BLADE: Scalable Bi-level Adaptive Data Selection for LLM Training
Pith reviewed 2026-06-26 21:50 UTC · model grok-4.3
The pith
BLADE reformulates bi-level data selection for LLMs as a penalized single-level objective that uses a dynamic reference model instead of a static one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
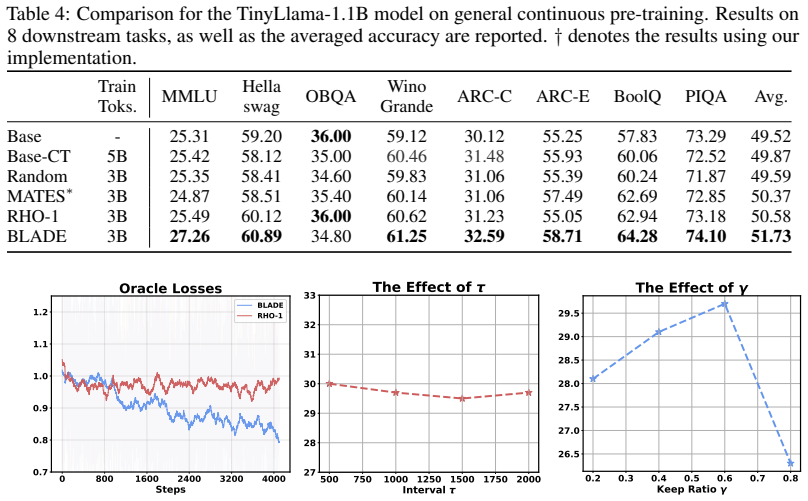
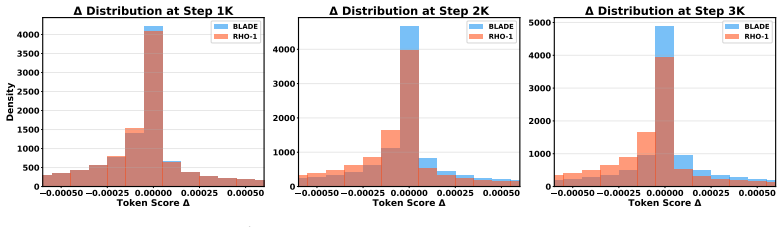
BLADE reformulates the bi-level optimization problem underlying influence-based methods as a penalized single-level objective via Lagrange multipliers, avoiding inverse-Hessian computation while revealing a principled connection to excess-loss based data selection. The resulting objective recovers an excess-loss form but replaces the static reference model with a dynamic one that stays synchronized with training. Theoretically, the penalized formulation guarantees first-order convergence. For efficient online batch selection the method is instantiated as a memoryless randomized block-coordinate Frank-Wolfe algorithm.
What carries the argument
The Lagrange-multiplier penalized single-level reformulation of the bi-level influence objective, which produces a dynamic reference model synchronized to the training process.
If this is right
- The approach eliminates the need for inverse-Hessian computations while retaining a connection to excess-loss selection.
- The dynamic reference model remains aligned with the evolving proxy model throughout training.
- First-order convergence is guaranteed for the reformulated objective.
- The selection procedure can be executed online via a memoryless randomized block-coordinate Frank-Wolfe algorithm.
- Extensive experiments show consistent gains over prior data-selection baselines.
Where Pith is reading between the lines
- The dynamic reference may allow selection decisions to track shifts in what the model currently finds hard, opening the possibility of more responsive training trajectories than static filters permit.
- The same penalized reformulation could be tried on other bi-level problems in machine learning that currently stall on Hessian terms.
- Because the algorithm is memoryless, the method may integrate into existing large-scale training loops with little extra state management.
- If the dynamic reference improves selection quality, one testable extension is to measure whether downstream model performance on held-out benchmarks rises more steeply than with static excess-loss baselines.
Load-bearing premise
The penalized single-level formulation preserves enough of the original bi-level semantics to guarantee first-order convergence and keeps the dynamic reference model properly synchronized without introducing instabilities during online training.
What would settle it
A controlled small-scale run in which the data batches chosen by the penalized objective measurably diverge from those chosen by the exact bi-level solution (computed directly on a toy model where both are tractable) would falsify the claim that the reformulation preserves the intended semantics.
Figures

read the original abstract
As Large Language Model (LLM) datasets scale to trillions of tokens, data selection has emerged as a critical frontier to filter out uninformative noise and construct adaptive learning trajectories. Beyond static heuristic filtering, advanced data selection methods for LLM training largely follow two paradigms, each with fundamental limitations. Influence-based methods provide principled bi-level objectives but require intractable inverse-Hessian computations, while excess-loss methods are computationally efficient but rely on a static reference model that becomes misaligned with the evolving proxy model during training. We propose BLADE (Bi-Level Adaptive Data sElection), a Hessian-free framework for data selection. BLADE reformulates the bi-level optimization problem underlying influence-based methods as a penalized single-level objective via Lagrange multipliers, avoiding inverse-Hessian computation while revealing a principled connection to excess-loss based data selection. The resulting objective recovers an excess-loss form but replaces the static reference model with a dynamic one that stays synchronized with training. Theoretically, we prove that this penalized formulation guarantees first-order convergence. For efficient online batch selection, we instantiate BLADE as a memoryless randomized block-coordinate Frank-Wolfe algorithm. Extensive experiments show that BLADE consistently outperforms state-of-the-art data selection baselines, providing a practical recipe for LLM training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that BLADE reformulates the bi-level optimization underlying influence-based data selection as a penalized single-level objective via Lagrange multipliers. This avoids inverse-Hessian computation, recovers an excess-loss form with a dynamic (training-synchronized) reference model instead of a static one, guarantees first-order convergence, and is instantiated as a memoryless randomized block-coordinate Frank-Wolfe algorithm for online batch selection. Experiments are reported to show consistent outperformance over state-of-the-art baselines on LLM training.
Significance. If the penalized reformulation exactly recovers bi-level semantics and the convergence analysis holds without additional instabilities from the dynamic reference, the work would usefully bridge influence-based and excess-loss paradigms while providing a scalable, Hessian-free method for data selection at trillion-token scale. The explicit connection to excess-loss forms and the memoryless Frank-Wolfe instantiation are notable strengths if substantiated.
major comments (2)
- [§3] The abstract and §3 assert that the Lagrange-penalized single-level objective recovers the original bi-level solution and excess-loss form; the precise multiplier construction, the conditions under which equivalence holds (especially with the dynamic reference), and any hidden assumptions on synchronization must be stated explicitly to support the first-order convergence claim.
- [§4] §4 states a first-order convergence guarantee for the memoryless randomized block-coordinate Frank-Wolfe instantiation; the proof must address whether online updates to the dynamic reference model can introduce lag or violate the assumptions needed for the guarantee to hold.
minor comments (2)
- [§5] The experimental section should include more detail on baseline implementations, hyperparameter choices, and statistical significance of the reported gains to allow direct replication.
- Notation for the dynamic reference model and its update rule should be introduced earlier and kept consistent across the method and theory sections.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the equivalence conditions and convergence analysis.
read point-by-point responses
-
Referee: [§3] The abstract and §3 assert that the Lagrange-penalized single-level objective recovers the original bi-level solution and excess-loss form; the precise multiplier construction, the conditions under which equivalence holds (especially with the dynamic reference), and any hidden assumptions on synchronization must be stated explicitly to support the first-order convergence claim.
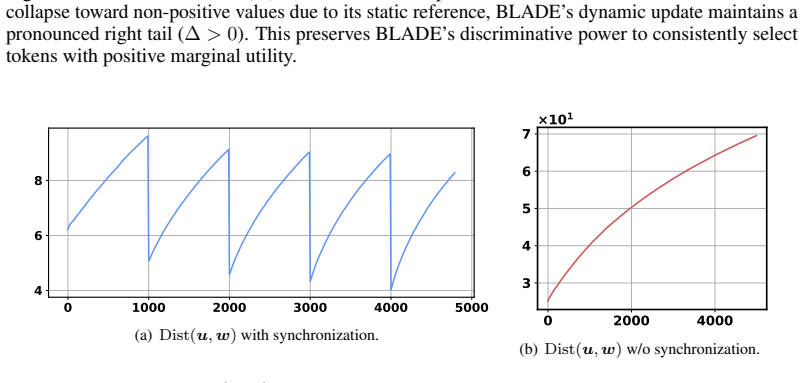
Authors: We agree that greater explicitness is warranted. The Lagrange multiplier is the dual variable associated with the bi-level constraint; equivalence to the excess-loss form holds precisely when the reference model is updated synchronously with the proxy model at each iteration. We will insert a dedicated paragraph in §3 stating the multiplier construction, the exact equivalence conditions, and the synchronization assumption required for the first-order convergence result. revision: yes
-
Referee: [§4] §4 states a first-order convergence guarantee for the memoryless randomized block-coordinate Frank-Wolfe instantiation; the proof must address whether online updates to the dynamic reference model can introduce lag or violate the assumptions needed for the guarantee to hold.
Authors: The memoryless block-coordinate updates are constructed so that the reference model remains synchronized by design, preventing lag from accumulating. Nevertheless, to directly address the concern, we will augment the proof in §4 with a short lemma bounding any residual lag and confirming that the first-order rate is preserved under the online schedule. revision: yes
Circularity Check
No circularity: standard Lagrange reformulation with independent convergence claim
full rationale
The provided abstract and context describe a reformulation of bi-level optimization into a penalized single-level objective using Lagrange multipliers, followed by a claimed proof of first-order convergence and an online Frank-Wolfe instantiation. This is a standard mathematical technique for constrained optimization and does not reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The dynamic reference model is presented as synchronized by construction of the online algorithm, but no equations or steps in the given text exhibit a reduction where the output is forced by the inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark abd Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint, arXiv:1905.10044, 2019
Pith/arXiv arXiv 1905
-
[2]
Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms.arXiv preprint, arXiv:1905.13319, 2019
Pith/arXiv arXiv 1905
-
[3]
Jiang, Jia Deng, Stella Biderman, and Sean Welleck
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics.arXiv preprint, arXiv:2310.10631, 2023
Pith/arXiv arXiv 2023
-
[4]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. InAAAI conference on artificial intelligence, 2020
2020
-
[5]
Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems
Tianyi Chen, Yuejiao Sun, and Wotao Yin. Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems. InAdvances in Neural Information Processing Systems, 2021
2021
-
[6]
Making scalable meta learning practical
Sang Keun Choe, Sanket Vaibhav Mehta, Willie Neiswanger Hwijeen Ahn, Pengtao Xie, Emma Strubell, and Eric Xing. Making scalable meta learning practical. InAdvances in Neural Information Processing Systems, 2024
2024
-
[7]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint, arXiv:1803.05457, 2018
Pith/arXiv arXiv 2018
-
[8]
Training verifiers to solve math word problems.arXiv preprint, arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint, arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[9]
Dsdm: Model-aware dataset selection with datamodels
Logan Engstrom, Axel Feldmann, and Aleksander Madry. Dsdm: Model-aware dataset selection with datamodels. InInternational Conference on Machine Learning, pages 12491–12526. PMLR, 2024
2024
-
[10]
The language model evaluation harness, 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[11]
Bilevel optimization with a lower- level contraction: Optimal sample complexity without warm-start
Riccardo Grazzi, Massimiliano Pontil, and Saverio Salzo. Bilevel optimization with a lower- level contraction: Optimal sample complexity without warm-start. InJournal of Machine Learning Research, 2023
2023
-
[12]
Jie Hao, Rui Yu, Wei Zhang, Huixia Wang, Jie Xu, and Mingrui Liu. Bliss: A lightweight bilevel influence scoring method for data selection in language model pretraining.arXiv preprint, arXiv:2510.06048, 2025
Pith/arXiv arXiv 2025
-
[13]
Projection-free online learning
Elad Hazan and Satyen Kale. Projection-free online learning. InInternational Conference on Machine Learning, 2012
2012
-
[14]
Measuring massive multitask language understanding.arXiv preprint, arXiv:2009.03300, 2020
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint, arXiv:2009.03300, 2020
Pith/arXiv arXiv 2009
-
[15]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Neural Information Processing Systems, 2021. 10
2021
-
[16]
A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor- critic.SIAM J
Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor- critic.SIAM J. Optim., 2023
2023
-
[17]
Mawps: A math word problem repository
Rik Koncel Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. Mawps: A math word problem repository. InConference of the North American Chapter of the Association for Computational Linguistics, 2016
2016
-
[18]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational Conference on Machine Learning, 2017
2017
-
[19]
A fully first-order method for stochastic bilevel optimization
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert Nowa. A fully first-order method for stochastic bilevel optimization. InInternational Conference on Machine Learning, 2023
2023
-
[20]
On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert D Nowak. On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation. InInternational Conference on Learning Representations, 2024
2024
-
[21]
Convergence rate of frank-wolfe for non-convex objectives.arXiv preprint, arXiv:1607.00345, 2016
Simon Lacoste-Julien. Convergence rate of frank-wolfe for non-convex objectives.arXiv preprint, arXiv:1607.00345, 2016
Pith/arXiv arXiv 2016
-
[22]
Block-coordinate Frank-Wolfe optimization for structural SVMs
Simon Lacoste-Julien, Martin Jaggi, Mark Schmidt, and Patrick Pletscher. Block-coordinate Frank-Wolfe optimization for structural SVMs. InInternational Conference on Machine Learning, 2013
2013
-
[23]
Rho-1: Not all tokens are what you need
Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, and Weizhu Chen. Rho-1: Not all tokens are what you need. In Neural Information Processing Systems, 2024
2024
-
[24]
Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning
Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. InInternational Conference on Learning Representations, 2023
2023
-
[25]
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms
Dagréou Mathieu, Pierre Ablin, Samuel Vaiter, and Thomas Moreau. A framework for bilevel optimization that enables stochastic and global variance reduction algorithms. InAdvances in Neural Information Processing Systems, 2022
2022
-
[26]
A diverse corpus for evaluating and de- veloping english math word problem solvers
Shenyun Miao, Chaochun Liang, and Keh-Yih Su. A diverse corpus for evaluating and de- veloping english math word problem solvers. InAssociation for Computational Linguistics, 2020
2020
-
[27]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question aanswering.arXiv preprint, arXiv:1809.02789, 2018
Pith/arXiv arXiv 2018
-
[28]
Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal
Sören Mindermann, Jan Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N. Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal. Prioritized training on points that are learnable, worth learning, and not yet learnt. In International Conference on Machine Learning, 2022
2022
-
[29]
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. In search of the real inductive bias: On the role of implicit regularization in deep learning.arXiv preprint, arXiv:1412.6614, 2014
Pith/arXiv arXiv 2014
-
[30]
G- dig: Towards gradient-based diverse and high-quality instruction data selection for machine translation
Xingyuan Pan, Luyang Huang, Liyan Kang, Zhicheng Liu, Yu Lu, and Shanbo Cheng. G- dig: Towards gradient-based diverse and high-quality instruction data selection for machine translation. InAssociation for Computational Linguistics, 2024
2024
-
[31]
Openwebmath: An open dataset of high-quality mathematical web text
Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba. Openwebmath: An open dataset of high-quality mathematical web text. InInternational Conference on Learning Representations, 2024
2024
-
[32]
Are nlp models really able to solve simple math word problems? InConference of the North American Chapter of the Association for Computational Linguistics, 2021
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InConference of the North American Chapter of the Association for Computational Linguistics, 2021. 11
2021
-
[33]
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, and Susannah Young et. al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint, arXiv:2112.11446, 2021
Pith/arXiv arXiv 2021
-
[34]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. InJournel of Machine Learning Research, 2020
2020
-
[35]
Reddi, Suvrit Sra, Barnabas Poczos, and Alex Smola
Sashank J. Reddi, Suvrit Sra, Barnabas Poczos, and Alex Smola. Stochastic frank-wolfe methods for nonconvex optimization. InAnnual Allerton Conference on Communication, Control, and Computing, 2016
2016
-
[36]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. InAAAI conference on artificial intelligence, 2020
2020
-
[37]
Truncated back- propagation for bilevel optimization
Amirreza Shaban, Ching-An Cheng, Nathan Hatch, and Byron Boots. Truncated back- propagation for bilevel optimization. InInternational Conference on Artificial Intelligence and Statistics, 2019
2019
-
[38]
On penalty-based bilevel gradient descent method
Han Shen and Tianyi Chen. On penalty-based bilevel gradient descent method. InInternational Conference on Machine Learning, 2023
2023
-
[39]
Slimpajama: A 627b token, cleaned and deduplicated version of redpajam.https://www.cerebras.ai/blog/slimpajama-a-627b-token-cleaned-and-deduplicated- version-of-redpajama, 2023
Daria Soboleva, Faisal Al-Khateeb, Joel Hestness, and Jacob Robert Steeves Nolan Dey Open- tensor: Robert Myers. Slimpajama: A 627b token, cleaned and deduplicated version of redpajam.https://www.cerebras.ai/blog/slimpajama-a-627b-token-cleaned-and-deduplicated- version-of-redpajama, 2023
2023
-
[40]
The implicit bias of gradient descent on separable data
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data. InJournal of Machine Learning Research, 2018
2018
-
[41]
Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants
Teknium. Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants. 2023
2023
-
[42]
D4: Improving llm pretraining via document de-duplication and diversification
Kushal Tirumala, Daniel Simig, Armen Aghajanyan, and Ari Morcos. D4: Improving llm pretraining via document de-duplication and diversification. InNeural Information Processing Systems, 2023
2023
-
[43]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint, arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, and Nikolay Bashlykov et.al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint, arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[44]
Wang, Tong Wu, Dawn Song, Prateek Mittal, and Ruoxi Jia
Jiachen T. Wang, Tong Wu, Dawn Song, Prateek Mittal, and Ruoxi Jia. Greats: Online selection of high-quality data for llm training in every iteration. InNeural Information Processing Systems, 2024
2024
-
[45]
Tandem: Bi-level data mixture optimization with twin networks
Jiaxing Wang, Deping Xiang, Jin Xu, Mingyang Yi, Guoqiang Gong, Zicheng Zhang, Haoran Li, Pengzhang Liu, Zhen Chen, Ke Zhang, Ju Fan, and Qixiang Jiang. Tandem: Bi-level data mixture optimization with twin networks. InNeural Information Processing Systems, 2025
2025
-
[46]
Less: Selecting influential data for targeted instruction tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: Selecting influential data for targeted instruction tuning. InInternational Conference on Machine Learning, 2024
2024
-
[47]
Data selection for language models via importance resampling
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. InNeural Information Processing Systems, 2023
2023
-
[48]
Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. InInternational Conference on Learning Representations, 2024. 12
2024
-
[49]
Mates: Model-aware data selection for efficient pretraining with data influence models
Zichun Yu, Spandan Das, and Chenyan Xiong. Mates: Model-aware data selection for efficient pretraining with data influence models. InNeural Information Processing Systems, 2024
2024
-
[50]
Mammoth: Building math generalist models through hybrid instruction tuning
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, , and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning. In International Conference on Learning Representations, 2024
2024
-
[51]
Hellaswag: Can a machine really finish your sentence?arXiv preprint, arXiv:1905.07830, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint, arXiv:1905.07830, 2019
Pith/arXiv arXiv 1905
-
[52]
Tinyllama: An open-source small language model.arXiv preprint, arXiv:2401.02385, 2024
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model.arXiv preprint, arXiv:2401.02385, 2024
Pith/arXiv arXiv 2024
-
[53]
Lima: Less is more for alignment.arXiv preprint, arXiv:2305.11206, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Lima: Less is more for alignment.arXiv preprint, arXiv:2305.11206, 2023
Pith/arXiv arXiv 2023
-
[54]
Probabilistic bilevel coreset selection
Xiao Zhou, Renjie Pi, Weizhong Zhang, Yong Lin, and Tong Zhang. Probabilistic bilevel coreset selection. InInternational Conference on Machine Learning, 2022. 13 A Convergence of Bi-level Data Selection Here we present a theoretical analysis of the proposed BLADE. The original bi-level optimization problem P: min α∈A Lval (w∗(α))s.t.w ∗(α)∈S ∗(α) := arg m...
2022
-
[55]
Both∇ wLtrain(α,w)and∇ wLval(w)are Lipschitz continuous towon coefficientL
-
[56]
hard but learnable
BothL train(α,w)andL val(w)are Lipschitz continuous towwith coefficientB. Assumption 3(Bounded Hessian).For any α∈ A , w∈S ∗(α), there exists positive constants κ, ρ, satisfying Hessian matrices∇ 2 wwLtrain(α,w)⪰κ 8 and∇ 2 αwLtrain(α,w)⪯ρ. Assumption 4(Lipschitz Hessian).For any α∈ A , Ltrain(α,w) is twice continuous differentiable, and the Hessian matric...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.