Multi-Modal Contrastive Learning for Implicit Earth Embeddings via Location Tying
Pith reviewed 2026-06-26 18:11 UTC · model grok-4.3
The pith
Two new architectures for multimodal contrastive learning on geospatial data match existing two-modality performance but show no benefit from additional modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
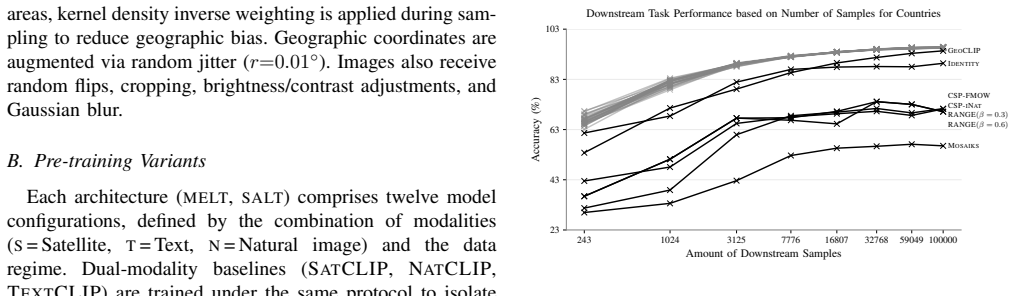
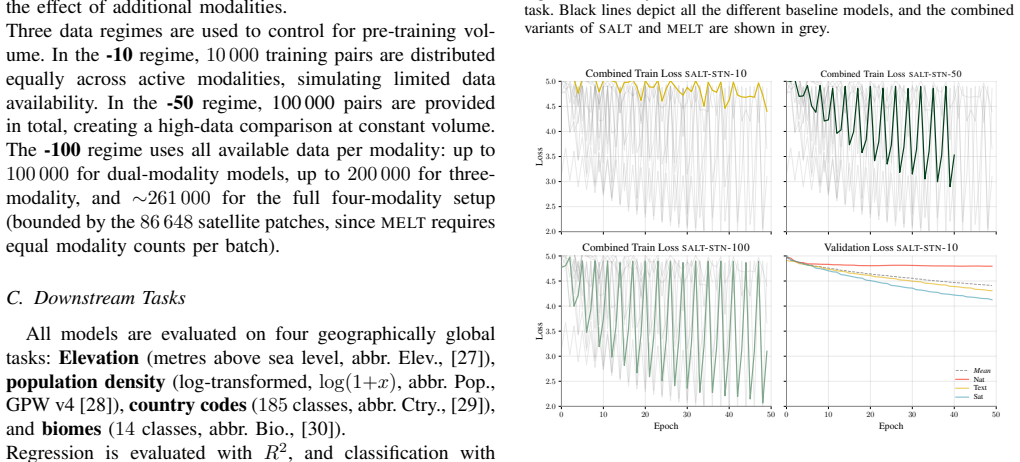
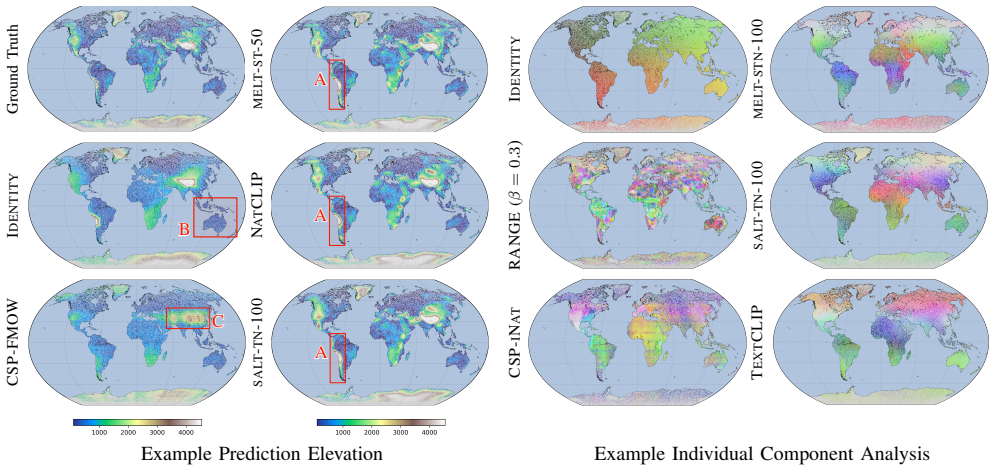
MELT and SALT are two multimodal contrastive learning architectures that expand the framework beyond two modalities by utilising unpaired geospatial data. Both match the performance of SATCLIP across four downstream tasks, but increasing the number of modalities does not consistently improve performance, suggesting that the chosen location encoder is the main limitation.
What carries the argument
MELT (Multimodal Embedding via Location Tying) and SALT (Sequential Alternating Location Training) architectures that tie multiple modalities to locations for contrastive learning.
If this is right
- MELT provides more stable training than SALT.
- The contrastive objective reaches its peak early, regardless of modality diversity or pre-training volume.
- Both methods are viable for using unpaired geospatial data across more than two modalities.
- Future scaling efforts should target the location encoder architecture instead of adding modalities.
Where Pith is reading between the lines
- The saturation pattern implies that contrastive objectives on current location encoders may have a hard capacity limit independent of modality count.
- Testing the same contrastive setup with stronger or differently structured location encoders could determine whether multimodal data can produce gains under different conditions.
- The location-tying mechanism could apply to other coordinate-based domains that have abundant unpaired multi-modal observations.
Load-bearing premise
The assumption that the location encoder architecture rather than the contrastive objective, data quality, or training procedure is the primary factor preventing gains from additional modalities.
What would settle it
An experiment ablating or replacing the location encoder with an alternative architecture and then measuring whether adding modalities produces consistent performance gains would test whether the encoder is the main limit.
Figures

read the original abstract
Spatial prediction tasks are often limited by a lack of high-quality labelled ground-truth observations. To overcome this challenge, self-supervised pre-training is a possible solution, with contrastive learning dominant for location encoders. Those approaches usually align geographic coordinates with just one additional modality. We propose two multimodal contrastive learning architectures: Multimodal Embedding via Location Tying (MELT) and Sequential Alternating Location Training (SALT). These architectures expand this framework beyond two modalities by utilising unpaired geospatial data. Both methods are technically viable and match the performance of the strongest two-modality baseline (SATCLIP) across four downstream tasks. However, increasing the number of modalities does not consistently improve performance, suggesting that the chosen location encoder is the main limitation - the contrastive objective reaches its peak early, regardless of modality diversity or pre-training volume. MELT provides more stable training than SALT and presents a stronger foundation for future scaling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two multi-modal contrastive learning architectures, MELT (Multimodal Embedding via Location Tying) and SALT (Sequential Alternating Location Training), to learn implicit earth embeddings from unpaired geospatial data across more than two modalities. It claims that both methods match the performance of the strongest two-modality baseline (SATCLIP) on four downstream tasks, but that increasing the number of modalities yields no consistent gains; this leads to the conclusion that the chosen location encoder architecture is the primary limitation because the contrastive objective reaches its peak early. MELT is reported to provide more stable training than SALT.
Significance. If the empirical claims hold after verification, the work would usefully extend contrastive pre-training for location encoders to handle unpaired multi-modal geospatial data, addressing a practical constraint in spatial prediction tasks. The finding that additional modalities do not help could usefully redirect attention toward encoder capacity rather than objective or data volume. No machine-checked proofs or parameter-free derivations are present, but the downstream-task evaluation setup provides a concrete, falsifiable test of the multi-modal tying approach.
major comments (2)
- [abstract and experimental results] The central claim that MELT and SALT match SATCLIP performance is stated without any quantitative metrics, standard deviations, error bars, or per-task numbers in the abstract and is not accompanied by ablation tables that isolate the contribution of the multi-modal tying objectives; this absence prevents verification of whether the match is within statistical noise or holds across all four tasks.
- [discussion of results and limitations] The inference that the location encoder (rather than contrastive loss formulation, unpaired alignment quality, or optimization) is the main limitation is drawn solely from the observed performance plateau when modalities are added; no ablation is reported that varies encoder depth, width, or architecture family while holding the MELT/SALT objectives fixed, so the evidence does not distinguish among candidate causes.
minor comments (2)
- [abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., average downstream accuracy or rank) to support the matching claim.
- [method sections] Notation for the location-tying mechanism and the sequential alternating schedule should be defined explicitly with a small diagram or pseudocode to clarify how unpaired data are aligned across modalities.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the presentation of results and claims.
read point-by-point responses
-
Referee: [abstract and experimental results] The central claim that MELT and SALT match SATCLIP performance is stated without any quantitative metrics, standard deviations, error bars, or per-task numbers in the abstract and is not accompanied by ablation tables that isolate the contribution of the multi-modal tying objectives; this absence prevents verification of whether the match is within statistical noise or holds across all four tasks.
Authors: We agree that the abstract would be strengthened by including quantitative support. The main text reports per-task results with standard deviations across multiple runs for all four downstream tasks. We will revise the abstract to include these key metrics with error bars. We will also add or explicitly highlight ablation tables that isolate the contribution of the multi-modal tying objectives versus the baseline two-modality setup. revision: yes
-
Referee: [discussion of results and limitations] The inference that the location encoder (rather than contrastive loss formulation, unpaired alignment quality, or optimization) is the main limitation is drawn solely from the observed performance plateau when modalities are added; no ablation is reported that varies encoder depth, width, or architecture family while holding the MELT/SALT objectives fixed, so the evidence does not distinguish among candidate causes.
Authors: The consistent performance plateau across increasing numbers of modalities and pre-training volumes, despite the contrastive objective having access to more diverse unpaired data, supports our interpretation that the location encoder capacity is the primary constraint. We acknowledge that this evidence is indirect and that controlled ablations varying encoder depth, width, or family while fixing the MELT/SALT objectives would be required to more definitively rule out other factors. We will revise the discussion and limitations sections to present the conclusion as a well-supported hypothesis rather than a definitive attribution and to note the absence of such encoder ablations as a limitation. revision: partial
Circularity Check
No circularity; empirical evaluation is self-contained
full rationale
The manuscript proposes MELT and SALT multi-modal contrastive architectures and reports downstream-task performance that matches the SATCLIP baseline. The inference that the location encoder is the limiting factor is drawn from observed performance plateaus across modality counts; this is an empirical observation, not a derivation, fitted parameter, or self-referential equation. No equations, self-citations, or ansatzes are presented that reduce the central claims to their own inputs by construction. The work relies on external benchmarks and is therefore scored at the low end of the non-circular range.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive loss can align location coordinates with multiple unpaired modalities when the encoder is fixed.
Reference graph
Works this paper leans on
-
[1]
K. Klemmer et al., ”Earth Embeddings: Towards ai-centric represen- tations of our planet,” EarthArXiv, Dec. 2025. [Online]. Available: https://doi.org/10.31223/X5HX9S
-
[2]
Mai et al., ”A review of location encoding for GeoAI: Methods and applications,” Int
G. Mai et al., ”A review of location encoding for GeoAI: Methods and applications,” Int. J. Geogr. Inf. Sci., vol. 36, no. 4, pp. 639–673, 2022
2022
-
[3]
Klemmer, E
K. Klemmer, E. Rolf, C. Robinson, L. Mackey, and M. Rußwurm, ”SatCLIP: Global, general-purpose location embeddings with satellite imagery,” in Proc. 39th AAAI Conf. Artificial Intelligence (AAAI), 2025
2025
-
[4]
V . V . Cepeda, G. K. Nayak, and M. Shah, ”GeoCLIP: CLIP-inspired alignment between locations and images for effective worldwide geo- localization,” in Proc. 37th Int. Conf. Neural Information Processing Systems (NeurIPS), 2023
2023
-
[5]
G. Mai, N. Lao, Y . He, J. Song, and S. Ermon, ”CSP: Self-supervised contrastive spatial pre-training for geospatial-visual representations,” in Proc. 40th Int. Conf. Machine Learning (ICML), 2023
2023
-
[6]
Dhakal, S
A. Dhakal, S. Sastry, S. Khanal, A. Ahmad, E. Xing, and N. Jacobs, ”RANGE: Retrieval augmented neural fields for multi-resolution geo- embeddings,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2025, pp. 24680–24689
2025
-
[7]
C. F. Brown et al., ”AlphaEarth foundations: An embedding field model for accurate and efficient global mapping from sparse label data,” arXiv:2507.22291 [cs.CV], Sep. 2025
Pith/arXiv arXiv 2025
-
[8]
M. J. de Smith, M. F. Goodchild, and P. Longley, Geospatial analysis: A comprehensive guide to principles, techniques and software tools, 7th ed. Drumlin Security, 2024
2024
-
[9]
Li et al., ”GeoAI for science and the science of GeoAI,” J
W. Li et al., ”GeoAI for science and the science of GeoAI,” J. Spatial Inf. Sci., no. 29, pp. 1–17, 2024
2024
-
[10]
Janowicz, S
K. Janowicz, S. Gao, G. McKenzie, Y . Hu, and B. Bhaduri, ”GeoAI: Spatially explicit artificial intelligence techniques for geographic knowledge discovery and beyond,” Int. J. Geogr. Inf. Sci., vol. 34, no. 4, pp. 625–636, 2020
2020
-
[11]
A. Rao, M. Rußwurm, K. Klemmer, and E. Rolf, ”Measuring the in- trinsic dimension of earth representations,” arXiv:2511.02101 [cs.LG], 2026
arXiv 2026
-
[12]
Cong et al., ”SatMAE: Pre-training transformers for temporal and multi-spectral satellite imagery,” in Proc
Y . Cong et al., ”SatMAE: Pre-training transformers for temporal and multi-spectral satellite imagery,” in Proc. 36th Int. Conf. Neural Information Processing Systems (NeurIPS), 2022
2022
-
[13]
Liu et al., ”RemoteCLIP: A vision language foundation model for remote sensing,” IEEE Trans
F. Liu et al., ”RemoteCLIP: A vision language foundation model for remote sensing,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–16, 2024
2024
-
[14]
Khanal, S
S. Khanal, S. Sastry, A. Dhakal and N. Jacobs, ”Learning tri-modal embeddings for zero-shot soundscape mapping”, in Proc. British Machine Vision Conference, 2023, pp. 1-13
2023
-
[15]
Dhakal, S
A. Dhakal, S. Khanal, S. Sastry, A. Ahmad and N. Jacobs, ”GeoBind: Binding text, image, and audio through satellite images”, IGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 2024, pp. 2729-2733
2024
-
[16]
Sastry, S
S. Sastry, S. Khanal, A. Dhakal, A. Ahmad and N. Jacobs, ”Tax- aBind: A unified embedding space for ecological applications,” 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), Tucson, AZ, USA, 2025, pp. 1765-1774
2025
-
[17]
Girdhar et al., ”ImageBind: One embedding space to bind them all,” in Proc
R. Girdhar et al., ”ImageBind: One embedding space to bind them all,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 15180–15190
2023
-
[18]
Mai et al., ”SRL: Towards a general-purpose framework for spatial representation learning,” in Proc
G. Mai et al., ”SRL: Towards a general-purpose framework for spatial representation learning,” in Proc. 32nd ACM Int. Conf. Advances in Geographic Information Systems (SIGSPATIAL), 2024, pp. 465–468
2024
-
[19]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, ”A simple frame- work for contrastive learning of visual representations,” in Proc. 37th Int. Conf. Machine Learning (ICML), 2020
2020
-
[20]
Rußwurm, K
M. Rußwurm, K. Klemmer, E. Rolf, R. Zbinden, and D. Tuia, ”Geographic location encoding with spherical harmonics and sinu- soidal representation networks,” in Proc. International Conference on Learning Representations (ICLR), 2024, pp. 1746–1759
2024
-
[21]
Sitzmann, J
V . Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein, ”Implicit neural representations with periodic activation functions,” in Proc. 34th Int. Conf. Neural Information Processing Systems (NeurIPS), 2020
2020
-
[22]
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, ”Momentum Contrast for Unsupervised Visual Representation Learning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9729–9738
2020
-
[23]
Caron et al., ”Emerging Properties in Self-Supervised Vision Trans- formers,” in Proc
M. Caron et al., ”Emerging Properties in Self-Supervised Vision Trans- formers,” in Proc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2021, pp. 9650–9660
2021
-
[24]
S. Xiao, Z. Liu, P. Zhang, N. Muennighoff, D. Lian, and J.-Y . Nie, ”C-Pack: Packed resources for general Chinese embeddings,” in Proc. 47th Int. ACM SIGIR Conf. Research and Development in Information Retrieval, 2024, pp. 641–649
2024
-
[25]
Larson, M
M. Larson, M. Soleymani, G. Gravier, B. Ionescu, and G. J. Jones, ”The benchmarking initiative for multimedia evaluation: MediaEval 2016,” IEEE MultiMedia, vol. 24, no. 1, pp. 93–96, 2017
2016
-
[26]
Thomee, D
B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland, D. Borth, and L.-J. Li, ”YFCC100M: The new data in multimedia research,” Commun. ACM, vol. 59, no. 2, pp. 64–73, 2016
2016
-
[27]
[Online]
Global Administrative Areas (GADM), ”GADM database of global administrative areas, Version 4.1,” 2022. [Online]. Available: https://gadm.org/download world.html. [Accessed: 07-May-2025]
2022
-
[28]
Center for International Earth Science Information Network (CIESIN), ”Documentation for the gridded population of the world, Ver- sion 4 (GPWv4), Revision 11 Data Sets,” Columbia Uni- versity, Palisades, NY , Tech. Rep., 2018. [Online]. Available: https://doi.org/10.7927/H45Q4T5F. [Accessed: 09-Sep-2025]
-
[29]
[Online]
Mapzen and Sentinel Hub, ”Mapzen terrain tiles — digital el- evation model,” Sentinel Hub Collections, 2017. [Online]. Avail- able: https://collections.sentinel-hub.com/mapzen-dem/. [Accessed: 07-May-2025]
2017
-
[30]
D. M. Olson et al., ”Terrestrial ecoregions of the world: A new map of life on earth,” BioScience, vol. 51, no. 11, pp. 933–938, 2001
2001
-
[31]
Rolf et al., ”A generalizable and accessible approach to machine learning with global satellite imagery,” Nature Commun., vol
E. Rolf et al., ”A generalizable and accessible approach to machine learning with global satellite imagery,” Nature Commun., vol. 12, no. 1, 2021
2021
-
[32]
R. Balestriero and Y . LeCun, ”LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics,” arXiv:2511.08544 [cs.LG], 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.