PACT: Preserving Anchored Cores in Task-vectors for Model Merging
Pith reviewed 2026-06-26 21:55 UTC · model grok-4.3
The pith
Task vectors overlook critical knowledge anchored in pre-trained weights, and aligning their orthogonal complements with the base subspace before merging resolves conflicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Load-Bearing Wall dimensions are the task-critical knowledge that remains embedded in pre-trained weights rather than fully transferring into task vectors. Aligning the orthogonal complements of these dimensions with the subspace of the pre-trained weights and removing the resulting components from the task vectors before merging allows standard algorithms to avoid damaging task-specific knowledge and to reduce conflicts, producing consistent gains across benchmarks.
What carries the argument
Load-Bearing Wall (LBW) dimensions, task-critical knowledge remaining in pre-trained weights, preserved by aligning their orthogonal complements with the pre-trained subspace and removing those aligned components from task vectors before merging.
If this is right
- Existing model merging methods gain performance when the PACT preprocessing step is added.
- Randomized SVD gives an efficient version that scales without changing the accuracy gains.
- The method integrates directly with any task-vector-based merging algorithm.
- Performance improvements hold across multiple standard benchmarks for model merging.
Where Pith is reading between the lines
- The same alignment step could be tested on merging methods that operate directly on weights rather than task vectors.
- LBW dimensions may offer a diagnostic tool for measuring how strongly pre-training imprints task preferences.
- Checking whether the subspace alignment still works when task vectors come from instruction-tuned rather than classification-tuned models would test generality.
Load-bearing premise
LBW dimensions exist as identifiable task-critical knowledge in pre-trained weights, and removing their aligned components from task vectors will not damage other useful knowledge or create new conflicts.
What would settle it
Running the merging experiments with the aligned LBW components left in the task vectors and obtaining equal or better performance than the version that removes them would falsify the central claim.
Figures

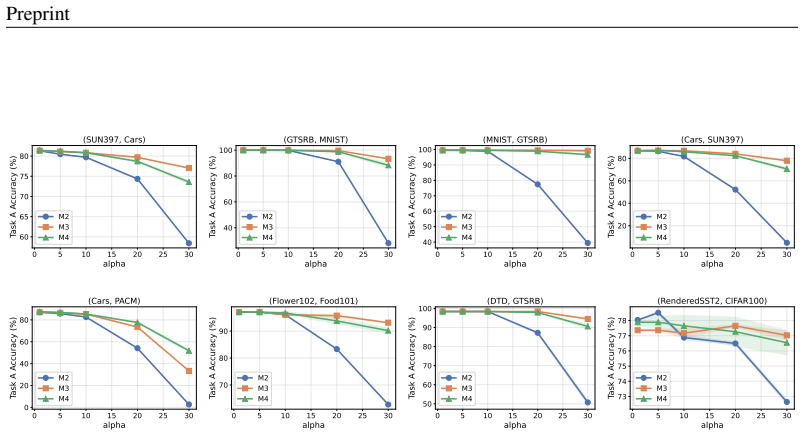
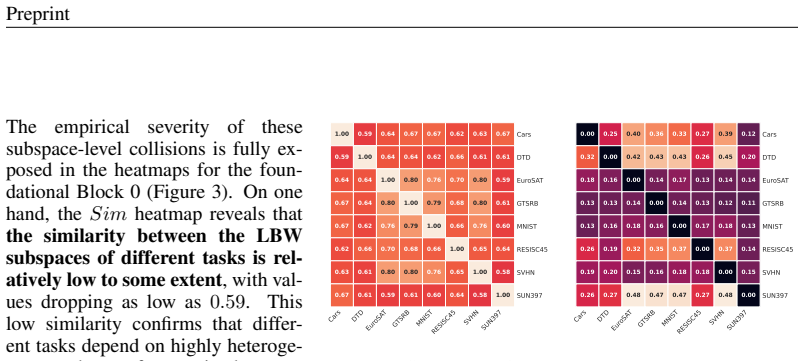

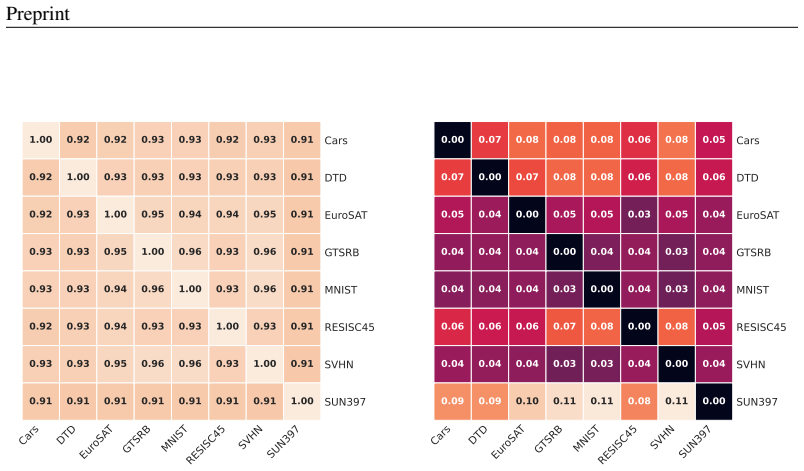
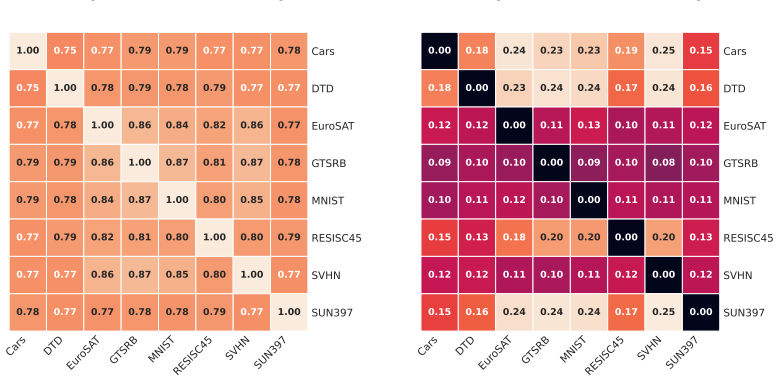





read the original abstract
Model merging has emerged as a training-free alternative to multi-task learning, aiming to combine multiple task-specific fine-tuned models into a single multi-task model. Most existing model merging approaches follow the Task Arithmetic paradigm, which decomposes fine-tuned weights into pre-trained parameters and task vectors, and performs merging exclusively in the task-vector space. The effectiveness of this paradigm implicitly relies on the assumption that task-specific knowledge is encoded solely within task vectors. We argue that this assumption generally does not hold due to the intrinsic task preferences of pre-trained models. Specifically, we identify \textbf{Load-Bearing Wall (LBW) dimensions}, namely some task-critical knowledge that remains embedded in the pre-trained weights rather than being fully transferred into task vectors. We characterize LBW dimensions from both scalar-weight and subspace perspectives, thereby covering the major paradigms of existing model merging methods. Our analysis reveals that, by ignoring LBW dimensions, task-vector-based approaches fail to fully resolve task conflicts and may inadvertently damage task-specific knowledge encoded in the pre-trained model, leading to degradation. To address this issue, we propose PACT, which preserves the anchored task-specific cores (i.e., LBW dimensions) within task vectors by aligning their orthogonal complements with the subspace of the pre-trained weights. These aligned subspace components are then removed from the task vectors before applying existing model merging algorithms. Furthermore, we develop an efficient variant based on randomized SVD to improve scalability. PACT can be seamlessly integrated with existing methods. Extensive experiments across multiple benchmarks demonstrate that PACT consistently enhances mainstream model merging approaches and establishes new state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the Task Arithmetic paradigm for model merging is limited because task-specific knowledge is not fully captured in task vectors; instead, some task-critical knowledge remains in the pre-trained weights as Load-Bearing Wall (LBW) dimensions. These are characterized from scalar-weight and subspace perspectives. PACT is proposed as a preprocessing step that aligns the orthogonal complements of task vectors with the pre-trained weight subspace, removes the aligned components from the task vectors, and then applies existing merging algorithms. An efficient randomized SVD variant is also introduced. Experiments are said to show consistent gains and new state-of-the-art results across benchmarks.
Significance. If the LBW characterization is valid and the alignment/removal step demonstrably preserves task knowledge without introducing new conflicts, the work would meaningfully extend the model merging literature by relaxing a core assumption of task-vector-only methods. The plug-in nature of PACT and the scalability variant are practical strengths that could see adoption if the gains hold under controlled ablations.
major comments (2)
- [Abstract] Abstract: The central claim that ignoring LBW dimensions 'may inadvertently damage task-specific knowledge encoded in the pre-trained model' is load-bearing, yet the abstract provides no equations or algorithmic steps for identifying LBW dimensions from either the scalar-weight or subspace view, preventing assessment of whether the identification is reproducible or introduces implicit hyperparameters.
- [Abstract] Abstract: The description of PACT states that 'aligned subspace components are then removed from the task vectors' but does not specify the precise projection or removal operator, nor how the orthogonal complement is defined relative to the pre-trained subspace; this is required to verify that the procedure is not circular or equivalent to a fitted quantity derived from the input task vectors themselves.
minor comments (2)
- [Abstract] The abstract refers to 'extensive experiments across multiple benchmarks' but does not name the benchmarks, baselines, or metrics; these details are needed for readers to evaluate the SOTA claim.
- [Abstract] The term 'Load-Bearing Wall (LBW) dimensions' is introduced as a new concept without immediate reference to prior related notions in the literature on weight subspaces or task vectors; a brief positioning sentence would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments highlight opportunities to improve clarity regarding LBW identification and the PACT procedure. We address each point below and will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ignoring LBW dimensions 'may inadvertently damage task-specific knowledge encoded in the pre-trained model' is load-bearing, yet the abstract provides no equations or algorithmic steps for identifying LBW dimensions from either the scalar-weight or subspace view, preventing assessment of whether the identification is reproducible or introduces implicit hyperparameters.
Authors: We agree that the abstract would benefit from a concise indication of how LBW dimensions are characterized. In the revision we will add one sentence summarizing the scalar-weight view (via magnitude thresholds on pre-trained weights) and the subspace view (via principal components of task vectors relative to the pre-trained basis), together with the key identification criterion. Full reproducible procedures, including any thresholds or SVD ranks, remain in Section 3; the abstract change will not introduce new hyperparameters. revision: yes
-
Referee: [Abstract] Abstract: The description of PACT states that 'aligned subspace components are then removed from the task vectors' but does not specify the precise projection or removal operator, nor how the orthogonal complement is defined relative to the pre-trained subspace; this is required to verify that the procedure is not circular or equivalent to a fitted quantity derived from the input task vectors themselves.
Authors: We accept the request for greater precision. The revised abstract will state that the orthogonal complement is taken with respect to the fixed pre-trained weight subspace (independent of any task vector) and that removal is performed by orthogonal projection onto the aligned components followed by subtraction. This formulation is non-circular because the pre-trained subspace is computed once from the base model and does not depend on the task vectors being merged. The exact projection operator and randomized-SVD implementation are detailed in Section 4. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PACT as an additive preprocessing step that identifies LBW dimensions via scalar and subspace analysis of pre-trained weights versus task vectors, then aligns and removes orthogonal complement components before applying existing merging algorithms. No equations or steps are shown that reduce the output to a fitted parameter or self-defined quantity by construction, nor does any load-bearing premise collapse to a self-citation chain. The central claim of consistent empirical gains is presented as externally testable rather than tautological, making the derivation self-contained against the Task Arithmetic baseline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task-specific knowledge is not fully transferred into task vectors and remains embedded in pre-trained weights as LBW dimensions
invented entities (1)
-
Load-Bearing Wall (LBW) dimensions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Layer normalization.arXiv preprint arXiv:1607.06450,
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
-
[2]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
Pith/arXiv arXiv 2010
-
[3]
Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022a
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022a. Gabriel Ilharco, Mitchell Wortsman, Samir Yitzhak Gadre, Shuran Song, Hannaneh Hajishirzi, Si- mon Kornblith, Ali Farhadi, and Ludwig Schmidt. Patching...
-
[4]
Map: Low-compute model merging with amortized pareto fronts via quadratic approximation
Lu Li, Tianyu Zhang, Zhiqi Bu, Suyuchen Wang, Huan He, Jie Fu, Yonghui Wu, Jiang Bian, Yong Chen, and Yoshua Bengio. Map: Low-compute model merging with amortized pareto fronts via quadratic approximation. InInternational Conference on Learning Representations, volume 2025, pp. 65032–65064,
2025
-
[5]
Deep model fusion: A survey.arXiv preprint arXiv:2309.15698,
Weishi Li, Yong Peng, Miao Zhang, Liang Ding, Han Hu, and Li Shen. Deep model fusion: A survey.arXiv preprint arXiv:2309.15698,
-
[6]
Daniel Marczak, Simone Magistri, Sebastian Cygert, Bartłomiej Twardowski, Andrew D Bagdanov, and Joost Van De Weijer. No task left behind: Isotropic model merging with common and task- specific subspaces.arXiv preprint arXiv:2502.04959,
-
[7]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning, volume 2011, pp
2011
-
[8]
The-Hai Nguyen, Dang Huu-Tien, Takeshi Suzuki, and Le-Minh Nguyen. Regmean++: Enhanc- ing effectiveness and generalization of regression mean for model merging.arXiv preprint arXiv:2508.03121,
-
[9]
cats and dogs,
OM Parkhi. A. vedaldi, a. InZisserman, c. Jawahar,“cats and dogs, ” in 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3498–3505,
2012
-
[10]
Wei Ruan, Tianze Yang, Yifan Zhou, Tianming Liu, and Jin Lu. From task-specific models to unified systems: A review of model merging approaches.arXiv preprint arXiv:2503.08998,
-
[11]
Gradient projection memory for continual learning
14 Preprint Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning. arXiv preprint arXiv:2103.09762,
-
[12]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 conference on empirical methods in natural language pro- cessing, pp. 1631–1642,
2013
-
[13]
The german traffic sign recognition benchmark: a multi-class classification competition
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. The german traffic sign recognition benchmark: a multi-class classification competition. InThe 2011 international joint conference on neural networks, pp. 1453–1460. IEEE,
2011
-
[14]
Model merging with svd to tie the knots
George Stoica, Pratik Ramesh, Boglarka Ecsedi, Leshem Choshen, and Judy Hoffman. Model merging with svd to tie the knots. InInternational Conference on Learning Representations, volume 2025, pp. 4501–4519,
2025
-
[15]
Anke Tang, Li Shen, Yong Luo, Liang Ding, Han Hu, Bo Du, and Dacheng Tao. Concrete subspace learning based interference elimination for multi-task model fusion.arXiv preprint arXiv:2312.06173,
-
[16]
Vinita Vasudevan and M Ramakrishna. A hierarchical singular value decomposition algorithm for low rank matrices.arXiv preprint arXiv:1710.02812,
-
[17]
Ke Wang, Nikolaos Dimitriadis, Guillermo Ortiz-Jimenez, Franc ¸ois Fleuret, and Pascal Frossard. Localizing task information for improved model merging and compression.arXiv preprint arXiv:2405.07813,
-
[18]
Yongxian Wei, Zixuan Hu, Li Shen, Zhenyi Wang, Yu Li, Chun Yuan, and Dacheng Tao. Task groupings regularization: Data-free meta-learning with heterogeneous pre-trained models.arXiv preprint arXiv:2405.16560,
-
[19]
Yongxian Wei, Anke Tang, Li Shen, Zixuan Hu, Chun Yuan, and Xiaochun Cao. Modeling multi- task model merging as adaptive projective gradient descent.arXiv preprint arXiv:2501.01230,
-
[20]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing in- ference time. InInternational conference on machine learning, pp. 23965–23998. P...
-
[21]
Multi-task model merging via adaptive weight disentanglement.arXiv preprint arXiv:2411.18729,
15 Preprint Feng Xiong, Runxi Cheng, Wang Chen, Zhanqiu Zhang, Yiwen Guo, Chun Yuan, and Ruifeng Xu. Multi-task model merging via adaptive weight disentanglement.arXiv preprint arXiv:2411.18729,
-
[22]
Metagpt: Merging large language models using model exclusive task arithmetic
Yuyan Zhou, Liang Song, Bingning Wang, and Weipeng Chen. Metagpt: Merging large language models using model exclusive task arithmetic. InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pp. 1711–1724,
2024
-
[23]
6, we present a unified mathematical deriva- tion based on the construction of the LBW subspace
Whenϵ g =ϵ ∆ = 0, the first-order term becomes ∆L(1) j ≤ ∥∇L j(θj)∥F ∥∆j∥F cos2(ϕj),(21) A.3 DERIVATION ANDPROOF OF THEABLATIONAPPROXIMATION To justify the ablation approximation presented in Eqn. 6, we present a unified mathematical deriva- tion based on the construction of the LBW subspace. Recall that the task-specific model parameter is decomposed asθ...
2011
-
[24]
Following the conventions established in previous works, let∆ t ∈R n×n, and letTandLbe the number of tasks and network layers, respectively
and Iso-CTS (Marczak et al., 2025). Following the conventions established in previous works, let∆ t ∈R n×n, and letTandLbe the number of tasks and network layers, respectively. For simplicity, assume that each layer consists of a single squaredn×nmatrix. In our analysis, we focus on the number of Singular Value Decompositions (SVDs) performed by each algo...
2025
-
[25]
However, SVDs utilized for final subspace alignment or full aggregation must remain exact
(33) Efficient Variants with Randomized SVD (RSVD): Since extracting task-specific features only requires the top-ksingular vectors, RSVD can approximate these components using random projections, strictly dropping the decompo- sition complexity fromO(n 3)toO(n 2kmax), wherek max is the maximum rank retained. However, SVDs utilized for final subspace alig...
2025
-
[26]
TSV-M (Gargiulo et al., 2025)T+ 2 0O (T+ 2)Ln3 Iso-CTS (Marczak et al., 2025)T+ 3 0O (T+ 3)Ln3 PACT-IsoC (Ours)T+ 2 0O (T+ 2)Ln3 PACT-TSVM (Ours)2T+ 3 0O (2T+ 3)Ln3 Efficient Variants with Randomized SVD (RSVD) Efficient TSV-M2TO T Ln2kmax+ 2Ln3 Efficient PACT-IsoC (Ours)1T+ 1O (T+ 1)Ln2kmax+Ln3 Efficient PACT-TSVM (Ours)2 2T+ 1O (2T+ 1)Ln2kmax+ 2Ln3 Tabl...
2025
-
[27]
the averaging illusion
and subspace alignment formulations (Fernando et al., 2013), we define theIntrusion Energy (E in)for a specific tasktat layerℓas: Ein(t, ℓ) = ∥∆tV0,K ∥2 F ∥∆t∥2 F (37) whereV 0,K ∈R n×K represents the top-Kright singular vectors of the pre-trained weightsθ 0, capturing the core coordinates of general pre-trained knowledge. The objective ofEin is to measur...
2013
-
[28]
The sensitivity analysis indicates thatPACTis relatively robust to different hyperparameter configu- rations
Table 13 examines the effects of varying the pre-trained core dimensionKand the active task vector dimensionk, alongside the corresponding base merging scaling coefficientsα. The sensitivity analysis indicates thatPACTis relatively robust to different hyperparameter configu- rations. Specifically, the parameter pair(K, k) = (15,8)consistently yields favor...
2013
-
[29]
EMNIST contains images of both characters and digits
is an extended version of MNIST. EMNIST contains images of both characters and digits. We choose to use only the EMNIST Letters split, which contains around145,000images evenly distributed in 26 classes of the alphabet letters. •KMNIST(Ba et al., 2016), yet another version of MNIST, represents 10 Japanese Hira- gana characters. •RenderedSST2(Socher et al....
2016
-
[30]
The images are rendered from sentences in the Stanford Sentiment Treebank v2 (Socher et al., 2013), with black texts on a white background in448×448resolution
is used for evaluating the mod- els’ capability on optical character recognition. The images are rendered from sentences in the Stanford Sentiment Treebank v2 (Socher et al., 2013), with black texts on a white background in448×448resolution. Each image is labeled as positive or negative based on the mood expressed in the text, and the number of images for...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.