Complementary Attention Head Pruning for Efficient Transformers
Pith reviewed 2026-06-26 20:54 UTC · model grok-4.3
The pith
CAHP selects complementary attention heads in transformers via graph clustering and automatically determines how many to keep from performance curves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
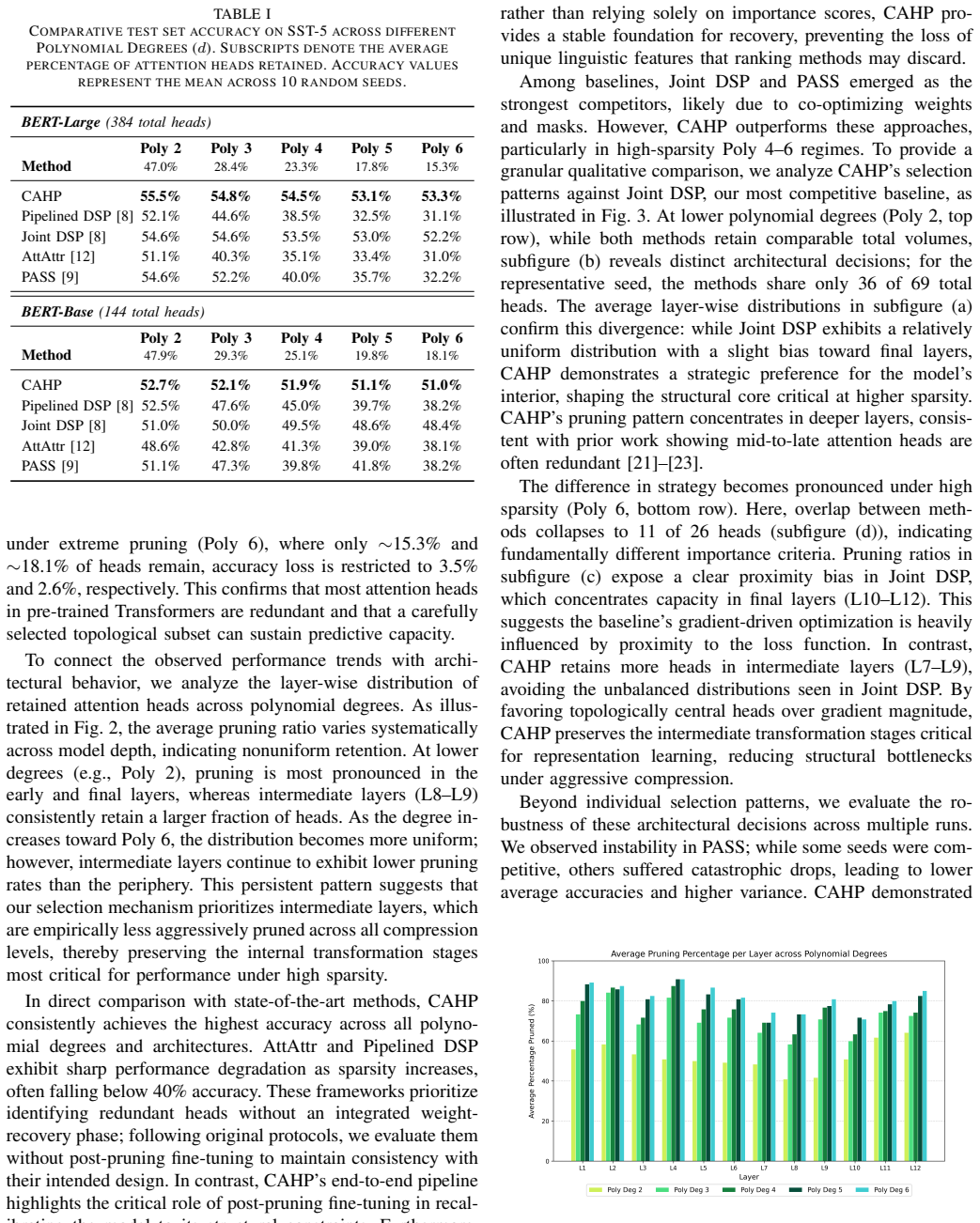
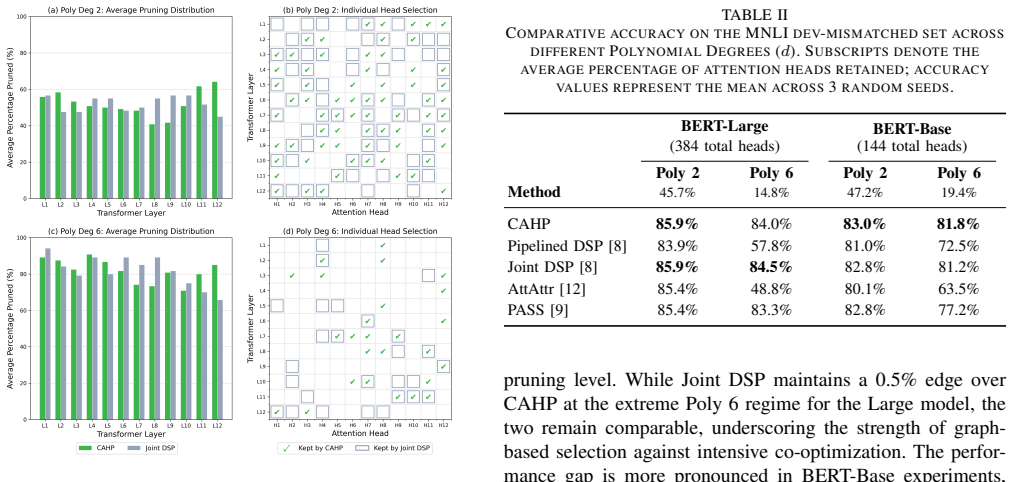
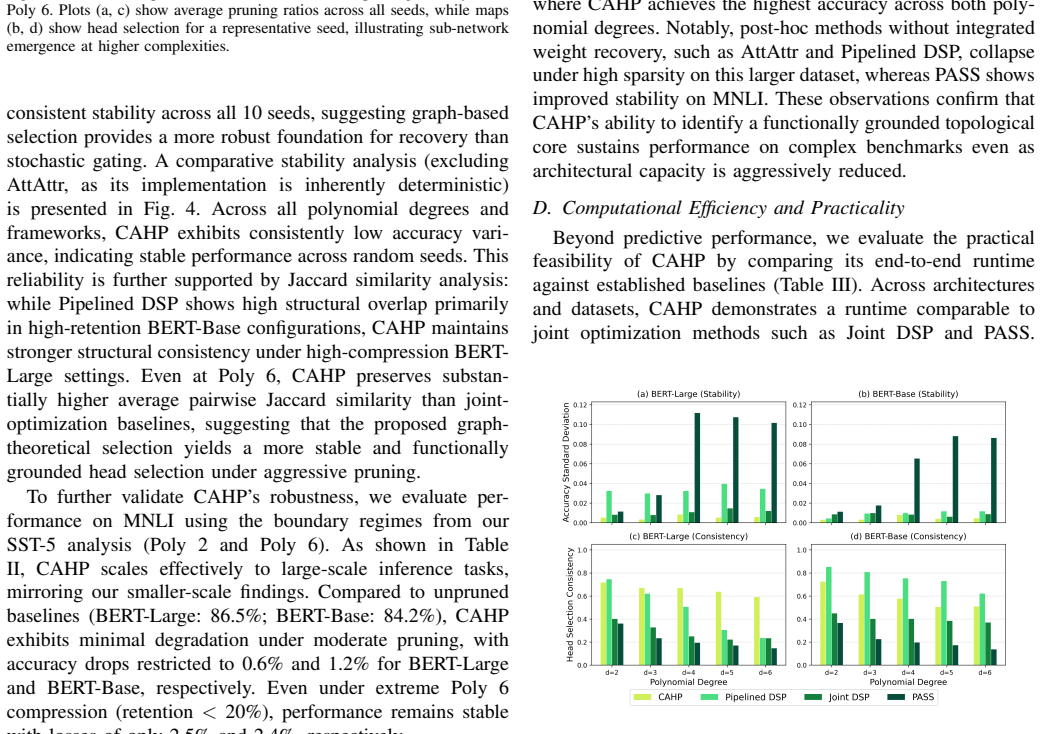
CAHP reframes head pruning as a global graph problem in which information-theoretic distances define edges and clustering extracts a complementary subset of heads. A polynomial fit to the diminishing-marginal-performance curve then identifies the largest number of heads that can be removed before accuracy drops sharply. Across model scales this procedure yields higher accuracy than prior structured pruning methods on SST-5 and MNLI, particularly under high compression, and produces a different layer-wise distribution of retained heads.
What carries the argument
Graph-based clustering on information-theoretic distances between attention heads, together with polynomial fitting on the performance degradation curve to choose the retained head count.
If this is right
- Transformer models can be compressed post-training without supplying a target pruning ratio in advance.
- Retained heads are drawn from intermediate layers rather than being concentrated near the output.
- Accuracy on sentence classification and inference tasks remains higher than gradient-ranking or gating methods when many heads are removed.
- The procedure removes the need to tune separate importance thresholds per layer.
Where Pith is reading between the lines
- The same graph-construction step could be applied to prune other structured components such as feed-forward blocks.
- Diversity among retained heads may correlate with robustness to domain shift after compression.
- Re-running the curve fit after additional fine-tuning could allow adaptive compression during deployment.
Load-bearing premise
Fitting a polynomial of fixed degree to the observed performance curve will reliably mark the correct point at which further pruning causes a sharp drop.
What would settle it
On SST-5 or MNLI, the number of heads chosen by the polynomial fit yields lower accuracy than a competitive baseline at the same or higher compression level.
Figures

read the original abstract
The remarkable success of Transformer-based models in natural language processing stems from architectural scaling, which leads to a large number of parameters and hinders deployment in resource-constrained environments. While structured pruning offers a pathway to compression, existing state-of-the-art methods often rely on gradient-based importance ranking or stochastic gating, which suffer from instability, structural degeneration, and the need for extensive manual hyperparameter tuning. In this paper, we introduce CAHP (Complementary Attention Head Pruning), a novel post-hoc framework that redefines head selection as a global graph-theoretical problem. Rather than evaluating heads in isolation, CAHP utilizes graph-based clustering combined with information-theoretic distance measures to identify and preserve a topologically diverse subset of complementary attention heads. Without requiring a predefined sparsity level or pruning ratio, the framework automatically determines the number of selected attention heads across layers by identifying a diminishing marginal performance curve, where pruning additional heads leads to a sharp degradation in performance, as determined by the chosen polynomial degree. Extensive evaluations on the SST-5 and MNLI benchmarks, across different Transformer model scales, demonstrate that CAHP consistently outperforms competitive baselines, particularly in high-compression regimes. Furthermore, our structural analysis shows that CAHP avoids the "proximity bias" of gradient-based pruning methods, which tend to preserve heads mainly in layers close to the output, and instead retains a functionally critical set of attention heads in the model's intermediate layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAHP, a post-hoc pruning framework for Transformer attention heads that models head selection as a global graph clustering problem using information-theoretic distances to preserve topologically complementary heads. It claims to automatically select the number of heads per layer by fitting a polynomial to a diminishing-marginal-performance curve and locating the point of sharp degradation, without a user-specified sparsity ratio. Evaluations on SST-5 and MNLI across model scales are said to show consistent outperformance over gradient-based and gating baselines, especially at high compression, while avoiding proximity bias toward output-proximal layers.
Significance. If the empirical claims hold and the polynomial-based knee detection proves stable, the method could reduce reliance on manual sparsity tuning and gradient instability in structured pruning, offering a more topology-aware alternative that retains functionally diverse heads. The graph-clustering formulation is a distinctive angle relative to existing importance-ranking approaches.
major comments (2)
- [Abstract] Abstract: the claim that CAHP 'automatically determines the number of selected attention heads across layers [...] without requiring a predefined sparsity level' is directly qualified by dependence on 'the chosen polynomial degree' to locate the sharp degradation point in the performance curve; because the degree is a free hyperparameter whose sensitivity to curve noise, number of points, or alternative degrees is not analyzed, the 'automatic' advantage over baselines that require sparsity tuning is not yet substantiated.
- [Abstract] Abstract (evaluations paragraph): the assertion of consistent outperformance 'particularly in high-compression regimes' on SST-5 and MNLI is presented without any quantitative tables, error bars, baseline configurations, or ablation results in the provided text, preventing verification that the reported gains are not artifacts of post-hoc baseline selection or curve-fitting choices.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each major comment below. We agree that sensitivity analysis for the polynomial degree is needed to strengthen the automatic selection claim and will add this in revision. The evaluation details are present in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CAHP 'automatically determines the number of selected attention heads across layers [...] without requiring a predefined sparsity level' is directly qualified by dependence on 'the chosen polynomial degree' to locate the sharp degradation point in the performance curve; because the degree is a free hyperparameter whose sensitivity to curve noise, number of points, or alternative degrees is not analyzed, the 'automatic' advantage over baselines that require sparsity tuning is not yet substantiated.
Authors: We acknowledge that the polynomial degree is a hyperparameter and that its sensitivity was not analyzed in the submission. In practice we used degree 3, which yielded stable knee points, but to substantiate robustness we will add an ablation in the revised version showing knee stability for degrees 2-4 across SST-5, MNLI, and model scales. We will also revise the abstract wording to state that the method avoids a user-specified sparsity ratio while employing a standard polynomial fit for knee detection. revision: yes
-
Referee: [Abstract] Abstract (evaluations paragraph): the assertion of consistent outperformance 'particularly in high-compression regimes' on SST-5 and MNLI is presented without any quantitative tables, error bars, baseline configurations, or ablation results in the provided text, preventing verification that the reported gains are not artifacts of post-hoc baseline selection or curve-fitting choices.
Authors: The abstract is a concise summary; the full manuscript contains the requested quantitative evidence. Tables 1-3 report mean accuracies with standard deviations over 5 runs, list all baseline hyperparameters, and include ablations on clustering distance and knee detection. Section 4 and the appendix provide the full results and statistical tests. If only the abstract excerpt was available, the complete tables can be highlighted for verification. revision: no
Circularity Check
No circularity: graph clustering with information-theoretic distances and post-hoc polynomial knee detection are independent of each other and of the reported benchmark results
full rationale
The paper defines CAHP via a graph-theoretical formulation that constructs a head-similarity graph, applies clustering, and uses information-theoretic distances to retain a topologically diverse subset; none of these steps are defined in terms of the final performance numbers or the polynomial fit. The polynomial fit is applied after pruning to locate a knee on the observed diminishing-marginal-performance curve and thereby choose the retained head count; this choice is a downstream heuristic, not an input that is renamed as a prediction. No equations equate the selected head set to quantities derived from the same data used to claim superiority, and the provided text contains no self-citations or uniqueness theorems that would render the central claim load-bearing on prior author work. The derivation chain therefore remains self-contained against the external SST-5 and MNLI benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- polynomial degree
axioms (1)
- domain assumption Information-theoretic distance between attention heads captures functional complementarity suitable for global pruning decisions
Reference graph
Works this paper leans on
-
[1]
Multilayer feedforward networks are universal approximators,
K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators,”Neural networks, vol. 2, no. 5, pp. 359–366, 1989
1989
-
[2]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[4]
Structured pruning of deep convolutional neural networks,
S. Anwar, K. Hwang, and W. Sung, “Structured pruning of deep convolutional neural networks,”ACM Journal on Emerging Technologies in Computing Systems (JETC), vol. 13, no. 3, pp. 1–18, 2017
2017
-
[5]
CoSeP: Complementary Separability Pruning via Class-Separability Clustering
D. Levin and G. Singer, “Automatic complementary separation pruning toward lightweight cnns,”arXiv preprint arXiv:2505.13225, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
E. V oita, D. Talbot, F. Moiseev, R. Sennrich, and I. Titov, “Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned,”arXiv preprint arXiv:1905.09418, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[7]
Are sixteen heads really better than one?
P. Michel, O. Levy, and G. Neubig, “Are sixteen heads really better than one?”Advances in neural information processing systems, vol. 32, 2019
2019
-
[8]
Differentiable subset pruning of transformer heads,
J. Li, R. Cotterell, and M. Sachan, “Differentiable subset pruning of transformer heads,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 1442–1459, 2021
2021
-
[9]
Pruning attention heads with almost-sure sparsity targets,
D. Ding, G. Jawahar, and L. V . S. Lakshmanan, “Pruning attention heads with almost-sure sparsity targets,” 2024. [Online]. Available: https://openreview.net/forum?id=yhvtZdqBNm
2024
-
[10]
The State of Sparsity in Deep Neural Networks
T. Gale, E. Elsen, and S. Hooker, “The state of sparsity in deep neural networks.(2019),”arXiv preprint cs.LG/1902.09574, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Learning both weights and con- nections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and con- nections for efficient neural network,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[12]
Self-attention attribution: Interpreting information interactions inside transformer,
Y . Hao, L. Dong, F. Wei, and K. Xu, “Self-attention attribution: Interpreting information interactions inside transformer,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 14, 2021, pp. 12 963–12 971
2021
-
[13]
Bhpvas: visual analysis system for pruning attention heads in bert model,
Z. Liu, H. Sun, H. Sun, X. Hong, G. Xu, and X. Wu, “Bhpvas: visual analysis system for pruning attention heads in bert model,”Journal of Visualization, vol. 27, no. 4, pp. 731–748, 2024
2024
-
[14]
Unsupervised segmentation evaluation using area-weighted variance and jeffries-matusita distance for remote sensing images,
Y . Wang, Q. Qi, and Y . Liu, “Unsupervised segmentation evaluation using area-weighted variance and jeffries-matusita distance for remote sensing images,”Remote Sensing, vol. 10, no. 8, p. 1193, 2018
2018
-
[15]
Quantification of the effects of land-cover- class spectral separability on the accuracy of markov-random-field-based superresolution mapping,
V . A. Tolpekin and A. Stein, “Quantification of the effects of land-cover- class spectral separability on the accuracy of markov-random-field-based superresolution mapping,”IEEE transactions on geoscience and remote sensing, vol. 47, no. 9, pp. 3283–3297, 2009
2009
-
[16]
Gb-afs: graph-based automatic feature selection for multi-class classification via mean simplified silhouette,
D. Levin and G. Singer, “Gb-afs: graph-based automatic feature selection for multi-class classification via mean simplified silhouette,”Journal of Big Data, vol. 11, no. 1, p. 79, 2024
2024
-
[17]
Graph-based feature selection method under budget constraint for multiclass classification problems,
D. Levin and G. Singer, “Graph-based feature selection method under budget constraint for multiclass classification problems,”INFORMS Journal on Data Science, 2025
2025
-
[18]
Finding a
V . Satopaa, J. Albrecht, D. Irwin, and B. Raghavan, “Finding a” kneedle” in a haystack: Detecting knee points in system behavior,” in2011 31st international conference on distributed computing systems workshops. IEEE, 2011, pp. 166–171
2011
-
[19]
D. E. Knuth,The art of computer programming: Seminumerical algo- rithms, volume 2. Addison-Wesley Professional, 2014
2014
-
[20]
Fast and eager k-medoids clustering: O (k) runtime improvement of the pam, clara, and clarans algorithms,
E. Schubert and P. J. Rousseeuw, “Fast and eager k-medoids clustering: O (k) runtime improvement of the pam, clara, and clarans algorithms,” Information Systems, vol. 101, p. 101804, 2021
2021
-
[21]
Finercut: Finer-grained interpretable layer pruning for large language models, 2024 c
Y . Zhang, Y . Li, X. Wang, Q. Shen, B. Plank, B. Bischl, M. Rezaei, and K. Kawaguchi, “Finercut: Finer-grained interpretable layer pruning for large language models,”arXiv preprint arXiv:2405.18218, 2024
-
[22]
On the effect of dropping layers of pre-trained transformer models,
H. Sajjad, F. Dalvi, N. Durrani, and P. Nakov, “On the effect of dropping layers of pre-trained transformer models,”Computer Speech & Language, vol. 77, p. 101429, 2023
2023
-
[23]
The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887, 2024
A. Gromov, K. Tirumala, H. Shapourian, P. Glorioso, and D. A. Roberts, “The unreasonable ineffectiveness of the deeper layers, 2024,”URL https://arxiv. org/abs/2403.17887, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.