution. To prevent spatial bias, we equip these tests with rotationally invariant kernels constructed via spectral theory, systematically evaluating two canonical families: smooth exponential decay (Heat) and strict frequency cutoff (Bandlimited) filters. Empirically, removing projection-induced noise results in more stable optimization, faster convergence, and consistent improvements over stochastic sliced regularizers on ImageNet and Galaxy10. Furthermore, we reveal that the choice of the statistical test shapes the geometry of the learned latent space: MMD and KSD favor locally clustered organization suitable for object-centric domains, whereas the continuous KDE-based KL divergence promotes fine-grained instance separation, yielding the strongest results on unclustered procedural texture retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that analytically integrating out the random projections in sliced statistical regularizers (SIGReg, SUSReg) for enforcing uniformity on the unit hypersphere yields exact deterministic equivalents to MMD (and likewise KSD, KL), enabling full-dimensional objectives equipped with rotationally invariant kernels (Heat and Bandlimited families) that eliminate projection-induced gradient variance; the resulting methods are reported to yield more stable optimization, faster convergence, and consistent gains over stochastic baselines on ImageNet and Galaxy10, while the choice of divergence is shown to control latent-space geometry (clustered for MMD/KSD, instance-separated for KL).
Significance. If the claimed exact equivalence holds without introducing bias or altering the underlying objective, the work would supply a family of deterministic, parameter-light regularizers that remove a known source of training instability in hyperspherical SSL; the empirical demonstration on two distinct datasets and the geometry-control observation would then constitute a practical and conceptual advance over existing sliced approaches.
major comments (2)
- [Abstract and §3] Abstract and §3 (theoretical development): the central claim that analytic integration of the random 1D projections exactly recovers the continuous uniform MMD (and KSD/KL) objective without new approximation artifacts is asserted but not accompanied by the integration steps, the resulting closed-form expression, or a verification that the deterministic gradient equals the expectation of the Monte-Carlo sliced gradient; this equivalence is load-bearing for the motivation that reported stability gains arise solely from noise removal.
- [§4 and §5] §4 and §5 (experiments): the manuscript reports consistent improvements on ImageNet and Galaxy10 yet supplies neither the precise dataset sizes, the full list of baselines with their hyper-parameters, nor error bars across multiple runs; without these, it is impossible to assess whether the gains are robust or sensitive to post-hoc choices.
minor comments (2)
- Notation for the two kernel families (Heat vs. Bandlimited) should be introduced with explicit spectral definitions before their use in the objectives.
- The abstract states that the choice of statistical test shapes latent-space geometry; a quantitative metric (e.g., clustering purity or nearest-neighbor retrieval) should be reported to support this qualitative observation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate clarifications and additional details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (theoretical development): the central claim that analytic integration of the random 1D projections exactly recovers the continuous uniform MMD (and KSD/KL) objective without new approximation artifacts is asserted but not accompanied by the integration steps, the resulting closed-form expression, or a verification that the deterministic gradient equals the expectation of the Monte-Carlo sliced gradient; this equivalence is load-bearing for the motivation that reported stability gains arise solely from noise removal.
Authors: We agree the derivation steps should be more explicit. Section 3 derives the equivalence by integrating the sliced MMD over the uniform measure on the sphere, yielding the closed-form full-dimensional MMD with the rotationally invariant kernel; the same holds for KSD and KL. The gradient equivalence follows because the deterministic objective is exactly the expectation of the sliced estimator. In revision we will expand the integration steps, state the closed-form expressions, and include the short verification that the deterministic gradient equals the Monte-Carlo expectation. revision: yes
-
Referee: [§4 and §5] §4 and §5 (experiments): the manuscript reports consistent improvements on ImageNet and Galaxy10 yet supplies neither the precise dataset sizes, the full list of baselines with their hyper-parameters, nor error bars across multiple runs; without these, it is impossible to assess whether the gains are robust or sensitive to post-hoc choices.
Authors: We agree these details are required for reproducibility. The revision will report exact dataset sizes (ImageNet-1k: 1.28M training images; Galaxy10: 17,736 images), the complete baseline list with all hyperparameters, and error bars computed over 3 independent runs with different random seeds for each method. revision: yes
Circularity Check
No circularity: analytical equivalence derived in-manuscript; empirical gains independent of fitted inputs
full rationale
The paper states it derives the key equivalence ('we first show that analytically integrating out these random projections natively yields a deterministic Maximum Mean Discrepancy') within the present manuscript rather than importing it via self-citation or definition. The full-dimensional MMD/KSD/KL objectives are then motivated by that derivation and equipped with rotationally invariant kernels via spectral theory. Performance claims on ImageNet/Galaxy10 are reported as experimental outcomes of removing projection variance, not as predictions forced by parameters fitted on the same data. No load-bearing step reduces by construction to its own inputs, and self-citations to prior SPHERE-JEPA work are not used to justify the central equivalence or uniqueness.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stat , volume=
Closed-form expressions for maximum mean discrepancy with applications to Wasserstein auto-encoders , author=. Stat , volume=. 2021 , publisher=
2021
-
[2]
Advances in Neural Information Processing Systems , volume=
Statistical and topological properties of sliced probability divergences , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Generalized sliced probability metrics , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[4]
Proceedings of the 37th International Conference on Machine Learning , pages =
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[5]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[6]
2019 , eprint=
Representation Learning with Contrastive Predictive Coding , author=. 2019 , eprint=
2019
-
[7]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[8]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[9]
2019 , eprint=
Spreading vectors for similarity search , author=. 2019 , eprint=
2019
-
[10]
2025 , eprint=
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics , author=. 2025 , eprint=
2025
-
[11]
T. W. Epps and Lawrence B. Pulley , journal =. A Test for Normality Based on the Empirical Characteristic Function , urldate =
-
[12]
Mhaskar, H. N. and Narcowich, F. J. and Ward, J. D. , title =. Mathematics of Computation , year =
-
[13]
Narcowich, F. J. and Sun, X. and Ward, J. D. and Wendland, H. , title =. Foundations of Computational Mathematics , year =
-
[14]
Cuesta-Albertos, J. A. and Fraiman, R. and Ransford, T. , title =. Journal of Theoretical Probability , year =
-
[15]
Datta, Ritendra and Joshi, Dhiraj and Li, Jia and Wang, James Z. , title =. ACM Comput. Surv. , month = may, articleno =. 2008 , issue_date =. doi:10.1145/1348246.1348248 , abstract =
-
[16]
Chikuse.Statistics on Special Manifolds
Statistics on Special Manifolds , author =. 2003 , isbn =. doi:10.1007/978-0-387-21540-2 , pages =
-
[17]
James , journal =
Alan T. James , journal =. Zonal Polynomials of the Real Positive Definite Symmetric Matrices , urldate =
-
[18]
1982 , isbn =
Aspects of Multivariate Statistical Theory , author =. 1982 , isbn =
1982
-
[19]
A tutorial on non central Wishart distributions , year =
Letac, Gérard and Massam, H. A tutorial on non central Wishart distributions , year =
-
[20]
2019 , eprint=
A Bayesian Approach for Analyzing Data on the Stiefel Manifold , author=. 2019 , eprint=
2019
-
[21]
2026 , eprint=
SPHERE-JEPA: Spherical Prediction with Homogeneous Embeddings , author=. 2026 , eprint=
2026
-
[22]
Linear Algebra and its Applications , volume =
On the largest principal angle between random subspaces , author =. Linear Algebra and its Applications , volume =. 2006 , doi =
2006
-
[23]
2025 , eprint=
Theory and Applications of Kernel Stein's Method on Riemannian Manifolds , author=. 2025 , eprint=
2025
-
[24]
and Rasch, Malte J
Gretton, Arthur and Borgwardt, Karsten M. and Rasch, Malte J. and Sch\". A kernel two-sample test , year =. J. Mach. Learn. Res. , month = mar, pages =
-
[25]
International conference on machine learning , pages=
A kernelized Stein discrepancy for goodness-of-fit tests , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[26]
Kullback and R
S. Kullback and R. A. Leibler , journal =. On Information and Sufficiency , urldate =
-
[27]
Random Features for Large-Scale Kernel Machines , url =
Rahimi, Ali and Recht, Benjamin , booktitle =. Random Features for Large-Scale Kernel Machines , url =
-
[29]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
ImageNet: A Large-Scale Hierarchical Image Database , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[31]
Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E. , title =. Commun. ACM , month = may, pages =. 2017 , issue_date =. doi:10.1145/3065386 , abstract =
-
[32]
P. E. Jupp , title =. The Annals of Statistics , number =. 2008 , doi =
2008
-
[33]
2012 , doi =
Kendall Atkinson and Weimin Han , title =. 2012 , doi =
2012
-
[34]
Thinplate splines on the sphere , author=. SIGMA. Symmetry, Integrability and Geometry: Methods and Applications , volume=. 2018 , publisher=
2018
-
[35]
The Annals of statistics , volume=
Invariant tests for uniformity on compact Riemannian manifolds based on Sobolev norms , author=. The Annals of statistics , volume=. 1975 , publisher=
1975
-
[36]
I. J. Schoenberg , title =. Duke Mathematical Journal , number =. 1942 , doi =
1942
-
[37]
SIAM Journal on Scientific and Statistical Computing , volume=
Spline interpolation and smoothing on the sphere , author=. SIAM Journal on Scientific and Statistical Computing , volume=. 1981 , publisher=
1981
-
[38]
2025 , eprint=
KerJEPA: Kernel Discrepancies for Euclidean Self-Supervised Learning , author=. 2025 , eprint=
2025
-
[40]
Alessandro Barp and Chris. J. Oates and Emilio Porcu and Mark Girolami , title =. Bernoulli , number =. 2022 , doi =
2022
-
[41]
International Conference on Artificial Intelligence and Statistics , pages=
A Stein goodness-of-fit test for directional distributions , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[42]
Proceedings of The 33rd International Conference on Machine Learning , pages =
A Kernel Test of Goodness of Fit , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[43]
R. Balestriero and Y. LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics, 2025. URL https://arxiv.org/abs/2511.08544
Pith/arXiv arXiv 2025
-
[44]
A. Barp, C. J. Oates, E. Porcu, and M. Girolami. A Riemann–Stein kernel method . Bernoulli, 28 0 (4): 0 2181 -- 2208, 2022. doi:10.3150/21-BEJ1415. URL https://doi.org/10.3150/21-BEJ1415
-
[45]
R. K. Beatson, W. Zu Castell, et al. Thinplate splines on the sphere. SIGMA. Symmetry, Integrability and Geometry: Methods and Applications, 14: 0 083, 2018
2018
-
[46]
Caron, H
M. Caron, H. Touvron, I. Misra, H. J \'e gou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650--9660, 2021
2021
-
[47]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597--1607. PmLR, 2020
2020
-
[48]
Chwialkowski, H
K. Chwialkowski, H. Strathmann, and A. Gretton. A kernel test of goodness of fit. In M. F. Balcan and K. Q. Weinberger, editors, Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 2606--2615, New York, New York, USA, 20--22 Jun 2016. PMLR. URL https://proceedings.mlr.press/v48...
2016
-
[49]
J. A. Cuesta-Albertos, R. Fraiman, and T. Ransford. A sharp form of the C ram\'er-- W old theorem. Journal of Theoretical Probability, 2007
2007
-
[50]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009
2009
-
[51]
T. W. Epps and L. B. Pulley. A test for normality based on the empirical characteristic function. Biometrika, 70 0 (3): 0 723--726, 1983. ISSN 00063444. URL http://www.jstor.org/stable/2336512
arXiv 1983
-
[52]
E. Gin \'e . Invariant tests for uniformity on compact riemannian manifolds based on sobolev norms. The Annals of statistics, 3 0 (6): 0 1243--1266, 1975
1975
-
[53]
Gretton, K
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch\" o lkopf, and A. Smola. A kernel two-sample test. J. Mach. Learn. Res., 13 0 (null): 0 723–773, Mar. 2012. ISSN 1532-4435
2012
-
[54]
Grill, F
J.-B. Grill, F. Strub, F. Altch \'e , C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33: 0 21271--21284, 2020
2020
-
[55]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
2016
-
[56]
P. E. Jupp. Data-driven Sobolev tests of uniformity on compact Riemannian manifolds . The Annals of Statistics, 36 0 (3): 0 1246 -- 1260, 2008. doi:10.1214/009053607000000541. URL https://doi.org/10.1214/009053607000000541
-
[57]
Kolouri, K
S. Kolouri, K. Nadjahi, S. Shahrampour, and U. S im s ekli. Generalized sliced probability metrics. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4513--4517. IEEE, 2022
2022
-
[58]
S. Kullback and R. A. Leibler. On information and sufficiency. The Annals of Mathematical Statistics, 22 0 (1): 0 79--86, 1951. ISSN 00034851. URL http://www.jstor.org/stable/2236703
arXiv 1951
-
[59]
H. W. Leung and J. Bovy. Deep learning of multi-element abundances from high-resolution spectroscopic data. Monthly Notices of the Royal Astronomical Society, Nov. 2018. ISSN 1365-2966. doi:10.1093/mnras/sty3217. URL http://dx.doi.org/10.1093/mnras/sty3217
-
[60]
Q. Liu, J. Lee, and M. Jordan. A kernelized stein discrepancy for goodness-of-fit tests. In International conference on machine learning, pages 276--284. PMLR, 2016
2016
-
[61]
Nadjahi, A
K. Nadjahi, A. Durmus, L. Chizat, S. Kolouri, S. Shahrampour, and U. Simsekli. Statistical and topological properties of sliced probability divergences. Advances in Neural Information Processing Systems, 33: 0 20802--20812, 2020
2020
-
[62]
L. Nicollier, M. Dunitz, M. Pic, P. Musé, E. Meinhardt-Llopis, and G. Facciolo. Sphere-jepa: Spherical prediction with homogeneous embeddings, 2026. URL https://arxiv.org/abs/2605.26900
arXiv 2026
- [63]
-
[64]
Rahimi and B
A. Rahimi and B. Recht. Random features for large-scale kernel machines. In J. Platt, D. Koller, Y. Singer, and S. Roweis, editors, Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007. URL https://proceedings.neurips.cc/paper_files/paper/2007/file/013a006f03dbc5392effeb8f18fda755-Paper.pdf
2007
-
[65]
R. M. Rustamov. Closed-form expressions for maximum mean discrepancy with applications to wasserstein auto-encoders. Stat, 10 0 (1): 0 e329, 2021
2021
-
[66]
A. Sablayrolles, M. Douze, C. Schmid, and H. Jégou. Spreading vectors for similarity search, 2019. URL https://arxiv.org/abs/1806.03198
arXiv 2019
-
[67]
I. J. Schoenberg. Positive definite functions on spheres . Duke Mathematical Journal, 9 0 (1): 0 96 -- 108, 1942. doi:10.1215/S0012-7094-42-00908-6. URL https://doi.org/10.1215/S0012-7094-42-00908-6
-
[68]
G. Wahba. Spline interpolation and smoothing on the sphere. SIAM Journal on Scientific and Statistical Computing, 2 0 (1): 0 5--16, 1981
1981
-
[69]
Xu and T
W. Xu and T. Matsuda. A stein goodness-of-fit test for directional distributions. In International Conference on Artificial Intelligence and Statistics, pages 320--329. PMLR, 2020
2020
-
[70]
C. Zhao and J. S. Song. Exact heat kernel on a hypersphere and its applications in kernel svm. Frontiers in Applied Mathematics and Statistics, 4, Jan. 2018. ISSN 2297-4687. doi:10.3389/fams.2018.00001. URL http://dx.doi.org/10.3389/fams.2018.00001
-
[71]
E. Zimmermann, H. Wiltzer, J. Szeto, D. Alvarez-Melis, and L. Mackey. Kerjepa: Kernel discrepancies for euclidean self-supervised learning, 2025. URL https://arxiv.org/abs/2512.19605
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.