HERALD: High-Throughput Block Diffusion LLM Serving via CPU-GPU Cooperative KV Cache Retrieval
Pith reviewed 2026-06-26 14:42 UTC · model grok-4.3
The pith
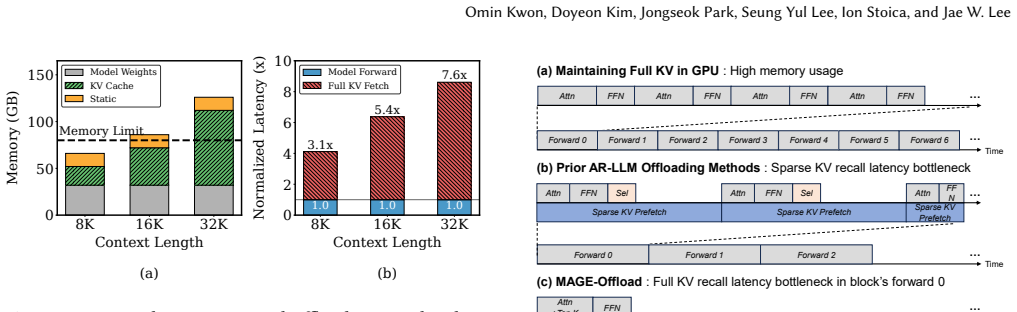
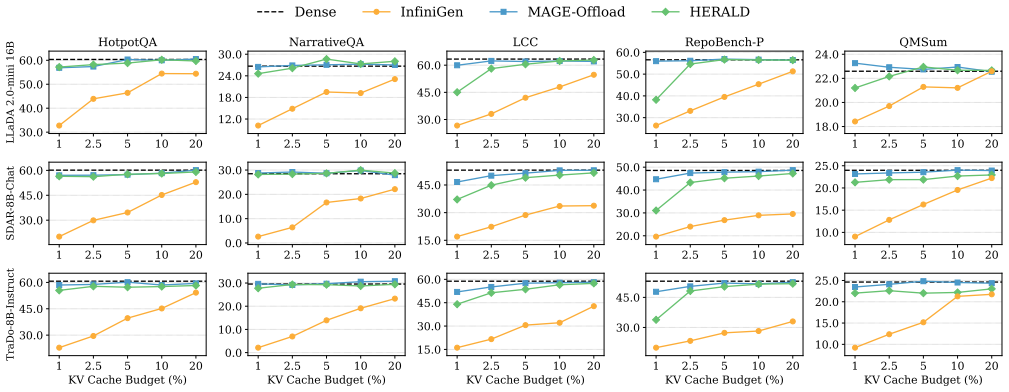
HERALD lets block diffusion LLMs keep only 5-10 percent of the KV cache on GPU by picking the needed entries once per block and reusing them across denoising steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
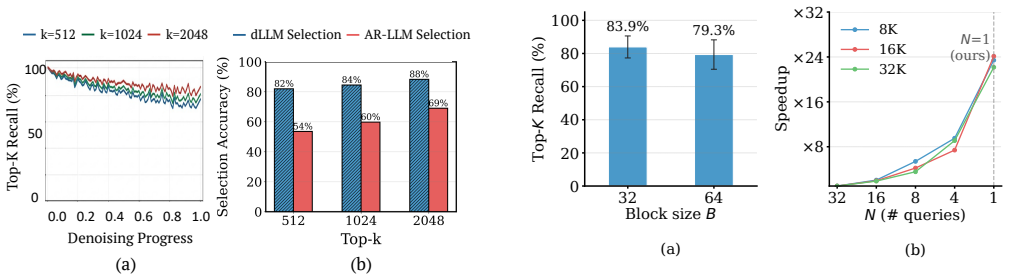
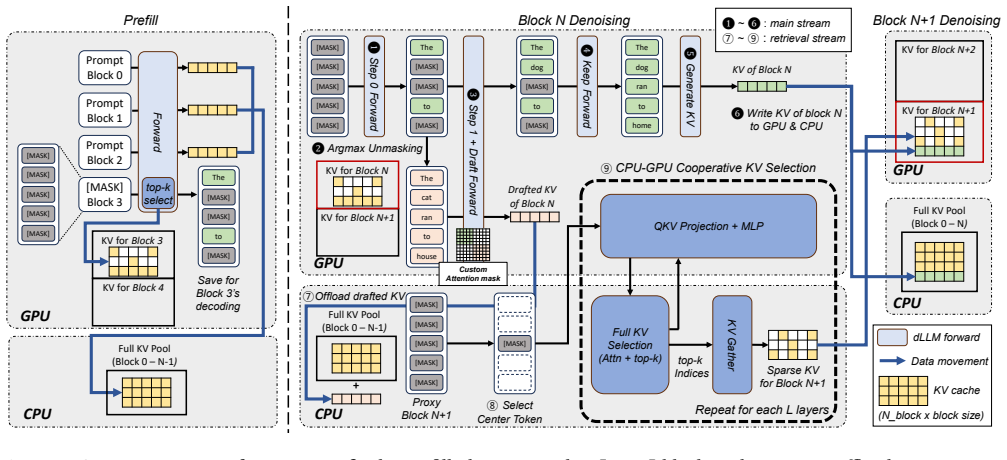
In block diffusion LLMs the relevant KV entries remain consistent across denoising steps within a block, so top-k selection performed once can be reused for all steps inside the block; HERALD exploits this by cutting the required selection compute by a factor of the block size and overlapping the remaining work with denoising through CPU-GPU cooperative retrieval, thereby supporting sparse offloading without accuracy loss.
What carries the argument
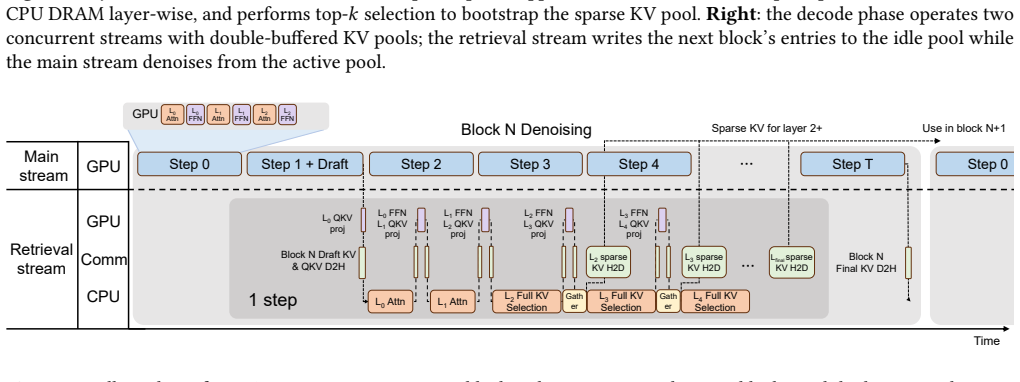
CPU-GPU cooperative KV cache retrieval that performs one-time top-k selection per block and overlaps the reduced selection work with denoising.
If this is right
- Near-lossless accuracy holds at 5-10 percent KV budget on GPU across three block dLLMs and five long-context tasks.
- Per-block latency drops by up to 1.59 times compared with GPU-only inference.
- Throughput rises by up to 2.47 times, and the speedup grows as context length increases.
- The selection overhead is amortized across the entire block rather than repeated each step.
Where Pith is reading between the lines
- The same reuse pattern could be tested in other multi-step generation schemes where cache relevance is stable inside fixed windows.
- Dynamic adjustment of the KV budget per block might further reduce memory use on tasks with varying attention sparsity.
- The overlap technique could be combined with other offloading policies that already move less-critical layers to CPU.
Load-bearing premise
The relevant KV entries remain consistent across denoising steps within a block.
What would settle it
A measurement showing that the set of top-k KV entries changes substantially between successive denoising steps inside the same block, causing accuracy to drop when the once-selected set is reused.
Figures





read the original abstract
Diffusion LLMs (dLLMs) improve GPU utilization over autoregressive decoding by generating multiple tokens per forward pass, but their KV cache still grows linearly with context, limiting throughput at long contexts. KV cache offloading to host DRAM alleviates this memory pressure, but the limited PCIe bandwidth necessitates recalling only a sparse subset of KV entries. In block dLLMs, the relevant KV entries remain consistent across denoising steps within a block, enabling high-accuracy selection by identifying the top-k entries once and reusing them throughout all denoising steps. This property appears attractive for offloading as it amortizes the selection overhead across the entire block, but it requires exact attention over the full KV cache, which is too expensive under offloading. We present HERALD, a KV offloading system for block dLLMs that resolves this through two opportunities that reduce the required selection compute by a factor of the block size and enable selection to be overlapped with denoising. Across three block dLLMs and five long context tasks, HERALD achieves near-lossless accuracy at 5-10% KV budget and up to 1.59x lower per block latency and 2.47x higher throughput over GPU-only inference, with speedups growing with context length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HERALD, a KV offloading system for block diffusion LLMs (dLLMs) that exploits the consistency of relevant KV entries across denoising steps within a block to amortize sparse top-k selection from CPU DRAM to GPU. It claims this enables near-lossless accuracy at 5-10% KV budget across three block dLLMs and five long-context tasks, along with up to 1.59x lower per-block latency and 2.47x higher throughput versus GPU-only inference, with speedups increasing with context length. The system uses two (unspecified in the abstract) opportunities to reduce selection compute by the block-size factor and overlap it with denoising.
Significance. If the empirical claims hold under the stated KV-consistency assumption, the work would be significant for efficient long-context dLLM serving by demonstrating practical CPU-GPU cooperative offloading that avoids full-cache attention costs. The amortization of selection overhead and context-length scaling are potentially impactful contributions to the systems-for-ML literature.
major comments (2)
- [Abstract] Abstract (and § on KV selection): the near-lossless accuracy claim at 5-10% KV budget is load-bearing on the assumption that relevant KV entries remain sufficiently consistent across denoising steps within a block so that a single top-k selection can be reused; the manuscript must provide quantitative evidence (e.g., attention-score variance, per-step accuracy drop when reusing the selection, or sensitivity analysis) rather than stating the property, because any material violation would invalidate the reported accuracy and the downstream latency/throughput numbers.
- [Experiments] Experimental section (results on three dLLMs and five tasks): the reported 1.59x latency and 2.47x throughput improvements lack visible error bars, ablation data on the two selection-compute-reduction opportunities, or controls for PCIe bandwidth variation; without these, it is impossible to assess whether the speedups are robust or whether they depend on the unverified consistency assumption.
minor comments (2)
- [Abstract] The abstract should name the three block dLLMs and five tasks to allow readers to assess generality.
- [System Design] Notation for the two opportunities that cut selection compute by the block-size factor should be introduced with a short equation or pseudocode in the system-overview section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of the consistency assumption and experimental robustness. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (and § on KV selection): the near-lossless accuracy claim at 5-10% KV budget is load-bearing on the assumption that relevant KV entries remain sufficiently consistent across denoising steps within a block so that a single top-k selection can be reused; the manuscript must provide quantitative evidence (e.g., attention-score variance, per-step accuracy drop when reusing the selection, or sensitivity analysis) rather than stating the property, because any material violation would invalidate the reported accuracy and the downstream latency/throughput numbers.
Authors: We agree that the consistency property is central and that the manuscript currently relies on stating the observed behavior in block dLLMs without accompanying quantitative metrics. The accuracy results across tasks provide indirect support, but explicit evidence such as attention-score variance across steps or accuracy sensitivity to reuse would directly address the concern. We will add a dedicated analysis subsection with these measurements in the revision. revision: yes
-
Referee: [Experiments] Experimental section (results on three dLLMs and five tasks): the reported 1.59x latency and 2.47x throughput improvements lack visible error bars, ablation data on the two selection-compute-reduction opportunities, or controls for PCIe bandwidth variation; without these, it is impossible to assess whether the speedups are robust or whether they depend on the unverified consistency assumption.
Authors: The reported numbers are means over repeated runs on the evaluated hardware, but we acknowledge the absence of error bars, explicit ablations isolating the two compute-reduction opportunities, and PCIe bandwidth controls limits assessment of robustness. We will add error bars, ablation studies, and a discussion of bandwidth sensitivity in the revised experimental section. The accuracy results provide supporting evidence for the consistency assumption, but the additional controls will clarify its role. revision: yes
Circularity Check
No significant circularity; empirical systems paper with no derivation chain
full rationale
The paper describes a KV offloading system for block dLLMs and reports empirical throughput/accuracy results. The central premise is an observed property (KV entry consistency across denoising steps within a block) that enables amortized top-k selection; this is presented as an input assumption rather than derived from any equation or prior result within the paper. No self-definitional loops, fitted parameters renamed as predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear. Performance numbers are direct measurements, not outputs of a closed mathematical chain. The contribution is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chiu, Zhihan Yang, Zhix- uan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhix- uan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov
-
[2]
InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
Block Diffusion: Interpolating Between Autoregressive and Dif- fusion Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net.https://openreview.net/forum?id=tyEyYT267x
2025
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhid- ian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Paper...
-
[4]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Li...
Pith/arXiv arXiv 2025
-
[5]
Josue Caldas and Elvis de Souza. 2025. A Comprehensive Evaluation of Large Language Models for Retrieval-Augmented Generation under Noisy Conditions. InProceedings of the 1st Workshop on Confabulation, Hallucinations and Overgeneration in Multilingual and Practical Settings (CHOMPS 2025), Aman Sinha, Raúl Vázquez, Timothee Mickus, Rohit Agarwal, Ioana Buh...
-
[6]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou. 2025. SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation. arXiv:2510.06303 [cs.LG] https://arxiv.org/abs/2510.06303
arXiv 2025
-
[7]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[8]
InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’22)
FLASHATTENTION: fast and memory-efficient exact attention with IO-awareness. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’22). Curran Associates Inc., Red Hook, NY, USA, Article 1189, 16 pages
-
[9]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.109972, 1 (2023), 32
Pith/arXiv arXiv 2023
-
[10]
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. 2025. Scaling Diffusion Language Models via Adaptation from Autoregressive Models. InThe Thirteenth Interna- tional Conference on Learning Representations.https://openreview.net/ forum?id=j1tSLYKwg8
2025
-
[11]
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and Lingpeng Kong. 2023. DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models. InThe Eleventh International Conference on Learning Representations.https://openreview.net/forum?id=jQj-_rLVXsj
2023
-
[12]
Google DeepMind. 2025. Gemini Diffusion.https://deepmind.google/ models/gemini-diffusion/. Accessed: 2026-04-14
2025
-
[13]
Yufeng Gu, Alireza Khadem, Sumanth Umesh, Ning Liang, Xavier Servot, Onur Mutlu, Ravi Iyer, and Reetuparna Das. 2025. Pim is all you need: A cxl-enabled gpu-free system for large language model inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 862–881
2025
-
[14]
Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Richard Charles Hooper, Sehoon Kim, Hiva Moham- madzadeh, Michael W. Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems.https: //openreview.net/forum?id=0LXotew9Du
2024
-
[15]
Xuanlin Jiang, Yang Zhou, Shiyi Cao, Ion Stoica, and Minlan Yu. 2025. NEO: Saving GPU Memory Crisis with CPU Offload- ing for Online LLM Inference. InProceedings of Machine Learn- ing and Systems, M. Zaharia, G. Joshi, and Y. Lin (Eds.), Vol. 7. MLSys.https://proceedings.mlsys.org/paper_files/paper/2025/file/ 66a026c0d17040889b50f0dfa650e5e0-Paper-Conference.pdf
2025
-
[16]
Hyungyo Kim, Nachuan Wang, Qirong Xia, Jinghan Huang, Amir Yazdanbakhsh, and Nam Sung Kim. 2025. LIA: A Single-GPU LLM Inference Acceleration with Cooperative AMX-Enabled CPU-GPU Computation and CXL Offloading. InProceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). As- sociation for Computing Machinery, New York, NY,...
-
[17]
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. 2025. Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions. arXiv:2502.06768 [cs.LG] https://arxiv.org/abs/2502.06768
arXiv 2025
-
[18]
Lee, Sangdoo Yun, and Hyun Oh Song
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, and Hyun Oh Song. 2025. KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction. InThe Thirty-ninth An- nual Conference on Neural Information Processing Systems.https: //openreview.net/forum?id=JFygzwx8SJ
2025
-
[19]
KyungSoo Kim, Omin Kwon, Yeonhong Park, and Jae W. Lee. 2025. AiDE: Attention-FFN Disaggregated Execution for Cost-Effective LLM Decoding on CXL-PNM .IEEE Computer Architecture Letters24, 02 (July 2025), 285–288.https://doi.org/10.1109/LCA.2025.3597323
-
[20]
Mahoney, Kurt Keutzer, and Amir Gholami
Minseo Kim, Coleman Hooper, Aditya Tomar, Chenfeng Xu, Mehrdad Farajtabar, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami
-
[21]
Beyond Next-Token Prediction: A Performance Characterization of Diffusion versus Autoregressive Language Models.arXiv preprint arXiv:2510.04146(2025).https://arxiv.org/abs/2510.04146
arXiv 2025
-
[22]
Minseo Kim, Chenfeng Xu, Coleman Hooper, Harman Singh, Ben Athiwaratkun, Ce Zhang, Kurt Keutzer, and Amir Gholami. 2026. CDLM: Consistency Diffusion Language Models For Faster Sampling. arXiv:2511.19269 [cs.LG]https://arxiv.org/abs/2511.19269
arXiv 2026
-
[23]
Omin Kwon, Yeonjae Kim, Doyeon Kim, Minseo Kim, Yeonhong Park, and Jae W. Lee. 2026. MAGE: All-[MASK] Block Already Knows Where to Look in Diffusion LLM. arXiv:2602.14209 [cs.LG]https: //arxiv.org/abs/2602.14209 12
Pith/arXiv arXiv 2026
-
[24]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[25]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New York, NY, USA, 611–626. https://doi.org/10.1145/3600006.3613165
-
[26]
Haeun Lee, Omin Kwon, Yeonhong Park, and Jae W. Lee. 2026. Nest- edFP: High-Performance, Memory-Efficient Dual-Precision Floating Point Support for LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum? id=WDAKFpWftI
2026
-
[27]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: efficient generative inference of large language models with dynamic KV cache management. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation (Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Article 9, 18 pages
2024
-
[28]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. arXiv:2211.17192 [cs.LG]https://arxiv.org/abs/2211.17192
Pith/arXiv arXiv 2023
-
[29]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks. InAd- vances in Neural Information Processing Systems, H. Larochelle, M. Ran- zato, R. Hadsell...
2020
-
[30]
Guangda Liu, Chengwei Li, Zhenyu Ning, Jing Lin, Yiwu Yao, Dan- ning Ke, Minyi Guo, and Jieru Zhao. 2026. FreeKV: Boosting KV Cache Retrieval for Efficient LLM Inference. InThe Fourteenth Inter- national Conference on Learning Representations.https://openreview. net/forum?id=wXAn7orB1H
2026
-
[31]
Guangda Liu, Chengwei Li, Jieru Zhao, Chenqi Zhang, and Minyi Guo. 2025. ClusterKV: Manipulating LLM KV Cache in Semantic Space for Recallable Compression. In2025 62nd ACM/IEEE Design Automation Conference (DAC). 1–7.https://doi.org/10.1109/DAC63849. 2025.11132479
-
[32]
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. 2025. dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching. arXiv:2506.06295 [cs.LG]https://arxiv.org/abs/2506.06295
Pith/arXiv arXiv 2025
-
[33]
Aaron Lou, Chenlin Meng, and Stefano Ermon. 2024. Discrete dif- fusion modeling by estimating the ratios of the data distribution. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria)(ICML’24). JMLR.org, Article 1333, 30 pages
2024
-
[34]
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. 2025. dKV-Cache: The Cache for Diffusion Language Models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=Gppo2JImHs
2025
-
[35]
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. Large Language Diffusion Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum? id=KnqiC0znVF
2025
-
[36]
Subham Sekhar Sahoo, Marianne Arriola, Aaron Gokaslan, Edgar Mar- iano Marroquin, Alexander M Rush, Yair Schiff, Justin T Chiu, and Volodymyr Kuleshov. 2024. Simple and Effective Masked Diffusion Language Models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum?id= L4uaAR4ArM
2024
-
[37]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. FlexGen: high-throughput generative inference of large language models with a single GPU. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA) (ICML’23). JMLR.org, Article 1288...
2023
-
[38]
Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. 2025. Sparse- dLLM: Accelerating Diffusion LLMs with Dynamic Cache Eviction. arXiv:2508.02558 [cs.CL]https://arxiv.org/abs/2508.02558
arXiv 2025
-
[39]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1348–1362.https://doi.org/10.1109/hpca61900.2025.00102
-
[40]
Hanshi Sun, Li-Wen Chang, Wenlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. 2025. SHADOWKV: KV cache in shadows for high-throughput long-context LLM inference. InProceedings of the 42nd International Conference on Machine Learning (Vancouver, Canada)(ICML’25). JMLR.org, Article 2276, 19 pages
2025
-
[41]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference. InForty-first International Conference on Machine Learning.https://openreview.net/forum?id=KzACYw0MTV
2024
-
[42]
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. 2025. Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models. arXiv:2509.06949 [cs.CL]https: //arxiv.org/abs/2509.06949
arXiv 2025
-
[43]
Zeqing Wang, Gongfan Fang, Xinyin Ma, Xingyi Yang, and Xinchao Wang. 2026. SparseD: Sparse Attention for Diffusion Language Models. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=dwbrZtYP04
2026
-
[44]
Qingyan Wei, Yaojie Zhang, Zhiyuan Liu, Puyu Zeng, Yuxuan Wang, Biqing Qi, Dongrui Liu, and Linfeng Zhang. 2026. Accelerating Dif- fusion Large Language Models with SlowFast Sampling: The Three Golden Principles. InThe Fourteenth International Conference on Learn- ing Representations.https://openreview.net/forum?id=Uh17FiwF4q
2026
-
[45]
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie
-
[46]
InThe Four- teenth International Conference on Learning Representations.https: //openreview.net/forum?id=1NZ3DHF9nT
Fast-dLLM v2: Efficient Block-Diffusion LLM. InThe Four- teenth International Conference on Learning Representations.https: //openreview.net/forum?id=1NZ3DHF9nT
-
[47]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. 2025. Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding. arXiv:2505.22618 [cs.CL]https://arxiv.org/ abs/2505.22618
Pith/arXiv arXiv 2025
-
[48]
Wenbo Wu, Qingyi Si, Xiurui Pan, Ye Wang, and Jie Zhang. 2025. LouisKV: Efficient KV Cache Retrieval for Long Input-Output Se- quences. arXiv:2510.11292 [cs.LG]https://arxiv.org/abs/2510.11292
arXiv 2025
-
[49]
Jiaming Xu, Jiayi Pan, Hanzhen Wang, Yongkang Zhou, Jiancai Ye, Yu Wang, and Guohao Dai. 2026. SpeContext: Enabling Efficient Long- context Reasoning with Speculative Context Sparsity in LLMs. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(USA)(ASPLOS ’26). Associa...
-
[50]
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. Dream 7B: Diffusion Large Language Models.arXiv preprint arXiv:2508.15487(2025).https: //arXiv.org/abs/2508.15487
Pith/arXiv arXiv 2025
-
[51]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and Cus- tomizable Attention Engine for LLM Inference Serving. InEighth Conference on Machine Learning and Systems.https://openreview.net/ 13 Omin Kwon, Doyeon Kim, Jongseok ...
2025
-
[52]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Asso- ciation, Carlsbad, CA, 521–538.https://www.usenix.org/conference/ osdi22/presentation/yu
2022
-
[53]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: effi- cient execution of structured language model programs. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC,...
2024
-
[54]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serv- ing. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Art...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.