Temporal Coarse-Graining of Multi-Sector Default Count Data Generates Posterior-Implied Copulas
Pith reviewed 2026-06-26 10:43 UTC · model grok-4.3
The pith
Aggregating monthly sector default counts through a dynamic factor model's posterior paths produces horizon-dependent effective copulas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
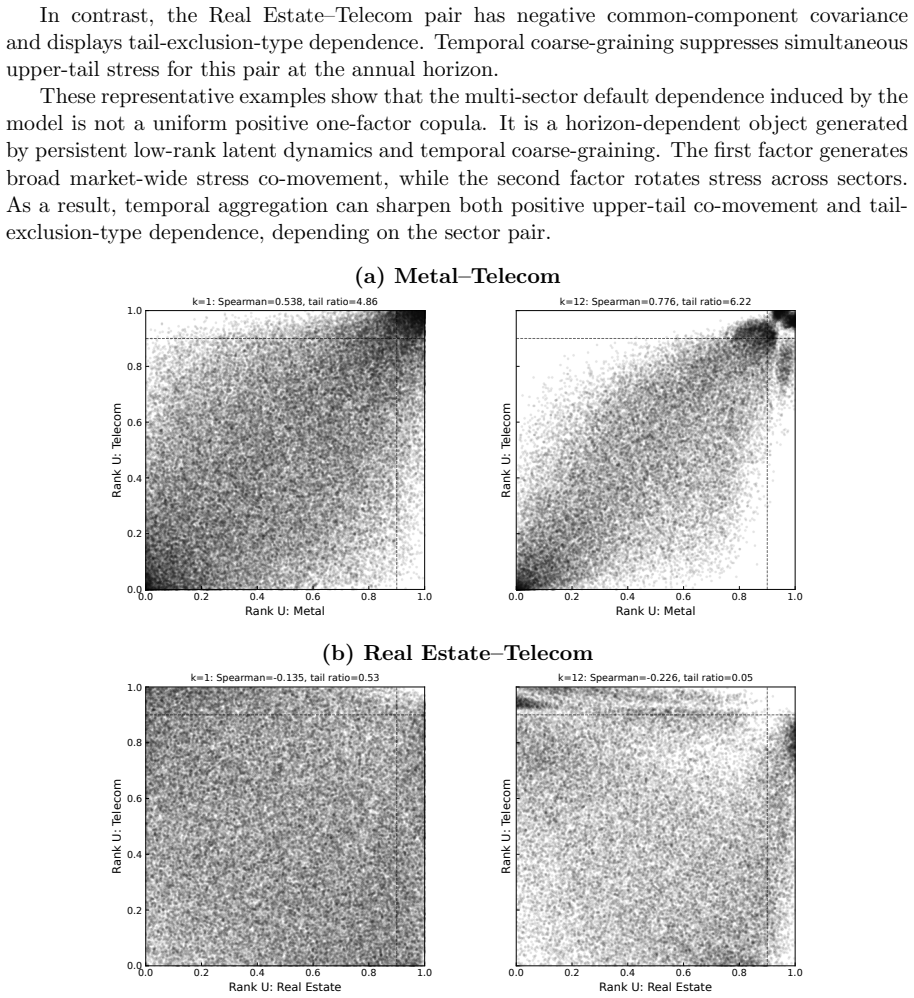
The central discovery is that temporal coarse-graining of the monthly posterior probability paths induces horizon-dependent distributions of sectoral default-probability vectors, from which effective correlation matrices, eigenvalue spectra, and posterior-implied rank copulas are obtained without specifying separate static dependence structures at each horizon.
What carries the argument
Survival aggregation of monthly posterior probability paths from the dynamic low-rank state-space model with fixed eigenvector loadings and binomial observation layer.
If this is right
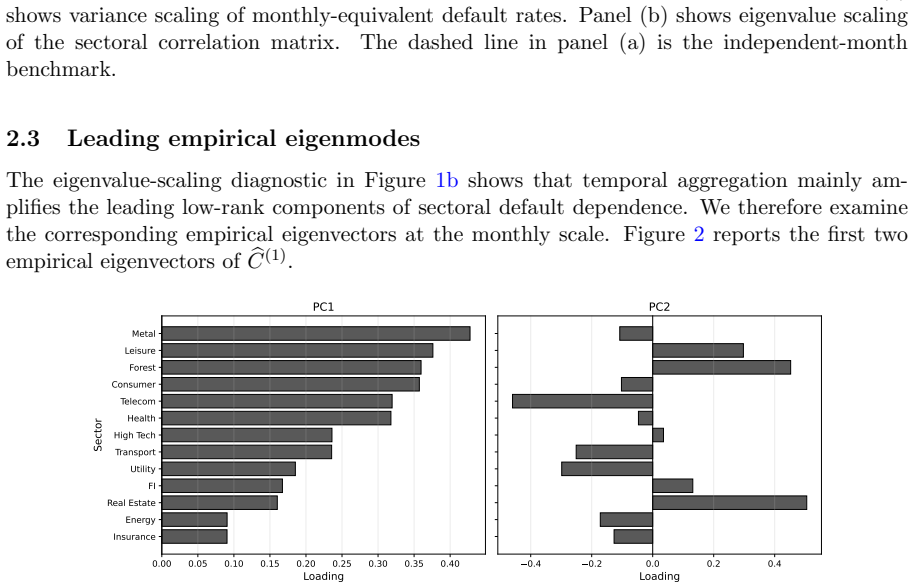
- A two-factor specification captures the dominant market-wide and sector-rotation modes in the monthly data.
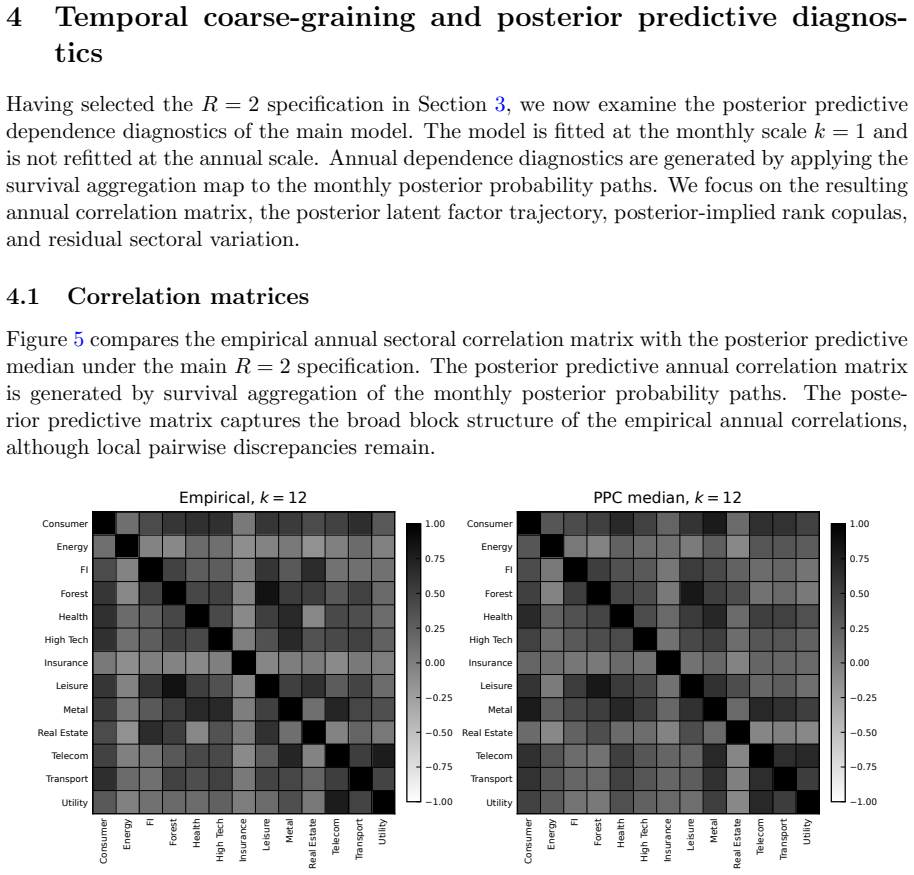
- The model reproduces the annual amplification of the leading eigenvalues without additional parameters.
- Posterior-implied copulas are heterogeneous across sector pairs and depend on the aggregation horizon.
- Dynamic factor versions reduce under-dispersion relative to static binomial and beta-binomial models, raising interval coverage and lowering CRPS for aggregate portfolio counts.
Where Pith is reading between the lines
- The same aggregation step could be applied to other count-valued time series to derive effective dependence structures at coarser frequencies.
- Forecast comparisons suggest that one-factor versions may suffice for aggregate portfolio risk while two-factor versions add value for sector-level calibration.
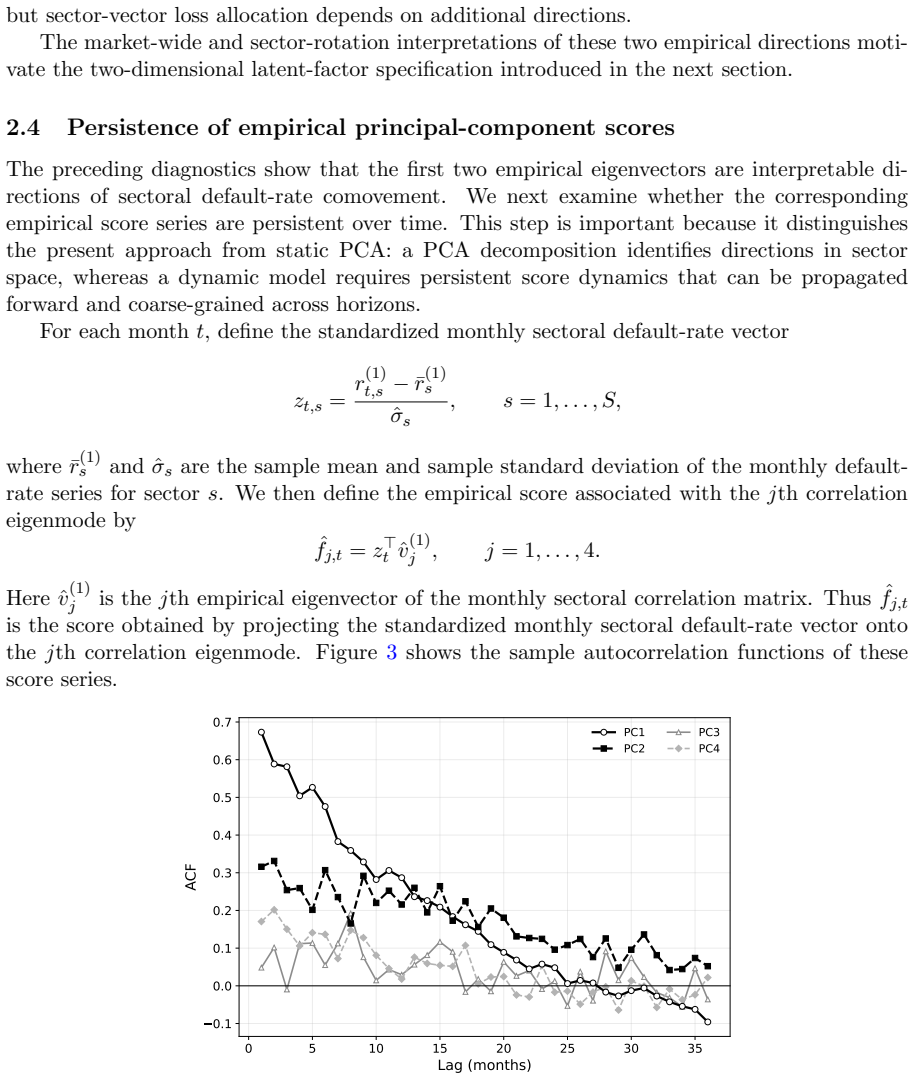
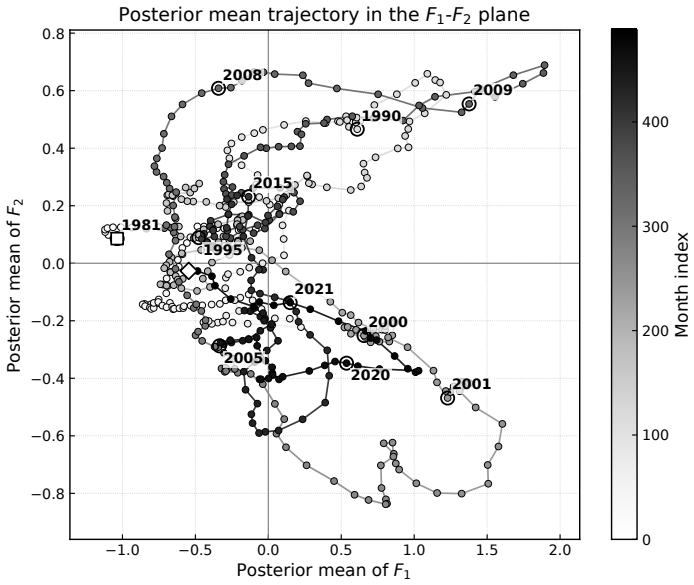
- The framework offers a route to time-varying dependence that arises from the observation process rather than from explicit time-varying parameters.
Load-bearing premise
The leading eigenvectors of the monthly sectoral default-rate correlation matrix remain fixed loading directions for the persistent latent credit-state factors across the sample.
What would settle it
If the aggregated posterior distributions from the fitted model do not reproduce the observed annual amplification of the leading eigenvalues in the data or fail to improve interval coverage and CRPS over static baselines in the annual forecast evaluation.
Figures





read the original abstract
Sectoral default dependence is usually described by a static correlation matrix, a static copula, or a small number of common factors. Such representations, when specified separately at each observation horizon, do not by themselves explain why the effective dependence observed in monthly credit data differs from that observed after annual aggregation. This paper proposes a dynamic low-rank state-space model for monthly multi-sector default-count data and studies the dependence structure induced by temporal coarse-graining. The leading eigenvectors of the monthly sectoral default-rate correlation matrix are used as fixed loading directions for persistent AR(1) latent credit-state factors, and defaults are modeled through a binomial observation layer. Survival aggregation of monthly posterior probability paths induces horizon-dependent distributions of sectoral default-probability vectors, from which effective correlation matrices, eigenvalue spectra, and posterior-implied rank copulas are obtained. Applied to S\&P monthly sector-level default-count data from 1981--01 to 2021--09, a two-factor specification captures the dominant market-wide and sector-rotation modes, reproduces the annual amplification of the leading eigenvalues, and generates heterogeneous copula structures across sector pairs. In an annual forecast evaluation, the dynamic factor specifications reduce the under-dispersion of static binomial and beta-binomial baselines, improving interval coverage and CRPS for aggregate portfolio counts. In log-score-based forecast comparisons, the one-factor specification is highly competitive, whereas the two-factor specification improves sector-level calibration as measured by per-sector CRPS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a dynamic low-rank state-space model for monthly multi-sector default-count data. Leading eigenvectors of the monthly sectoral default-rate correlation matrix are used as fixed loadings for persistent AR(1) latent credit-state factors, with defaults modeled via a binomial observation layer. Survival aggregation of monthly posterior paths induces horizon-dependent distributions of default-probability vectors, from which effective correlation matrices, eigenvalue spectra, and posterior-implied rank copulas are derived. Applied to S&P monthly sector-level default counts (1981-01 to 2021-09), a two-factor specification captures market-wide and sector-rotation modes, reproduces annual amplification of leading eigenvalues, generates heterogeneous copulas across sector pairs, and improves annual forecast performance on interval coverage and CRPS relative to static binomial and beta-binomial baselines; the one-factor variant is competitive on log-score.
Significance. If the empirical results hold under scrutiny, the work supplies a mechanistic account of how temporal coarse-graining from a low-dimensional monthly dynamic specification can generate the observed horizon dependence in credit data. The explicit construction of posterior-implied copulas and the reported forecast gains on aggregate portfolio counts constitute a practical contribution to multi-horizon credit-risk modeling. The parsimonious choice of data-driven fixed loadings combined with AR(1) dynamics is a strength in model transparency.
major comments (2)
- [§5 (Forecast Evaluation)] §5 (Forecast Evaluation): The central claim that the dynamic factor specifications reduce under-dispersion and improve CRPS and coverage rests on the annual out-of-sample evaluation. The manuscript does not report the numerical CRPS values, the number of forecast windows, the precise cross-validation scheme, or standard errors on the differences versus the static baselines. These details are required to assess whether the reported improvements are statistically and economically meaningful.
- [§2 (Model Specification)] §2 (Model Specification): The leading eigenvectors are extracted once from the full-sample monthly correlation matrix and held fixed as loading directions for the AR(1) factors. Because this choice directly determines the market-wide and sector-rotation modes that are later shown to reproduce annual eigenvalue amplification, a robustness check (e.g., rolling-window loadings or alternative factor extraction) is needed to confirm that the headline results are not artifacts of the fixed-loading construction.
minor comments (3)
- [Model section] The precise definition of the survival aggregation operator that maps monthly posterior paths to annual default-probability vectors should be stated as an explicit equation in the model section rather than described only in prose.
- [Results figures] Figure captions for the eigenvalue spectra and copula heat-maps should include the corresponding static-model benchmarks for direct visual comparison.
- [Abstract] The abstract states that the one-factor model is 'highly competitive' on log-score while the two-factor model improves per-sector CRPS; reporting the actual log-score and CRPS differences (even in a footnote) would make this trade-off quantitative.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [§5 (Forecast Evaluation)] The central claim that the dynamic factor specifications reduce under-dispersion and improve CRPS and coverage rests on the annual out-of-sample evaluation. The manuscript does not report the numerical CRPS values, the number of forecast windows, the precise cross-validation scheme, or standard errors on the differences versus the static baselines. These details are required to assess whether the reported improvements are statistically and economically meaningful.
Authors: We agree that the forecast evaluation section would benefit from greater transparency. In the revision we will add a table reporting the exact CRPS values (and log-scores) for the one-factor, two-factor, binomial, and beta-binomial specifications, state the number of annual forecast origins (2012–2021), describe the rolling-origin scheme, and include bootstrap standard errors on the CRPS differences. These additions will allow direct assessment of statistical and economic significance. revision: yes
-
Referee: [§2 (Model Specification)] The leading eigenvectors are extracted once from the full-sample monthly correlation matrix and held fixed as loading directions for the AR(1) factors. Because this choice directly determines the market-wide and sector-rotation modes that are later shown to reproduce annual eigenvalue amplification, a robustness check (e.g., rolling-window loadings or alternative factor extraction) is needed to confirm that the headline results are not artifacts of the fixed-loading construction.
Authors: The full-sample eigenvectors are used deliberately to obtain stable, data-driven directions that correspond to the dominant modes without introducing time-varying estimation noise into the factor interpretation. To address the concern, we will include an appendix that recomputes the leading eigenvectors on a rolling window ending at each forecast origin and verifies that the reported eigenvalue amplification, copula heterogeneity, and forecast gains remain qualitatively unchanged under this alternative construction. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper constructs a dynamic state-space model with loadings taken from the empirical monthly correlation matrix and an AR(1) latent process, then derives induced annual quantities via explicit aggregation of posterior paths. This is a standard modeling exercise whose outputs (eigenvalue amplification, heterogeneous copulas) are consequences of the stated assumptions rather than tautological re-statements of the inputs. The annual forecast evaluation against static baselines supplies an independent empirical check that is not forced by the monthly fitting step. No load-bearing step reduces by definition or by self-citation to the target result; the central claim remains falsifiable and externally benchmarked.
Axiom & Free-Parameter Ledger
free parameters (2)
- AR(1) persistence parameters
- Eigenvector loadings
axioms (2)
- domain assumption Defaults in each sector-month are conditionally binomial given the latent-state probability vector.
- domain assumption Latent factors evolve as independent AR(1) processes.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.jfineco.2018.04.008. Sanjiv R. Das, Darrell Duffie, Nikunj Kapadia, and Leandro Saita. Common failings: How corporate defaults are correlated.J. Finance, 62(1):93–117,
-
[2]
doi: 10.1111/j.1540-6261. 2007.01202.x. Mark H. A. Davis and Violet Lo. Infectious defaults.Quant. Finance, 1(4):382–387,
-
[3]
Darrell Duffie, Leandro Saita, and Ke Wang
doi: 10.1080/713665832. Darrell Duffie, Leandro Saita, and Ke Wang. Multi-period corporate default prediction with stochastic covariates.Journal of Financial Economics, 83:635–665,
-
[4]
Frailty correlated default
Darrell Duffie, Andreas Eckner, Guillaume Horel, and Leandro Saita. Frailty correlated default. J. Finance, 64(5):2089–2123,
2089
-
[5]
Eymen Errais, Kay Giesecke, and Lisa R
doi: 10.1111/j.1540-6261.2009.01485.x. Eymen Errais, Kay Giesecke, and Lisa R. Goldberg. Affine point processes and portfolio credit risk.SIAM J. Financial Math., 1(1):642–665,
-
[6]
32 Tilmann Gneiting and Matthias Katzfuss
doi: 10.1137/090771272. 32 Tilmann Gneiting and Matthias Katzfuss. Probabilistic forecasting.Annual Review of Statistics and Its Application, 1:125–151,
-
[7]
doi: 10.1146/annurev-statistics-062713-085831. Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and es- timation.Journal of the American Statistical Association, 102(477):359–378,
-
[8]
doi: 10.1198/016214506000001437. A. G. Hawkes. Spectra of some self-exciting and mutually exciting point processes.Biometrika, 58(1):83–90,
-
[9]
doi: 10.1093/biomet/58.1.83. Masato Hisakado, Kodai Hattori, and Shintaro Mori. Multi-dimensional self-exciting nbd pro- cess and default portfolios.The Review of Socionetwork Strategies, 16:493–512,
-
[10]
doi: 10.1007/s12626-022-00122-y. J.P. Morgan. CreditMetrics: Technical document. Technical report, J.P. Morgan,
-
[11]
Dynamic factor models with macro, frailty, and industry effects for U.S
Siem Jan Koopman, Andr´ e Lucas, and Bernd Schwaab. Dynamic factor models with macro, frailty, and industry effects for U.S. default counts: The credit crisis of 2008.Journal of Business & Economic Statistics, 30(4):521–532,
2008
-
[12]
doi: 10.3905/jfi.2000.319253. Alexander J. McNeil, R¨ udiger Frey, and Paul Embrechts.Quantitative Risk Management: Concepts, Techniques and Tools. Princeton University Press, Princeton, revised edition,
-
[13]
Shintaro Mori. Identifiability of contagion components amid environmental fluctuations in aggregated default counts, 2026a. arXiv preprint arXiv:2604.18118. Shintaro Mori. Temporal coarse-graining of latent default-probability paths generates effective default correlation, 2026b. arXiv preprint arXiv:2606.12446. Ayaka Sakata, Masato Hisakado, and Shintaro...
-
[14]
doi: 10.1143/JPSJ.76.054801. Philipp J. Sch¨ onbucher.Credit Derivatives Pricing Models: Models, Pricing and Implementa- tion. John Wiley & Sons,
-
[15]
doi: https://doi.org/10.1016/j.cnsns.2026.109886
ISSN 1007-5704. doi: https://doi.org/10.1016/j.cnsns.2026.109886. Oldrich A. Vasicek. Limiting loan loss probability distribution.KMV Corporation,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.