Scalable Maximum Entropy Reinforcement Learning for Diffusion Policies via Adjoint Matching
Pith reviewed 2026-06-26 10:35 UTC · model grok-4.3
The pith
Adjoint matching enables simulation-free training of diffusion policies for online maximum entropy reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adjoint matching transfers to score-based diffusion policy training to deliver simulation-free maximum entropy RL updates that avoid both likelihood estimation and differentiation through the diffusion process.
What carries the argument
Adjoint matching, a stochastic optimal control device that matches adjoint variables to obtain policy gradients without trajectory simulation or likelihood computation.
If this is right
- Diffusion policies become trainable online without ground-truth trajectories.
- Training overhead drops because simulation and backpropagation steps are removed.
- The same matching approach supports the added robustness extensions described in the paper.
- Maximum entropy objectives remain compatible with the resulting diffusion policies.
Where Pith is reading between the lines
- The technique could be tested on tasks where diffusion policies previously failed due to compute limits.
- It opens a route to apply similar adjoint ideas to other score-based generative models in control.
- If the transfer holds, hybrid methods combining adjoint matching with off-policy corrections become feasible next steps.
Load-bearing premise
The adjoint-matching technique transfers directly from stochastic optimal control to diffusion policy score training in online RL without extra assumptions that would force simulation or invalidate the method.
What would settle it
An experiment on a standard continuous-control benchmark where the adjoint-matching procedure either diverges or requires explicit simulation or backpropagation through diffusion would falsify the claim.
Figures

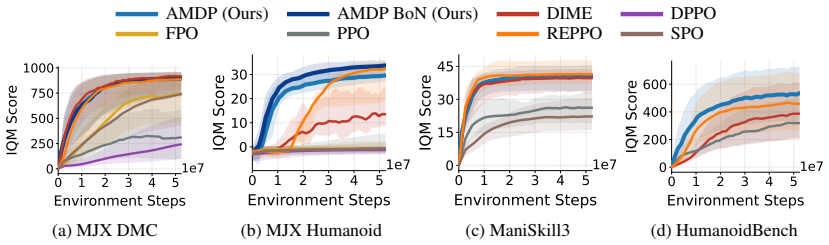
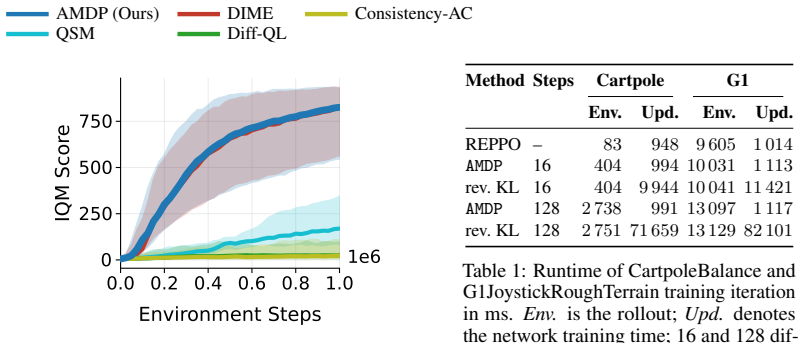
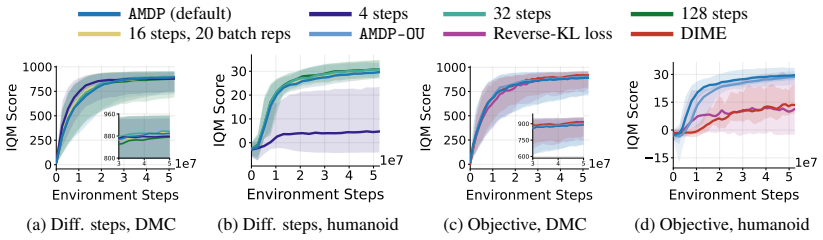

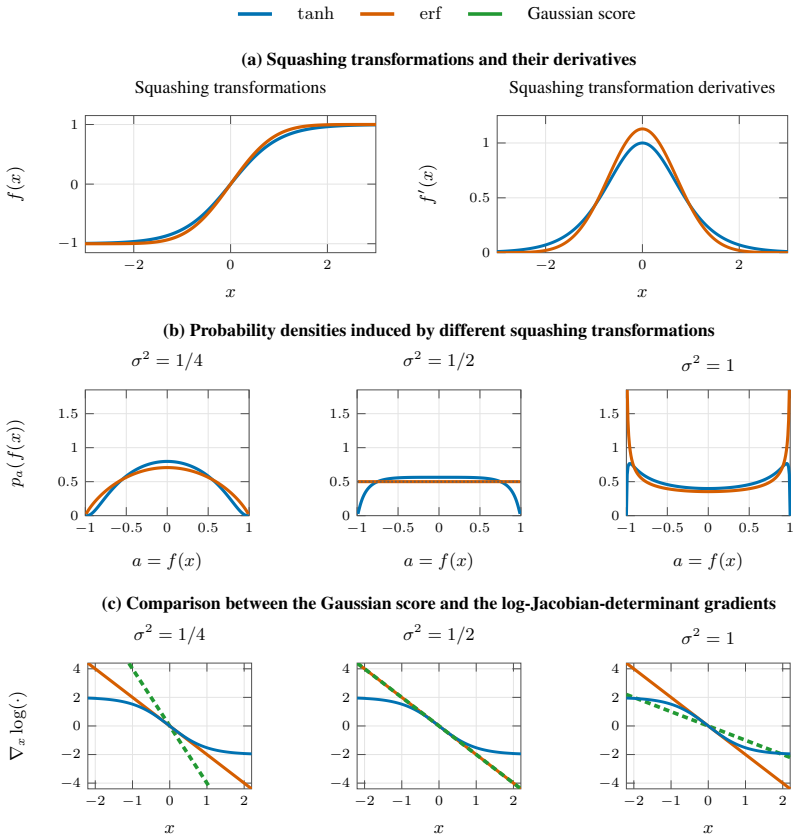




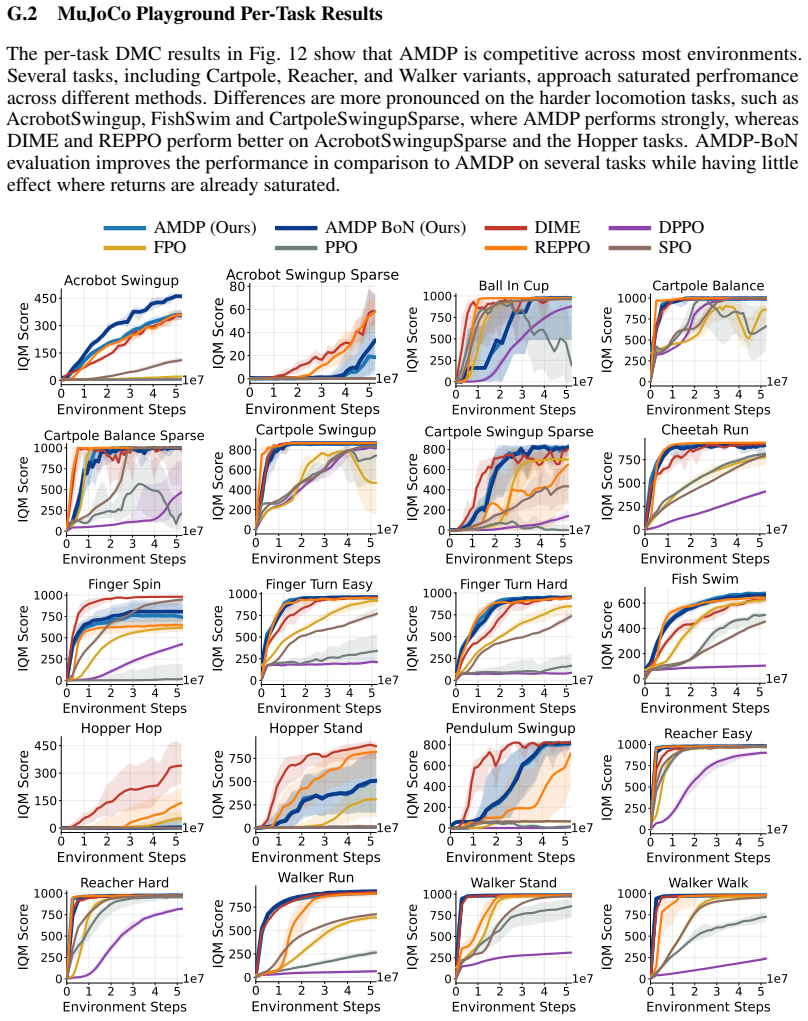




read the original abstract
Diffusion policies have recently emerged as a powerful paradigm for representing complex action distributions in reinforcement learning (RL). However, their application to online RL remains limited by the challenge of scalable training in the absence of ground-truth data, where standard optimization techniques such as score matching are not directly applicable. In this work, we introduce a highly efficient algorithm for optimizing diffusion policies by leveraging recent advances in stochastic optimal control. Our approach is based on adjoint matching, which enables simulation-free training and circumvents the need for explicit likelihood estimation or costly backpropagation through the diffusion process. Furthermore, we propose several extensions that improve the robustness and stability of the method in practical settings. Empirical results demonstrate that our approach achieves competitive performance while significantly reducing computational overhead, making diffusion policies more viable for online RL scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an adjoint-matching algorithm, drawn from stochastic optimal control, that enables simulation-free training of diffusion policies for online maximum-entropy RL. The method is asserted to avoid explicit likelihood estimation and back-propagation through the diffusion process; several robustness extensions are proposed, and empirical results are reported to show competitive performance at substantially lower computational cost.
Significance. If the adjoint-matching construction truly yields a simulation-free, score-free objective that remains valid for state-action-dependent rewards, the work would remove a major computational barrier to using expressive diffusion policies in online RL settings.
major comments (2)
- [Abstract] Abstract: the central claim that adjoint matching 'enables simulation-free training' and 'circumvents ... costly backpropagation through the diffusion process' is stated without any derivation, equation, or proof sketch; the stress-test concern that the matching step may implicitly reintroduce score estimation or Monte-Carlo trajectory sampling is therefore impossible to evaluate from the manuscript as presented.
- [Abstract] Abstract / claimed method: the transfer of the SOC adjoint to score-based diffusion policies is asserted to preserve the simulation-free property, yet no explicit rewriting of the adjoint dynamics in terms of the policy score (without instantiating the reverse SDE) is supplied; this is load-bearing for the 'scalable' and 'simulation-free' assertions.
minor comments (1)
- [Abstract] Abstract: the phrase 'several extensions that improve the robustness and stability' is used without naming or characterizing those extensions.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the need for clearer presentation of the core claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that adjoint matching 'enables simulation-free training' and 'circumvents ... costly backpropagation through the diffusion process' is stated without any derivation, equation, or proof sketch; the stress-test concern that the matching step may implicitly reintroduce score estimation or Monte-Carlo trajectory sampling is therefore impossible to evaluate from the manuscript as presented.
Authors: The abstract serves as a high-level summary. The full derivation establishing the simulation-free property, including the explicit adjoint-matching objective that avoids both likelihood estimation and back-propagation through the diffusion process, appears in Section 3 (Equations 4–7). These equations demonstrate that the matching step operates directly on the forward process without requiring reverse-SDE instantiation or additional Monte-Carlo sampling. We will revise the abstract to include a concise parenthetical reference to the main theoretical result. revision: yes
-
Referee: [Abstract] Abstract / claimed method: the transfer of the SOC adjoint to score-based diffusion policies is asserted to preserve the simulation-free property, yet no explicit rewriting of the adjoint dynamics in terms of the policy score (without instantiating the reverse SDE) is supplied; this is load-bearing for the 'scalable' and 'simulation-free' assertions.
Authors: Section 3.2 supplies the requested rewriting: the adjoint dynamics are expressed solely through the policy score (Equation 8) by substituting the score-based representation of the diffusion policy into the stochastic optimal control adjoint, without ever instantiating the reverse SDE. This substitution is what preserves the simulation-free character. We will add a short proof sketch of this rewriting to the introduction of the revised manuscript to make the load-bearing step immediately visible. revision: yes
Circularity Check
No significant circularity; adjoint matching invoked as external SOC advance
full rationale
The abstract and provided context present adjoint matching as a transfer from recent stochastic optimal control advances, enabling simulation-free training without any exhibited reduction of the central claim to a self-defined quantity, fitted parameter, or self-citation chain within the paper. No equations or load-bearing steps are shown that equate the claimed result to its own inputs by construction. The derivation is treated as self-contained against external SOC benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning at the edge of the statistical precipice.Advances in neural information processing systems, 34:29304–29320, 2021
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron C Courville, and Marc Bellemare. Deep reinforcement learning at the edge of the statistical precipice.Advances in neural information processing systems, 34:29304–29320, 2021
2021
-
[2]
floq: Training critics via flow-matching for scaling compute in value-based RL
Bhavya Kumar Agrawalla, Michal Nauman, Khush Agrawal, and Aviral Kumar. floq: Training critics via flow-matching for scaling compute in value-based RL. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026. URL https://openreview.net/ forum?id=m14YNdmPAh
2026
-
[3]
Tenenbaum, Tommi S
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua B. Tenenbaum, Tommi S. Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision making? InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[4]
URLhttps://openreview.net/forum?id=sP1fo2K9DFG
OpenReview.net, 2023. URLhttps://openreview.net/forum?id=sP1fo2K9DFG
2023
-
[5]
Iterated denoising energy matching for sampling from boltzmann densities
Tara Akhound-Sadegh, Jarrid Rector-Brooks, Joey Bose, Sarthak Mittal, Pablo Lemos, Cheng- Hao Liu, Marcin Sendera, Siamak Ravanbakhsh, Gauthier Gidel, Yoshua Bengio, Nikolay Malkin, and Alexander Tong. Iterated denoising energy matching for sampling from boltzmann densities. InForty-first International Conference on Machine Learning, 2024. URL https: //op...
2024
-
[6]
Stochastic interpolants with data-dependent couplings.arXiv preprint arXiv:2310.03725, 2023
Michael S Albergo, Mark Goldstein, Nicholas M Boffi, Rajesh Ranganath, and Eric Vanden-Eijnden. Stochastic interpolants with data-dependent couplings.arXiv preprint arXiv:2310.03725, 2023
arXiv 2023
-
[7]
An optimal control perspective on diffusion- based generative modeling.Transactions on Machine Learning Research, 2024
Julius Berner, Lorenz Richter, and Karen Ullrich. An optimal control perspective on diffusion- based generative modeling.Transactions on Machine Learning Research, 2024
2024
-
[8]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[9]
Denis Blessing, Julius Berner, Lorenz Richter, Carles Domingo-Enrich, Yuanqi Du, Arash Vahdat, and Gerhard Neumann. Trust region constrained measure transport in path space for stochastic optimal control and inference.arXiv preprint arXiv:2508.12511, 2025
arXiv 2025
-
[10]
Underdamped diffusion bridges with applications to sampling
Denis Blessing, Julius Berner, Lorenz Richter, and Gerhard Neumann. Underdamped diffusion bridges with applications to sampling. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[11]
Denis Blessing, Xiaogang Jia, and Gerhard Neumann. End-to-end learning of Gaussian mixture priors for diffusion sampler.arXiv preprint arXiv:2503.00524, 2025
arXiv 2025
-
[12]
Springer, 2007
Vladimir Igorevich Bogachev and Maria Aparecida Soares Ruas.Measure theory, volume 1. Springer, 2007
2007
-
[13]
Cambridge university press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex optimization. Cambridge university press, 2004
2004
-
[14]
Jax: Autograd and xla.Astrophysics Source Code Library, pages ascl–2111, 2021
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, et al. Jax: Autograd and xla.Astrophysics Source Code Library, pages ascl–2111, 2021
2021
-
[15]
DIME: Diffusion-based maximum entropy reinforcement learning.arXiv preprint arXiv:2502.02316, 2025
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palanicek, Jan Peters, Georgia Chal- vatzaki, and Gerhard Neumann. DIME: Diffusion-based maximum entropy reinforcement learning.arXiv preprint arXiv:2502.02316, 2025
arXiv 2025
-
[16]
Offline reinforcement learn- ing via high-fidelity generative behavior modeling
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learn- ing via high-fidelity generative behavior modeling. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net,
2023
-
[17]
URLhttps://openreview.net/forum?id=42zs3qa2kpy. 11
-
[18]
Score regularized policy optimization through diffusion behavior
Huayu Chen, Cheng Lu, Zhengyi Wang, Hang Su, and Jun Zhu. Score regularized policy optimization through diffusion behavior. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=xCRr9DrolJ
2024
-
[19]
One-step flow policy mirror descent,
Tianyi Chen, Haitong Ma, Na Li, Kai Wang, and Bo Dai. One-step flow policy mirror descent,
-
[20]
URLhttps://arxiv.org/abs/2507.23675
-
[21]
Diffusion policies creating a trust region for offline reinforcement learning
Tianyu Chen, Zhendong Wang, and Mingyuan Zhou. Diffusion policies creating a trust region for offline reinforcement learning. InThe Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems, 2024. URL https://openreview.net/forum?id=74c9EOng9C
2024
-
[22]
On the relation between optimal transport and Schrödinger bridges: A stochastic control viewpoint.Journal of Optimization Theory and Applications, 169(2):671–691, 2016
Yongxin Chen, Tryphon T Georgiou, and Michele Pavon. On the relation between optimal transport and Schrödinger bridges: A stochastic control viewpoint.Journal of Optimization Theory and Applications, 169(2):671–691, 2016
2016
-
[23]
Boosting continuous control with consistency policy
Yuhui Chen, Haoran Li, and Dongbin Zhao. Boosting continuous control with consistency policy. In Mehdi Dastani, Jaime Simão Sichman, Natasha Alechina, and Virginia Dignum, edi- tors,Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, AAMAS 2024, Auckland, New Zealand, May 6-10, 2024, pages 335–344. International F...
-
[24]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[25]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[26]
A stochastic control approach to reciprocal diffusion processes.Applied mathematics and Optimization, 23(1):313–329, 1991
Paolo Dai Pra. A stochastic control approach to reciprocal diffusion processes.Applied mathematics and Optimization, 23(1):313–329, 1991
1991
-
[27]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=UWUUVKtKeu
2024
-
[28]
GenPO: Generative diffusion models meet on-policy reinforcement learning
Shutong Ding, Ke Hu, Shan Zhong, Haoyang Luo, Weinan Zhang, Jingya Wang, Jun Wang, and Ye Shi. GenPO: Generative diffusion models meet on-policy reinforcement learning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=BmRNz1TpCc
2026
-
[29]
Consistency models as a rich and efficient policy class for reinforce- ment learning
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforce- ment learning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=v8jdwkUNXb
2024
-
[30]
Stochas- tic optimal control matching.Advances in Neural Information Processing Systems, 37: 112459–112504, 2024
Carles Domingo-Enrich, Jiequn Han, Brandon Amos, Joan Bruna, and Ricky T Chen. Stochas- tic optimal control matching.Advances in Neural Information Processing Systems, 37: 112459–112504, 2024
2024
-
[31]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2409.08861
arXiv 2025
-
[32]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[33]
EXPO: Stable reinforcement learning with expressive policies
Perry Dong, Qiyang Li, Dorsa Sadigh, and Chelsea Finn. EXPO: Stable reinforcement learning with expressive policies. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=aFjSjkB6CV. 12
2026
-
[34]
Value flows
Perry Dong, Chongyi Zheng, Chelsea Finn, Dorsa Sadigh, and Benjamin Eysenbach. Value flows. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=2VyNYUVF2k
2026
-
[35]
Maximum entropy reinforcement learning with diffusion policy
Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion policy. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=CpjKXe9rY7
2025
-
[36]
Mean flow policy optimization, 2026
Xiaoyi Dong, Xi Sheryl Zhang, and Jian Cheng. Mean flow policy optimization, 2026. URL https://arxiv.org/abs/2604.14698
Pith/arXiv arXiv 2026
-
[37]
Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning
Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, and Bingyi Jing. Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview...
2025
-
[38]
Stop regressing: Training value functions via classification for scalable deep RL
Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Taiga, Yevgen Chebotar, Ted Xiao, Alex Irpan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, Aviral Kumar, and Rishabh Agarwal. Stop regressing: Training value functions via classification for scalable deep RL. InForty-first International Conference on Machine Learning, 2024. URL https: //openr...
2024
-
[39]
Random fields and diffusion processes
Hans Föllmer. Random fields and diffusion processes. InÉcole d’Été de Probabilités de Saint-Flour XV–XVII, 1985–87, pages 101–203. Springer, 1988
1985
-
[40]
Résolution d’un système d’équations de m
Robert Fortet. Résolution d’un système d’équations de m. schrödinger.Journal de mathéma- tiques pures et appliquées, 19(1-4):83–105, 1940
1940
-
[41]
Behavior-regularized diffusion policy optimization for offline reinforcement learning
Chen-Xiao Gao, Chenyang Wu, Mingjun Cao, Chenjun Xiao, Yang Yu, and Zongzhang Zhang. Behavior-regularized diffusion policy optimization for offline reinforcement learning. InForty- second International Conference on Machine Learning, 2025. URL https://openreview. net/forum?id=pUCYJ9JJuZ
2025
-
[42]
Flowrl: A taxonomy and modular framework for reinforcement learning with diffusion policies, 2026
Chenxiao Gao, Edward Chen, Tianyi Chen, and Bo Dai. Flowrl: A taxonomy and modular framework for reinforcement learning with diffusion policies, 2026. URL https://arxiv. org/abs/2603.27450
arXiv 2026
-
[43]
Flow matching policy with entropy regularization, 2026
Ting Gao, Stavros Orfanoudakis, Nan Lin, Elvin Isufi, Winnie Daamen, and Serge Hoogen- doorn. Flow matching policy with entropy regularization, 2026. URL https://arxiv.org/ abs/2603.17685
Pith/arXiv arXiv 2026
-
[44]
Proximal policy optimization in path space: A schrödinger bridge perspective, 2026
Yuehu Gong, Zeyuan Wang, Yulin Chen, and Yanwei Fu. Proximal policy optimization in path space: A schrödinger bridge perspective, 2026. URL https://arxiv.org/abs/2603. 21621
2026
-
[45]
Know your boundaries: The necessity of explicit behavioral cloning in offline rl, 2022
Wonjoon Goo and Scott Niekum. Know your boundaries: The necessity of explicit behavioral cloning in offline rl, 2022. URLhttps://arxiv.org/abs/2206.00695
arXiv 2022
-
[46]
Maniskill2: A unified benchmark for generalizable manipulation skills
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023
2023
-
[47]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational conference on machine learning, pages 1352–1361. PMLR, 2017
2017
-
[48]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018. 13
2018
-
[49]
Soft actor-critic algorithms and applications, 2019
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Soft actor-critic algorithms and applications, 2019. URLhttps://arxiv.org/abs/1812.05905
Pith/arXiv arXiv 2019
-
[51]
Aaron Havens, Benjamin Kurt Miller, Bing Yan, Carles Domingo-Enrich, Anuroop Sriram, Brandon Wood, Daniel Levine, Bin Hu, Brandon Amos, Brian Karrer, et al. Adjoint sampling: Highly scalable diffusion samplers via adjoint matching.arXiv preprint arXiv:2504.11713, 2025
arXiv 2025
-
[52]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[53]
Langevin soft actor- critic: Efficient exploration through uncertainty-driven critic learning
Haque Ishfaq, Guangyuan Wang, Sami Nur Islam, and Doina Precup. Langevin soft actor- critic: Efficient exploration through uncertainty-driven critic learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=FvQsk3la17
2025
-
[54]
Sampling from energy-based policies using diffusion
Vineet Jain, Tara Akhound-Sadegh, and Siamak Ravanbakhsh. Sampling from energy-based policies using diffusion. InReinforcement Learning Conference, 2025. URL https:// openreview.net/forum?id=LEBzhd3TQ9
2025
-
[55]
Tenenbaum, and Sergey Levine
Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors,International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, Proceedings of Machine Learnin...
2022
-
[56]
Efficient dif- fusion policies for offline reinforcement learning
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient dif- fusion policies for offline reinforcement learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Informa- tion Processing Systems 2023, NeurIP...
2023
-
[57]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35: 26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35: 26565–26577, 2022
2022
-
[58]
Direct soft-policy sampling via langevin dynamics, 2026
Donghyeon Ki, Hee-Jun Ahn, Kyungyoon Kim, and Byung-Jun Lee. Direct soft-policy sampling via langevin dynamics, 2026. URLhttps://arxiv.org/abs/2602.07873
arXiv 2026
-
[59]
Probability densities with given marginals.The Annals of Mathematical Statistics, 39(4):1236–1243, 1968
Solomon Kullback. Probability densities with given marginals.The Annals of Mathematical Statistics, 39(4):1236–1243, 1968
1968
-
[60]
Hyperspherical normalization for scalable deep reinforcement learning
Hojoon Lee, Youngdo Lee, Takuma Seno, Donghu Kim, Peter Stone, and Jaegul Choo. Hyperspherical normalization for scalable deep reinforcement learning. In42nd International Conference on Machine Learning, ICML 2025. ML Research Press, 2025
2025
-
[61]
Christian Léonard. A survey of the Schrödinger problem and some of its connections with optimal transport.arXiv preprint arXiv:1308.0215, 2013
arXiv 2013
-
[62]
Q-learning with adjoint matching
Qiyang Li and Sergey Levine. Q-learning with adjoint matching. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026. URL https://openreview.net/ forum?id=vd4eNAdtO6. 14
2026
-
[63]
Reinforcement learning with action chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=XUks1Y96NR
2026
-
[65]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[66]
Adjoint Schrödinger Bridge Sampler.arXiv preprint arXiv:2506.22565, 2025
Guan-Horng Liu, Jaemoo Choi, Yongxin Chen, Benjamin Kurt Miller, and Ricky TQ Chen. Adjoint Schrödinger Bridge Sampler.arXiv preprint arXiv:2506.22565, 2025
arXiv 2025
-
[67]
Flow-grpo: Training flow matching models via online rl, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl, 2025. URLhttps://arxiv.org/abs/2505.05470
Pith/arXiv arXiv 2025
-
[68]
Flow-GRPO: Training flow matching models via online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=oCBKGw5HNf
2026
-
[69]
Xingchao Liu, Lemeng Wu, Mao Ye, and Qiang Liu. Let us build bridges: Understanding and extending diffusion generative models.arXiv preprint arXiv:2208.14699, 2022
arXiv 2022
-
[70]
Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Conference on Machine Learning, ICML 2023, 23-29...
2023
-
[71]
Flow-based policy for online reinforcement learning
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, Tao Kong, Jiafeng Xu, and Xiao Ma. Flow-based policy for online reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026. URL https://openreview.net/forum?id=CANUXhPoyn
2026
-
[72]
Flac: Maximum entropy rl via kinetic energy regularized bridge matching, 2026
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, and Xiao Ma. Flac: Maximum entropy rl via kinetic energy regularized bridge matching, 2026. URLhttps://arxiv.org/abs/2602.12829
arXiv 2026
-
[73]
Efficient online reinforcement learning for diffusion policy
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy. InForty-second International Conference on Machine Learning,
-
[74]
URLhttps://openreview.net/forum?id=6Anv3KB9lz
-
[75]
Haitong Ma, Ofir Nabati, Aviv Rosenberg, Bo Dai, Oran Lang, Idan Szpektor, Craig Boutilier, Na Li, Shie Mannor, Lior Shani, et al. Reinforcement learning with discrete diffusion policies for combinatorial action spaces.arXiv preprint arXiv:2509.22963, 2025
Pith/arXiv arXiv 2025
-
[76]
Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning
Liyuan Mao, Haoran Xu, Xianyuan Zhan, Weinan Zhang, and Amy Zhang. Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Inf...
2024
-
[77]
Flow matching policy gradients
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=eoEmoKoQpJ. 15
2026
-
[78]
Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło´s, and Marek Cygan. Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control. Advances in neural information processing systems, 37:113038–113071, 2024
2024
-
[79]
Nikolas Nüsken and Lorenz Richter. Solving high-dimensional Hamilton–Jacobi–Bellman PDEs using neural networks: perspectives from the theory of controlled diffusions and mea- sures on path space.Partial differential equations and applications, 2:1–48, 2021
2021
-
[80]
Nikolas Nüsken and Lorenz Richter. Solving high-dimensional hamilton–jacobi–bellman pdes using neural networks: perspectives from the theory of controlled diffusions and measures on path space.Partial differential equations and applications, 2(4):48, 2021
2021
-
[81]
Stochastic differential equations
Bernt Øksendal. Stochastic differential equations. InStochastic differential equations: an introduction with applications, pages 38–50. Springer, 2003
2003
-
[82]
Fabian Otto, Philipp Becker, Ngo Anh Vien, Hanna Carolin Ziesche, and Gerhard Neu- mann. Differentiable trust region layers for deep reinforcement learning.arXiv preprint arXiv:2101.09207, 2021
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.