Parameterized Representations via Implicit Stochastic Modulation for High-Dimensional and High-Order Neural PDE Solvers
Pith reviewed 2026-06-26 12:18 UTC · model grok-4.3
The pith
PRISM maps physical parameters to affine modulators on a spatial latent manifold to keep high-order derivative graphs free of parameter entanglement in neural PDE solvers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
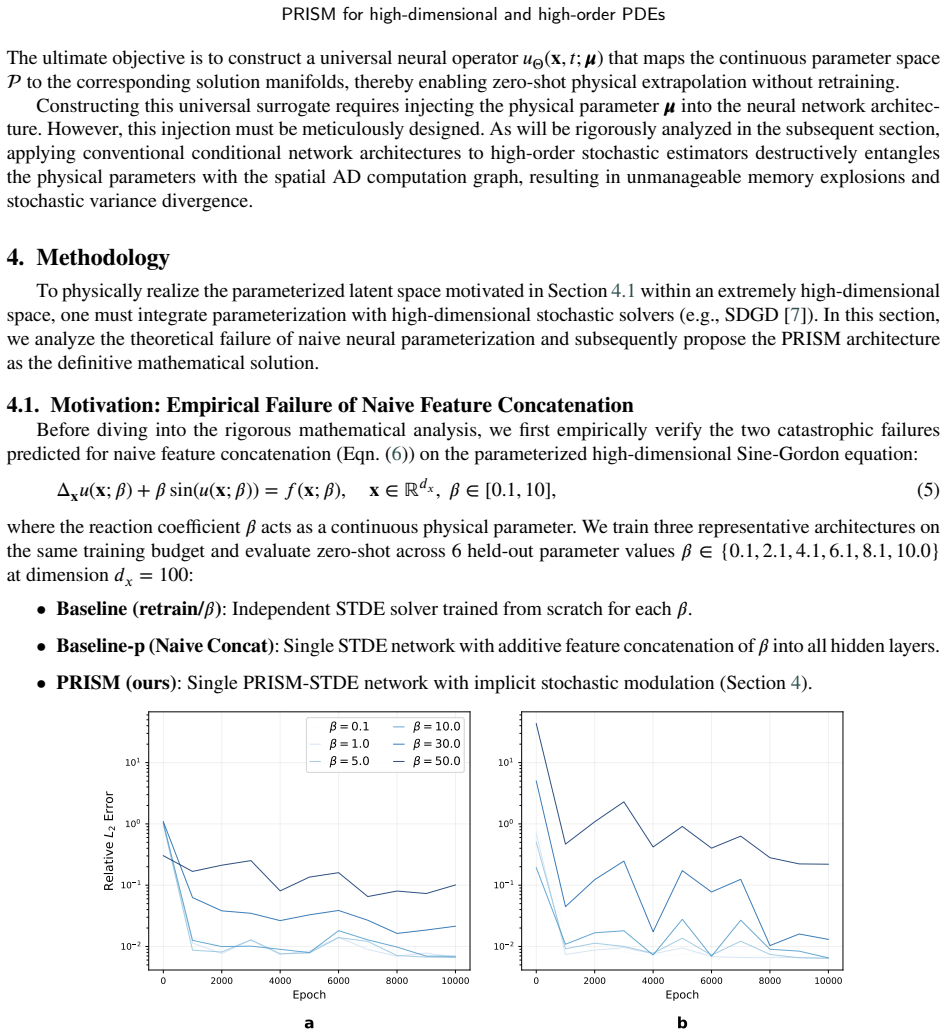
Core claim
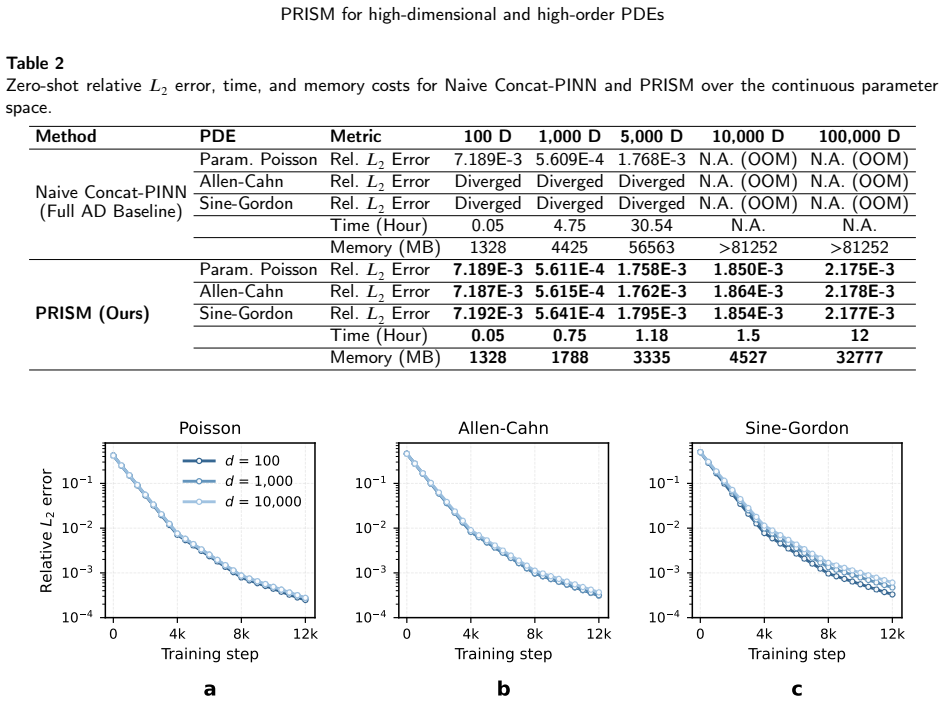
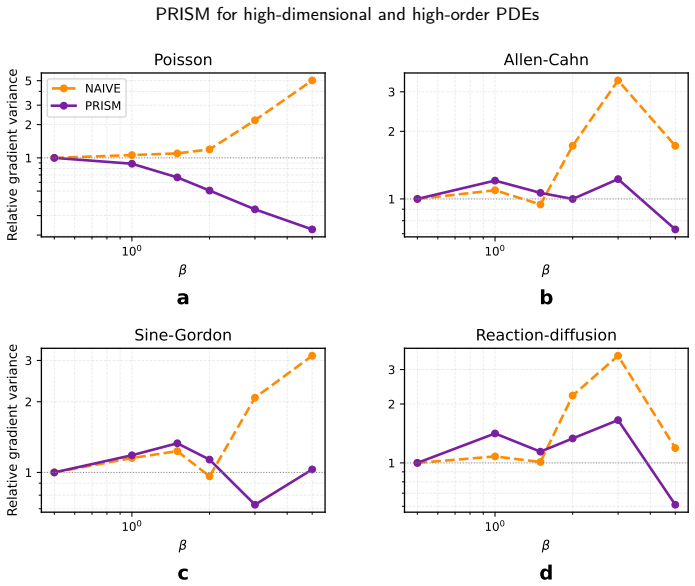
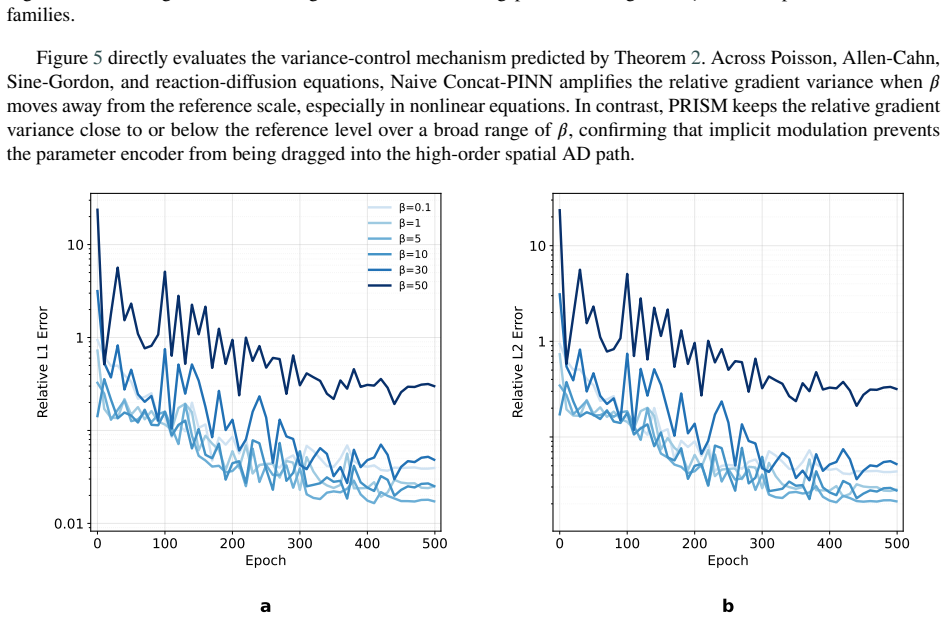
PRISM uses a hyper-generator to map physical parameters to affine modulators that scale and shift a purely spatial latent manifold, while keeping parameter branches value-connected but spatial-tangent-disconnected. This design preserves unbiased stochastic dimension and Taylor estimators, removes the parameter encoder from high-order spatial AD, and provides a variance-aware Lipschitz envelope over the parameter space. The paper proves parameterized unbiasedness, estimation-error bounds, and convergence under bounded stochastic variance.
What carries the argument
Hyper-generator that produces affine modulators (scale and shift) applied to a purely spatial latent manifold, enforcing spatial-tangent-disconnection from parameter branches.
If this is right
- Parameterized unbiasedness of stochastic derivative estimators holds after modulation.
- Estimation-error bounds and convergence under bounded variance extend to the parameterized case.
- Zero-shot generalization to unseen parameters occurs without retraining the spatial solver.
- Memory growth is avoided because the parameter encoder is excluded from high-order spatial AD.
- Low-rank SVD adaptation enables efficient handling of new parameters at 100,000 dimensions.
Where Pith is reading between the lines
- The same modulator construction could be inserted into other stochastic-gradient PDE methods that already rely on dimension or Taylor estimators.
- The variance-aware Lipschitz envelope supplies a natural way to quantify how solution uncertainty grows with parameter distance.
- Low-rank adaptation of the modulators suggests a route to rapid fine-tuning when only a few new parameter samples become available.
- The separation of parameter and spatial graphs may reduce the cost of multi-query or inverse problems that repeatedly evaluate the PDE at different parameters.
Load-bearing premise
The spatial-tangent-disconnected property between parameter branches and the spatial manifold can be maintained in practice without introducing bias or extra variance into the stochastic derivative estimators.
What would settle it
A numerical check that stochastic derivative estimates acquire measurable bias once the learned affine modulators are applied to a parameter value outside the training set.
Figures

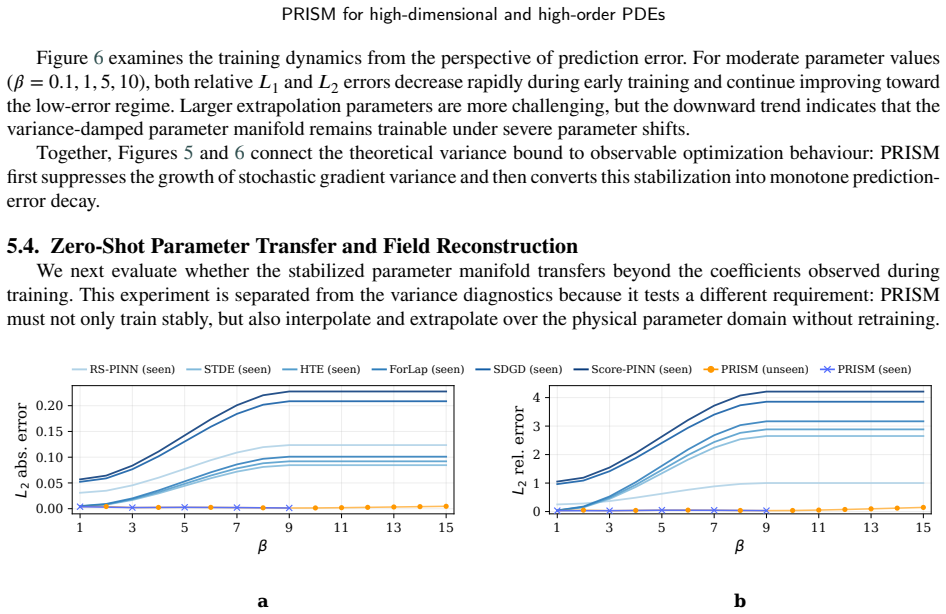

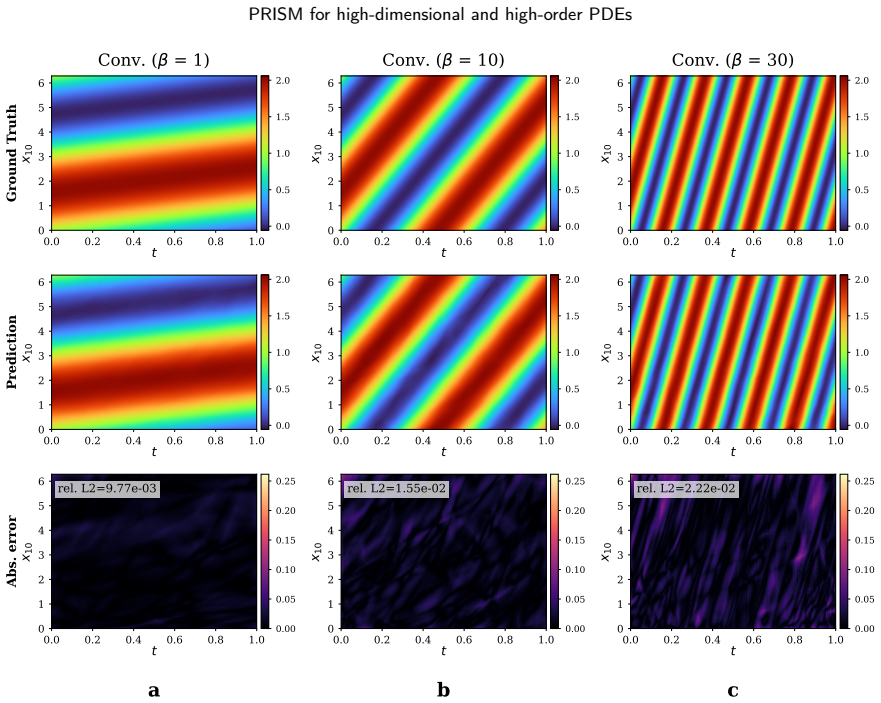


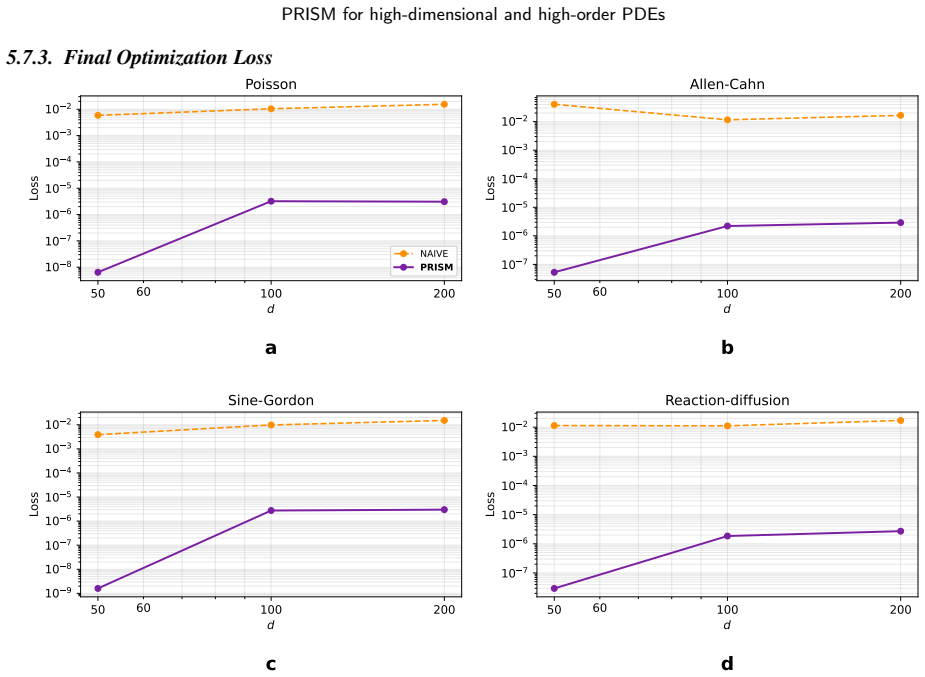
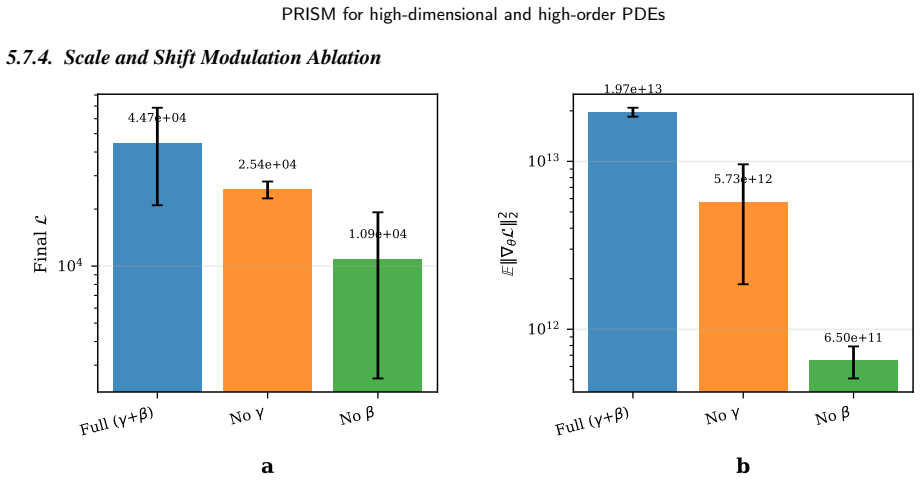

read the original abstract
Solving high-dimensional and high-order PDEs is challenged by the coupled growth of spatial dimensionality and derivative order. Recent stochastic derivative estimators reduce this cost by replacing full derivative tensors with randomized dimension or Taylor estimators, but they are mostly designed for fixed physical parameters and require retraining for each new parameter. We show that direct conditional parameterization of such solvers entangles physical parameters with the high-order automatic differentiation graph, causing extra memory growth and parameter-induced variance amplification. We propose Parameterized Representations via Implicit Stochastic Modulation (PRISM), a plug-and-play framework for parameterized high-dimensional and high-order stochastic neural PDE solvers. PRISM uses a hyper-generator to map physical parameters to affine modulators that scale and shift a purely spatial latent manifold, while keeping parameter branches value-connected but spatial-tangent-disconnected. This design preserves unbiased stochastic dimension and Taylor estimators, removes the parameter encoder from high-order spatial AD, and provides a variance-aware Lipschitz envelope over the parameter space. We prove parameterized unbiasedness, estimation-error bounds, and convergence under bounded stochastic variance. Experiments with PRISM-STDE and PRISM-SDGD on nonlinear parameterized PDEs show stable zero-shot generalization, reduced memory usage, and scalability up to 100,000 dimensions on a single GPU, with efficient low-rank SVD adaptation for unseen parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, a plug-and-play framework for parameterized high-dimensional and high-order stochastic neural PDE solvers. It uses a hyper-generator to map physical parameters to affine modulators (scale and shift) applied to a purely spatial latent manifold, keeping parameter branches value-connected but spatial-tangent-disconnected. This preserves unbiased stochastic dimension and Taylor estimators, removes the parameter encoder from high-order spatial AD, and provides a variance-aware Lipschitz envelope. The authors prove parameterized unbiasedness, estimation-error bounds, and convergence under bounded stochastic variance. Experiments with PRISM-STDE and PRISM-SDGD on nonlinear parameterized PDEs demonstrate stable zero-shot generalization, reduced memory usage, and scalability up to 100,000 dimensions on a single GPU, with efficient low-rank SVD adaptation for unseen parameters.
Significance. If the central claims hold, PRISM addresses a key limitation in extending stochastic derivative estimators to parameterized settings by structurally decoupling parameter dependence from the spatial differentiation graph. This enables zero-shot generalization across parameter spaces without retraining or parameter-induced variance amplification, while maintaining unbiasedness and providing convergence guarantees. The design's explicit preservation of stochastic estimators and the experimental scalability to extreme dimensions represent a meaningful contribution to high-dimensional neural PDE solving.
minor comments (3)
- [Abstract] Abstract: the claim of 'efficient low-rank SVD adaptation for unseen parameters' is stated without reference to the specific adaptation procedure or its integration with the hyper-generator; a brief description or forward reference would improve clarity.
- [Methods] The notation for the hyper-generator output (affine modulators) and the spatial latent manifold could be introduced with explicit equations in the methods section to make the value-connected vs. tangent-disconnected distinction immediately formal.
- [Experiments] Experiments: while scalability to 100,000 dimensions is reported, the memory and variance comparisons would benefit from an explicit baseline table showing the entangled parameterization case to quantify the claimed reduction.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately reflects the core contributions of PRISM in decoupling parameters from the differentiation graph while preserving unbiased stochastic estimators.
Circularity Check
No significant circularity detected
full rationale
The paper's central design (hyper-generator mapping parameters to affine modulators on a spatial latent manifold, with value-connected but spatial-tangent-disconnected branches) is presented as an architectural choice that by definition removes the parameter encoder from high-order AD graphs. The abstract states that this preserves unbiased stochastic estimators and that proofs of parameterized unbiasedness, error bounds, and convergence exist under bounded variance. No equations, self-citations, or fitted inputs are quoted that reduce the claimed proofs or unbiasedness results to the inputs by construction. The derivation chain remains self-contained against external benchmarks, with the proofs and experiments providing independent content beyond the design description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic dimension and Taylor estimators remain unbiased when the spatial manifold is modulated by affine transforms derived from a separate hyper-generator.
invented entities (2)
-
hyper-generator
no independent evidence
-
affine modulators
no independent evidence
Reference graph
Works this paper leans on
-
[1]
rep., USDOE Office of Science (SC), Washington, DC (United States) (2019)
N.Baker,F.Alexander,T.Bremer,A.Hagberg,Y.Kevrekidis,H.Najm,M.Parashar,A.Patra,J.Sethian,S.Wild,etal.,Workshopreporton basic research needs for scientific machine learning: Core technologies for artificial intelligence, Tech. rep., USDOE Office of Science (SC), Washington, DC (United States) (2019)
2019
-
[2]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707
2019
-
[3]
G.E.Karniadakis,I.G.Kevrekidis,L.Lu,P.Perdikaris,S.Wang,L.Yang,Physics-informedmachinelearning,NatureReviewsPhysics3(6) (2021) 422–440. Z. Liang et al.:Preprint submitted to ElsevierPage 38 of 40 PRISM for high-dimensional and high-order PDEs
2021
-
[4]
C. Beck, S. Becker, P. Cheridito, A. Jentzen, A. Neufeld, Deep splitting method for parabolic pdes, SIAM Journal on Scientific Computing 43 (5) (2021) A3135–A3154
2021
-
[5]
J. Han, A. Jentzen, W. E, Solving high-dimensional partial differential equations using deep learning, Proceedings of the National Academy of Sciences 115 (34) (2018) 8505–8510
2018
-
[6]
M. Raissi, Forward-backward stochastic neural networks: Deep learning of high-dimensional partial differential equations, arXiv preprint arXiv:1804.07010 (2018)
Pith/arXiv arXiv 2018
- [7]
-
[8]
Z. Hu, Z. Shi, G. E. Karniadakis, K. Kawaguchi, Hutchinson trace estimation for high-dimensional and high-order physics-informed neural networks,ComputerMethodsinAppliedMechanicsandEngineering424(2024)116883.doi:https://doi.org/10.1016/j.cma.2024. 116883
-
[9]
Z. Hu, K. Kawaguchi, Z. Zhang, G. E. Karniadakis, Stochastic taylor derivative estimator: Efficient amortization for arbitrary differential operators, Advances in Neural Information Processing Systems 37 (2024)
2024
-
[10]
X. Liu, X. Zhang, W. Peng, W. Zhou, W. Yao, A novel meta-learning initialization method for physics-informed neural networks, Neural Computing and Applications 34 (17) (2022) 14511–14534
2022
-
[11]
A.Krishnapriyan,A.Gholami,S.Zhe,R.Kirby,M.W.Mahoney,Characterizingpossiblefailuremodesinphysics-informedneuralnetworks, Advances in Neural Information Processing Systems 34 (2021) 26548–26560
2021
-
[12]
L.Lu,P.Jin,G.Pang,Z.Zhang,G.E.Karniadakis,Learningnonlinearoperatorsviadeeponetbasedontheuniversalapproximationtheorem of operators, Nature machine intelligence 3 (3) (2021) 218–229
2021
-
[13]
Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, in: International Conference on Learning Representations, 2021
2021
-
[14]
N.Kovachki,Z.Li,B.Liu,K.Azizzadenesheli,K.Bhattacharya,A.Stuart,A.Anandkumar,Neuraloperator:Learningmapsbetweenfunction spaces with applications to pdes, Journal of Machine Learning Research 24 (89) (2023) 1–97
2023
-
[15]
Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, A. Anandkumar, Physics-informed neural operator for learning partial differential equations, arXiv preprint arXiv:2111.03794 (2021)
arXiv 2021
-
[16]
S. Goswami, A. Bora, Y. Yu, G. E. Karniadakis, Physics-informed neural operators, arXiv preprint arXiv:2207.05748 (2022)
arXiv 2022
-
[17]
Raissi, G
M. Raissi, G. E. Karniadakis, Hidden physics models: Machine learning of nonlinear partial differential equations, Journal of Computational Physics 357 (2018) 125–141
2018
-
[18]
E.Haghighat,M.Raissi,A.Moure,H.Gomez,R.Juanes,Aphysics-informeddeeplearningframeworkforinversionandsurrogatemodeling in solid mechanics, Computer Methods in Applied Mechanics and Engineering 379 (2021) 113741
2021
-
[19]
Y. Yang, P. Perdikaris, Adversarial uncertainty quantification in physics-informed neural networks, Journal of Computational Physics 394 (2019) 136–152
2019
-
[20]
A. D. Jagtap, D. Mitsotakis, G. E. Karniadakis, Deep learning of inverse water waves problems using multi-fidelity data: Application to serre–green–naghdi equations, Ocean Engineering 248 (2022) 110775
2022
-
[21]
S.Cai,Z.Mao,Z.Wang,M.Yin,G.E.Karniadakis,Physics-informedneuralnetworks(pinns)forfluidmechanics:Areview,ActaMechanica Sinica 37 (12) (2021) 1727–1738
2021
-
[22]
S. Goswami, A. D. Jagtap, H. Babaee, B. T. Susi, G. E. Karniadakis, Learning stiff chemical kinetics using extended deep neural operators, arXiv preprint arXiv:2302.12645 (2023)
arXiv 2023
-
[23]
K.Shukla,V.Oommen,A.Peyvan,M.Penwarden,L.Bravo,A.Ghoshal,R.M.Kirby,G.E.Karniadakis,Deepneuraloperatorscanserveas accurate surrogates for shape optimization: a case study for airfoils, arXiv preprint arXiv:2302.00807 (2023)
arXiv 2023
-
[24]
Goswami, M
S. Goswami, M. Yin, Y. Yu, G. E. Karniadakis, A physics-informed variational deeponet for predicting crack path in quasi-brittle materials, Computer Methods in Applied Mechanics and Engineering 391 (2022) 114587
2022
-
[25]
T. Luo, H. Yang, Two-layer neural networks for partial differential equations: Optimization and generalization theory, ArXiv abs/2006.15733 (2020)
arXiv 2006
- [26]
-
[27]
Y. Shin, J. Darbon, G. E. Karniadakis, On the convergence of physics informed neural networks for linear second-order elliptic and parabolic type pdes, arXiv preprint arXiv:2004.01806 (2020)
arXiv 2004
-
[28]
J.Lu,Y.Lu,M.Wang,Apriorigeneralizationanalysisofthedeepritzmethodforsolvinghighdimensionalellipticequations,arXivpreprint arXiv:2101.01708 (2021)
arXiv 2021
-
[29]
Z.Hu,A.D.Jagtap,G.E.Karniadakis,K.Kawaguchi,Whendoextendedphysics-informedneuralnetworks(xpinns)improvegeneralization?, SIAM Journal on Scientific Computing 44 (5) (2022) A3158–A3182.doi:10.1137/21M1447039
-
[30]
A.D.Jagtap,G.E.Karniadakis,Extendedphysics-informedneuralnetworks(xpinns):Ageneralizedspace-timedomaindecompositionbased deep learning framework for nonlinear partial differential equations, Communications in Computational Physics 28 (5) (2020) 2002–2041
2020
-
[31]
Z. Hu, A. D. Jagtap, G. E. Karniadakis, K. Kawaguchi, Augmented physics-informed neural networks (apinns): A gating network-based soft domain decomposition methodology, arXiv preprint arXiv:2211.08939 (2022)
arXiv 2022
-
[32]
C. Wang, S. Li, D. He, L. Wang, Is $l^2$ physics informed loss always suitable for training physics informed neural network?, in: A. H. Oh, A. Agarwal, D. Belgrave, K. Cho (Eds.), Advances in Neural Information Processing Systems, 2022
2022
-
[33]
D. He, S. Li, W. Shi, X. Gao, J. Zhang, J. Bian, L. Wang, T.-Y. Liu, Learning physics-informed neural networks without stacked back- propagation, in: International Conference on Artificial Intelligence and Statistics, PMLR, 2023, pp. 3034–3047
2023
-
[34]
J. Cho, S. Nam, H. Yang, S.-B. Yun, Y. Hong, E. Park, Separable pinn: Mitigating the curse of dimensionality in physics-informed neural networks, arXiv preprint arXiv:2211.08761 (2022). Z. Liang et al.:Preprint submitted to ElsevierPage 39 of 40 PRISM for high-dimensional and high-order PDEs
arXiv 2022
-
[35]
J. Han, A. Jentzen, et al., Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations, Communications in mathematics and statistics 5 (4) (2017) 349–380
2017
-
[36]
C.Beck,W.E,A.Jentzen,Machinelearningapproximationalgorithmsforhigh-dimensionalfullynonlinearpartialdifferentialequationsand second-order backward stochastic differential equations, Journal of Nonlinear Science 29 (2019) 1563–1619
2019
-
[37]
Chan-Wai-Nam, J
Q. Chan-Wai-Nam, J. Mikael, X. Warin, Machine learning for semi linear pdes, Journal of scientific computing 79 (3) (2019) 1667–1712
2019
-
[38]
Henry-Labordere, Deep primal-dual algorithm for bsdes: Applications of machine learning to cva and im, Available at SSRN 3071506 (2017)
P. Henry-Labordere, Deep primal-dual algorithm for bsdes: Applications of machine learning to cva and im, Available at SSRN 3071506 (2017)
2017
-
[39]
C. Huré, H. Pham, X. Warin, Deep backward schemes for high-dimensional nonlinear pdes, Mathematics of Computation 89 (324) (2020) 1547–1579
2020
-
[40]
S.Ji,S.Peng,Y.Peng,X.Zhang,Threealgorithmsforsolvinghigh-dimensionalfullycoupledfbsdesthroughdeeplearning,IEEEIntelligent Systems 35 (3) (2020) 71–84
2020
-
[41]
Becker, P
S. Becker, P. Cheridito, A. Jentzen, T. Welti, Solving high-dimensional optimal stopping problems using deep learning, European Journal of Applied Mathematics 32 (3) (2021) 470–514
2021
-
[42]
C.Beck,L.Gonon,A.Jentzen,Overcomingthecurseofdimensionalityinthenumericalapproximationofhigh-dimensionalsemilinearelliptic partial differential equations, arXiv preprint arXiv:2003.00596 (2020)
arXiv 2003
-
[43]
C.Beck,F.Hornung,M.Hutzenthaler,A.Jentzen,T.Kruse,Overcomingthecurseofdimensionalityinthenumericalapproximationofallen– cahn partial differential equations via truncated full-history recursive multilevel picard approximations, Journal of Numerical Mathematics 28 (4) (2020) 197–222
2020
- [44]
-
[45]
Hutzenthaler, A
M. Hutzenthaler, A. Jentzen, T. Kruse, T. Anh Nguyen, P. von Wurstemberger, Overcoming the curse of dimensionality in the numerical approximation of semilinear parabolic partial differential equations, Proceedings of the Royal Society A 476 (2244) (2020) 20190630
2020
-
[46]
Hutzenthaler, A
M. Hutzenthaler, A. Jentzen, T. Kruse, et al., Multilevel picard iterations for solving smooth semilinear parabolic heat equations, Partial Differential Equations and Applications 2 (6) (2021) 1–31
2021
-
[47]
Y. Wang, P. Jin, H. Xie, Tensor neural network and its numerical integration, arXiv preprint arXiv:2207.02754 (2022)
arXiv 2022
-
[48]
Y. Wang, Y. Liao, H. Xie, Solving schr∖"{o}dinger equation using tensor neural network, arXiv preprint arXiv:2209.12572 (2022)
arXiv 2022
-
[49]
Y. Zang, G. Bao, X. Ye, H. Zhou, Weak adversarial networks for high-dimensional partial differential equations, Journal of Computational Physics 411 (2020) 109409
2020
-
[50]
J.Sirignano,K.Spiliopoulos,Dgm:Adeeplearningalgorithmforsolvingpartialdifferentialequations,Journalofcomputationalphysics375 (2018) 1339–1364
2018
-
[51]
Weinan, T
E. Weinan, T. Yu, The deep ritz method: A deep learning-based numerical algorithm for solving variational problems, Communications in Mathematics and Statistics 6 (2017) 1–12
2017
-
[52]
B.Fehrman,B.Gess,A.Jentzen,Convergenceratesforthestochasticgradientdescentmethodfornon-convexobjectivefunctions,TheJournal of Machine Learning Research 21 (1) (2020) 5354–5401
2020
-
[53]
Y. Lei, T. Hu, G. Li, K. Tang, Stochastic gradient descent for nonconvex learning without bounded gradient assumptions, IEEE transactions on neural networks and learning systems 31 (10) (2019) 4394–4400
2019
-
[54]
Mertikopoulos, N
P. Mertikopoulos, N. Hallak, A. Kavis, V. Cevher, On the almost sure convergence of stochastic gradient descent in non-convex problems, Advances in Neural Information Processing Systems 33 (2020) 1117–1128
2020
-
[55]
H. Gao, L. Sun, J.-X. Wang, Svd-pinns: Transfer learning of physics-informed neural networks via singular value decomposition, Computer Methods in Applied Mechanics and Engineering 393 (2022) 114787
2022
-
[56]
X.Glorot,Y.Bengio,Understandingthedifficultyoftrainingdeepfeedforwardneuralnetworks,in:Proceedingsofthethirteenthinternational conference on artificial intelligence and statistics, JMLR Workshop and Conference Proceedings, 2010, pp. 249–256
2010
-
[57]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, ICLR (2015)
2015
-
[58]
L. Lu, R. Pestourie, W. Yao, Z. Wang, F. Verdugo, S. G. Johnson, Physics-informed neural networks with hard constraints for inverse design, SIAM Journal on Scientific Computing 43 (6) (2021) B1105–B1132. Z. Liang et al.:Preprint submitted to ElsevierPage 40 of 40
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.