INCARBench: A Benchmark for Scientific Configuration in VASP INCAR by Large Language Models
Pith reviewed 2026-06-26 07:06 UTC · model grok-4.3
The pith
INCARBench shows that high semantic accuracy in LLM VASP configurations does not ensure scientific validity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
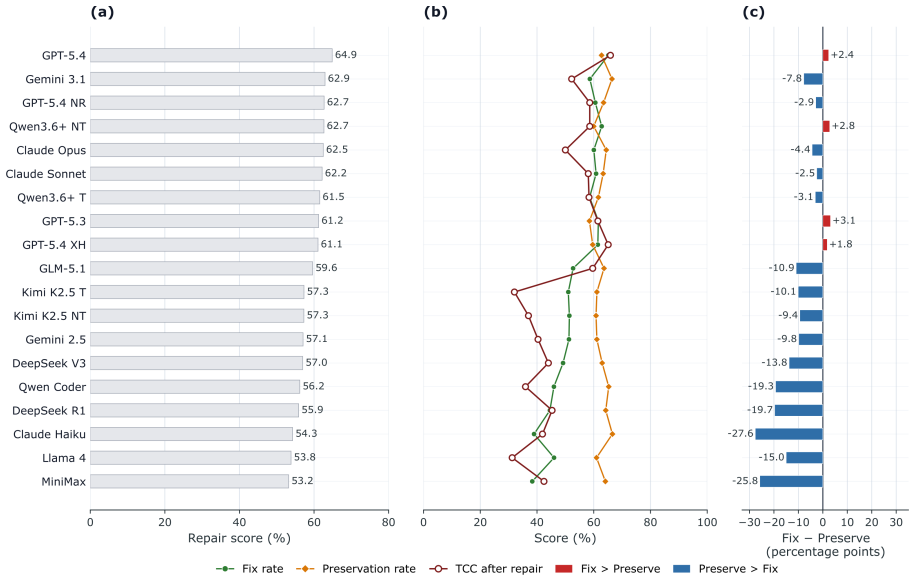
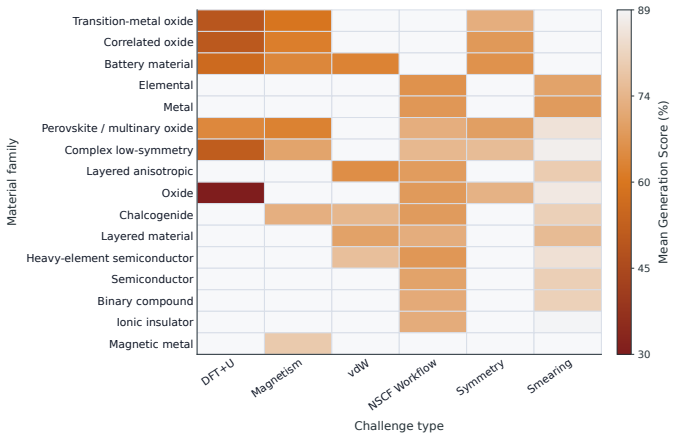
Current frontier LLMs can produce VASP INCAR files that satisfy semantic and policy checks yet still fail to meet the stricter standard of task-critical correctness required for scientifically valid simulations. Errors concentrate in settings where multiple physical constraints interact, such as DFT+U combined with magnetism in correlated materials. Repair tasks further separate the ability to correct errors from the ability to leave valid parameters untouched, with the latter remaining a persistent weakness.
What carries the argument
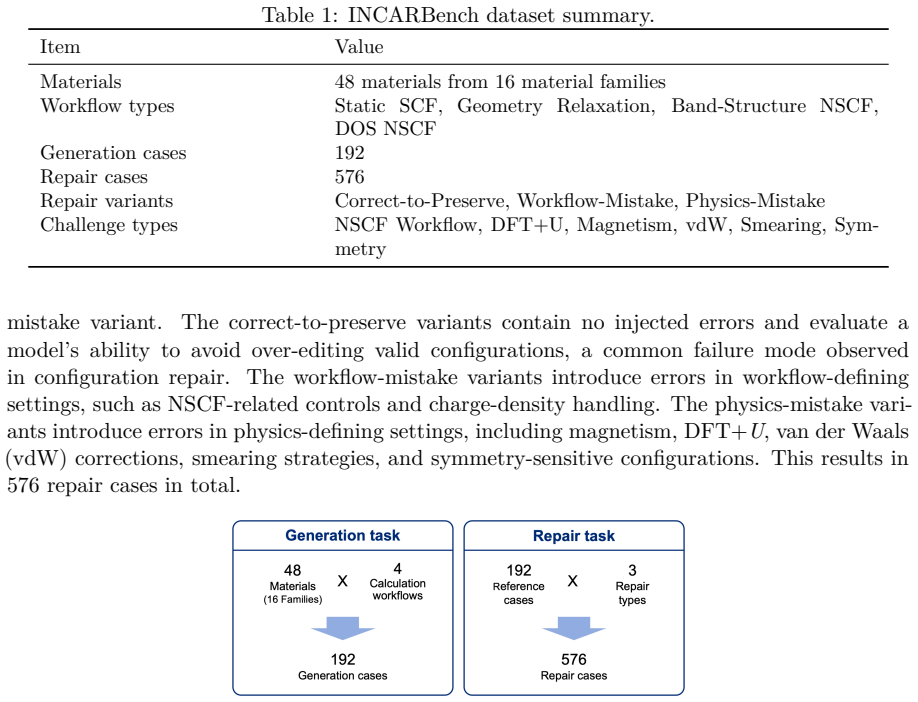
INCARBench benchmark consisting of configuration generation and repair tasks evaluated by semantic accuracy, policy accuracy, and task-critical correctness metrics.
If this is right
- Task-critical correctness is a stricter and distinct requirement from semantic or policy accuracy.
- Errors are concentrated in physically coupled parameter sets involving DFT+U, magnetism, and correlated materials.
- Correcting incorrect settings and preserving already-valid configurations are separate capabilities.
- Scientific configuration for computational materials science can be treated as a measurable LLM capability.
Where Pith is reading between the lines
- Models may require additional training signals that enforce simultaneous satisfaction of multiple physical constraints rather than isolated parameter rules.
- Extending the benchmark to full workflow validation, such as checking whether generated inputs produce stable convergence and expected physical properties, would test real-world utility.
- The gap between parameter-level correctness and scientific validity could be addressed by coupling LLMs with lightweight physics checkers during generation.
Load-bearing premise
The chosen generation and repair tasks plus the three accuracy metrics are enough to determine whether a configuration is scientifically valid in actual VASP workflows.
What would settle it
Run the same LLM-generated INCAR files through real VASP calculations on a set of DFT+U magnetic materials and compare outcomes against expert-validated reference results to check whether high benchmark scores predict correct physical outputs.
Figures


read the original abstract
Large language models (LLMs) are increasingly being integrated into first-principles computational workflows, yet their ability to configure scientific calculations remains poorly understood. Here, we introduce INCARBench, a benchmark for evaluating LLMs on input configuration for the Vienna Ab initio Simulation Package (VASP) through both configuration generation and repair tasks. Evaluating 19 model configurations reveals substantial capability differences among current frontier models. While several models achieve high semantic and policy accuracy, task-critical correctness remains substantially lower, demonstrating that parameter-level correctness does not necessarily imply scientifically valid configurations. Failure analysis shows that errors concentrate in physically coupled settings involving DFT+$U$, magnetism, and correlated materials, where multiple constraints must be satisfied simultaneously. Repair evaluation further reveals that correcting incorrect settings and preserving already-valid configurations are distinct capabilities, with configuration preservation remaining a major challenge. These findings establish scientific configuration as a measurable capability of large language models and provide a foundation for developing more reliable AI systems for computational materials science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces INCARBench, a benchmark for evaluating LLMs on VASP INCAR configuration generation and repair tasks. It assesses 19 model configurations using semantic accuracy, policy accuracy, and task-critical correctness metrics, reporting that high performance on the first two does not guarantee the third, with errors concentrating in physically coupled regimes (DFT+U, magnetism, correlated materials). Repair tasks further show that error correction and valid-configuration preservation are distinct skills, with the latter remaining challenging.
Significance. If the metrics prove robust and non-circular, the work is significant for establishing a measurable, domain-specific capability gap in LLMs for computational materials science workflows. It supplies a concrete benchmark with failure-mode analysis that can guide targeted improvements, and the separation of generation versus repair tasks plus the emphasis on coupled-parameter constraints represent a useful empirical contribution beyond generic LLM evaluations.
major comments (3)
- [Methods] Methods (task-critical correctness definition): The manuscript must explicitly document how the rules underlying task-critical correctness are constructed and whether they are derived independently of the policy guidelines used for policy accuracy. Without this, the central claim that parameter-level correctness does not imply scientific validity risks being partly definitional rather than an empirical demonstration of LLM shortcomings in coupled regimes.
- [Results] Results (failure analysis): The statement that errors concentrate in DFT+U, magnetism, and correlated materials lacks quantitative support such as the fraction of test cases involving these regimes, the per-regime error rates, or concrete examples of coupled constraints that were violated. This detail is load-bearing for the claim that failures are regime-specific rather than uniformly distributed.
- [Evaluation] Evaluation protocol: No mention is made of external grounding for task-critical correctness (e.g., expert physicist review of a sample of outputs or execution of generated INCAR files in VASP to check for runtime or convergence issues). This absence weakens the assertion that the metric captures scientific validity beyond internal checklist compliance.
minor comments (2)
- [Abstract] Abstract: Include the total number of test cases or INCAR instances used in the benchmark to give readers immediate scale context.
- Notation: Ensure consistent use of “task-critical correctness” versus any shorthand throughout; minor inconsistencies in abbreviation appear in the provided text.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed report. We address each major comment below, indicating planned revisions where appropriate. All changes will be incorporated in a revised manuscript.
read point-by-point responses
-
Referee: [Methods] Methods (task-critical correctness definition): The manuscript must explicitly document how the rules underlying task-critical correctness are constructed and whether they are derived independently of the policy guidelines used for policy accuracy. Without this, the central claim that parameter-level correctness does not imply scientific validity risks being partly definitional rather than an empirical demonstration of LLM shortcomings in coupled regimes.
Authors: We agree that explicit documentation is required. In the revised manuscript we will add a new subsection in Methods that details the construction of the task-critical correctness rules. These rules were assembled from the official VASP manual, peer-reviewed literature on DFT+U and magnetism, and independent input from two computational materials scientists; they were finalized before the policy-accuracy checklist was written and address physical consistency constraints (e.g., simultaneous satisfaction of ISPIN, MAGMOM, and LDAU parameters) that are orthogonal to the syntactic and formatting rules used for policy accuracy. This addition will make the empirical nature of the observed gap explicit. revision: yes
-
Referee: [Results] Results (failure analysis): The statement that errors concentrate in DFT+U, magnetism, and correlated materials lacks quantitative support such as the fraction of test cases involving these regimes, the per-regime error rates, or concrete examples of coupled constraints that were violated. This detail is load-bearing for the claim that failures are regime-specific rather than uniformly distributed.
Authors: We accept this criticism and will expand the failure-analysis section. The revision will report: (i) the exact fraction of the 1,200 test cases that involve DFT+U, magnetism, or correlated-electron settings; (ii) task-critical correctness error rates broken down by regime; and (iii) two to three concrete examples of simultaneously violated coupled constraints (e.g., incorrect MAGMOM sign together with missing LDAUL for a transition-metal oxide). These additions will supply the requested quantitative grounding. revision: yes
-
Referee: [Evaluation] Evaluation protocol: No mention is made of external grounding for task-critical correctness (e.g., expert physicist review of a sample of outputs or execution of generated INCAR files in VASP to check for runtime or convergence issues). This absence weakens the assertion that the metric captures scientific validity beyond internal checklist compliance.
Authors: We acknowledge that the current benchmark relies on rule-based internal validation rather than runtime VASP execution or post-hoc expert review of every output. Performing full DFT runs for thousands of generated INCAR files would have been computationally prohibitive within the scope of this study. In the revised manuscript we will add an explicit limitations paragraph stating this design choice and outlining how future work could incorporate sampled VASP executions or expert adjudication. We therefore treat the requested external grounding as a planned extension rather than a change to the present results. revision: partial
Circularity Check
No significant circularity; empirical benchmark evaluation
full rationale
This paper introduces INCARBench as an empirical benchmark for LLM performance on VASP INCAR configuration generation and repair tasks. It reports model accuracies on defined metrics (semantic accuracy, policy accuracy, task-critical correctness) and analyzes failure modes in physically coupled settings. No derivations, equations, fitted parameters, or self-citation chains are present that could reduce any claim to its inputs by construction. The evaluation relies on external model outputs and task definitions without internal reductions or load-bearing self-references. This is a standard self-contained benchmark study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ge Lei, Ronan Docherty, and Samuel J. Cooper. Materials science in the era of large language models: a perspective.Digital Discovery, 3:1257–1272, 2024. doi: 10.1039/ D4DD00074A
2024
-
[2]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chem- ical research with large language models.Nature, 624:570–578, 2023. doi: 10.1038/ s41586-023-06792-0
2023
-
[3]
Jaewoong Choi and Byungju Lee. Accelerating materials language processing with large language models.Communications Materials, 5:13, 2024. doi: 10.1038/s43246-024-00449-9
-
[4]
Andre Niyongabo Rubungo, Craig Arnold, Barry P. Rand, and Adji Bousso Dieng. Llm- prop: predicting the properties of crystalline materials using large language models.npj Computational Materials, 11:186, 2025. doi: 10.1038/s41524-025-01536-2
-
[5]
Nguyen, See-Kiong Ng, and Anh Tuan Luu
Huan Zhang, Yu Song, Ziyu Hou, Santiago Miret, and Bang Liu. HoneyComb: A flex- ible LLM-based agent system for materials science. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 3369–3382, 2024. doi: 10.18653/v1/2024. findings-emnlp.192
-
[6]
An agentic framework for autonomous materials computation.arXiv preprint arXiv:2512.19458, 2025
Mingyu Guo et al. An agentic framework for autonomous materials computation.arXiv preprint arXiv:2512.19458, 2025
arXiv 2025
-
[7]
Zijian Chen et al. VASPilot: MCP-facilitated multi-agent intelligence for autonomous VASP.arXiv preprint arXiv:2508.07035, 2025
arXiv 2025
-
[8]
G. Kresse and D. Joubert. From ultrasoft pseudopotentials to the projector augmented- wave method.Physical Review B, 59(3):1758–1775, 1999. doi: 10.1103/PhysRevB.59.1758
-
[9]
Georg Kresse and Jürgen Furthmüller. Efficiency of ab-initio total energy calculations for metals and semiconductors using a plane-wave basis set.Computational Materials Science, 6(1):15–50, 1996. doi: 10.1016/0927-0256(96)00008-0
-
[10]
Georg Kresse and Jürgen Furthmüller. Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set.Physical Review B, 54(16):11169–11186, 1996. doi: 10.1103/PhysRevB.54.11169
-
[11]
Incar – vasp wiki, 2025
VASP Development Team. Incar – vasp wiki, 2025. URLhttps://www.vasp.at/wiki/ index.php/INCAR. Accessed: 2026-06-02. 11
2025
-
[12]
D. Hobbs, G. Kresse, and J. Hafner. Fully unconstrained noncollinear magnetism within the projector augmented-wave method.Physical Review B, 62(17):11556–11570, 2000. doi: 10.1103/PhysRevB.62.11556
-
[13]
S. L. Dudarev, G. A. Botton, S. Y. Savrasov, C. J. Humphreys, and A. P. Sutton. Electron- energy-lossspectraandthestructuralstabilityofnickeloxide: AnLSDA+Ustudy.Physical Review B, 57(3):1505–1509, 1998. doi: 10.1103/PhysRevB.57.1505
-
[14]
A. I. Liechtenstein, V. I. Anisimov, and J. Zaanen. Density-functional theory and strong interactions: Orbital ordering in mott-hubbard insulators.Physical Review B, 52(8):R5467– R5470, 1995. doi: 10.1103/PhysRevB.52.R5467
-
[15]
Stefan Grimme, Jens Antony, Stephan Ehrlich, and Helge Krieg. A consistent and accurate ab initio parametrization of density functional dispersion correction (DFT-D) for the 94 elements H–Pu.The Journal of Chemical Physics, 132(15):154104, 2010. doi: 10.1063/1. 3382344
work page doi:10.1063/1 2010
-
[16]
M. Dion, H. Rydberg, E. Schröder, D. C. Langreth, and B. I. Lundqvist. Van der Waals density functional for general geometries.Physical Review Letters, 92(24):246401, 2004. doi: 10.1103/PhysRevLett.92.246401
-
[17]
Openai gpt-5 system card, 2025
OpenAI. Openai gpt-5 system card, 2025. URLhttps://arxiv.org/abs/2601.03267
Pith/arXiv arXiv 2025
-
[18]
Gemini 2.5 pro
Google DeepMind. Gemini 2.5 pro. Google AI for Developers model documentation, 2025. URLhttps://ai.google.dev/gemini-api/docs/models#gemini-2.5-pro
2025
-
[19]
Introducing claude 4, 2025
Anthropic. Introducing claude 4, 2025. URLhttps://www.anthropic.com/news/ claude-4
2025
-
[20]
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in large language models via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[21]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[22]
Minimax-m1: Scaling test-time compute efficiently with lightning attention
MiniMax. Minimax-m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585, 2025
Pith/arXiv arXiv 2025
-
[23]
Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Kimi Team and Moonshot AI. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Pith/arXiv arXiv 2026
-
[24]
Glm-5: From vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
GLM-5 Team, Jie Tang, et al. Glm-5: From vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
Pith/arXiv arXiv 2026
-
[25]
Junkai Zhang et al. MatSciBench: Benchmarking the reasoning ability of large language models in materials science.arXiv preprint arXiv:2510.12171, 2025
Pith/arXiv arXiv 2025
-
[26]
Jerry Junyang Cheung, Shiyao Shen, Yuchen Zhuang, Yinghao Li, Rampi Ramprasad, and Chao Zhang. Msqa: Benchmarking llms on graduate-level materials science reasoning and knowledge.arXiv preprint arXiv:2505.23982, 2025
arXiv 2025
-
[27]
Llm4mat-bench: Benchmarking large language models for materials property prediction
Andre Niyongabo Rubungo, Kangming Li, Jason Hattrick-Simpers, and Adji Bousso Dieng. Llm4mat-bench: Benchmarking large language models for materials property prediction. arXiv preprint arXiv:2411.00177, 2024
arXiv 2024
-
[28]
Mattools: Benchmarking large language models for materials science tools
Siyu Liu et al. Mattools: Benchmarking large language models for materials science tools. arXiv preprint arXiv:2505.10852, 2025. 12
arXiv 2025
-
[29]
LAMBench: a benchmark for large atomistic models.npj Computational Materials, 12:62,
Anyang Peng, Chun Cai, Mingyu Guo, Duo Zhang, Chengqian Zhang, Wanrun Jiang, Yinan Wang, Antoine Loew, Chengkun Wu, Weinan E, Linfeng Zhang, and Han Wang. LAMBench: a benchmark for large atomistic models.npj Computational Materials, 12:62,
-
[30]
doi: 10.1038/s41524-025-01929-3
-
[31]
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, and Kristin A. Persson. Commentary: The materials project: A materials genome ap- proach to accelerating materials innovation.APL Materials, 1(1):011002, 2013. doi: 10.1063/1.4812323
-
[32]
Matthew K. Horton, Patrick Huck, Ruo Xi Yang, Jason M. Munro, Shyam Dwaraknath, Alex M. Ganose, Ryan S. Kingsbury, Mingjian Wen, Jimmy X. Shen, Tyler S. Mathis, Aaron D. Kaplan, Karlo Berket, Janosh Riebesell, Janine George, Andrew S. Rosen, Evan W. C. Spotte-Smith, Matthew J. McDermott, Orion A. Cohen, Alex Dunn, Matthew C. Kuner, Gian-Marco Rignanese, G...
-
[33]
Computational Materials Science , volume =
Shyue Ping Ong, William Davidson Richards, Anubhav Jain, Geoffroy Hautier, Michael Kocher, Shreyas Cholia, Dan Gunter, Vincent L. Chevrier, Kristin A. Persson, and Ger- brand Ceder. Python materials genomics (pymatgen): A robust, open-source python li- brary for materials analysis.Computational Materials Science, 68:314–319, 2013. doi: 10.1016/j.commatsci...
-
[34]
Claude models overview
Anthropic. Claude models overview. Claude API documentation, 2026. URLhttps: //platform.claude.com/docs/en/about-claude/models/overview
2026
-
[35]
Introducing claude haiku 4.5, 2025
Anthropic. Introducing claude haiku 4.5, 2025. URLhttps://www.anthropic.com/news/ claude-haiku-4-5
2025
-
[36]
Gemini 3.1 pro
Google DeepMind. Gemini 3.1 pro. Google AI for Developers model documentation, 2026. URLhttps://ai.google.dev/gemini-api/docs/models#gemini-3.1-pro
2026
-
[37]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[38]
Qwen3-coder: Agentic coding in the world, 2025
Qwen Team. Qwen3-coder: Agentic coding in the world, 2025. URLhttps://qwenlm. github.io/blog/qwen3-coder/
2025
-
[39]
The minimax-m2 series: Mini activations unleashing max real-world intelligence
MiniMax. The minimax-m2 series: Mini activations unleashing max real-world intelligence. arXiv preprint arXiv:2605.26494, 2026
Pith/arXiv arXiv 2026
-
[40]
The llama 4 herd: The beginning of a new era of natively multimodal ai innova- tion, 2025
Meta AI. The llama 4 herd: The beginning of a new era of natively multimodal ai innova- tion, 2025. URLhttps://ai.meta.com/blog/llama-4-multimodal-intelligence/. 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.