MassSpecGym in the Wild: Uncovering and Correcting Evaluation Pitfalls in AI-Driven Molecule Discovery
Pith reviewed 2026-06-26 20:43 UTC · model grok-4.3
The pith
Evaluation issues affect at least 17 of 26 papers using the MassSpecGym benchmark for AI molecule discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that evaluation issues in data leakage, shortcut learning, and implementation bugs and metric divergence appear in at least 17 of 26 papers using MassSpecGym, and that these corrupt the evaluation standards the benchmark was designed to enforce. Extensive experimentation and code replication quantify the impact of each class of failure and lead to concrete fixes in MassSpecGym v1.5.
What carries the argument
The manual review and classification of 26 papers into the three failure classes, supported by code replication experiments that measure how much each class distorts benchmark scores.
If this is right
- Many previously reported performance numbers on MassSpecGym cannot be trusted because they rest on flawed evaluation procedures.
- The original MassSpecGym benchmark does not by itself prevent data leakage or shortcut learning in experimental setups.
- The updated MassSpecGym v1.5 restores the intended evaluation integrity by addressing the identified failure modes.
- The distilled recommendations apply beyond MassSpecGym to other MS/MS benchmarks and custom molecule discovery evaluations.
Where Pith is reading between the lines
- Re-running published models under the v1.5 protocol could reorder which approaches appear strongest on the benchmark.
- Automated checks for leakage and shortcuts could be added to future benchmark releases in mass spectrometry machine learning.
- Similar manual audits of evaluation practices would be useful for other rapidly adopted benchmarks in AI for chemistry.
Load-bearing premise
The authors' manual review and classification of the 26 papers accurately captures the presence and impact of the three failure classes without selection bias or over-interpretation of what counts as a failure.
What would settle it
Independent teams reproducing the exact code and data splits from the 26 papers and checking each one for data leakage, shortcut learning, or metric divergence to confirm or refute the count of 17 affected papers.
Figures

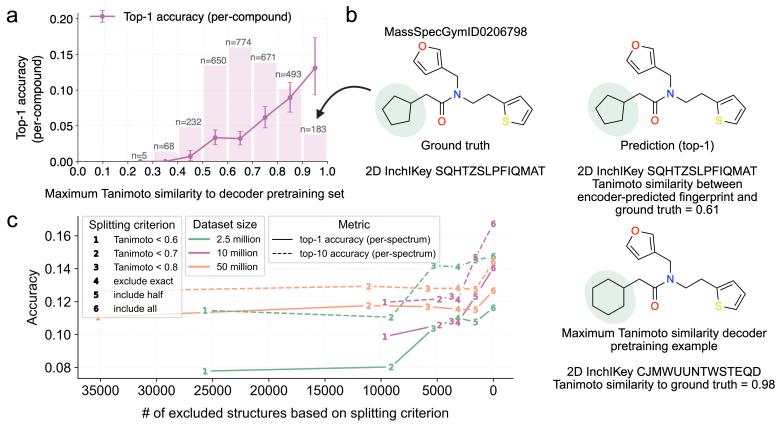
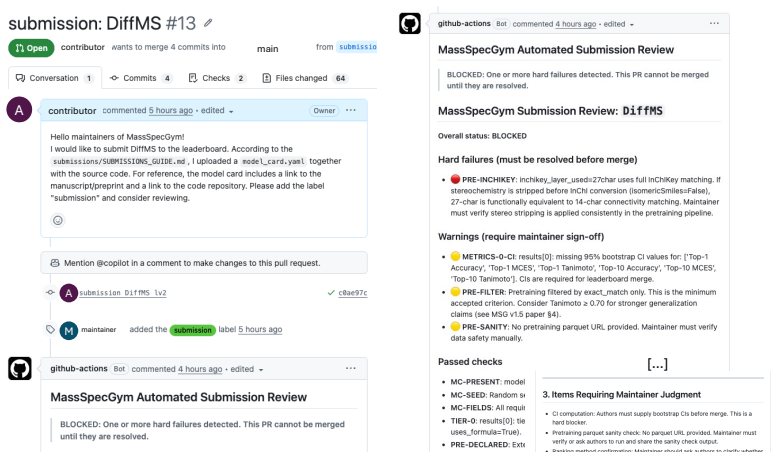
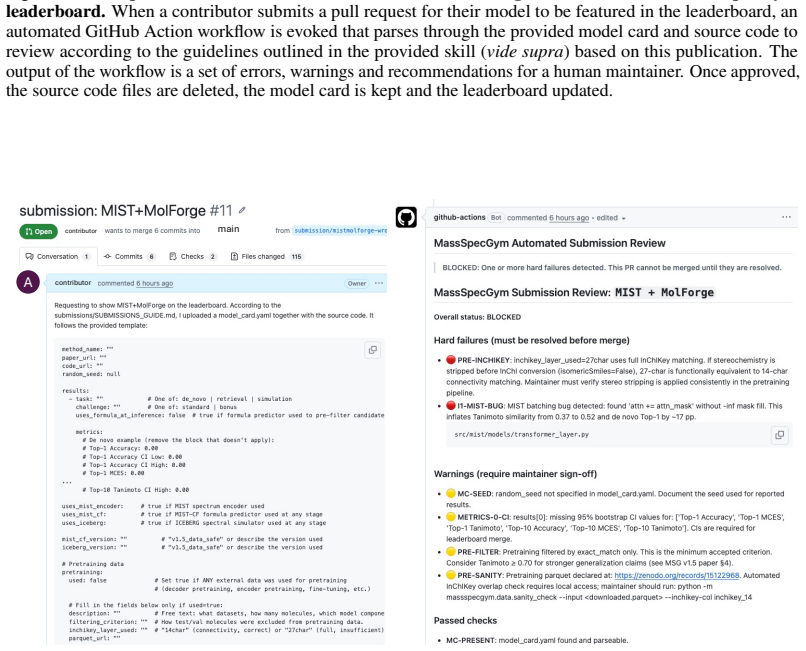
read the original abstract
Reliable benchmarking is critical for developing machine learning models for tandem mass spectrometry (MS/MS) based molecule discovery. Subtle issues in experimental design and model evaluation procedures can degrade the trustworthiness of such benchmarks and lead to erroneous conclusions. We conduct a thorough review of model evaluation issues in the recent MS/MS machine learning literature, using the standard MassSpecGym benchmark suite as a case study to illustrate the impact of these issues. We find evaluation issues in at least 17 of 26 papers reporting MassSpecGym benchmark results in the first year of its adoption. We isolate three classes of failures: (i) data leakage, (ii) shortcut learning, and (iii) implementation bugs and metric divergence. Through extensive experimentation and code replication, we quantify the impact of these issues and show how they corrupt the evaluation standards MassSpecGym was designed to enforce. We distill our findings into recommendations generalizable to MS/MS challenges, benchmarks, and custom evaluation setups. We also release MassSpecGym v1.5, an implementation of our recommendations in the MassSpecGym benchmarking suite which addresses the failure modes identified in this audit. MassSpecGym v1.5 is publicly available at https://github.com/pluskal-lab/MassSpecGym.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits 26 papers reporting results on the MassSpecGym benchmark for tandem mass spectrometry (MS/MS) molecule discovery. It claims that at least 17 of these papers exhibit evaluation issues falling into three classes—data leakage, shortcut learning, and implementation bugs/metric divergence—quantifies their impact via replication experiments, distills generalizable recommendations, and releases MassSpecGym v1.5 to correct the identified failure modes.
Significance. If the classification and impact quantification hold, the work is significant because it documents systemic evaluation problems in a rapidly adopting benchmark, directly undermining claims of progress in AI-driven MS/MS discovery. The release of v1.5 together with reproducible code for the replication experiments provides a concrete, immediately usable improvement to the community's evaluation standards.
major comments (2)
- [Literature review / methods for paper classification] The section describing the literature review and paper classification (the source of the headline 17/26 count) provides no explicit decision criteria, code-pattern definitions, or inter-rater reliability statistics for assigning papers to the three failure classes. Different reviewers could therefore produce materially different counts, rendering the central quantitative claim unverifiable from the text alone.
- [Experimental results / impact quantification] The replication experiments that are said to quantify the downstream corruption of evaluation standards are summarized at a high level but lack the precise experimental protocols, dataset splits, statistical tests, or code artifacts needed to reproduce the reported effect sizes. This prevents independent confirmation that the identified issues actually degrade the benchmark as claimed.
minor comments (2)
- [Abstract] The abstract states that the review covers "the first year of its adoption" but does not specify the exact date range or search strategy used to identify the 26 papers.
- [Figures and tables] Figure captions and table legends should explicitly state whether the reported metrics are computed on the original or corrected MassSpecGym splits.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review of our manuscript. We address each of the major comments below and have revised the manuscript accordingly to improve the transparency and reproducibility of our audit.
read point-by-point responses
-
Referee: [Literature review / methods for paper classification] The section describing the literature review and paper classification (the source of the headline 17/26 count) provides no explicit decision criteria, code-pattern definitions, or inter-rater reliability statistics for assigning papers to the three failure classes. Different reviewers could therefore produce materially different counts, rendering the central quantitative claim unverifiable from the text alone.
Authors: We agree that explicit documentation of the classification process would strengthen the verifiability of our results. In the revised manuscript, we will include a new subsection under Methods that outlines the decision criteria for each of the three failure classes, including the specific code patterns, keywords, and heuristics used to identify issues in the reviewed papers. We will also provide the full list of the 26 papers with our annotations as supplementary material. Although a formal inter-rater reliability assessment was not performed (as the review was conducted by the authors), we will describe the review protocol in detail to allow others to replicate the classification. These additions will make the 17/26 count fully verifiable from the text and supplementary materials. revision: yes
-
Referee: [Experimental results / impact quantification] The replication experiments that are said to quantify the downstream corruption of evaluation standards are summarized at a high level but lack the precise experimental protocols, dataset splits, statistical tests, or code artifacts needed to reproduce the reported effect sizes. This prevents independent confirmation that the identified issues actually degrade the benchmark as claimed.
Authors: We note that the code for all replication experiments is already released as part of the MassSpecGym v1.5 GitHub repository, which includes the exact scripts, dataset splits, and commands to reproduce the effect sizes reported in the paper. However, we acknowledge that the main text provides only high-level summaries. In the revision, we will expand the relevant experimental sections to include precise protocols, the specific dataset splits used, the statistical tests applied (e.g., paired t-tests with p-values), and direct pointers to the corresponding code files and execution commands in the repository. This will enable independent reproduction directly from the manuscript. revision: yes
Circularity Check
External literature audit with independent review and replication; no derivation chain present
full rationale
The paper performs a manual review of 26 external papers plus replication experiments to identify evaluation issues in MassSpecGym usage. Its central claim (issues in ≥17/26 papers) rests on that external classification and code inspection rather than any mathematical derivation, fitted parameter, or self-citation chain that reduces to the paper's own inputs. No equations, predictions, or uniqueness theorems are invoked that could trigger the enumerated circularity patterns. The work is self-contained against the reviewed literature as an external benchmark audit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard definitions of data leakage, shortcut learning, and implementation bugs constitute evaluation failures that corrupt benchmark standards.
Reference graph
Works this paper leans on
-
[1]
Julian Pollmann, Roman Bushuiev, Anton Bushuiev, Tomáš Pluskal, and Florian Huber. Bridg- ing ms2 spectra and chemical space: Advances in spectral similarity, molecular retrieval, and de novo structure discovery.ChemRxiv, 2026(0309), 2026. doi: 10.26434/chemrxiv.15000536/v2. URLhttps://chemrxiv.org/doi/abs/10.26434/chemrxiv.15000536/v2
-
[2]
Atanas G. Atanasov, Sergey B. Zotchev, Verena M. Dirsch, Ilkay Erdogan Orhan, Maciej Banach, Judith M. Rollinger, Davide Barreca, Wolfram Weckwerth, Rudolf Bauer, Edward A. Bayer, Muhammed Majeed, Anupam Bishayee, Valery Bochkov, Günther K. Bonn, Nady Braidy, Franz Bucar, Alejandro Cifuentes, Grazia D’Onofrio, Michael Bodkin, Marc Diederich, Albena T. Din...
-
[3]
Eberhard Breitmaier.Structure elucidation by NMR in organic chemistry: a practical guide. John Wiley & Sons, 2002. doi: 10.1002/0470853069
-
[4]
Cailum M. K. Stienstra, Jaegun Song, David Healey, Gennady V oronov, Eric Gardner, Abhishek Patel, Venkat Macherla, Christoph A. Krettler, Tobias Kind, Pieter C. Dorrestein, and Daniel Domingo-Fernández. Structure characterization with nmr molecular networking.Communi- cations Chemistry, 9(1):28, Dec 2025. ISSN 2399-3669. doi: 10.1038/s42004-025-01839-x. ...
-
[5]
Are we learning yet? A meta review of evaluation failures across machine learning
Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. Are we learning yet? A meta review of evaluation failures across machine learning. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 10
2021
-
[6]
URL https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/ hash/757b505cfd34c64c85ca5b5690ee5293-Abstract-round2.html
2021
-
[7]
An efficient P300-based brain–computer interface for disabled subjects
Rachel L. Thomas and David Uminsky. Reliance on metrics is a fundamental challenge for ai.Patterns, 3(5):100476, 2022. ISSN 2666-3899. doi: https://doi.org/10.1016/j. patter.2022.100476. URL https://www.sciencedirect.com/science/article/pii/ S2666389922000563
work page doi:10.1016/j 2022
-
[8]
Bender, Alex Hanna, and Amandalynne Paullada
Inioluwa Deborah Raji, Emily Denton, Emily M. Bender, Alex Hanna, and Amandalynne Paullada. AI and the everything in the whole wide world benchmark. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual,
2021
-
[9]
URL https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/ hash/084b6fbb10729ed4da8c3d3f5a3ae7c9-Abstract-round2.html
2021
-
[10]
de Jonge, Adamo Young, Fleming Kretschmer, Ra- man Samusevich, Janne Heirman, Fei Wang, Luke Zhang, Kai Dührkop, Marcus Ludwig, Nils A
Roman Bushuiev, Anton Bushuiev, Niek F. de Jonge, Adamo Young, Fleming Kretschmer, Ra- man Samusevich, Janne Heirman, Fei Wang, Luke Zhang, Kai Dührkop, Marcus Ludwig, Nils A. Haupt, Apurva Kalia, Corinna Brungs, Robin Schmid, Russell Greiner, Bo Wang, David S. Wishart, Liping Liu, Juho Rousu, Wout Bittremieux, Hannes Rost, Tytus D. Mak, Soha Hassoun, Flo...
2024
-
[11]
C. A. E. Goodhart.Problems of Monetary Management: The UK Experience, pages 91–
-
[12]
Macmillan Education UK, London, 1984. ISBN 978-1-349-17295-5. doi: 10.1007/ 978-1-349-17295-5_4. URLhttps://doi.org/10.1007/978-1-349-17295-5_4
-
[13]
Natural emergent misalignment from reward hacking in production rl, 2025
Monte MacDiarmid, Benjamin Wright, Jonathan Uesato, Joe Benton, Jon Kutasov, Sara Price, Naia Bouscal, Sam Bowman, Trenton Bricken, Alex Cloud, Carson Denison, Johannes Gasteiger, Ryan Greenblatt, Jan Leike, Jack Lindsey, Vlad Mikulik, Ethan Perez, Alex Rodrigues, Drake Thomas, Albert Webson, Daniel Ziegler, and Evan Hubinger. Natural emergent misalignmen...
arXiv 2025
-
[14]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 ofProceedings of Machine Learning Research, p...
2019
-
[15]
Sean Whalen, Jacob Schreiber, William S. Noble, and Katherine S. Pollard. Navigating the pitfalls of applying machine learning in genomics.Nature Reviews Genetics, 23(3):169–181, November 2021. ISSN 1471-0064. doi: 10.1038/s41576-021-00434-9. URL http://dx.doi. org/10.1038/s41576-021-00434-9
-
[16]
Have protein-ligand cofolding methods moved beyond memorisation?bioRxiv, 2025
Peter Škrinjar, Jérôme Eberhardt, Gerardo Tauriello, Torsten Schwede, and Janani Durairaj. Have protein-ligand cofolding methods moved beyond memorisation?bioRxiv, 2025. doi: 10. 1101/2025.02.03.636309. URL https://www.biorxiv.org/content/early/2025/08/ 04/2025.02.03.636309
2025
-
[18]
Rıza Özçelik and Francesca Grisoni. How evaluation choices distort the outcome of generative drug discovery.Journal of Cheminformatics, 17(1), November 2025. ISSN 1758-2946. doi: 10. 1186/s13321-025-01108-y. URLhttp://dx.doi.org/10.1186/s13321-025-01108-y. 11
-
[19]
Klau, and Sebastian Böcker
Fleming Kretschmer, Jan Seipp, Marcus Ludwig, Gunnar W. Klau, and Sebastian Böcker. Coverage bias in small molecule machine learning.Nature Communications, 16(1):554, Jan
-
[20]
doi: 10.1038/s41467-024-55462-w
ISSN 2041-1723. doi: 10.1038/s41467-024-55462-w. URL https://doi.org/10. 1038/s41467-024-55462-w
-
[21]
Emma L. Schymanski, Christoph Ruttkies, Martin Krauss, Céline Brouard, Tobias Kind, Kai Dührkop, Felicity Allen, Arpana Vaniya, Dries Verdegem, Sebastian Böcker, Juho Rousu, Huibin Shen, Hiroshi Tsugawa, Tanvir Sajed, Oliver Fiehn, Bart Ghesquière, and Steffen Neumann. Critical assessment of small molecule identification 2016: automated methods.Journal of...
-
[22]
Samuel Goldman, Jeremy Wohlwend, Martin Stražar, Guy Haroush, Ramnik J. Xavier, and Connor W. Coley. Annotating metabolite mass spectra with domain-inspired chemical formula transformers.Nature Machine Intelligence, 5(9):965–979, Sep 2023. ISSN 2522-5839. doi: 10.1038/s42256-023-00708-3. URLhttps://doi.org/10.1038/s42256-023-00708-3
-
[23]
Mingxun Wang, Jeremy J. Carver, Vanessa V . Phelan, Laura M. Sanchez, Neha Garg, Yao Peng, Don Duy Nguyen, Jeramie Watrous, Clifford A. Kapono, Tal Luzzatto-Knaan, Carla Porto, Amina Bouslimani, Alexey V . Melnik, Michael J. Meehan, Wei-Ting Liu, Max Crüsemann, Paul D. Boudreau, Eduardo Esquenazi, Mario Sandoval-Calderón, Roland D. Kersten, Laura A. Pace,...
-
[24]
Samuel Goldman, John Bradshaw, Jiayi Xin, and Connor W. Coley. Prefix-tree de- coding for predicting mass spectra from molecules. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Informa- tion Processing Systems 2023, NeurIP...
2023
-
[25]
Beck, Matthew Muhoberac, Caitlin E
Armen G. Beck, Matthew Muhoberac, Caitlin E. Randolph, Connor H. Beveridge, Prageeth R. Wijewardhane, Hilkka I. Kenttämaa, and Gaurav Chopra. Recent developments in machine learning for mass spectrometry.ACS Measurement Science Au, 4(3):233–246, 2024. doi: 10.1021/acsmeasuresciau.3c00060. URL https://doi.org/10.1021/acsmeasuresciau. 3c00060
-
[26]
Comparative analysis of formula and structure prediction from tandem mass spectra, 2026
Xujun Che, Xiuxia Du, and Depeng Xu. Comparative analysis of formula and structure prediction from tandem mass spectra, 2026. URLhttps://arxiv.org/abs/2601.00941. 12
arXiv 2026
-
[27]
Mark Yu. Schneider, Daniil D. Kholmanskikh, Kirill Ya. Romanov, Elena A. Perekina, Sergei A. Nikolenko, Ruslan Yu. Lukin, and Ivan V . Golov. De novo structure prediction from tandem mass spectra: Algorithms, benchmarks, and limitations.Molecules, 31(5), 2026. ISSN 1420-3049. doi: 10.3390/molecules31050769. URLhttps://www.mdpi.com/1420-3049/31/5/769
-
[28]
Small molecule retrieval from tandem mass spectrometry: what are we optimizing for?, 2026
Gaetan De Waele, Marek Wydmuch, Krzysztof Dembczy´nski, Wojciech Kotłowski, and Willem Waegeman. Small molecule retrieval from tandem mass spectrometry: what are we optimizing for?, 2026. URLhttps://arxiv.org/abs/2602.16507
arXiv 2026
-
[29]
Hoffmann, Fleming Kretschmer, Marcus Ludwig, and Sebastian Böcker
Martin A. Hoffmann, Fleming Kretschmer, Marcus Ludwig, and Sebastian Böcker. Mad hatter correctly annotates 98% of small molecule tandem mass spectra searching in pubchem. Metabolites, 13(3), 2023. ISSN 2218-1989. doi: 10.3390/metabo13030314. URL https: //www.mdpi.com/2218-1989/13/3/314
-
[30]
de Jonge, Kevin Mildau, David Meijer, Joris J
Niek F. de Jonge, Kevin Mildau, David Meijer, Joris J. R. Louwen, Christoph Bueschl, Florian Huber, and Justin J. J. van der Hooft. Good practices and recommendations for using and benchmarking computational metabolomics metabolite annotation tools.Metabolomics, 18 (12):103, Dec 2022. ISSN 1573-3890. doi: 10.1007/s11306-022-01963-y. URL https: //doi.org/1...
-
[31]
Michael Strobel, Alberto Gil-de-la Fuente, Mohammad Reza Zare Shahneh, Yasin El Abiead, Roman Bushuiev, Anton Bushuiev, Tomáš Pluskal, and Mingxun Wang. An evaluation method- ology for machine learning-based tandem mass spectra similarity prediction.BMC Bioinfor- matics, 26(1):174, Jul 2025. ISSN 1471-2105. doi: 10.1186/s12859-025-06194-1. URL https://doi...
-
[32]
Yunhua Zhong, Yixuan Tang, Yifan Li, Jie Yang, Pan Liu, and Jun Xia. Flexms is a flex- ible framework for benchmarking deep learning-based mass spectrum prediction tools in metabolomics, 2026. URLhttps://arxiv.org/abs/2602.22822
Pith/arXiv arXiv 2026
-
[33]
John J. Irwin, Khanh G. Tang, Jennifer Young, Chinzorig Dandarchuluun, Benjamin R. Wong, Munkhzul Khurelbaatar, Yurii S. Moroz, John Mayfield, and Roger A. Sayle. ZINC20—a free ultralarge-scale chemical database for ligand discovery.Journal of Chemical Information and Modeling, 60(12):6065–6073, 2020. doi: 10.1021/acs.jcim.0c00675
-
[34]
Jon Chambers, Mark Davies, Anna Gaulton, Anne Hersey, Sameer Velankar, Robert Petryszak, Janna Hastings, John P Overington, Christoph Steinbeck, and Andrew R Leach. UniChem: a unified chemical structure cross-referencing and identifier tracking system.Journal of Cheminformatics, 5(1):3, 2013. doi: 10.1186/1758-2946-5-3
-
[35]
MSNovelist: de novo structure generation from mass spectra.Nature Methods, 19(7):865–870, 2022
Michael A Stravs, Kai Dührkop, Sebastian Böcker, and Nicola Zamboni. MSNovelist: de novo structure generation from mass spectra.Nature Methods, 19(7):865–870, 2022. doi: 10.1038/s41592-022-01486-3
-
[36]
Neural spectral prediction for structure elucidation with tandem mass spectrometry
Runzhong Wang, Mrunali Manjrekar, Babak Mahjour, Julian Avila-Pacheco, Joules Provenzano, Erin Reynolds, Magdalena Lederbauer, Eivgeni Mashin, Samuel Goldman, Mingxun Wang, et al. Neural spectral prediction for structure elucidation with tandem mass spectrometry. BioRxiv, 2025
2025
-
[37]
Unravel- ing molecular structure: A multimodal spectroscopic dataset for chemistry
Marvin Alberts, Oliver Schilter, Federico Zipoli, Nina Hartrampf, and Teodoro Laino. Unravel- ing molecular structure: A multimodal spectroscopic dataset for chemistry. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 125780–125808. Curran Asso...
-
[38]
MIST-CF: Chemical formula inference from tandem mass spectra.J
Samuel Goldman, Jiayi Xin, Joules Provenzano, and Connor W Coley. MIST-CF: Chemical formula inference from tandem mass spectra.J. Chem. Inf. Model., 64(7):2421–2431, April 2024. 13
2024
-
[39]
SIRIUS 4: a rapid tool for turning tandem mass spectra into metabolite structure information.Nat
Kai Dührkop, Markus Fleischauer, Marcus Ludwig, Alexander A Aksenov, Alexey V Melnik, Marvin Meusel, Pieter C Dorrestein, Juho Rousu, and Sebastian Böcker. SIRIUS 4: a rapid tool for turning tandem mass spectra into metabolite structure information.Nat. Methods, 16(4): 299–302, April 2019
2019
-
[40]
Scalfani, Daniel Probst, Kazuya Ujihara, Jeremy Monat, and Juuso Lehtivarjo
Greg Landrum, Paolo Tosco, Brian Kelley, Ricardo Rodriguez, David Cosgrove, Riccardo Vianello, sriniker, Peter Gedeck, Gareth Jones, Eisuke Kawashima, NadineSchneider, Dan Nealschneider, tadhurst cdd, Andrew Dalke, Matt Swain, Brian Cole, Samo Turk, Aleksandr Savelev, Niels Maeder, Yakov Pechersky, Alain Vaucher, Maciej Wójcikowski, Rachel Walker, Hussein...
-
[41]
Apurva Kalia, Yan Zhou Chen, Dilip Krishnan, and Soha Hassoun. Jestr: Joint embedding space technique for ranking candidate molecules for the annotation of untargeted metabolomics data.Bioinformatics, 41(7):btaf354, 2025. doi: 10.1093/bioinformatics/btaf354
-
[42]
Yan Zhou Chen and Soha Hassoun. Learning from all views: A multiview contrastive framework for metabolite annotation.Analytical Chemistry, 2026. doi: 10.1021/acs.analchem.5c05675
-
[43]
FLARE: Fine-grained learning for alignment of spectra-molecule REpresentation enhances metabolite annotation.bioRxivorg, page 2026.01.27.702086, January 2026
Yan Zhou Chen, Blake Rushing, and Soha Hassoun. FLARE: Fine-grained learning for alignment of spectra-molecule REpresentation enhances metabolite annotation.bioRxivorg, page 2026.01.27.702086, January 2026
2026
-
[44]
A data attribution-based approach to model diagnosis in lc-ms/ms structure prediction
Ling Min Serena Khoo. A data attribution-based approach to model diagnosis in lc-ms/ms structure prediction. Master’s thesis, Massachusetts Institute of Technology, 2025. URL https://dspace.mit.edu/handle/1721.1/164644
2025
-
[45]
Diffms: Diffusion generation of molecules conditioned on mass spectra
Montgomery Bohde, Mrunali Manjrekar, Runzhong Wang, Shuiwang Ji, and Connor W Coley. Diffms: Diffusion generation of molecules conditioned on mass spectra. InInternational Conference on Machine Learning, pages 4737–4756. PMLR, 2025
2025
-
[46]
Neng Kai Nigel Neo, Lim Jing, Ngoui Yong Zhau Preston, Koh Xue Ting Serene, and Bingquan Shen. One small step with fingerprints, one giant leap for de novo molecule generation from mass spectra.arXiv preprint arXiv:2508.04180, 2025. doi: 10.48550/arXiv.2508.04180. Accepted at AI4Mat-NeurIPS-2025 Workshop
-
[47]
Montgomery Bohde, Hongxuan Liu, Mrunali Manjrekar, Magdalena Lederbauer, Shuiwang Ji, Runzhong Wang, and Connor W Coley. Frigid: Scaling diffusion-based molecular generation from mass spectra at training and inference time.arXiv preprint arXiv:2604.16648, 2026
Pith/arXiv arXiv 2026
-
[48]
Self-supervised learning of molecular representations from millions of tandem mass spectra using DreaMS.Nature Biotechnology, 44:630–640, April 2026
Roman Bushuiev, Anton Bushuiev, Raman Samusevich, Corinna Brungs, Josef Sivic, and Tomáš Pluskal. Self-supervised learning of molecular representations from millions of tandem mass spectra using DreaMS.Nature Biotechnology, 44:630–640, April 2026. doi: 10.1038/ s41587-025-02663-3. Published online May 23, 2025
2026
-
[49]
Design Initiative for a 10 TeV pCM Wakefield Collider,
Walid Ahmad, Elana Simon, Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. Chemberta-2: Towards chemical foundation models.CoRR, abs/2209.01712, 2022. doi: 10.48550/ARXIV .2209.01712. URLhttps://doi.org/10.48550/arXiv.2209.01712
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[50]
Ross Irwin, Spyridon Dimitriadis, Jiazhen He, and Esben Jannik Bjerrum. Chemformer: a pre- trained transformer for computational chemistry.Machine Learning: Science and Technology, 3(1):015022, 2022. doi: 10.1088/2632-2153/ac3ffb
-
[51]
Benchmarking sets for molecular docking
Niu Huang, Brian K Shoichet, and John J Irwin. Benchmarking sets for molecular docking. Journal of medicinal chemistry, 49(23):6789–6801, 2006. doi: 10.1021/jm0608356
-
[52]
cc/paper_files/paper/2021/file/ 314450613369e0ee72d0da7f6fee773c-Paper
Michael M. Mysinger, Michael Carchia, John. J. Irwin, and Brian K. Shoichet. Directory of useful decoys, enhanced (dud-e): Better ligands and decoys for better benchmarking.Journal of Medicinal Chemistry, 55(14):6582–6594, Jul 2012. ISSN 0022-2623. doi: 10.1021/jm300687e. URLhttps://doi.org/10.1021/jm300687e. 14
-
[53]
Vishu Gupta and Michael A. Skinnider. Confronting spurious evaluations of computational methods in small molecule mass spectrometry.bioRxiv, 2026. doi: 10.64898/2026.05.03.722532. URLhttps://www.biorxiv.org/content/early/2026/05/06/2026.05.03.722532
-
[54]
Christopher M Grulke, Antony J Williams, Inthirany Thillanadarajah, and Ann M Richard. EPA’s DSSTox database: History of development of a curated chemistry resource supporting computational toxicology research.Computational Toxicology, 12:100096, 2019. doi: 10.1016/ j.comtox.2019.100096
arXiv 2019
-
[55]
David S Wishart, AnChi Guo, Eponine Oler, Fei Wang, Afia Anjum, Harrison Peters, Raynard Diber, Zinat Liang, Vasuk Gautam, Dan Wishart, et al. HMDB 5.0: the human metabolome database for 2022.Nucleic Acids Research, 50(D1):D622–D631, 2022. doi: 10.1093/nar/ gkab1062
-
[56]
Maria Sorokina, Peter Merseburger, Kohulan Rajan, Mehmet Aziz Yirik, and Christoph Stein- beck. COCONUT online: Collection of open natural products database.Journal of Cheminfor- matics, 13(1):2, 2021. doi: 10.1186/s13321-020-00478-9
-
[57]
Daniil Polykovskiy, Alexander Zhebrak, Benjamin Sanchez-Lengeling, Sergey Golovanov, Oktai Tatanov, Stanislav Belyaev, Rauf Kurbanov, Aleksey Artamonov, Vladimir Aladinskiy, Mark Veselov, Artur Kadurin, Simon Johansson, Hongming Chen, Sergey Nikolenko, Alán Aspuru-Guzik, and Alex Zhavoronkov. Molecular sets (MOSES): A benchmarking platform for molecular g...
arXiv 2020
-
[58]
MADGEN: Mass-spec attends to de novo molecular generation
Yinkai Wang, Xiaohui Chen, Liping Liu, and Soha Hassoun. MADGEN: Mass-spec attends to de novo molecular generation. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=78tc3EiUrN
2025
-
[59]
MS-BART: Unified modeling of mass spectra and molecules for structure elucidation
Yang Han, Pengyu Wang, Kai Yu, Xin Chen, and Lu Chen. MS-BART: Unified modeling of mass spectra and molecules for structure elucidation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[60]
Laura Mismetti, Marvin Alberts, Andreas Krause, and Mara Graziani. Test-time tuned language models enable end-to-end de novo molecular structure generation from ms/ms spectra.arXiv preprint arXiv:2510.23746, 2025
arXiv 2025
-
[61]
MS2Mol: A transformer model for illuminating dark chemical space from mass spectra.Chem- Rxiv, September 2023
Thomas Butler, Abraham Frandsen, Rose Lightheart, Brian Bargh, Thomas Kerby, Kiana West, Joseph Davison, James Taylor, Christoph Krettler, T J Bollerman, Gennady V oronov, Kevin Moon, Tobias Kind, Pieter Dorrestein, August Allen, Viswa Colluru, and David Healey. MS2Mol: A transformer model for illuminating dark chemical space from mass spectra.Chem- Rxiv,...
2023
-
[62]
simulation_challenge
on validation loss, and the best-validation checkpoint is selected for inference. Training uses a single NVIDIA H100 GPU with 16 CPU workers and up to 200 GB of memory; all models (batch size 4) trained to convergence in approximately 7 hours over a maximum of 10 epochs. As earlier stated, we generate formula candidates from SIRIUS’s mass decomposition al...
2048
-
[63]
Read the automated report and triage any WARNINGs that require judgment
-
[64]
Fetch and read the paper if the automated LLM review flagged concerns or couldn't access the paper,→
-
[65]
Check items the automation explicitly cannot verify (listed below)
-
[66]
Do not override hard failures without a documented reason
Approve or request changes Hard failures in the automated report must be resolved by the author before you even look at the PR. Do not override hard failures without a documented reason. ,→ ,→ --- ## Submission requirements (what a valid PR must contain)
-
[67]
A new row in the correct`results/*.csv`with all required metrics and 95% bootstrap CIs,→
-
[68]
See `submissions/SUBMISSION_GUIDE.md`
A`submissions/<method_name>/model_card.yaml`filled from the template The method name in the CSV`Method`column must exactly match`method_name`in `model_card.yaml`(underscored folder name, spaced method name). See `submissions/SUBMISSION_GUIDE.md`. ,→ ,→ --- ## Step 1: Read the automated report The PR comment from the review bot contains: - **Hard failures*...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.