VIMPO: Value-Implicit Policy Optimization for LLMs
Pith reviewed 2026-06-26 17:57 UTC · model grok-4.3
The pith
VIMPO derives a policy-implied value function from KL-regularized RL optimality conditions to enable critic-free optimization for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
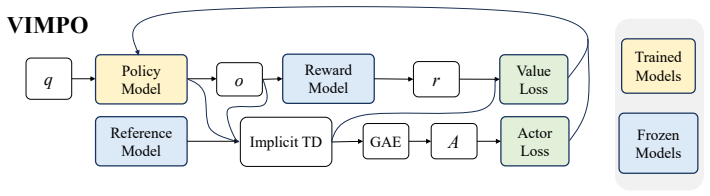
VIMPO derives a policy-implied value function from the optimality conditions of KL-regularized reinforcement learning. For autoregressive generation, the resulting value recurrence can be written in terms of policy-reference log-ratios and anchored by the terminal condition that no future reward remains at the end of a trajectory. This gives a simple value loss that incorporates outcome-level verifiable rewards without training a critic. The same derivation also yields a critic-free actor advantage, allowing VIMPO to separate reward incorporation through the value loss from policy improvement through a PPO-style actor update.
What carries the argument
Policy-implied value function derived from KL-regularized optimality conditions, expressed as a log-ratio recurrence anchored at trajectory termination.
Load-bearing premise
The value recurrence for autoregressive generation can be written in terms of policy-reference log-ratios and anchored by the terminal condition that no future reward remains at the end of a trajectory.
What would settle it
Running VIMPO and GRPO on the same set of math benchmarks and observing whether VIMPO fails to show improvement when the value loss component is removed.
Figures

read the original abstract
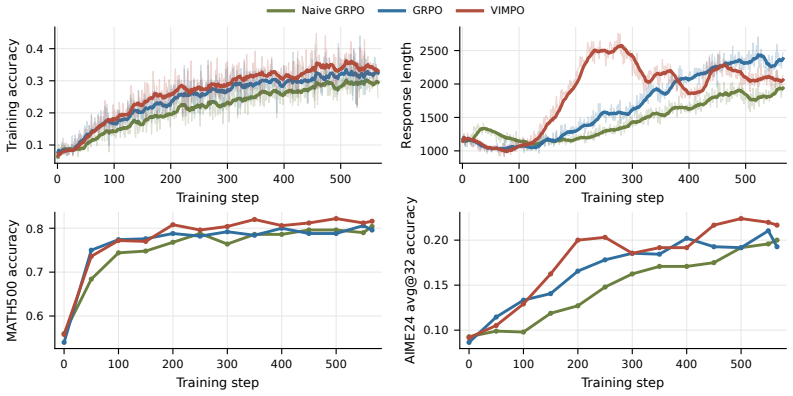
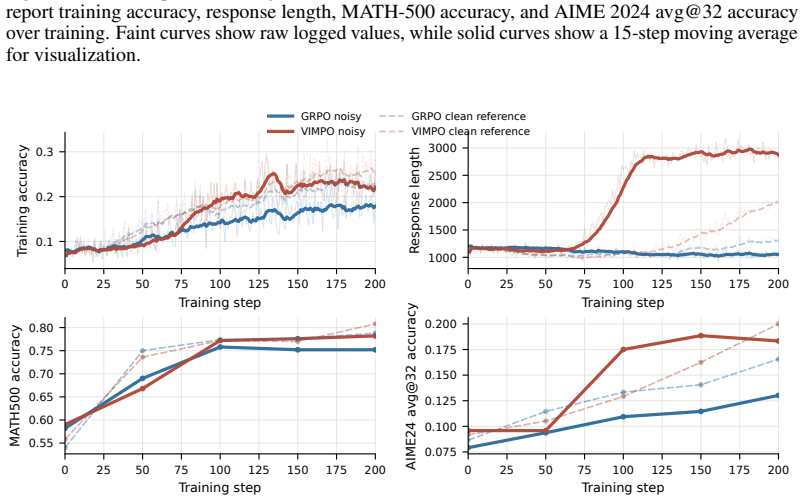
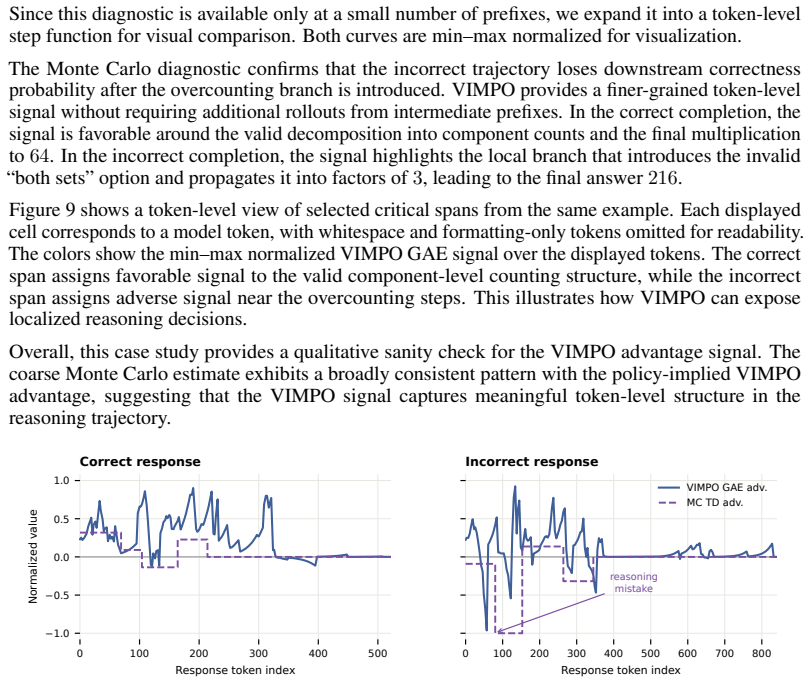
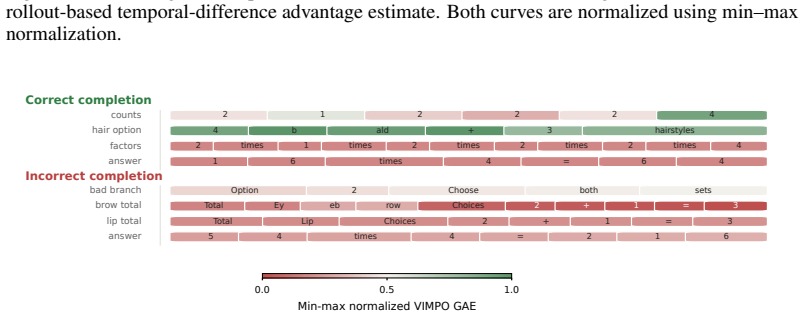
Reinforcement learning with verifiable rewards has become a central tool for improving the reasoning ability of large language models, but current methods face a trade-off between simplicity and credit assignment. Group-relative methods such as GRPO avoid training a critic, but typically assign a trajectory-level advantage to every token. Actor-critic methods provide denser learning signals, but require a learned value function with its own training instability. We introduce VIMPO, a critic-free policy optimization method that derives a policy-implied value function from the optimality conditions of KL-regularized reinforcement learning. For autoregressive generation, the resulting value recurrence can be written in terms of policy-reference log-ratios and anchored by the terminal condition that no future reward remains at the end of a trajectory. This gives a simple value loss that incorporates outcome-level verifiable rewards without training a critic. The same derivation also yields a critic-free actor advantage, allowing VIMPO to separate reward incorporation through the value loss from policy improvement through a PPO-style actor update. On mathematical RLVR benchmarks, VIMPO improves over GRPO across MATH-500, AIME 2024, AIME 2025, and OlympiadBench, with especially larger gains on competition-style evaluations. Under noisy rewards, VIMPO retains a consistent advantage over GRPO, suggesting that policy-implied value optimization can provide finer credit assignment while preserving the practical simplicity of critic-free training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VIMPO, a critic-free policy optimization method for LLMs under verifiable rewards. It derives a policy-implied value function directly from the optimality conditions of KL-regularized RL; for autoregressive generation this yields a value recurrence expressed via policy-reference log-ratios and anchored solely by the terminal condition of zero future reward. The same derivation supplies a critic-free actor advantage, enabling a value loss for reward incorporation and a PPO-style actor update for policy improvement. Experiments report consistent gains over GRPO on MATH-500, AIME 2024, AIME 2025 and OlympiadBench (larger on competition problems) together with retained advantage under noisy rewards.
Significance. If the central derivation is free of hidden assumptions on reference-policy cancellation or advantage separation, VIMPO would supply a practical middle path between the coarse credit assignment of group-relative methods and the instability of learned critics. The reported robustness to reward noise and the differential gains on harder benchmarks would then constitute a concrete empirical contribution to RLVR for reasoning models.
major comments (2)
- [Value recurrence derivation (Methods section)] Value recurrence derivation (Methods section): the manuscript states that the recurrence follows directly from KL-regularized optimality conditions and is anchored only by the terminal condition. It must be shown explicitly that the reference policy continuation value cancels exactly under outcome-only rewards; otherwise the claimed separation of value loss from actor advantage may not hold and the method could reduce to a reparameterized form of GRPO rather than delivering distinct finer credit assignment.
- [Results section] Experimental claims (Results section): the reported improvements over GRPO are presented without error bars, number of independent runs, or statistical significance tests. This information is load-bearing for the claim of “especially larger gains on competition-style evaluations” and for the assertion of consistent advantage under noisy rewards.
minor comments (1)
- [Abstract] The acronym RLVR is used without an initial definition; a parenthetical expansion on first use would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the value recurrence derivation and the experimental reporting. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Value recurrence derivation (Methods section)] Value recurrence derivation (Methods section): the manuscript states that the recurrence follows directly from KL-regularized optimality conditions and is anchored only by the terminal condition. It must be shown explicitly that the reference policy continuation value cancels exactly under outcome-only rewards; otherwise the claimed separation of value loss from actor advantage may not hold and the method could reduce to a reparameterized form of GRPO rather than delivering distinct finer credit assignment.
Authors: The derivation starts from the KL-regularized optimality condition for the soft value function under a reference policy. For outcome-only rewards the terminal condition is V_T = 0. Expanding the soft Bellman equation yields a recurrence in which the reference-policy continuation value appears symmetrically in both the log-ratio term and the subtracted future-value term; these cancel exactly, leaving a value expressed solely in policy-reference log-ratios anchored at the terminal zero. This cancellation is what permits the separate value loss and actor advantage. We will add a fully expanded, line-by-line derivation in the Methods section to make the cancellation explicit. revision: yes
-
Referee: [Results section] Experimental claims (Results section): the reported improvements over GRPO are presented without error bars, number of independent runs, or statistical significance tests. This information is load-bearing for the claim of “especially larger gains on competition-style evaluations” and for the assertion of consistent advantage under noisy rewards.
Authors: We agree that the current results lack the statistical detail needed to support the strength of the claims. In the revision we will report means and standard deviations over multiple independent runs, include error bars on all figures, and add statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing VIMPO against GRPO on each benchmark and under noisy rewards. revision: yes
Circularity Check
Derivation from standard KL-regularized optimality conditions is self-contained
full rationale
The central claim derives a policy-implied value recurrence directly from the optimality conditions of KL-regularized RL, expressed via policy-reference log-ratios and anchored only by the terminal condition of zero future reward. No self-citations, fitted parameters renamed as predictions, or self-definitional steps are present in the provided description. The separation of value loss from PPO-style actor update follows from the same optimality conditions without reducing to GRPO by construction. This is a standard theoretical derivation in RL and remains independent of the paper's own inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2506.14965. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617,
-
[2]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[3]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiad- bench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
-
[4]
Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
10 Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[5]
Software package. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Alex Low, Alan Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
-
[6]
Yang Li, Zhichen Dong, Yuhan Sun, Weixun Wang, Shaopan Xiong, Yijia Luo, Jiashun Liu, Han Lu, Jiamang Wang, Wenbo Su, Bo Zheng, and Junchi Yan. Attention illuminates llm reason- ing: The preplan-and-anchor rhythm enables fine-grained policy optimization.arXiv preprint arXiv:2510.13554,
-
[7]
Chiyu Ma, Shuo Yang, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang, Bolin Ding, Soroush V osoughi, Guoyin Wang, and Jingren Zhou. Fipo: Eliciting deep reasoning with future-kl influenced policy optimization.arXiv preprint arXiv:2603.19835,
-
[8]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[9]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[10]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256,
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256,
-
[11]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
-
[12]
Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
11 Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[13]
Yufeng Yuan, Yu Yue, Ruofei Zhu, Tiantian Fan, and Lin Yan. What’s behind ppo’s collapse in long-cot? value optimization holds the secret.arXiv preprint arXiv:2503.01491,
-
[14]
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, Tiantian Fan, Zhengyin Du, Xiangpeng Wei, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118,
-
[15]
Method- specific VIMPO coefficients are reported in Section 4.1
12 A Experimental Details A.1 Shared hyperparameters Table 2 lists the hyperparameters shared by GRPO and VIMPO in the main experiments. Method- specific VIMPO coefficients are reported in Section 4.1. Table 2: Shared experimental hyperparameters for GRPO and VIMPO. Hyperparameter Value Base model Qwen3-4B-Base Training data Guru Math subset, 54.4K exampl...
2048
-
[16]
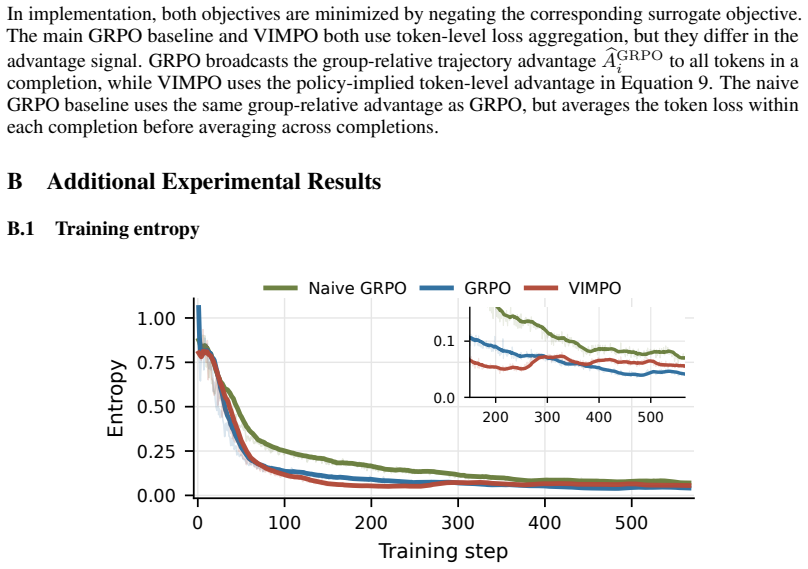
The naive GRPO baseline uses the same group-relative advantage as GRPO, but averages the token loss within each completion before averaging across completions. B Additional Experimental Results B.1 Training entropy 0 100 200 300 400 500 Training step 0.00 0.25 0.50 0.75 1.00 Entropy Naive GRPO GRPO VIMPO 200 300 400 500 0.0 0.1 Figure 6: Training entropy ...
2025
-
[17]
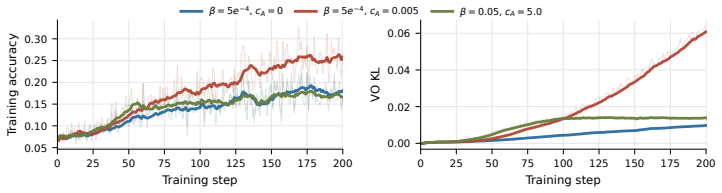
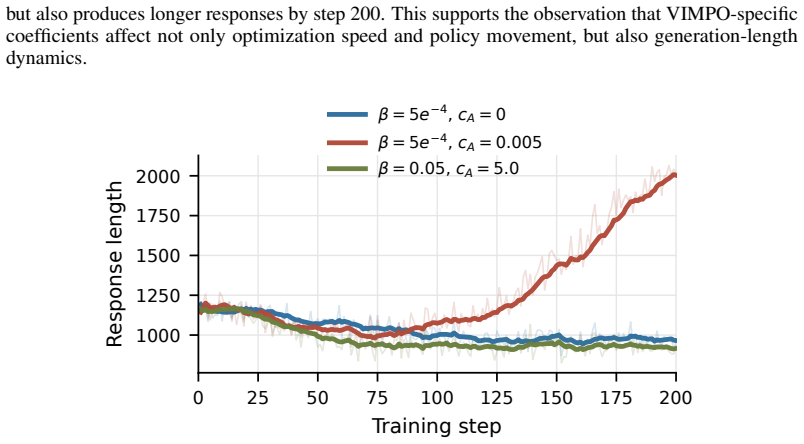
This supports the observation that VIMPO-specific coefficients affect not only optimization speed and policy movement, but also generation-length dynamics. 0 25 50 75 100 125 150 175 200 Training step 1000 1250 1500 1750 2000 Response length β = 5e−4, cA = 0 β = 5e−4, cA = 0.005 β = 0.05, cA = 5.0 Figure 7: Response-length dynamics for the VIMPO coefficie...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.