Neural Operator Processes for Probabilistic Operator Learning under Partial Observations
Pith reviewed 2026-06-26 09:03 UTC · model grok-4.3
The pith
Neural Operator Processes predict full function fields from sparse partial observations by unifying neural process conditioning with operator decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neural Operator Processes (NOPs) provide a shared encoder-decoder architecture that conditions on sparse joint input-output observations using either convolutional pooled summaries or query-aligned attention, then decodes full output fields while supporting both deterministic and probabilistic modes through latent stochastic variables; performance varies with PDE geometry such that local geometry preservation proves essential outside periodic regimes.
What carries the argument
Neural Operator Processes, a framework that merges neural-process conditioning on sparse context with neural-operator decoding to handle partial observations in function space.
If this is right
- Sparse conditional operator learning matches dense-grid results in multiple function regression and PDE settings.
- Local context-query geometry must be preserved for reliable results on non-periodic problems.
- Uncertainty-aware predictions succeed specifically when latent conditioning augments rather than overrides geometric pathways.
- The same encoder-decoder structure supports both deterministic and probabilistic output fields from limited observations.
Where Pith is reading between the lines
- The approach could apply to sensor networks or irregular sampling in real-world physical monitoring where full grids are unavailable.
- Different PDE types may require tailored choices between summary pooling and attention mechanisms rather than a single default strategy.
- Extending the latent conditioning to handle time-dependent or multi-physics operators might follow naturally from the geometry-dependent findings.
Load-bearing premise
The interaction between convolutional or attention-based conditioning and latent stochastic variables behaves differently across periodic versus non-periodic PDE geometries in a way that explains the observed performance patterns.
What would settle it
A controlled test on a non-periodic PDE benchmark where removing query-aligned attention or local geometry preservation causes sparse NOP performance to fall significantly below dense-grid baselines while the full model matches them.
Figures



read the original abstract
Neural operators learn mappings between function spaces, but are typically developed with dense input-output training fields and fully observed inputs at inference. Many scientific problems require instead predicting solution fields from sparse, irregular, or partial observations under uncertainty. We introduce Neural Operator Processes (NOPs), a framework that unifies neural-process conditioning with neural-operator decoding to predict full output fields from limited context. NOPs condition on sparse joint input-output observations and support deterministic and probabilistic prediction within a shared encoder-decoder architecture. We study two conditioning strategies, convolutional pooled summaries and query-aligned attention, and analyze how their interaction with latent stochastic variables depends on PDE geometry. Across function regression and three PDE benchmarks, we find that sparse conditional operator learning is viable and can match dense-grid behavior in several regimes, that preserving local context-query geometry is essential in non-periodic settings but less so in spectrally smooth periodic regimes, and that uncertainty-aware operator learning succeeds when latent conditioning complements rather than overwrites the local geometric pathway. These results provide a basis for probabilistic operator learning under partial observations and help bridge operator learning and probabilistic meta-learning in function space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural Operator Processes (NOPs), a framework unifying neural-process conditioning with neural-operator decoding to predict full output fields from sparse joint input-output observations under uncertainty. It examines two conditioning strategies (convolutional pooled summaries and query-aligned attention) and analyzes their interaction with latent stochastic variables as a function of PDE geometry. Across function regression and three PDE benchmarks, the work claims that sparse conditional operator learning is viable and can match dense-grid performance in several regimes, that preserving local context-query geometry is essential in non-periodic settings but less critical in spectrally smooth periodic regimes, and that uncertainty-aware learning succeeds when latent conditioning complements rather than overwrites the local geometric pathway.
Significance. If the empirical results hold after addressing experimental controls, the work would be significant for enabling probabilistic operator learning in scientific domains with partial observations, bridging neural operators and neural processes in function space. The shared encoder-decoder architecture supporting both deterministic and probabilistic modes is a constructive contribution.
major comments (1)
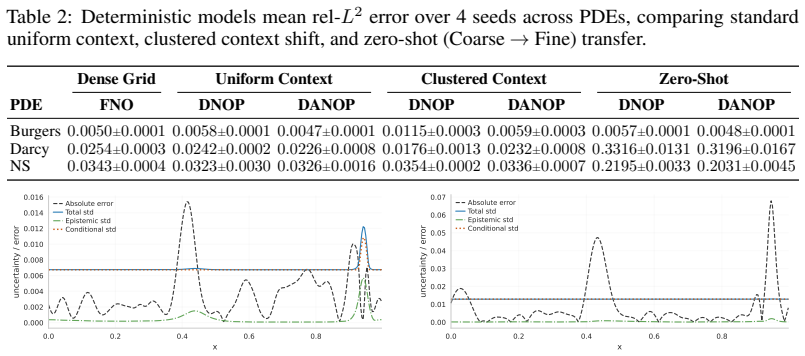
- [Abstract] Abstract: The central claim that performance differences and the interaction between convolutional pooled summaries, query-aligned attention, and latent variables depend on PDE geometry (periodic vs. non-periodic) is load-bearing but not secured. The three PDE benchmarks may confound geometry with uncontrolled factors such as choice of specific PDE, spectral content, observation density patterns, or hyperparameter settings; no matched controls or ablations isolating geometry as the causal driver are described.
minor comments (1)
- [Abstract] The abstract would benefit from naming the three PDE benchmarks and briefly indicating the observation densities or grid types used, to allow readers to assess the scope of the viability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below, acknowledging where additional clarification or revision is warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that performance differences and the interaction between convolutional pooled summaries, query-aligned attention, and latent variables depend on PDE geometry (periodic vs. non-periodic) is load-bearing but not secured. The three PDE benchmarks may confound geometry with uncontrolled factors such as choice of specific PDE, spectral content, observation density patterns, or hyperparameter settings; no matched controls or ablations isolating geometry as the causal driver are described.
Authors: We agree that the claim would be strengthened by explicit matched controls that vary only geometry while holding the underlying PDE fixed. Our three benchmarks were selected as representative cases from the neural-operator literature (one non-periodic Darcy-flow problem and two spectrally smooth periodic problems), using identical hyperparameter schedules, observation densities, and encoder-decoder architectures across all experiments. Spectral-content differences are an intrinsic feature of the periodic/non-periodic distinction under study rather than an uncontrolled variable. Nevertheless, we acknowledge the absence of a dedicated ablation that isolates geometry alone. In the revised manuscript we will add a dedicated limitations paragraph in the discussion section that explicitly lists potential confounding factors and note that future work could employ periodic and non-periodic variants of the same base PDE. This constitutes a partial revision that clarifies the experimental rationale without altering the reported empirical trends. revision: partial
Circularity Check
No circularity: new architectural framework with empirical evaluation
full rationale
The paper introduces Neural Operator Processes as a unification of neural-process conditioning and neural-operator decoding, then reports empirical results across function regression and PDE benchmarks comparing two conditioning strategies. No derivation chain, fitted-parameter prediction, or self-citation load-bearing step is present in the provided text; the central claims rest on architectural design choices and benchmark performance rather than any reduction to inputs by construction or prior self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PDE geometry (periodic vs non-periodic) determines whether local context-query geometry must be preserved for effective conditioning.
invented entities (1)
-
Neural Operator Processes (NOPs)
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Sibo Cheng, Che Liu, Yike Guo, and Rossella Arcucci
URL https://arxiv.org/ abs/2502.12902. Sibo Cheng, Che Liu, Yike Guo, and Rossella Arcucci. Efficient deep data assimilation with sparse observations and time-varying sensors.arXiv preprint arXiv:2310.16187,
-
[3]
URL https://arxiv.org/abs/2310.16187. Antoine Farchi et al. Neural incremental data assimilation.arXiv preprint arXiv:2406.15076,
-
[4]
Chelsea Finn, Pieter Abbeel, and Sergey Levine
URLhttps://arxiv.org/abs/2406.15076. Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1126–1135. PMLR,
-
[5]
Marta Garnelo, Dan Rosenbaum, Chris J
URL https://proceedings.mlr.press/v70/finn17a.html. Marta Garnelo, Dan Rosenbaum, Chris J. Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo J. Rezende, and S. M. Ali Eslami. Conditional neural processes. InProceedings of the 35th International Conference on Machine Learning, vol- ume 80 ofProceedings of Machine Learning Researc...
-
[7]
Hyunjik Kim, Andriy Mnih, Jonathan Schwarz, Marta Garnelo, S
URLhttps://arxiv.org/abs/2209.00517. Hyunjik Kim, Andriy Mnih, Jonathan Schwarz, Marta Garnelo, S. M. Ali Eslami, Dan Rosenbaum, Oriol Vinyals, and Yee Whye Teh. Attentive neural processes. InInternational Conference on Learning Representations,
-
[9]
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh
URL https://arxiv.org/ abs/2504.14416. Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set trans- former: A framework for attention-based permutation-invariant neural networks. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3744–3753. PMLR,
-
[10]
URL https://proceedings.mlr.press/ v97/lee19d.html. Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485,
Pith/arXiv arXiv 2003
-
[11]
URL https://arxiv.org/abs/2003. 03485. Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, An- drew M. Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial dif- ferential equations. InInternational Conference on Learning Representations,
2003
-
[12]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
doi: 10.1038/s42256-021-00302-5. Emilia Magnani, Nicholas Krämer, Runa Eschenhagen, Lorenzo Rosasco, and Philipp Hennig. Approximate bayesian neural operators: Uncertainty quantification for parametric pdes.arXiv preprint arXiv:2208.01565,
-
[13]
URLhttps://arxiv.org/abs/2208.01565. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, An- dreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala....
-
[15]
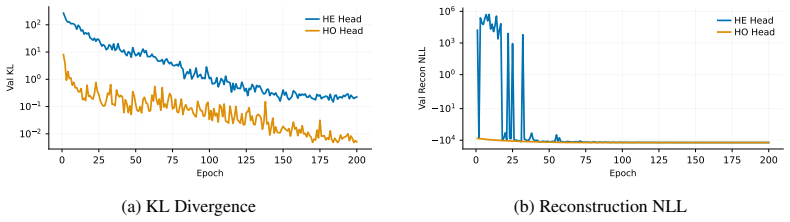
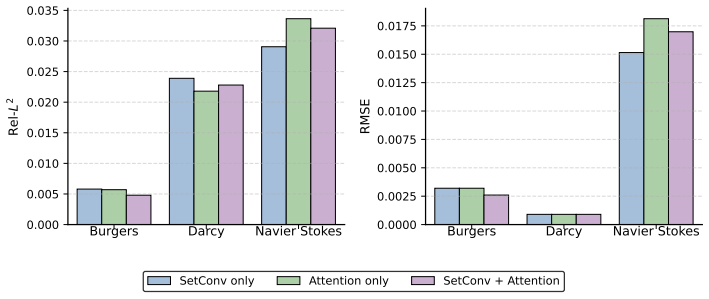
URL https://arxiv.org/abs/2301.12095. 11 A Overview of Extended Analysis and Ablations This appendix complements the main text with a broader set of diagnostics, robustness analyses, and practical profiling results. Its purpose is twofold: first, to clarify how the probabilistic latent mecha- nisms behave beyond the main summary tables; and second, to str...
arXiv 2019
-
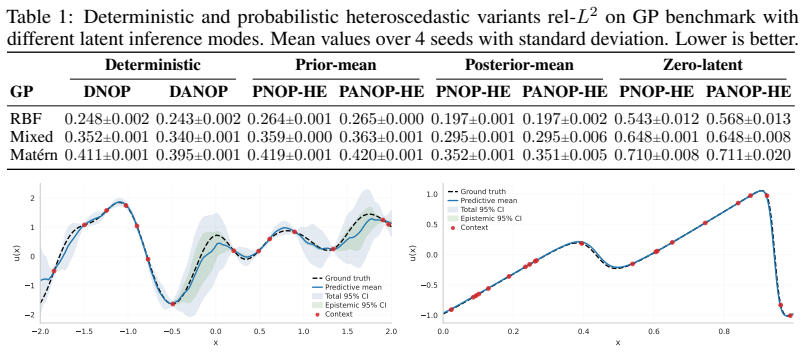
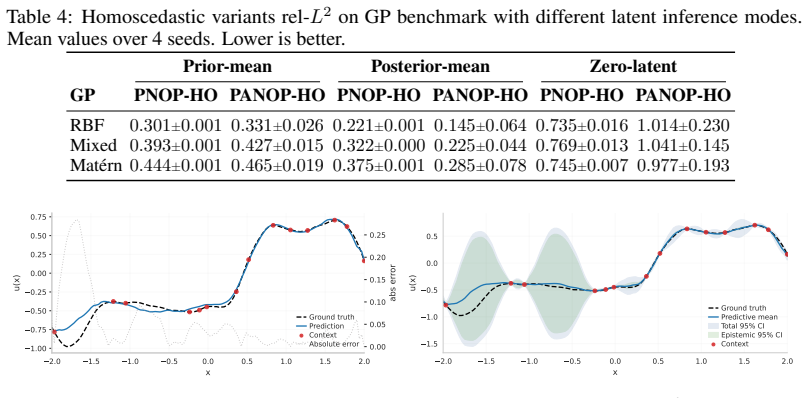
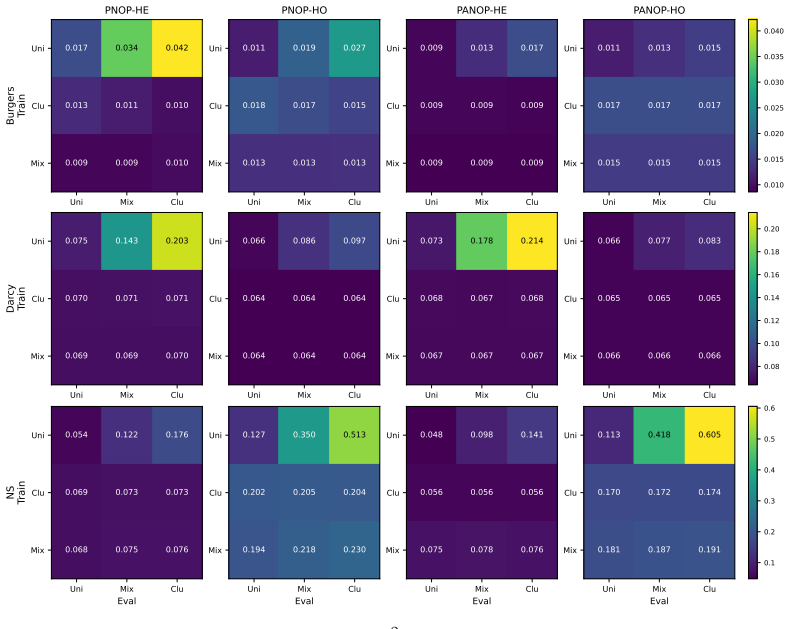
[16]
Posterior-mean evaluation is much stronger than zero-latent evaluation, confirming that the latent pathway is active, while prior-mean remains reasonably close to posterior-mean in the stable regimes. At the same time, PANOP-HO configuration exhibits a larger prior–posterior gap and substantially higher variability across seeds than the HE variants in Tab...
1913
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.