Prefix-Guided On-Policy Distillation: Mining Golden Trajectories from Rollouts
Pith reviewed 2026-06-26 11:55 UTC · model grok-4.3
The pith
Prefix-Guided On-Policy Distillation uses early top-k overlap on fixed-length prefixes to select which trajectories to generate fully, improving accuracy while cutting compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
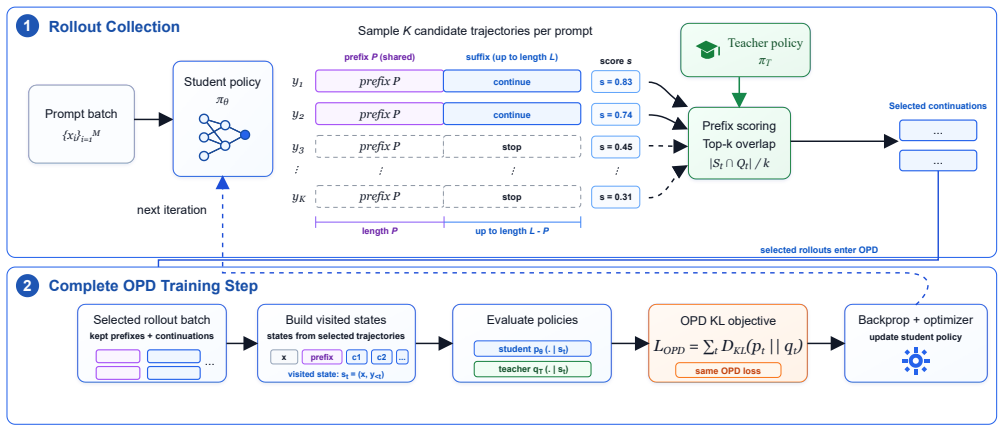
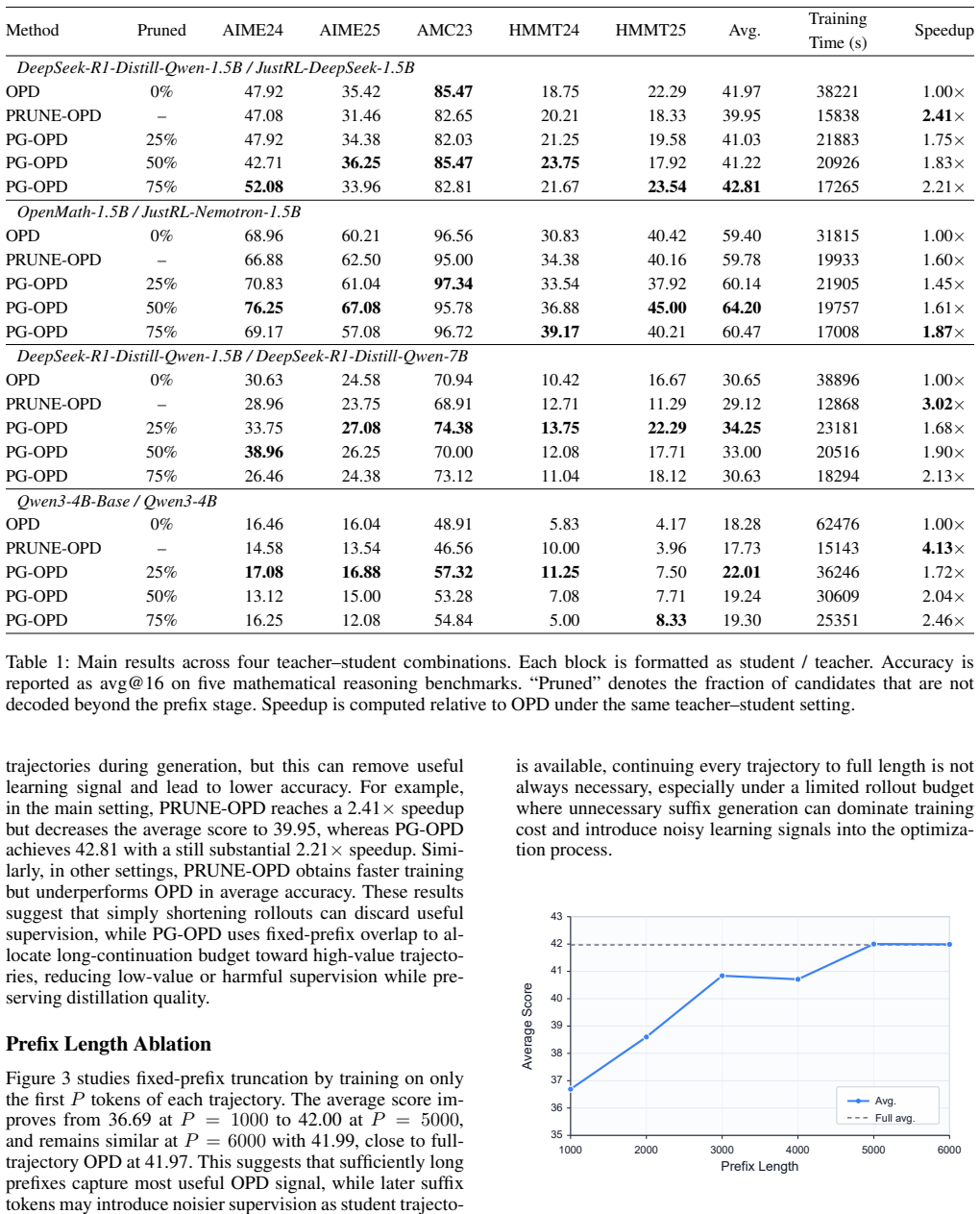
PG-OPD first decodes every sampled candidate to the same prefix length, computes teacher-student top-k overlap within an early probe window of that prefix, and selectively continues high-overlap candidates to a fixed long length while stopping low-overlap candidates at the prefix. This directs supervision toward trajectories that remain aligned with the teacher. Across diverse teacher-student combinations on AMC, AIME, and HMMT benchmarks, PG-OPD improves average accuracy by up to 4.80 points while reducing training time by up to 2.46x.
What carries the argument
Prefix-guided rollout allocation that estimates trajectory value via teacher-student top-k overlap on fixed-length prefixes before committing to long-horizon generation
If this is right
- High-overlap prefixes identify trajectories that provide denser, more reliable teacher supervision during on-policy updates.
- Stopping low-overlap candidates at the prefix length avoids both unnecessary generation cost and injection of misaligned learning signals.
- Prefix-level compatibility serves as a practical early filter for directing limited rollout budget in long-horizon distillation.
- The same allocation logic applies uniformly across different teacher-student model pairs without additional tuning.
- Accuracy and wall-clock improvements hold on standard math competition benchmarks when the prefix probe is used.
Where Pith is reading between the lines
- The early-stop rule could be generalized to other sequential generation tasks where partial outputs predict final alignment quality.
- Combining the overlap signal with variance-reduction techniques might further stabilize on-policy updates in reasoning domains.
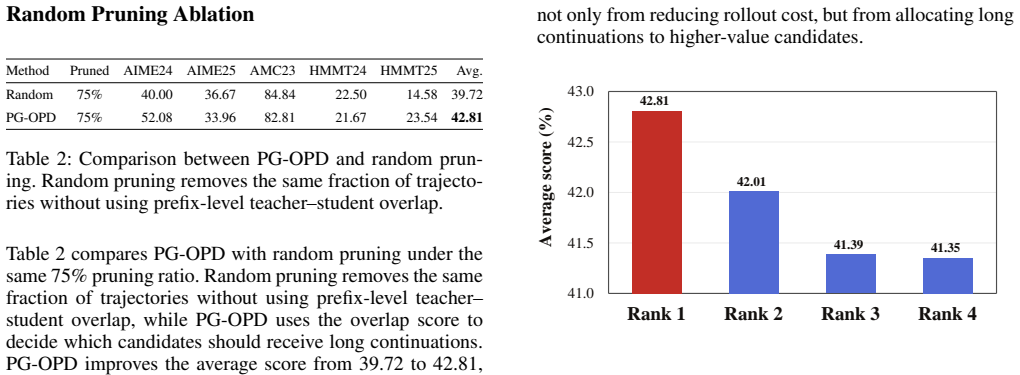
- Varying the probe-window length offers a tunable tradeoff between estimation reliability and prefix-generation overhead.
- The approach may reduce the effective sample complexity of distillation when teacher signals are expensive to obtain.
Load-bearing premise
Low top-k overlap on fixed-length student prefixes reliably indicates that continuing to the long suffix will produce noisy or low-value supervision.
What would settle it
A controlled comparison in which full-length trajectories from low-overlap prefixes produce equal or larger accuracy gains than those from high-overlap prefixes would falsify the selection rule.
Figures

read the original abstract
On-policy distillation (OPD) improves reasoning models by applying dense teacher supervision on student-sampled trajectories. However, scaling OPD to long-horizon mathematical reasoning exposes a reliability and efficiency problem: standard OPD assigns every sampled candidate the same long rollout budget, even though some trajectories may quickly become weakly aligned with the teacher and provide less useful supervision. Prior analyses suggest that successful OPD depends on local teacher-student compatibility, which can be measured by top-k overlap on student-visited prefixes. When this overlap is low, continuing to generate or train on long suffixes may waste computation and introduce noisy learning signal. To address this, we introduce Prefix-Guided On-Policy Distillation (PG-OPD), a simple rollout-allocation framework that uses fixed-length prefixes to estimate trajectory value before expensive long-horizon generation. PG-OPD first decodes every sampled candidate to the same prefix length, computes teacher-student top-k overlap within an early probe window of that prefix, and selectively continues high-overlap candidates to a fixed long length. Low-overlap candidates stop at the fixed prefix, avoiding unnecessary suffix generation. Across diverse teacher-student combinations on AMC, AIME, and HMMT benchmarks, PG-OPD improves average accuracy by up to 4.80 points while reducing training time by up to 2.46x. These results suggest that prefix-level compatibility provides a practical signal for directing OPD computation toward trajectories that remain learnable from the teacher.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Prefix-Guided On-Policy Distillation (PG-OPD), a rollout-allocation heuristic for on-policy distillation in mathematical reasoning. It decodes student candidates to a fixed prefix length, computes teacher-student top-k overlap in an early probe window, and continues only high-overlap prefixes to full length while stopping low-overlap ones early. Across teacher-student pairs on AMC, AIME, and HMMT, it reports accuracy gains of up to 4.80 points and training-time reductions of up to 2.46x.
Significance. If the empirical claims hold after proper validation, the work offers a practical, low-overhead way to allocate compute in OPD by exploiting local prefix compatibility, which could help scale distillation to longer horizons. The approach is grounded in prior observations about teacher-student alignment rather than introducing new fitted quantities or machine-checked proofs.
major comments (2)
- [§4] §4 (Experiments): The abstract and results claim specific numerical gains (4.80 accuracy points, 2.46x time) but supply no variance across seeds, statistical significance tests, exact definitions of the overlap metric, probe-window length, or prefix length; without these, it is impossible to determine whether the data support the central claim that the prefix filter drives the improvements.
- [§3.2] §3.2 (Method): The load-bearing assumption that low top-k overlap on the fixed prefix reliably indicates that the long suffix will be low-value is stated but not directly tested; the manuscript lacks an ablation that continues all trajectories (or uses overlap only for reweighting) versus the early-stop filter, so gains cannot be attributed to the prefix heuristic rather than other unablated design choices.
minor comments (2)
- [Abstract] Abstract: The terms 'fixed-length prefixes', 'probe window', and 'top-k overlap' are used without numerical values or pseudocode; adding these would improve reproducibility.
- [§4] §4, Table 1: Baseline comparisons are mentioned but the exact teacher and student model sizes, training hyperparameters, and number of rollouts per problem are not tabulated; a single consolidated table would clarify the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The abstract and results claim specific numerical gains (4.80 accuracy points, 2.46x time) but supply no variance across seeds, statistical significance tests, exact definitions of the overlap metric, probe-window length, or prefix length; without these, it is impossible to determine whether the data support the central claim that the prefix filter drives the improvements.
Authors: We agree that the reported gains require additional statistical detail and precise hyperparameter definitions to be fully interpretable. In the revised manuscript we will (i) report mean and standard deviation across at least three random seeds for all accuracy and timing results, (ii) include paired t-test or Wilcoxon signed-rank p-values for the accuracy improvements, and (iii) explicitly state the overlap metric (top-k token overlap), probe-window length, and prefix length used in every experiment. These additions will be placed in §4 and the associated tables/figures. revision: yes
-
Referee: [§3.2] §3.2 (Method): The load-bearing assumption that low top-k overlap on the fixed prefix reliably indicates that the long suffix will be low-value is stated but not directly tested; the manuscript lacks an ablation that continues all trajectories (or uses overlap only for reweighting) versus the early-stop filter, so gains cannot be attributed to the prefix heuristic rather than other unablated design choices.
Authors: The assumption is grounded in the cited prior observations on local teacher-student compatibility, yet we acknowledge that a controlled ablation isolating the early-stop decision is necessary to attribute performance gains specifically to the prefix filter. In the revision we will add an ablation that (a) runs the full rollout budget on every candidate and (b) uses overlap only as a reweighting signal without early stopping, comparing both against the proposed PG-OPD filter on the same teacher-student pairs. The new results and discussion will appear in §4. revision: yes
Circularity Check
No significant circularity; heuristic framework without self-referential derivations or fitted predictions
full rationale
The paper describes PG-OPD as a heuristic rollout-allocation method motivated by prior observations on teacher-student compatibility via top-k overlap. No equations, derivations, parameter fits, or self-citation chains are present that reduce any claimed result to its own inputs by construction. The method selects trajectories based on an early prefix probe but does not define or predict quantities in a self-referential loop. This is a standard non-circular empirical heuristic paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- prefix length
- probe window length
axioms (1)
- domain assumption top-k overlap on student-visited prefixes measures local teacher-student compatibility that predicts long-horizon supervision value
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1503.02531 , year=
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[2]
Proceedings of EMNLP , pages=
Sequence-Level Knowledge Distillation , author=. Proceedings of EMNLP , pages=
-
[3]
arXiv preprint arXiv:1910.01108 , year=
DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter , author=. arXiv preprint arXiv:1910.01108 , year=
Pith/arXiv arXiv 1910
-
[4]
Findings of EMNLP , pages=
TinyBERT: Distilling BERT for Natural Language Understanding , author=. Findings of EMNLP , pages=
-
[5]
NeurIPS , year=
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , author=. NeurIPS , year=
-
[6]
NeurIPS , year=
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author=. NeurIPS , year=
-
[7]
ICLR , year=
MiniLLM: Knowledge Distillation of Large Language Models , author=. ICLR , year=
-
[8]
ICLR , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. ICLR , year=
-
[9]
2025 , note=
On-Policy Distillation , author=. 2025 , note=
2025
-
[10]
arXiv preprint arXiv:2402.03300 , year=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[11]
arXiv preprint arXiv:2501.12948 , year=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[12]
arXiv preprint , year=
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe , author=. arXiv preprint , year=
-
[13]
arXiv preprint , year=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. arXiv preprint , year=
-
[14]
arXiv preprint , year=
Qwen3 Technical Report , author=. arXiv preprint , year=
-
[15]
arXiv preprint arXiv:2604.13016 , year=
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. arXiv preprint arXiv:2604.13016 , year=
-
[16]
arXiv preprint , year=
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author=. arXiv preprint , year=
-
[17]
arXiv preprint , year=
Stable On-Policy Distillation through Adaptive Target Reformulation , author=. arXiv preprint , year=
-
[18]
arXiv preprint , year=
Entropy-Aware On-Policy Distillation of Language Models , author=. arXiv preprint , year=
-
[19]
arXiv preprint , year=
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation , author=. arXiv preprint , year=
-
[20]
arXiv preprint arXiv:2605.07804 , year=
PRUNE-OPD: Efficient and Reliable On-Policy Distillation for Long-Horizon Reasoning , author=. arXiv preprint arXiv:2605.07804 , year=
-
[21]
NeurIPS , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. NeurIPS , year=
-
[22]
arXiv preprint arXiv:1707.06347 , year=
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[23]
NeurIPS , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. NeurIPS , year=
-
[24]
arXiv preprint arXiv:2203.11171 , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[25]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[26]
arXiv preprint , year=
Reinforcement Learning via Self-Distillation , author=. arXiv preprint , year=
-
[27]
arXiv preprint , year=
Self-Distillation Enables Continual Learning , author=. arXiv preprint , year=
-
[28]
arXiv preprint , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.