Objective-Behavior Alignment: Diagnostics for MORL Policy Selection
Pith reviewed 2026-06-26 14:32 UTC · model grok-4.3
The pith
Policies achieving similar objective trade-offs in multi-objective reinforcement learning can still differ substantially in their actual behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
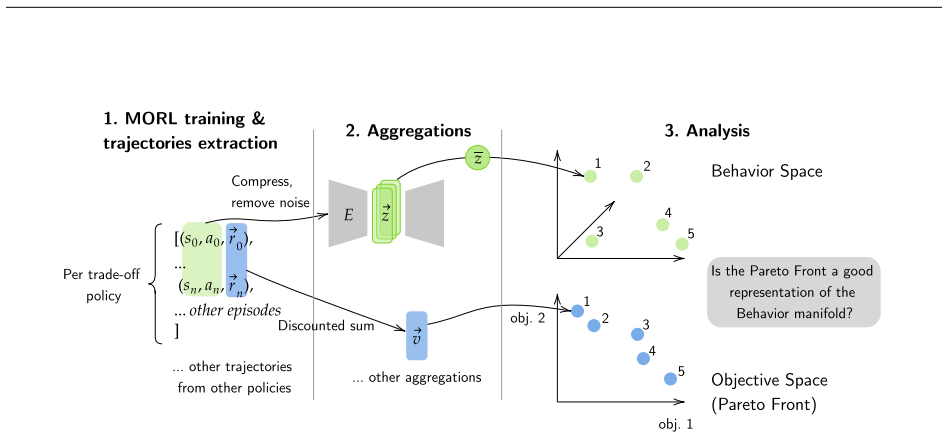
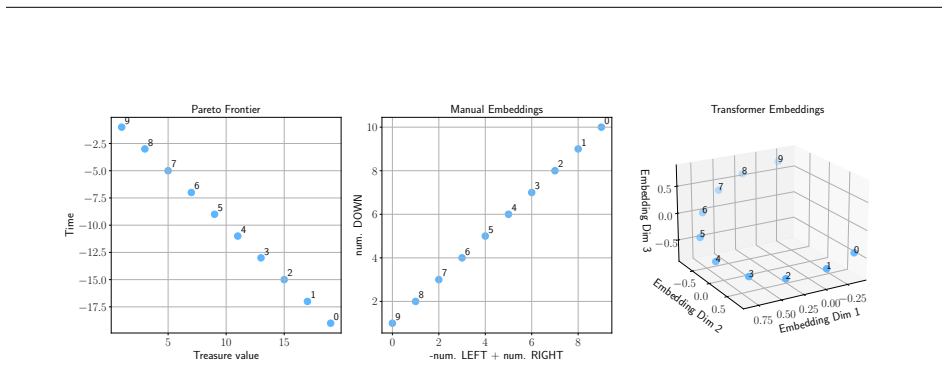
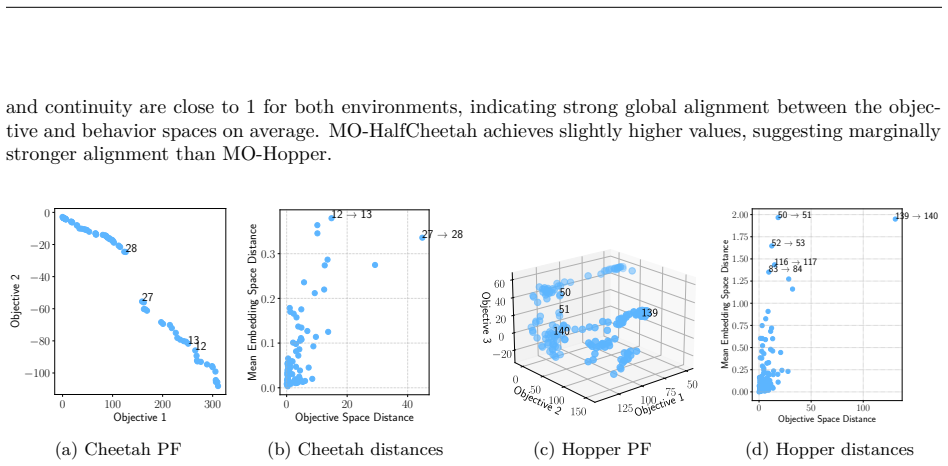
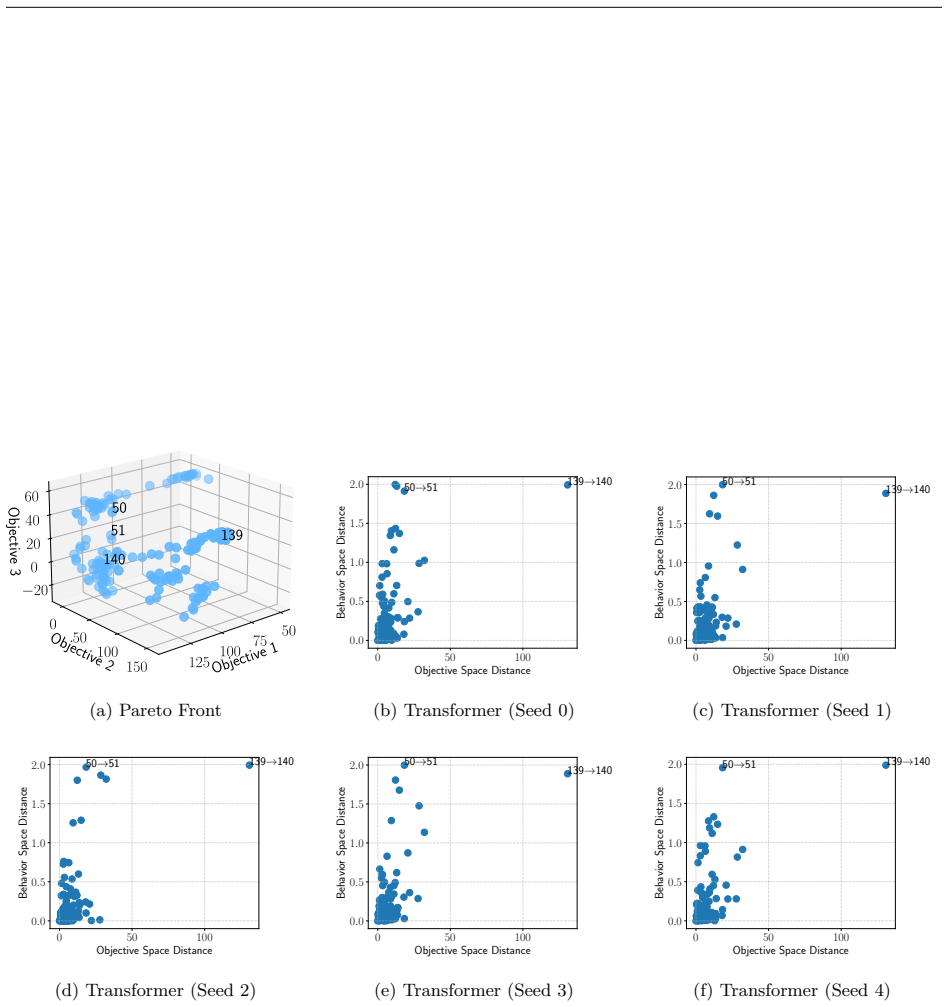
The paper claims that value vectors alone can obscure substantial behavioral variation among policies on the Pareto front in MORL, and introduces an exploratory diagnostic workflow that highlights this variation using quantitative and visual tools, validated on gridworld examples and continuous control benchmarks.
What carries the argument
The exploratory diagnostic workflow that automatically highlights behavioral variation along the Pareto front.
Load-bearing premise
That policies with similar value vectors exhibit substantial behavioral variation that the diagnostic workflow can detect and present usefully.
What would settle it
Running the workflow on a set of policies known to have identical behaviors but similar values and finding that it reports no variation, or failing to detect differences in cases where behaviors clearly differ.
Figures





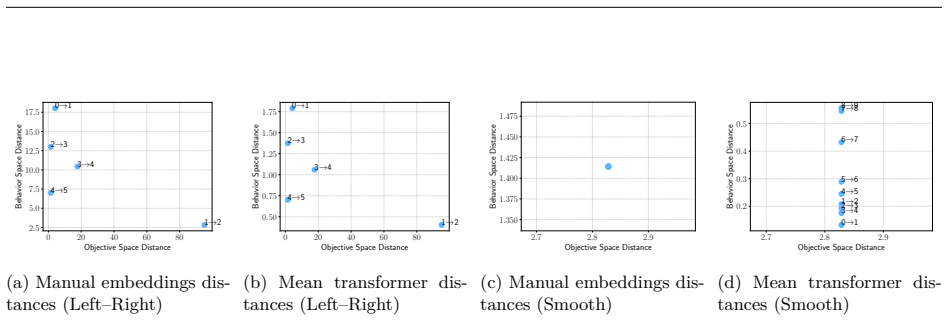
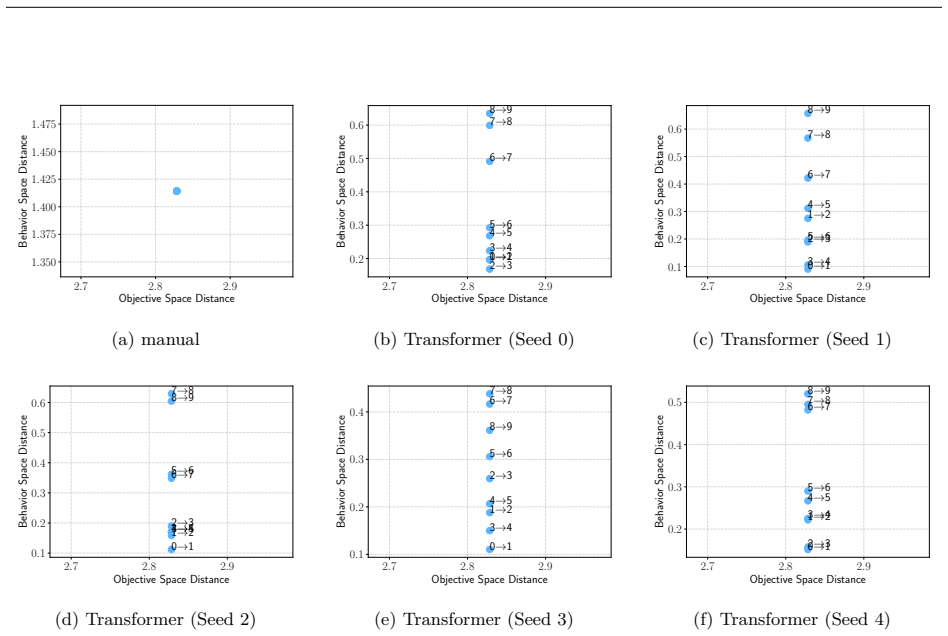
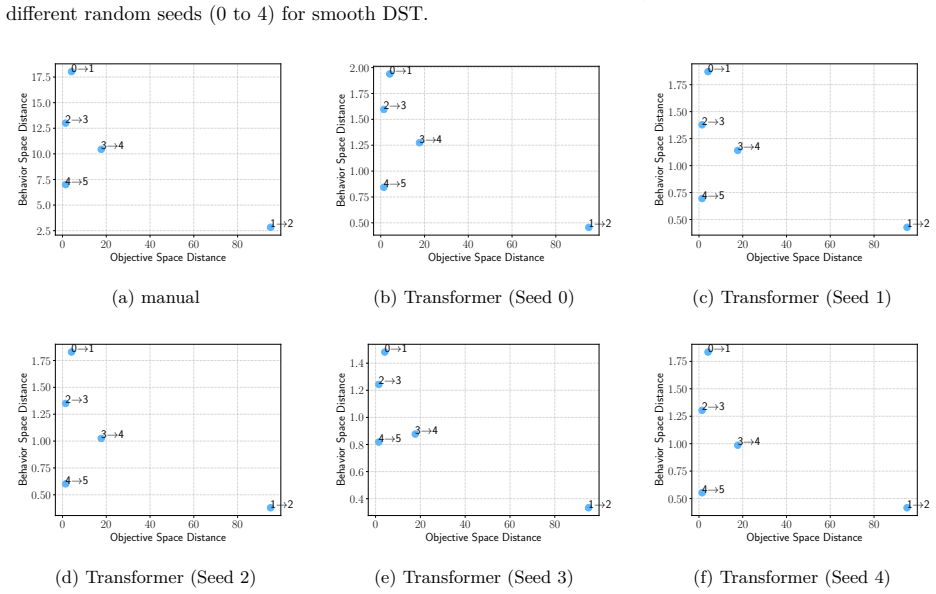
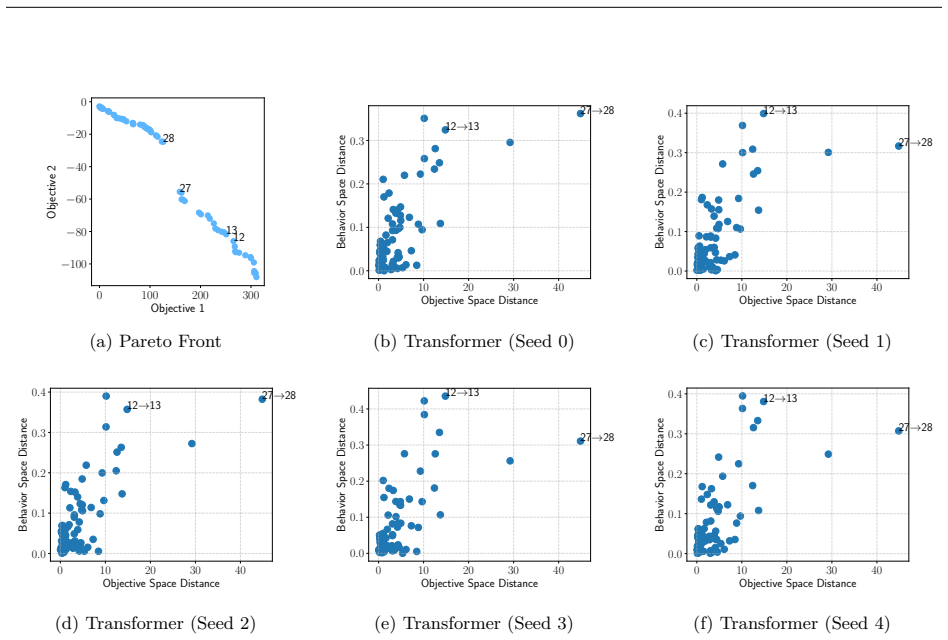
read the original abstract
Real-world decision-making often requires optimizing multiple competing objectives simultaneously. In reinforcement learning (RL), this is typically addressed by combining reward signals into a single scalar objective via a scalarization function, which can be fragile: small changes in the weights can induce drastically different policies. Multi-objective reinforcement learning (MORL) instead produces sets of policies that explicitly represent trade-offs between objectives. However, these policies are typically presented to the decision maker only through their value vectors, which can obscure substantial behavioral variation: policies that induce distinct trajectories may appear indistinguishable when evaluated solely by expected returns. We propose an exploratory diagnostic workflow that automatically highlights behavioral variation along the Pareto front that objective values alone do not reveal, providing both quantitative and visual tools to support policy inspection. We validate our approach on simple grid examples and scale it to continuous control benchmarks, demonstrating that it remains effective as problem complexity increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an exploratory diagnostic workflow for multi-objective reinforcement learning (MORL) that automatically highlights behavioral variation along the Pareto front not revealed by objective value vectors alone. It supplies quantitative and visual tools to support policy inspection and claims validation on grid examples scaled to continuous control benchmarks, showing the workflow remains effective as complexity increases.
Significance. If the workflow reliably detects and presents behavioral differences among policies with similar value vectors, it could meaningfully aid decision-making in applied MORL settings by moving beyond scalarized or vector-valued summaries. The scaling claim to continuous-control domains is a positive indicator of practicality, but the absence of any reported metrics, baselines, or error analysis makes the practical significance difficult to gauge from the manuscript.
major comments (1)
- [Abstract] Abstract: the manuscript states that the workflow is validated on grid examples and continuous control benchmarks 'demonstrating that it remains effective as problem complexity increases,' yet supplies no methods, quantitative results, error analysis, or comparison to existing MORL inspection techniques. This directly undermines assessment of the central claim that the diagnostic reveals behaviorally distinct policies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that the workflow is validated on grid examples and continuous control benchmarks 'demonstrating that it remains effective as problem complexity increases,' yet supplies no methods, quantitative results, error analysis, or comparison to existing MORL inspection techniques. This directly undermines assessment of the central claim that the diagnostic reveals behaviorally distinct policies.
Authors: The manuscript presents the diagnostic workflow through a series of illustrative case studies on grid environments and continuous-control tasks. These examples include both visual trajectory comparisons and quantitative measures (e.g., divergence metrics between policies that share similar value vectors) to show that behavioral differences exist and can be surfaced by the workflow. We acknowledge, however, that the abstract's claim of demonstrating effectiveness as complexity increases is stated without accompanying error bars, statistical tests, or explicit comparisons to prior MORL inspection methods. We will revise the abstract to describe the validation as exploratory and illustrative rather than comprehensive, and we will add a dedicated limitations subsection that discusses the absence of baselines and outlines directions for more rigorous quantitative evaluation. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents a methodological proposal for an exploratory diagnostic workflow in MORL without equations, fitted parameters, derivations, or self-citation chains that reduce claims to inputs by construction. Validation is descriptive on gridworlds and benchmarks; no load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial Neural Networks —
Jarkko Venna and Samuel Kaski , title =. Artificial Neural Networks —. 2001 , doi =
2001
-
[2]
W. Bradley Knox and Alessandro Allievi and Holger Banzhaf and Felix Schmitt and Peter Stone , keywords =. Reward (Mis)design for autonomous driving , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.artint.2022.103829 , url =
-
[3]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
The Perils of Trial-and-Error Reward Design: Misdesign through Overfitting and Invalid Task Specifications , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , month=. doi:10.1609/aaai.v37i5.25733 , abstractNote=
-
[4]
Todorov, Emanuel and Erez, Tom and Tassa, Yuval , month = oct, year =. 2012. doi:10.1109/IROS.2012.6386109 , abstract =
-
[5]
Journal of Artificial Intelligence Research , author =
A. Journal of Artificial Intelligence Research , author =. 2013 , note =. doi:10.1613/jair.3987 , abstract =
-
[6]
Outracing champion. Nature , author =. 2022 , note =. doi:10.1038/s41586-021-04357-7 , language =
-
[7]
Jeon, Hyeon and Kuo, Yun-Hsin and Aupetit, Michael and Ma, Kwan-Liu and Seo, Jinwook , journal=. 2024 , volume=. doi:10.1109/TVCG.2023.3327187 , url =
-
[8]
Advances in Neural Information Processing Systems , volume=
Lipschitz regularity of deep neural networks: analysis and efficient estimation , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Grigory Khromov and Sidak Pal Singh , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[10]
2019 , publisher=
Lipschitz functions , author=. 2019 , publisher=
2019
-
[11]
Felten, Florian and Ucak, Umut and Azmani, Hicham and Peng, Gao and Röpke, Willem and Baier, Hendrik and Mannion, Patrick and Roijers, Diederik M. and Terry, Jordan K. and Talbi, El-Ghazali and Danoy, Grégoire and Nowé, Ann and Rădulescu, Roxana , month = jul, year =. doi:10.48550/arXiv.2407.16312 , abstract =
-
[12]
Felten, Florian , month = jun, year =. Multi-
-
[13]
Haarnoja, Tuomas and Zhou, Aurick and Abbeel, Pieter and Levine, Sergey , month = jul, year =. Soft. Proceedings of the 35th
-
[14]
IEEE Transactions on Evolutionary Computation , author =. 2007 , note =. doi:10.1109/TEVC.2007.892759 , number =
-
[15]
Journal of Artificial Intelligence Research , volume=
Multi-objective reinforcement learning based on decomposition: A taxonomy and framework , author=. Journal of Artificial Intelligence Research , volume=
-
[16]
Greenwade
George D. Greenwade. The C omprehensive T ex A rchive N etwork ( CTAN ). TUGBoat. 1993
1993
-
[17]
Journal of computational and applied mathematics , volume=
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author=. Journal of computational and applied mathematics , volume=. 1987 , publisher=
1987
-
[18]
Similarity Search and Applications: 12th International Conference, SISAP 2019, Newark, NJ, USA, October 2--4, 2019, Proceedings 12 , pages=
Faster k-medoids clustering: improving the PAM, CLARA, and CLARANS algorithms , author=. Similarity Search and Applications: 12th International Conference, SISAP 2019, Newark, NJ, USA, October 2--4, 2019, Proceedings 12 , pages=. 2019 , organization=
2019
-
[19]
Parallel Problem Solving from Nature-PPSN VIII: 8th International Conference, Birmingham, UK, September 18-22, 2004
Finding knees in multi-objective optimization , author=. Parallel Problem Solving from Nature-PPSN VIII: 8th International Conference, Birmingham, UK, September 18-22, 2004. Proceedings 8 , pages=. 2004 , organization=
2004
-
[20]
International conference on machine learning , pages=
Dynamic weights in multi-objective deep reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[21]
Hubert, Lawrence and Arabie, Phipps , date =. Comparing partitions , url =. Journal of Classification , number =. 1985 , bdsk-url-1 =. doi:10.1007/BF01908075 , id =
-
[22]
Adaptive Agents and Multi-Agent Systems , year=
HIGHLIGHTS: Summarizing Agent Behavior to People , author=. Adaptive Agents and Multi-Agent Systems , year=
-
[23]
The Journal of Machine Learning Research , volume=
Multi-objective reinforcement learning using sets of pareto dominating policies , author=. The Journal of Machine Learning Research , volume=. 2014 , publisher=
2014
-
[24]
2021 , eprint=
A Review of the Deep Sea Treasure problem as a Multi-Objective Reinforcement Learning Benchmark , author=. 2021 , eprint=
2021
-
[25]
Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems , pages =
Torrey, Lisa and Taylor, Matthew , title =. Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems , pages =. 2013 , isbn =
2013
-
[26]
Efficient Reinforcement Learning with Multiple Reward Functions for Randomized Controlled Trial Analysis , year =
Lizotte, Daniel and Bowling, Michael and Murphy, Susan , journal =. Efficient Reinforcement Learning with Multiple Reward Functions for Randomized Controlled Trial Analysis , year =
-
[27]
Journal of Experimental & Theoretical artificial intelligence , volume=
Multi-objective optimization of radiotherapy: distributed Q-learning and agent-based simulation , author=. Journal of Experimental & Theoretical artificial intelligence , volume=. 2017 , publisher=
2017
-
[28]
Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages =
Li, Changjian and Czarnecki, Krzysztof , title =. Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages =. 2019 , isbn =
2019
-
[29]
Journal of Water Resources Planning and Management , volume=
Curses, tradeoffs, and scalable management: Advancing evolutionary multiobjective direct policy search to improve water reservoir operations , author=. Journal of Water Resources Planning and Management , volume=. 2016 , publisher=
2016
-
[30]
Tree-based Fitted Q-iteration for Multi-Objective Markov Decision problems , year=
Castelletti, Andrea and Pianosi, Francesca and Restelli, Marcello , booktitle=. Tree-based Fitted Q-iteration for Multi-Objective Markov Decision problems , year=
-
[31]
I Don’t Think So
“I Don’t Think So”: Summarizing Policy Disagreements for Agent Comparison , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Deepsynth: Automata synthesis for automatic task segmentation in deep reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Establishing appropriate trust via critical states , author=. 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2018 , organization=
2018
-
[34]
IJCAI: proceedings of the conference , volume=
Exploring computational user models for agent policy summarization , author=. IJCAI: proceedings of the conference , volume=. 2019 , organization=
2019
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Iterative bounding mdps: Learning interpretable policies via non-interpretable methods , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[36]
Proceedings of the International Conference on Automated Planning and Scheduling , volume=
Tldr: Policy summarization for factored ssp problems using temporal abstractions , author=. Proceedings of the International Conference on Automated Planning and Scheduling , volume=
-
[37]
International conference on machine learning , pages=
Graying the black box: Understanding dqns , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Generation of policy-level explanations for reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
International conference on machine learning , pages=
Prediction-guided multi-objective reinforcement learning for continuous robot control , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[40]
Computers & Operations Research , volume=
Multi-objective optimization models for patient allocation during a pandemic influenza outbreak , author=. Computers & Operations Research , volume=. 2014 , publisher=
2014
-
[41]
GitHub repository , howpublished =
Leurent, Edouard , title =. GitHub repository , howpublished =. 2018 , publisher =
2018
-
[42]
Roijers and Frans A
Zuzanna Osika and Jazmin ZatarainSalazar and Diederik M. Roijers and Frans A. Oliehoek and Pradeep K. Murukannaiah , title =. Proceedings of the 32nd International Joint Conference on Artificial Intelligence , series =. 2023 , address =
2023
-
[43]
Coello , booktitle=
Falcón-Cardona, Jesús Guillermo and Ishibuchi, Hisao and Coello, Carlos A. Coello , booktitle=. Riesz s-energy-based Reference Sets for Multi-Objective optimization , year=
-
[44]
and Bazzan, Ana L
Alegre, Lucas N. and Bazzan, Ana L. C. and Roijers, Diederik M. and Now\'. Sample-Efficient Multi-Objective Learning via Generalized Policy Improvement Prioritization , year =. Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages =
2023
-
[45]
Milani, Stephanie and Topin, Nicholay and Veloso, Manuela and Fang, Fei , title =. ACM Comput. Surv. , month =. 2023 , publisher =. doi:10.1145/3616864 , abstract =
-
[46]
and Vamplew, Peter and Whiteson, Shimon and Dazeley, Richard , title =
Roijers, Diederik M. and Vamplew, Peter and Whiteson, Shimon and Dazeley, Richard , title =. J. Artif. Int. Res. , month =. 2013 , issue_date =
2013
-
[47]
Alegre and Florian Felten and El-Ghazali Talbi and Gr
Lucas N. Alegre and Florian Felten and El-Ghazali Talbi and Gr. Proceedings of the 34th Benelux Conference on Artificial Intelligence BNAIC/Benelearn 2022 , year =
2022
-
[48]
and Nowé, Ann , booktitle=
Van Moffaert, Kristof and Drugan, Madalina M. and Nowé, Ann , booktitle=. Scalarized multi-objective reinforcement learning: Novel design techniques , year=
-
[49]
Pareto-Set Analysis: Biobjective Clustering in Decision and Objective Spaces , url =
Ulrich, Tamara , doi =. Pareto-Set Analysis: Biobjective Clustering in Decision and Objective Spaces , url =. 2013 , bdsk-url-1 =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/mcda.1477 , journal =
-
[50]
Coit and Alexandra Brintrup and Anupong Wannakrairot and Ajith Kumar Parlikad , doi =
Sanyapong Petchrompo and David W. Coit and Alexandra Brintrup and Anupong Wannakrairot and Ajith Kumar Parlikad , doi =. A review of Pareto pruning methods for multi-objective optimization , url =. Computers & Industrial Engineering , keywords =. 2022 , bdsk-url-1 =
2022
-
[51]
Ng and Kalyanmoy Deb , doi =
Sunith Bandaru and Amos H.C. Ng and Kalyanmoy Deb , doi =. Data mining methods for knowledge discovery in multi-objective optimization: Part A - Survey , url =. Expert Systems with Applications , keywords =. 2017 , bdsk-url-1 =
2017
-
[52]
Journal of Building Engineering , volume=
Multi-objective optimization methodology for net zero energy buildings , author=. Journal of Building Engineering , volume=. 2018 , publisher=
2018
-
[53]
IEEE Transactions on Industrial Electronics , volume=
Multiobjective gas turbine engine controller design using genetic algorithms , author=. IEEE Transactions on Industrial Electronics , volume=. 1996 , publisher=
1996
-
[54]
Evolutionary computation , volume=
Multi-objective genetic algorithms: Problem difficulties and construction of test problems , author=. Evolutionary computation , volume=. 1999 , publisher=
1999
-
[55]
Felten, Florian and Alegre, Lucas N. and Now. A Toolkit for Reliable Benchmarking and Research in Multi-Objective Reinforcement Learning , booktitle =
-
[56]
Machine Learning , year=
Hypervolume indicator and dominance reward based multi-objective Monte-Carlo Tree Search , author=. Machine Learning , year=
-
[57]
Quinn, J. D. and Reed, P. M. and Giuliani, M. and Castelletti, A. , title =. Water Resources Research , volume =. doi:https://doi.org/10.1029/2018WR024177 , url =. https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2018WR024177 , abstract =
-
[58]
IEEE Transactions on Transportation Electrification , year=
Multi-Objective Battery Charging Strategy Based on Deep Reinforcement Learning , author=. IEEE Transactions on Transportation Electrification , year=
-
[59]
Automation in Construction , volume=
Multi-objective reinforcement learning for autonomous drone navigation in urban areas with wind zones , author=. Automation in Construction , volume=. 2024 , publisher=
2024
-
[60]
IEEE Access , year=
Multi-Objective Reinforcement Learning for Power Allocation in Massive MIMO Networks: A Solution to Spectral and Energy Trade-Offs , author=. IEEE Access , year=
-
[61]
Autonomous Agents and Multi-Agent Systems , volume=
A practical guide to multi-objective reinforcement learning and planning , author=. Autonomous Agents and Multi-Agent Systems , volume=. 2022 , publisher=
2022
-
[62]
Is Conditional Generative Modeling all you need for Decision-Making?
Anurag Ajay and Yilun Du and Abhi Gupta and Joshua B. Tenenbaum and Tommi S. Jaakkola and Pulkit Agrawal , title =. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2211.15657 , eprinttype =. 2211.15657 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.15657 2022
-
[63]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Carroll, Micah and Paradise, Orr and Lin, Jessy and Georgescu, Raluca and Sun, Mingfei and Bignell, David and Milani, Stephanie and Hofmann, Katja and Hausknecht, Matthew and Dragan, Anca and Devlin, Sam , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[64]
Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages =
Ge, Zichang and Chen, Changyu and Sinha, Arunesh and Varakantham, Pradeep , title =. Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages =. 2025 , isbn =
2025
-
[65]
ECAI , year=
Navigating Trade-offs: Policy Summarization for Multi-Objective Reinforcement Learning , author=. ECAI , year=
-
[66]
International Conference on Learning Representations , year=
Evolutionary diversity optimization with clustering-based selection for reinforcement learning , author=. International Conference on Learning Representations , year=
-
[67]
arXiv preprint arXiv:1802.06971 , year=
A survey on trajectory clustering analysis , author=. arXiv preprint arXiv:1802.06971 , year=
-
[68]
Information systems , volume=
Time-series clustering--a decade review , author=. Information systems , volume=. 2015 , publisher=
2015
-
[69]
Empirical evaluation methods for multiobjective reinforcement learning algorithms , volume =. Machine Learning , author =. 2011 , pages =. doi:10.1007/s10994-010-5232-5 , abstract =
-
[70]
Felten, Florian and Danoy, Grégoire and Talbi, El-Ghazali and Bouvry, Pascal , year =. Metaheuristics-based. Proceedings of the 14th. doi:10.5220/0010989100003116 , language =
-
[71]
Autonomous Agents and Multi-Agent Systems , author =
Scalar reward is not enough: a response to. Autonomous Agents and Multi-Agent Systems , author =. 2022 , keywords =. doi:10.1007/s10458-022-09575-5 , abstract =
-
[72]
Abhishek Vivekanandan and Christian Hubschneider and J. Marius Z. Contrast. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.02571 , eprinttype =. 2506.02571 , timestamp =
-
[73]
Yanchuan Chang and Jianzhong Qi and Yuxuan Liang and Egemen Tanin , title =. 39th. 2023 , url =. doi:10.1109/ICDE55515.2023.00224 , timestamp =
-
[74]
Learning Options via Compression , url =
Yiding Jiang and Evan Zheran Liu and others , bibsource =. Learning Options via Compression , url =. Adv. Neural Inf. Process. Syst. (NIPS) , timestamp =
-
[75]
Gomez and Lukasz Kaiser and Illia Polosukhin , bibsource =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , bibsource =. Attention is All you Need , url =. Adv. Neural Inf. Process. Syst. (NIPS) , pages =
-
[76]
Trading positional complexity vs deepness in coordinate networks , year =
Zheng, Jianqiao and Ramasinghe, Sameera and others , booktitle =. Trading positional complexity vs deepness in coordinate networks , year =. doi:http://dx.doi.org/10.1007/978-3-031-19812-0_9 , organization =
-
[77]
Learnable Fourier Features for Multi-dimensional Spatial Positional Encoding , url =
Yang Li and Si Si and others , bibsource =. Learnable Fourier Features for Multi-dimensional Spatial Positional Encoding , url =. Adv. Neural Inf. Process. Syst. (NIPS) , pages =
-
[78]
Srinivasan and others , bibsource =
Matthew Tancik and Pratul P. Srinivasan and others , bibsource =. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains , url =. Adv. Neural Inf. Process. Syst. (NIPS) , timestamp =
-
[79]
S im CSE : Simple Contrastive Learning of Sentence Embeddings
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi , booktitle =. doi:10.18653/v1/2021.emnlp-main.552 , pages =
-
[80]
Oord, Aaron van den and Li, Yazhe and Vinyals, Oriol , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.