ELADO: Elliptic PDE Assessment Datasets for Operator Learning
Pith reviewed 2026-06-26 18:17 UTC · model grok-4.3
The pith
ELADO benchmark datasets isolate how heavy-tailed targets, spectral shifts, and input sensitivity degrade neural operator accuracy on elliptic PDEs in ways mean relative L2 error misses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ELADO supplies datasets generated by a controllable process around Poisson's and Helmholtz equations that separately isolate heavy-tailed solution distributions, spectral input shifts, frequency-domain heavy tails, input sensitivity, and signal complexity effects; across tested neural operator architectures these factors each produce substantial prediction degradation that the mean relative L2 error metric can obscure.
What carries the argument
A controllable data-generating process that creates separate datasets each isolating one source of difficulty for elliptic PDE operator learning.
If this is right
- Heavy-tailed solution distributions from light-tailed coefficient fields reduce prediction accuracy.
- Spectral distribution shifts between training and test inputs degrade operator performance.
- Input sensitivity, quantified by empirical local Lipschitz analysis, leads to larger errors on certain inputs.
- Heavy tails in the frequency domain of solutions arise even from light-tailed coefficients and hurt accuracy.
- Standard mean relative L2 error can mask these specific failure modes on elliptic PDE tasks.
Where Pith is reading between the lines
- New evaluation metrics that separately track tail behavior and spectral properties may be needed alongside average error.
- Architectures could incorporate explicit normalization or frequency-aware layers to mitigate the isolated sensitivities.
- The same isolation approach could be applied to time-dependent or nonlinear PDEs to check whether the same failure modes dominate.
Load-bearing premise
The controllable data-generating process isolates each targeted difficulty without creating confounding interactions among them.
What would settle it
Training the same neural operator architectures on the ELADO datasets and finding that mean relative L2 error fully tracks the observed accuracy losses with no extra degradation attributable to heavy tails, spectral shift, or input sensitivity.
Figures

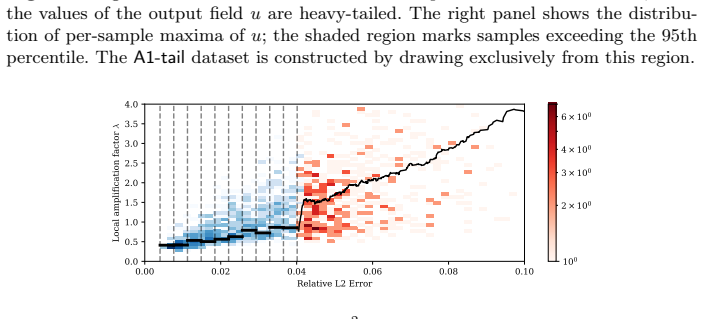
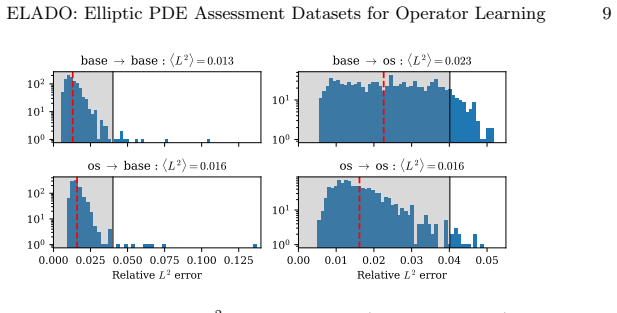
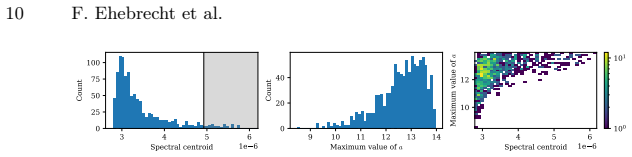
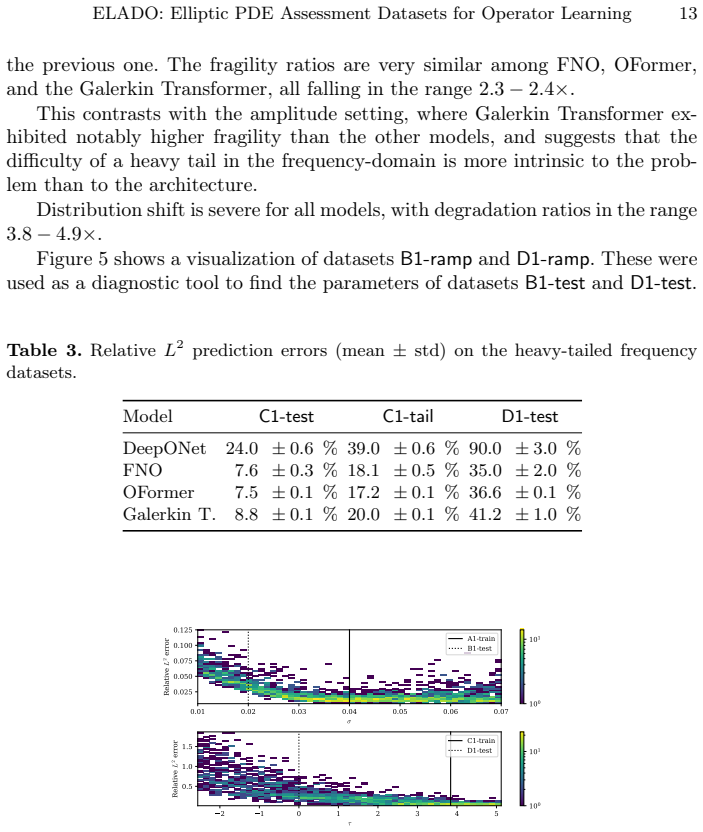
read the original abstract
We introduce ELADO (Elliptic PDE Assessment Datasets for Operator Learning), a systematic benchmark suite constructed to show and quantify failure modes of neural operator architectures when learning solution operators of elliptic PDEs. While the benchmarks of existing datasets focus on average case performance, the ELADO datasets are constructed to highlight challenges that arise naturally in elliptic PDE problems. In particular, we construct several datasets built around Poisson's equation and the Helmholtz equation, each with non-constant coefficients. We define a controllable data-generating process to create datasets, that are designed to isolate a distinct source of difficulty. Specifically, these are (1) heavy-tailed solution distributions arising from light-tailed coefficient field distributions, (2) spectral distribution shift of the input data, (3) heavy-tailed distributions in the frequency domain of solutions, arising from light-tailed coefficient field distributions, (4) input sensitivity of learned operators, quantified by an empirical local Lipschitz analysis, and (5) the effect of input signal complexity on prediction accuracy under controlled amplitude normalization. We evaluate several neural operator architectures across all datasets and show that heavy-tailed targets, spectral shift, and input sensitivity each cause substantial degradation of the prediction accuracy that standard datasets and metrics (e.g., the mean relative $L^2$ error) may obscure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ELADO, a benchmark suite of datasets for neural operator learning on elliptic PDEs (Poisson and Helmholtz with non-constant coefficients). It defines a controllable data-generating process intended to isolate five distinct difficulties: (1) heavy-tailed solution distributions from light-tailed coefficient fields, (2) spectral distribution shift in inputs, (3) heavy-tailed frequency content in solutions, (4) input sensitivity measured by empirical local Lipschitz constants, and (5) input complexity under amplitude normalization. Evaluations of several neural operator architectures on these datasets are reported to show that heavy-tailed targets, spectral shift, and input sensitivity produce substantial accuracy degradation that is obscured by standard mean relative L² error on conventional benchmarks.
Significance. If the claimed isolation holds and the datasets are released with reproducible generation code, ELADO would supply a useful addition to the operator-learning literature by moving beyond average-case metrics to targeted stress tests for elliptic problems. The empirical focus and explicit construction of failure-mode-specific data are strengths that could guide architecture improvements, provided the attribution of performance drops to individual factors is secured.
major comments (2)
- [Data Generation / Methods] The central claim that each dataset isolates one targeted difficulty without confounding interactions is load-bearing for all reported conclusions, yet the manuscript provides no verification (e.g., cross-measurement of spectral content or local Lipschitz constants on the heavy-tailed-coefficient dataset) that the DGP achieves orthogonality; elliptic Green's functions couple coefficient statistics to both solution tails and eigenstructure, so the attribution step remains unsecured.
- [Evaluation Results] § on evaluation results: the abstract asserts 'substantial degradation' and that standard metrics 'may obscure' it, but no quantitative tables, error bars, or comparisons against baseline datasets are supplied in the available text; without these numbers the practical magnitude of the claimed effect cannot be assessed.
minor comments (2)
- [Abstract] The abstract lists five datasets but does not name the specific neural operator architectures evaluated or the precise PDE instances (e.g., domain, boundary conditions) used for each.
- [Methods] Notation for the empirical local Lipschitz analysis and the amplitude-normalization procedure should be defined explicitly before the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Data Generation / Methods] The central claim that each dataset isolates one targeted difficulty without confounding interactions is load-bearing for all reported conclusions, yet the manuscript provides no verification (e.g., cross-measurement of spectral content or local Lipschitz constants on the heavy-tailed-coefficient dataset) that the DGP achieves orthogonality; elliptic Green's functions couple coefficient statistics to both solution tails and eigenstructure, so the attribution step remains unsecured.
Authors: We agree that explicit verification of isolation is necessary to support the attribution of performance drops to individual factors. The data-generating process was designed with independent controls on coefficient statistics, spectral properties, and amplitude, but we did not include cross-dataset measurements in the original submission. In the revised version we will add these verifications, reporting spectral content, frequency-domain statistics, and empirical local Lipschitz constants across all datasets to quantify any residual confounding. We will also discuss the role of the elliptic Green's function and how the chosen parameter ranges limit unintended couplings. revision: yes
-
Referee: [Evaluation Results] § on evaluation results: the abstract asserts 'substantial degradation' and that standard metrics 'may obscure' it, but no quantitative tables, error bars, or comparisons against baseline datasets are supplied in the available text; without these numbers the practical magnitude of the claimed effect cannot be assessed.
Authors: We apologize that the quantitative results were not presented with sufficient detail in the reviewed manuscript. The full paper contains evaluations of multiple neural operator architectures on each dataset, but we will expand the evaluation section to include complete tables of mean relative L² errors with standard deviations across repeated runs, together with direct comparisons against conventional benchmarks. These additions will make the magnitude of the reported degradation and the limitations of average-case metrics explicit. revision: yes
Circularity Check
No significant circularity: empirical benchmark construction with no derivations or self-referential loops
full rationale
The paper presents an empirical benchmark suite for neural operators on elliptic PDEs, defining controllable data-generating processes to create datasets targeting specific difficulties (heavy-tailed solutions, spectral shifts, etc.). No derivation chain, first-principles predictions, fitted parameters renamed as outputs, or load-bearing self-citations appear in the abstract or described structure. The work is self-contained as dataset construction and evaluation against external architectures and metrics, with no steps reducing by construction to their own inputs. Attribution of failure modes to isolated factors is an empirical claim open to external verification rather than a logical reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Reviews Physics6(5), 320–328 (2024)
Azizzadenesheli, K., Kovachki, N., Li, Z., Liu-Schiaffini, M., Kossaifi, J., Anandku- mar, A.: Neural operators for accelerating scientific simulations and design. Nature Reviews Physics6(5), 320–328 (2024)
2024
-
[2]
IEEE transactions on neural networks6(4), 911–917 (1995)
Chen, T., Chen, H.: Universal approximation to nonlinear operators by neural net- works with arbitrary activation functions and its application to dynamical systems. IEEE transactions on neural networks6(4), 911–917 (1995)
1995
-
[3]
arXiv preprint arXiv:2209.15616 (2022)
Gupta, J.K., Brandstetter, J.: Towards multi-spatiotemporal-scale generalized pde modeling. arXiv preprint arXiv:2209.15616 (2022)
-
[4]
Kovachki, N.B., Li, Z.Y., Liu, B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A.M., Anandkumar, A.: Neural operator: Learning maps between function spaces. arXivabs/2108.08481(2021)
-
[5]
JMLR24(388), 1–26 (2023)
Li, Z., Huang, D.Z., Liu, B., Anandkumar, A.: Fourier neural operator with learned deformations for pdes on general geometries. JMLR24(388), 1–26 (2023)
2023
-
[6]
Fourier Neural Operator for Parametric Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., Anandkumar, A.: Fourier neural operator for parametric partial differential equa- tions. arXiv preprint arXiv:2010.08895 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Stuart, A., Bhattacharya, K., Anandkumar, A.: Multipole graph neural operator for parametric partial differen- tial equations. Proc. NeurIPS33, 6755–6766 (2020)
2020
-
[8]
arXiv preprint arXiv:2111.04860 (2021)
Liu, L., Cai, W.: Multiscale deeponet for nonlinear operators in oscillatory function spaces for building seismic wave responses. arXiv preprint arXiv:2111.04860 (2021)
-
[9]
arXiv preprint arXiv:2209.08397 (2022)
Liu, L., Nath, K., Cai, W.: A causality-deeponet for causal responses of linear dynamical systems. arXiv preprint arXiv:2209.08397 (2022)
-
[10]
Lu, L., Jin, P., Karniadakis, G.E.: Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
- [11]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.