Don't Go Breaking My LLM: The Impact of Pruning Attention Layers on Explanation Faithfulness and Confidence Calibration
Pith reviewed 2026-06-26 01:04 UTC · model grok-4.3
The pith
Pruning attention layers in LLMs often degrades explanation faithfulness and confidence calibration even when accuracy holds steady.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
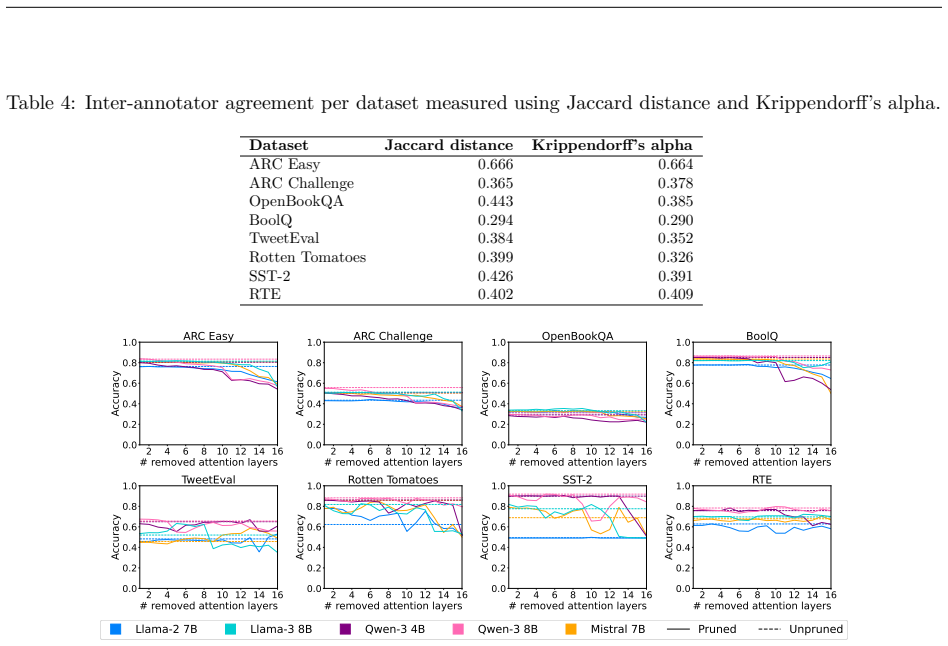
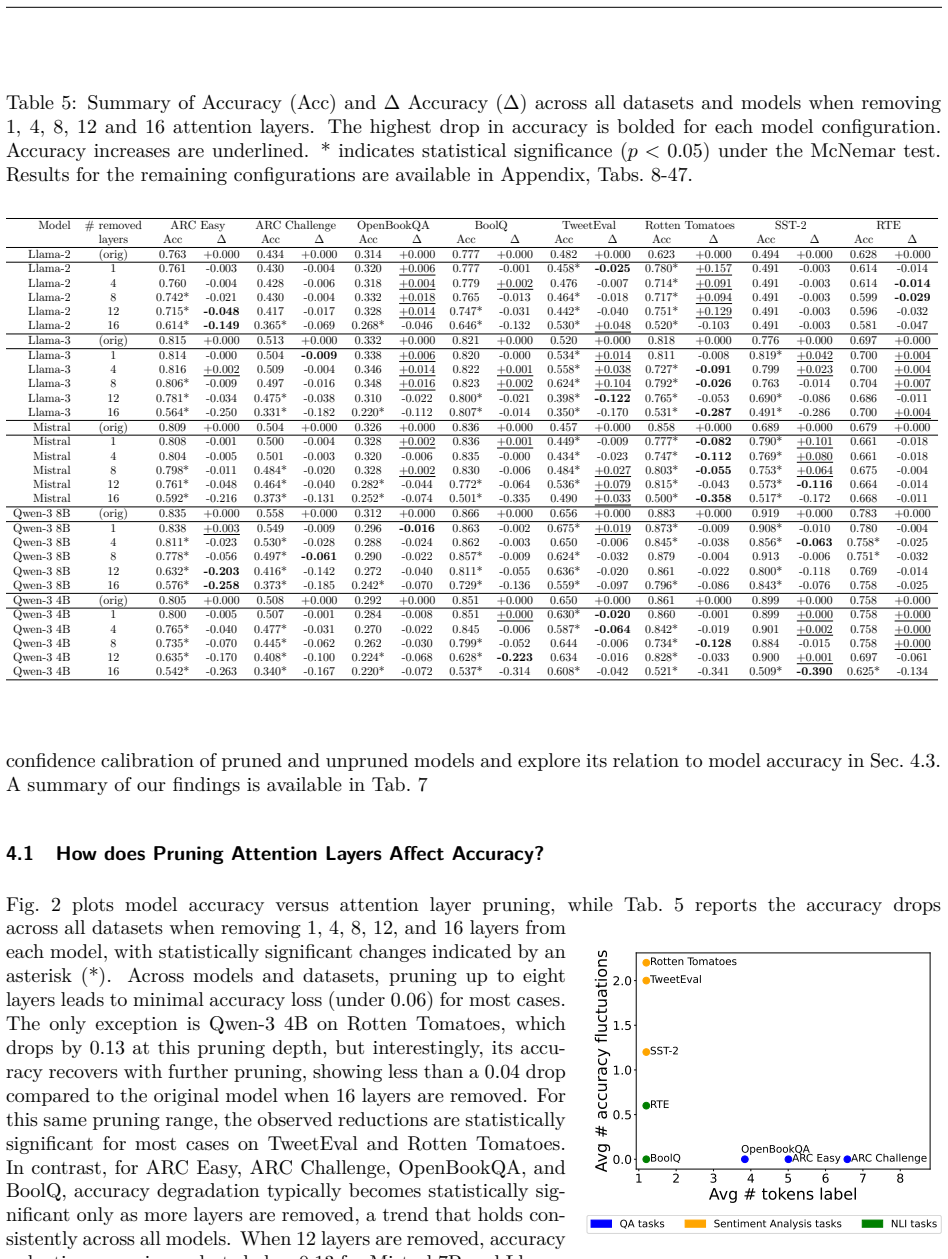
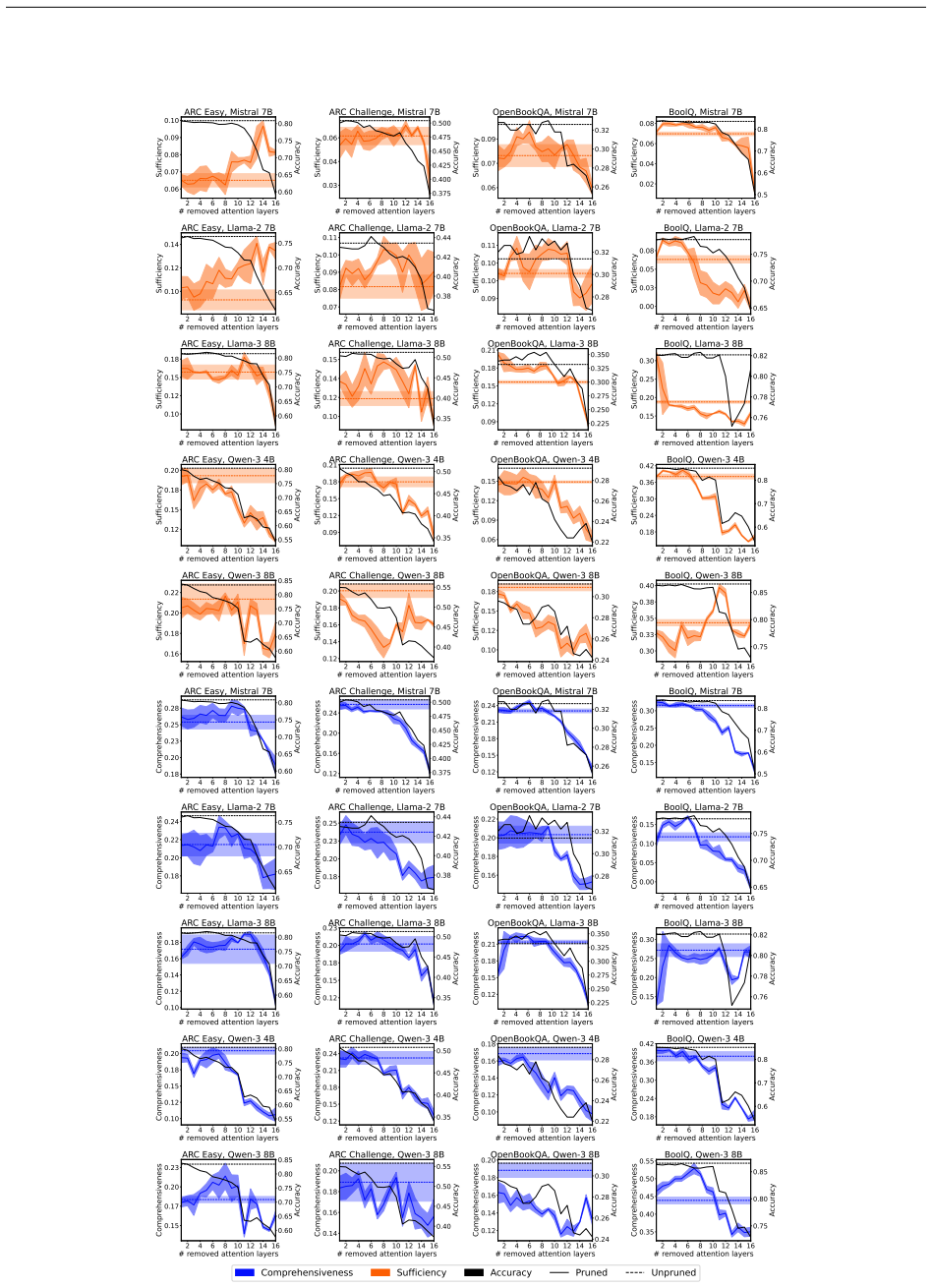
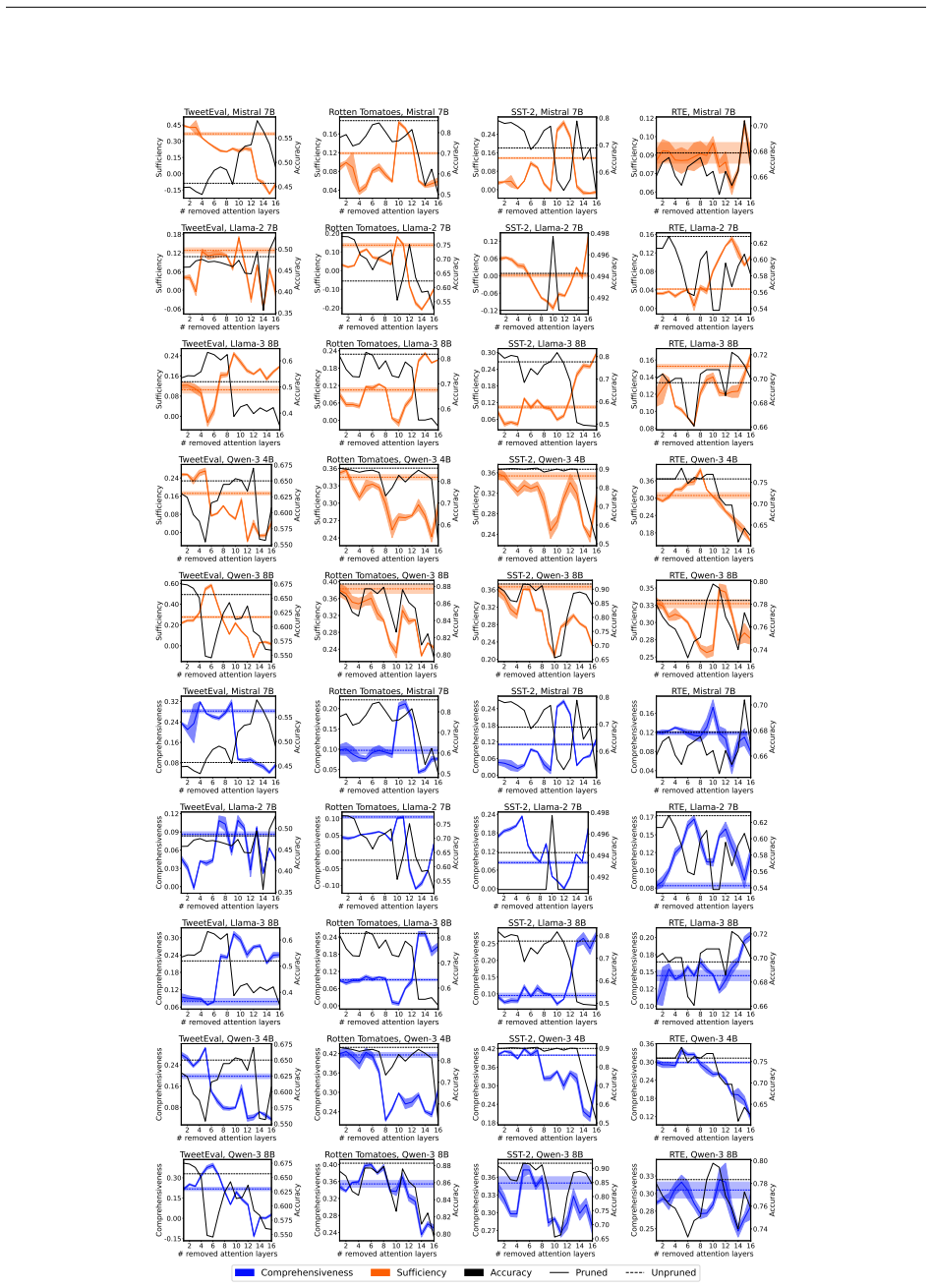
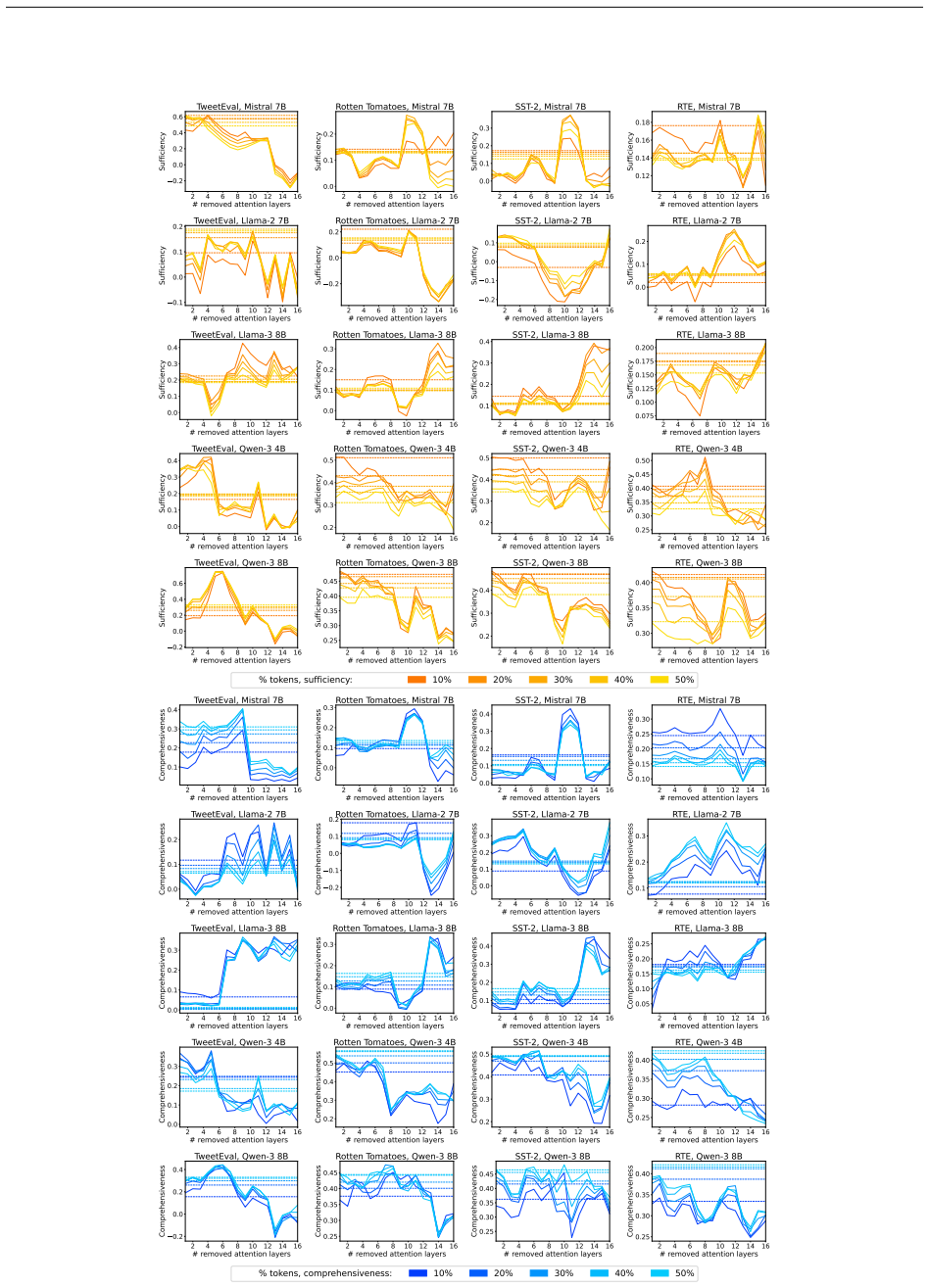
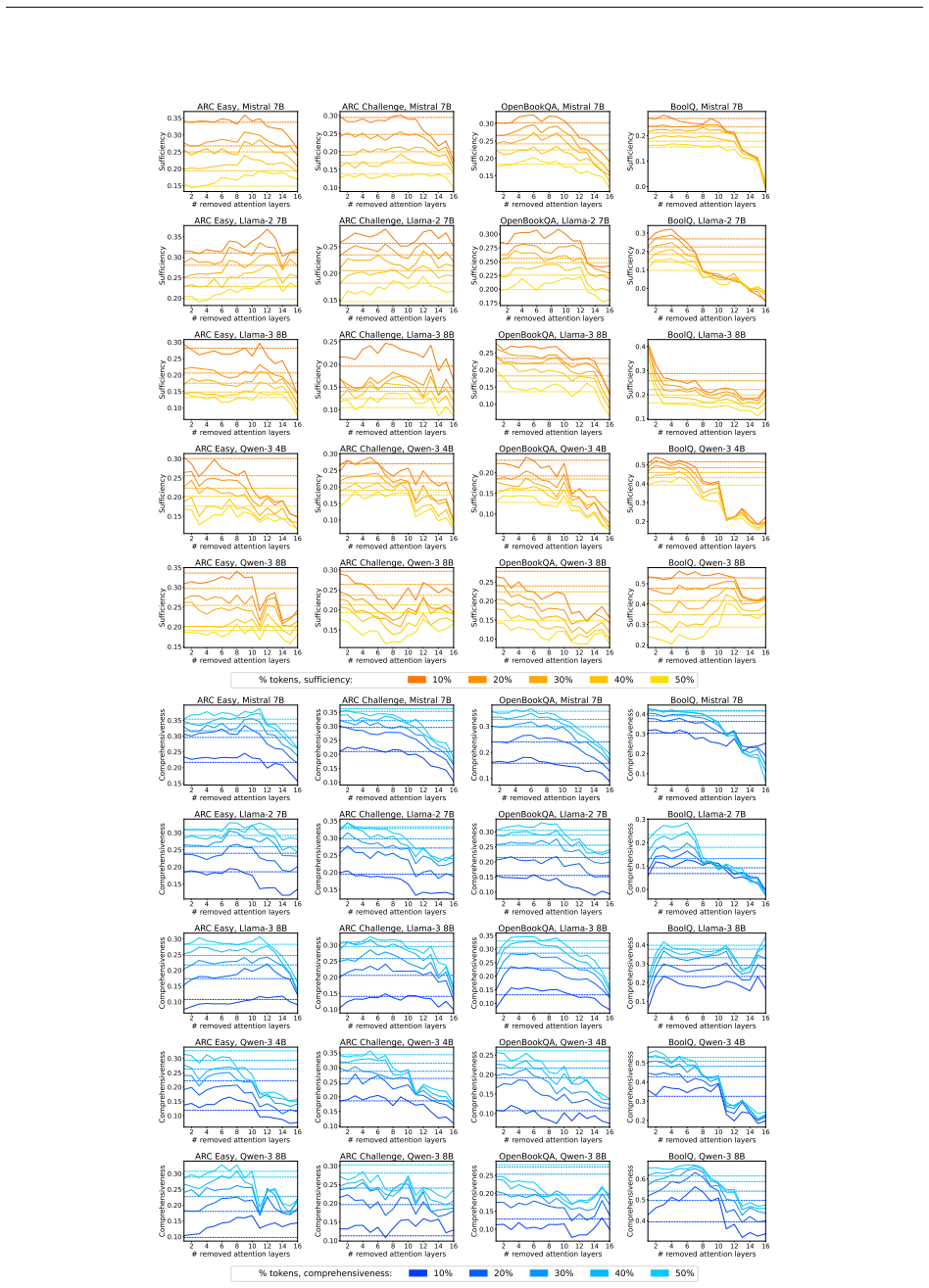
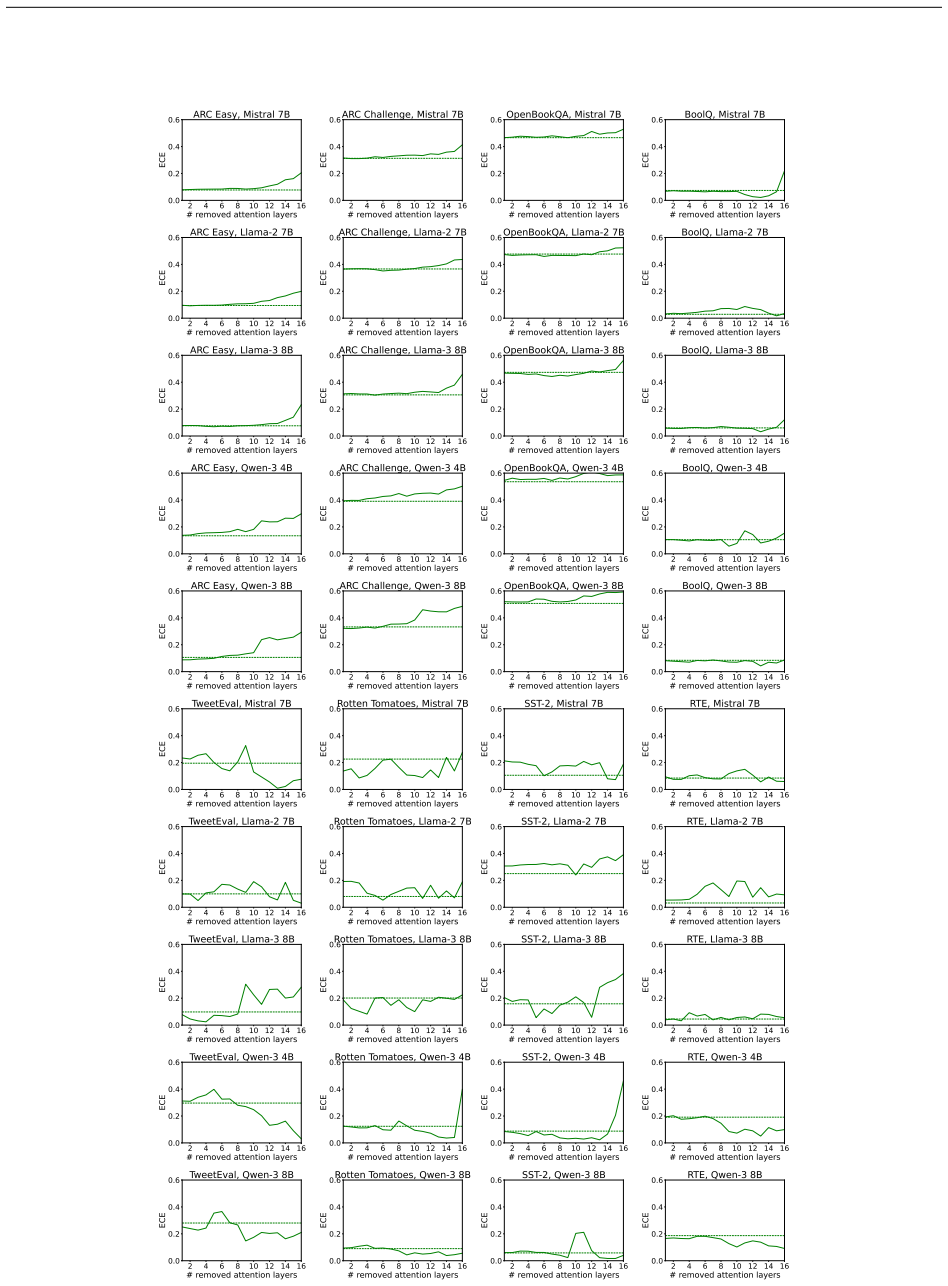
Removing up to one-third of the attention layers preserves most accuracy in the tested LLMs, but the faithfulness of explanations and the calibration of confidence scores frequently decline. These declines occur independently of accuracy changes and can vary substantially across pruning ratios, models, and datasets, revealing that accuracy and efficiency metrics alone do not capture the full impact on interpretability and reliability.
What carries the argument
The removal of attention layers from transformer-based LLMs, measured against faithfulness metrics for explanations and calibration metrics for confidence scores.
If this is right
- Pruned models may generate explanations that do not match their internal decision process.
- Confidence scores from pruned models may fail to indicate when predictions are likely to be wrong.
- Accuracy figures alone cannot be relied upon to certify the quality of a compressed LLM.
- Standard pruning evaluations should be expanded to include faithfulness and calibration checks.
- The misalignment between accuracy and the other properties can differ by model and by dataset.
Where Pith is reading between the lines
- Teams deploying pruned models in settings that require explanations may need additional post-pruning adjustments to restore faithfulness.
- The same independence of accuracy from calibration could appear under other compression techniques such as quantization or distillation.
- Safety evaluations for compressed LLMs should treat faithfulness and calibration as first-class requirements rather than optional add-ons.
Load-bearing premise
The observed effects depend on the assumption that the particular pruning strategy and the chosen faithfulness and calibration metrics are suitable and representative for the models and tasks examined.
What would settle it
An experiment showing that faithfulness and calibration scores remain stable or improve after the same attention-layer pruning on the same models and datasets would falsify the central claim.
Figures


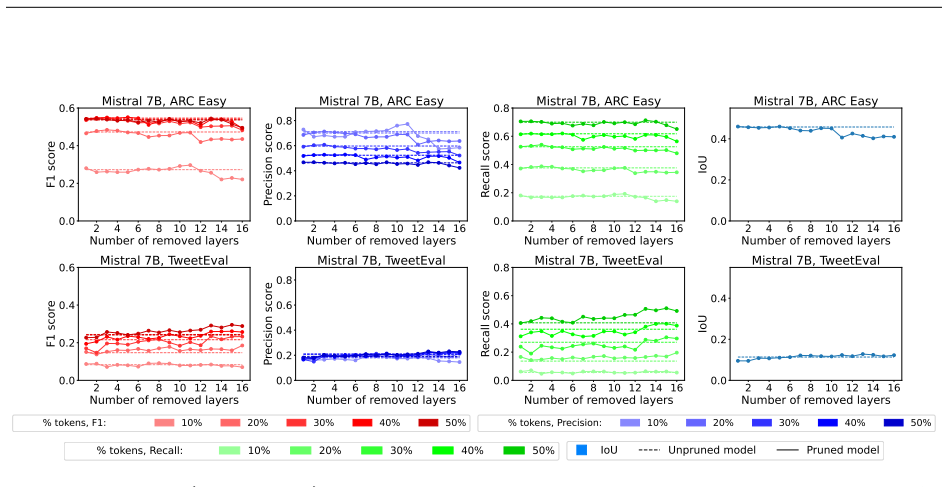
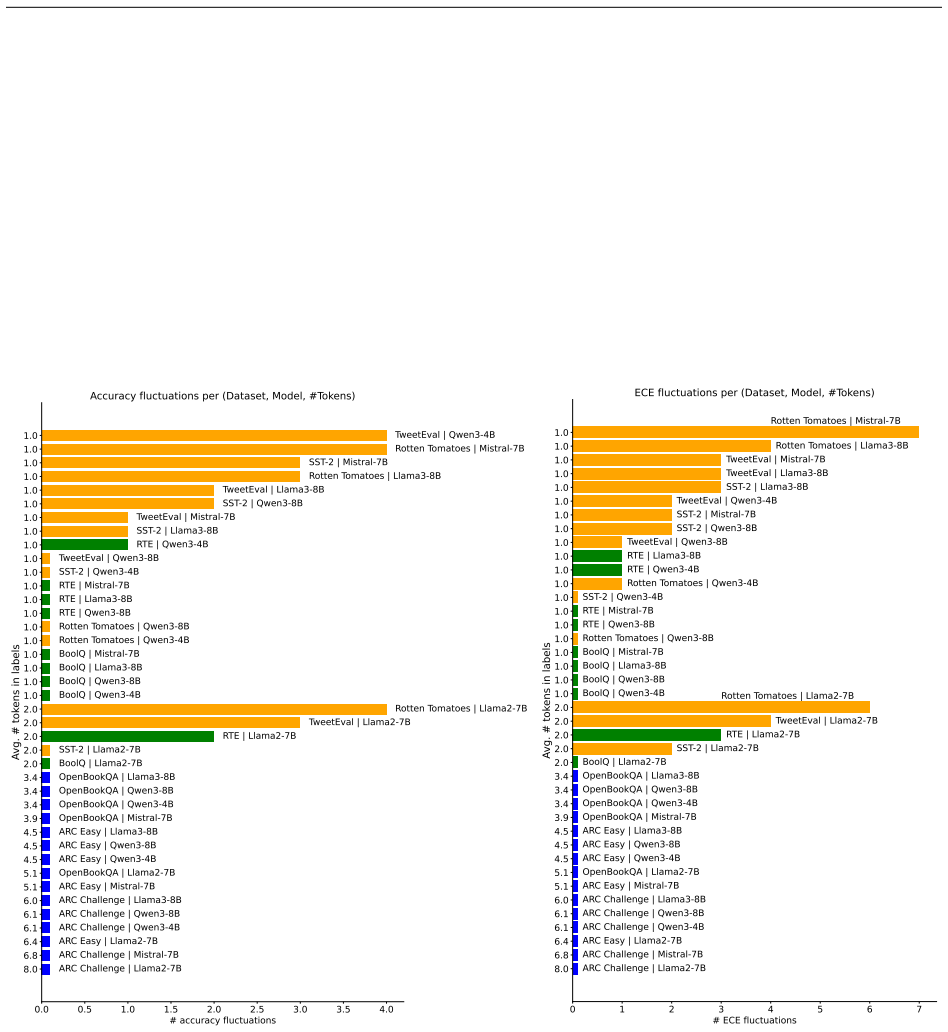
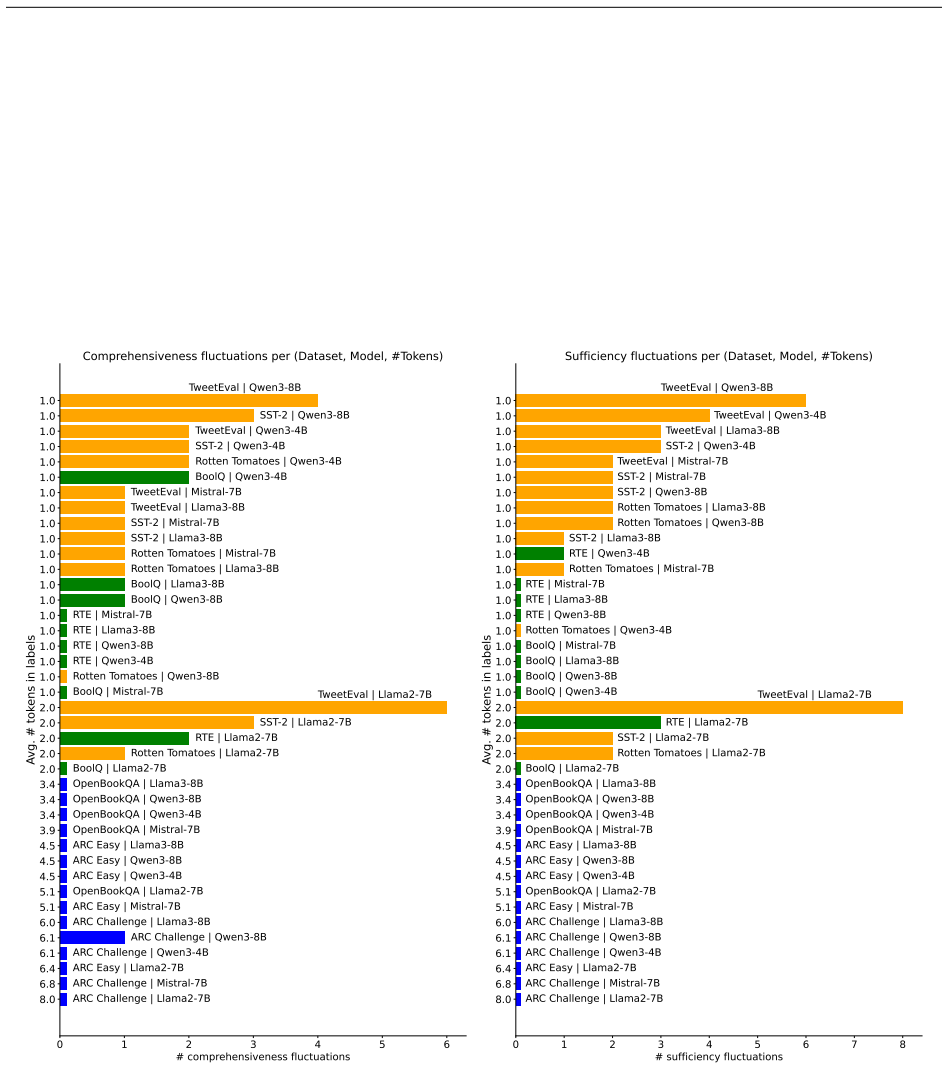
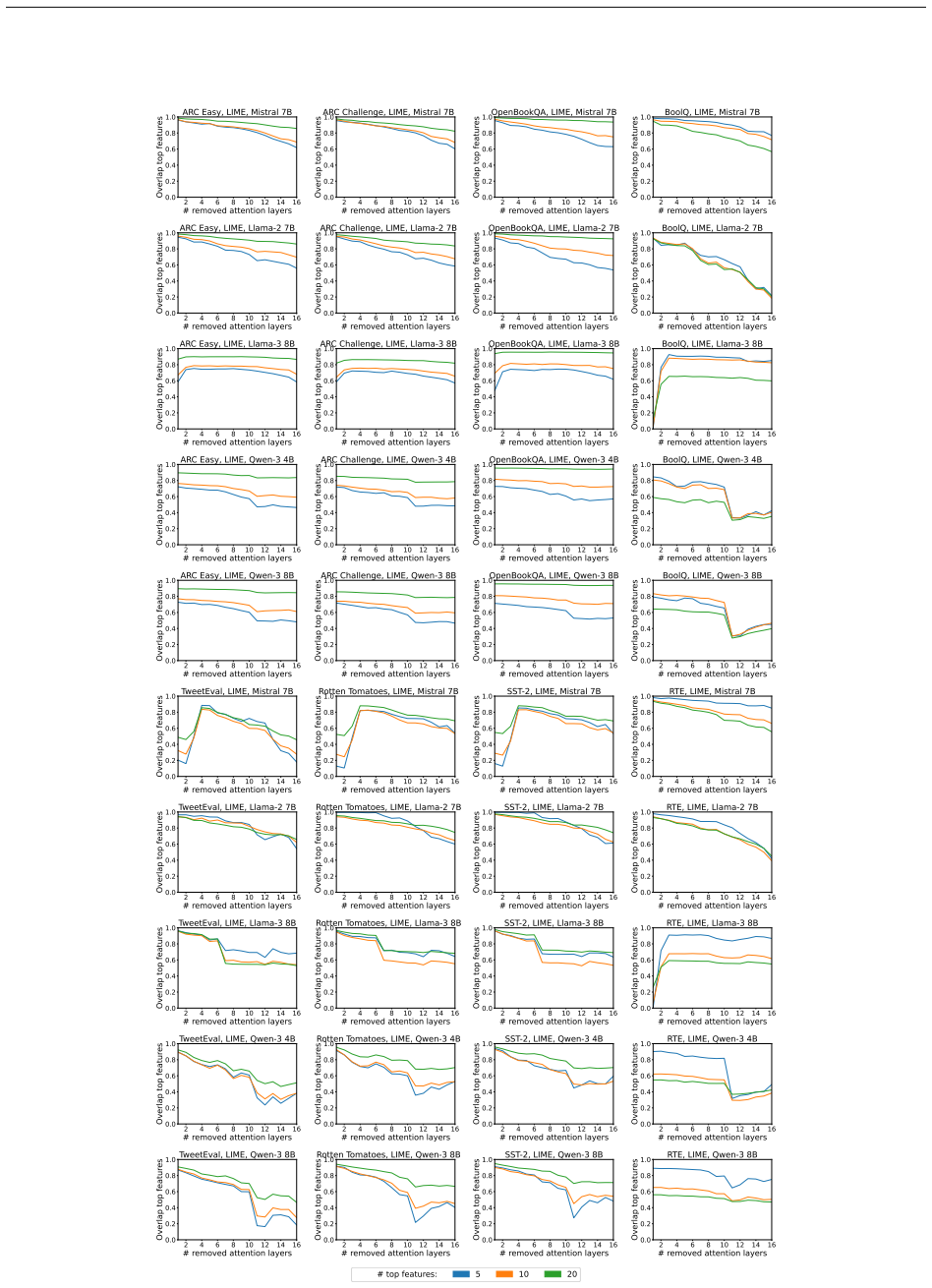




















read the original abstract
Pruning Large Language Models (LLMs) reduces memory and inference costs by removing parts of the network, producing smaller models that retain most of their accuracy. As attention layers are the most resource-intensive parts of LLMs, pruning them is a promising compression strategy. Prior work shows that up to 33% of attention layers can be pruned with minimal accuracy loss. Nevertheless, the impact of attention pruning on model interpretability, specifically faithfulness and confidence calibration, remains unstudied. To address this gap, we study how pruning attention layers affects explanation faithfulness and confidence calibration across five LLMs and eight datasets. While the pruned models often maintain high accuracy, we find that their faithfulness and calibration often degrade. Notably, faithfulness and calibration can fluctuate significantly, even when accuracy remains stable, highlighting a misalignment between model confidence, interpretability, and accuracy. Our findings suggest that layer pruning can affect LLMs' interpretability and reliability in ways not captured by accuracy and efficiency measures alone. We recommend including explainability and calibration metrics when evaluating pruned models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical investigation into the effects of pruning attention layers (up to 33%) in five LLMs across eight datasets. It reports that pruned models frequently preserve high accuracy but exhibit degraded or fluctuating explanation faithfulness and confidence calibration, indicating a misalignment between accuracy, interpretability, and reliability. The authors conclude that evaluation of pruned LLMs should incorporate faithfulness and calibration metrics beyond accuracy and efficiency.
Significance. If the empirical findings are robust, the work is significant for highlighting that model compression via attention pruning can decouple accuracy from explanation quality and calibration in ways not captured by standard metrics. This could influence evaluation practices in LLM compression research by emphasizing the need for multi-faceted assessments of pruned models.
major comments (2)
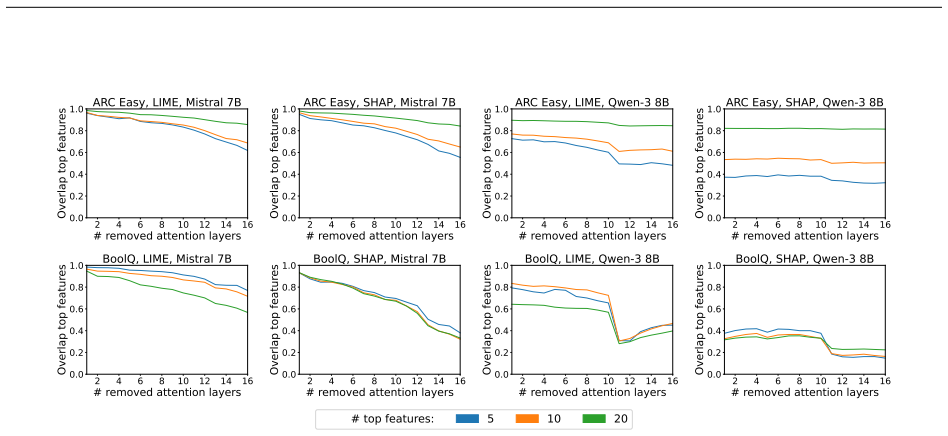
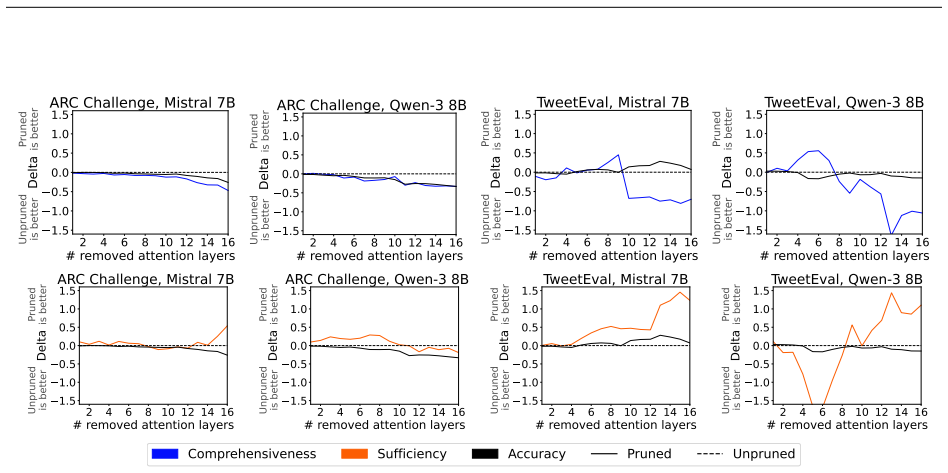
- [§3 and §4] §3 (Experimental Setup) and §4 (Results): The faithfulness metrics are applied directly to pruned models without reported validation for invariance to attention-layer removal. Since many standard faithfulness metrics (sufficiency, comprehensiveness, or attention-weight based) depend on the very components removed by pruning, the observed degradations may be artifacts of metric sensitivity rather than substantive changes in explanation quality; this directly undermines the central claim of misalignment.
- [§4.2] §4.2 (Faithfulness and Calibration Results): The reported fluctuations in faithfulness/calibration while accuracy remains stable lack accompanying statistical controls (e.g., significance testing across the 5×8 model-dataset combinations or ablation on pruning ratios), making it unclear whether the fluctuations exceed noise or multiple-comparison artifacts.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit definitions or citations for the specific faithfulness and calibration metrics employed, even if expanded in the methods.
- [Tables in §4] Tables reporting per-model/per-dataset results should include error bars or variance measures to support claims of 'significant fluctuation'.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps improve the robustness of our empirical analysis. We address each major comment below.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Experimental Setup) and §4 (Results): The faithfulness metrics are applied directly to pruned models without reported validation for invariance to attention-layer removal. Since many standard faithfulness metrics (sufficiency, comprehensiveness, or attention-weight based) depend on the very components removed by pruning, the observed degradations may be artifacts of metric sensitivity rather than substantive changes in explanation quality; this directly undermines the central claim of misalignment.
Authors: We appreciate this concern about potential metric sensitivity. Our primary faithfulness metrics are perturbation-based (sufficiency and comprehensiveness), which evaluate explanation quality via input feature removal and are independent of internal attention layers; thus they remain valid post-pruning. Any attention-weight metrics are secondary. To further address the point, we will add a validation subsection in the revised §3 showing that these metrics yield stable rankings on a subset of pruned vs. original models, confirming the degradations are not artifacts. revision: yes
-
Referee: [§4.2] §4.2 (Faithfulness and Calibration Results): The reported fluctuations in faithfulness/calibration while accuracy remains stable lack accompanying statistical controls (e.g., significance testing across the 5×8 model-dataset combinations or ablation on pruning ratios), making it unclear whether the fluctuations exceed noise or multiple-comparison artifacts.
Authors: We agree that additional statistical controls would strengthen the results. In the revision we will add paired significance tests (e.g., Wilcoxon signed-rank) across all 5×8 combinations, report p-values with multiple-comparison correction, and include an ablation table for pruning ratios (10%, 20%, 33%) with error bars to demonstrate that observed fluctuations exceed noise levels. revision: yes
Circularity Check
Empirical study reports observations with no derivation chain
full rationale
The paper is an empirical investigation that measures the effects of attention-layer pruning on accuracy, faithfulness, and calibration across LLMs and datasets. It states prior results via citation and reports direct experimental outcomes without equations, fitted parameters renamed as predictions, self-definitional constructs, or any load-bearing self-citation chains. No derivation is claimed or present, so the findings rest on external measurements rather than internal reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine learning evaluation practices apply to the faithfulness and calibration metrics used.
Reference graph
Works this paper leans on
-
[1]
Slicegpt: Compress large language models by deleting rows and columns
Saleh Ashkboos, Maximilian Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. Slicegpt: Compress large language models by deleting rows and columns. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.), International Conference on Learning Representations, volume 2024, pp.\ 11682--11701, 2024. URL https://proc...
2024
-
[2]
Bach, Victor Sanh, Zheng-Xin Yong, Albert Webson, Colin Raffel, Nihal V
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong, Albert Webson, Colin Raffel, Nihal V. Nayak, Abheesht Sharma, Taewoon Kim, M Saiful Bari, Thibault Fevry, Zaid Alyafeai, Manan Dey, Andrea Santilli, Zhiqing Sun, Srulik Ben-David, Canwen Xu, Gunjan Chhablani, Han Wang, Jason Alan Fries, Maged S. Al-shaibani, Shanya Sharma, Urmish Thakker, Khalid Almubarak, Xia...
-
[3]
T weet E val: Unified Benchmark and Comparative Evaluation for Tweet Classification
Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa Anke, and Leonardo Neves. T weet E val: Unified benchmark and comparative evaluation for tweet classification. In Trevor Cohn, Yulan He, and Yang Liu (eds.), Findings of the Association for Computational Linguistics: EMNLP 2020, pp.\ 1644--1650, Online, November 2020. Association for Computational L...
-
[4]
The disagreement problem in faithfulness metrics
Brian Barr, Noah Fatsi, Leif Hancox-Li, Peter Richter, and Daniel Proano. The disagreement problem in faithfulness metrics. In XAI in Action: Past, Present, and Future Applications, 2023. URL https://openreview.net/forum?id=KPtW2SU0my
2023
-
[5]
The fifth pascal recognizing textual entailment challenge
Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. The fifth pascal recognizing textual entailment challenge. TAC, 7 0 (8): 0 1, 2009. URL https://hdl.handle.net/11582/5351
2009
-
[6]
A comparative study of faithfulness metrics for model interpretability methods
Chun Sik Chan, Huanqi Kong, and Liang Guanqing. A comparative study of faithfulness metrics for model interpretability methods. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5029--5038, Dublin, Ireland, May 2022. Asso...
-
[7]
Investigating hallucinations in pruned large language models for abstractive summarization
George Chrysostomou, Zhixue Zhao, Miles Williams, and Nikolaos Aletras. Investigating hallucinations in pruned large language models for abstractive summarization. Transactions of the Association for Computational Linguistics, 12: 0 1163--1181, 2024. doi:10.1162/tacl_a_00695. URL https://aclanthology.org/2024.tacl-1.64/
-
[8]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. B ool Q : Exploring the surprising difficulty of natural yes/no questions. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: H...
-
[9]
Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URL https://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[10]
The pascal recognising textual entailment challenge
Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Joaquin Qui \ n onero-Candela, Ido Dagan, Bernardo Magnini, and Florence d'Alch \'e Buc (eds.), Machine Learning Challenges. Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Tectual Entailment, pp.\ 177--190, Berlin, Heid...
-
[11]
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C. Wallace. ERASER : A benchmark to evaluate rationalized NLP models. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 4443--4458, Onl...
-
[12]
An unsupervised approach to achieve supervised-level explainability in healthcare records
Joakim Edin, Maria Maistro, Lars Maal e, Lasse Borgholt, Jakob Drachmann Havtorn, and Tuukka Ruotsalo. An unsupervised approach to achieve supervised-level explainability in healthcare records. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 4869--489...
-
[13]
S parse GPT : Massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. S parse GPT : Massive language models can be accurately pruned in one-shot. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 1032...
2023
-
[14]
Pruning weights but not truth: Safeguarding truthfulness while pruning LLM s
Yao Fu, Runchao Li, Xianxuan Long, Haotian Yu, Xiaotian Han, Yu Yin, and Pan Li. Pruning weights but not truth: Safeguarding truthfulness while pruning LLM s. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 20750--20768, Suzhou, China, Nov...
-
[15]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
arXiv 2024
-
[16]
The third PASCAL recognizing textual entailment challenge
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. The third PASCAL recognizing textual entailment challenge. In Satoshi Sekine, Kentaro Inui, Ido Dagan, Bill Dolan, Danilo Giampiccolo, and Bernardo Magnini (eds.), Proceedings of the ACL - PASCAL Workshop on Textual Entailment and Paraphrasing , pp.\ 1--9, Prague, June 2007. Association for ...
2007
-
[17]
Compressed but compromised? a study of jailbreaking in compressed LLM s
Satya Sai Srinath Namburi GNVV, Alex James Boyd, and Andrew Warrington. Compressed but compromised? a study of jailbreaking in compressed LLM s. In Lock-LLM Workshop: Prevent Unauthorized Knowledge Use from Large Language Models, 2025. URL https://openreview.net/forum?id=OkNfb8SmLh
2025
-
[18]
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A. Roberts. The unreasonable ineffectiveness of the deeper layers. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (eds.), International Conference on Learning Representations, volume 2025, pp.\ 81906--81920, 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/file/cbabc...
2025
-
[19]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Doina Precup and Yee Whye Teh (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp.\ 1321--1330. PMLR, 06--11 Aug 2017. URL https://proceedings.mlr.press/v70/guo17a.html
2017
-
[20]
The second pascal recognising textual entailment challenge
R Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. The second pascal recognising textual entailment challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment, volume 7, pp.\ 785--794, 2006
2006
-
[21]
Pruning for protection: Increasing jailbreak resistance in aligned LLM s without fine-tuning
Adib Hasan, Ileana Rugina, and Alex Wang. Pruning for protection: Increasing jailbreak resistance in aligned LLM s without fine-tuning. In Yonatan Belinkov, Najoung Kim, Jaap Jumelet, Hosein Mohebbi, Aaron Mueller, and Hanjie Chen (eds.), Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp.\ 417--430, Miami,...
-
[22]
Does BERT learn as humans perceive? understanding linguistic styles through lexica
Shirley Anugrah Hayati, Dongyeop Kang, and Lyle Ungar. Does BERT learn as humans perceive? understanding linguistic styles through lexica. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 6323--6331, Online and Punta Cana, Domin...
-
[23]
Uncovering the redundancy in transformers via a unified study of layer dropping
Shwai He, Guoheng Sun, Zheyu Shen, and Ang Li. Uncovering the redundancy in transformers via a unified study of layer dropping. Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URL https://openreview.net/forum?id=1I7PCbOPfe
2026
-
[24]
Aligning \ ai \ with shared human values
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning \ ai \ with shared human values. In International Conference on Learning Representations, 2021 a . URL https://openreview.net/forum?id=dNy_RKzJacY
2021
-
[25]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021 b . URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[26]
Characterising bias in compressed models, 2020
Sara Hooker, Nyalleng Moorosi, Gregory Clark, Samy Bengio, and Emily Denton. Characterising bias in compressed models, 2020. URL https://arxiv.org/abs/2010.03058
arXiv 2020
-
[27]
Fasp: Fast and accurate structured pruning of large language models, 2025
Hanyu Hu, Pengxiang Zhao, Ping Li, Yi Zheng, Zhefeng Wang, and Xiaoming Yuan. Fasp: Fast and accurate structured pruning of large language models, 2025. URL https://arxiv.org/abs/2501.09412
arXiv 2025
-
[28]
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness? In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 4198--4205, Online, July 2020. Association for Computational Lin...
-
[29]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
Pith/arXiv arXiv 2023
-
[30]
The cost of down-scaling language models: Fact recall deteriorates before in-context learning, 2023
Tian Jin, Nolan Clement, Xin Dong, Vaishnavh Nagarajan, Michael Carbin, Jonathan Ragan-Kelley, and Gintare Karolina Dziugaite. The cost of down-scaling language models: Fact recall deteriorates before in-context learning, 2023. URL https://arxiv.org/abs/2310.04680
Pith/arXiv arXiv 2023
-
[31]
Logic traps in evaluating attribution scores
Yiming Ju, Yuanzhe Zhang, Zhao Yang, Zhongtao Jiang, Kang Liu, and Jun Zhao. Logic traps in evaluating attribution scores. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5911--5922, Dublin, Ireland, May 2022. Associati...
-
[32]
Shortened llama: Depth pruning for large language models with comparison of retraining methods, 2024
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, and Hyoung-Kyu Song. Shortened llama: Depth pruning for large language models with comparison of retraining methods, 2024. URL https://arxiv.org/abs/2402.02834
arXiv 2024
-
[33]
The impact of inference acceleration on bias of LLM s
Elisabeth Kirsten, Ivan Habernal, Vedant Nanda, and Muhammad Bilal Zafar. The impact of inference acceleration on bias of LLM s. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), ...
2025
-
[34]
Pruning filters for efficient convnets
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=rJqFGTslg
2017
-
[35]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017
2017
-
[36]
Towards faithful model explanation in NLP : A survey
Qing Lyu, Marianna Apidianaki, and Chris Callison-Burch. Towards faithful model explanation in NLP : A survey. Computational Linguistics, 50 0 (2): 0 657--723, June 2024. doi:10.1162/coli_a_00511. URL https://aclanthology.org/2024.cl-2.6/
-
[37]
Llm-pruner: On the structural pruning of large language models
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp.\ 21702--21720. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/f...
arXiv 2023
-
[38]
Shortgpt: Layers in large language models are more redundant than you expect, 2024
Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect, 2024. URL https://arxiv.org/abs/2403.03853
arXiv 2024
-
[39]
Are sixteen heads really better than one? In H
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one? In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alch\' e -Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/2c601ad9d2ff9bc8b28...
2019
-
[40]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun ' ichi Tsujii (eds.), Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.\ 2381--2391, Brussels, Belgium, ...
-
[41]
Mahdi Pakdaman Naeini, Gregory F. Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI'15, pp.\ 2901–2907. AAAI Press, 2015. ISBN 0262511290. URL https://doi.org/10.1609/aaai.v29i1.9602
-
[42]
Bo Pang and Lillian Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Kevin Knight, Hwee Tou Ng, and Kemal Oflazer (eds.), Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics ( ACL ' 05) , pp.\ 115--124, Ann Arbor, Michigan, June 2005. Association for Comput...
-
[43]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21 0 (140): 0 1--67, 2020. URL http://jmlr.org/papers/v21/20-074.html
2020
-
[44]
A comparative study on the impact of model compression techniques on fairness in language models
Krithika Ramesh, Arnav Chavan, Shrey Pandit, and Sunayana Sitaram. A comparative study on the impact of model compression techniques on fairness in language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 15762--1578...
-
[45]
Marco Ribeiro, Sameer Singh, and Carlos Guestrin. why should I trust you? : Explaining the predictions of any classifier. In John DeNero, Mark Finlayson, and Sravana Reddy (eds.), Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Demonstrations , pp.\ 97--101, San Diego, California, June 20...
-
[46]
S em E val-2017 task 4: Sentiment analysis in T witter
Sara Rosenthal, Noura Farra, and Preslav Nakov. S em E val-2017 task 4: Sentiment analysis in T witter. In Steven Bethard, Marine Carpuat, Marianna Apidianaki, Saif M. Mohammad, Daniel Cer, and David Jurgens (eds.), Proceedings of the 11th International Workshop on Semantic Evaluation ( S em E val-2017) , pp.\ 502--518, Vancouver, Canada, August 2017. Ass...
-
[47]
Sofia Serrano and Noah A. Smith. Is attention interpretable? In Anna Korhonen, David Traum, and Llu \'i s M \`a rquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp.\ 2931--2951, Florence, Italy, July 2019. Association for Computational Linguistics. doi:10.18653/v1/P19-1282. URL https://aclanthology.org...
-
[48]
Who reasons in the large language models? In D
Jie Shao and Jianxin Wu. Who reasons in the large language models? In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen (eds.), Advances in Neural Information Processing Systems, volume 38, pp.\ 113087--113108. Curran Associates, Inc., 2025. URL https://proceedings.neurips.cc/paper_files/paper/2025/file/a40462acc6959034c6aa6d...
2025
-
[49]
A deeper look at depth pruning of LLM s
Shoaib Ahmed Siddiqui, Xin Dong, Greg Heinrich, Thomas Breuel, Jan Kautz, David Krueger, and Pavlo Molchanov. A deeper look at depth pruning of LLM s. In ICML 2024 Workshop on Theoretical Foundations of Foundation Models, 2024. URL https://openreview.net/forum?id=9B7ayWclwN
2024
-
[50]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard (eds.), Proceedings of the 2013 Conference on Empirical Methods in Natural Langu...
2013
-
[51]
SLEB : Streamlining LLM s through redundancy verification and elimination of transformer blocks
Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, and jae-joon kim. SLEB : Streamlining LLM s through redundancy verification and elimination of transformer blocks. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=fuX4hyLPmO
2024
-
[52]
A simple and effective pruning approach for large language models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=PxoFut3dWW
2024
-
[53]
The llama 3 herd of models, 2024
The Llama Team. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[54]
Llama 2: Open foundation and fine-tuned chat models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023. URL https://arxiv.org/abs/2307.09288
Pith/arXiv arXiv 2023
-
[55]
GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE : A multi-task benchmark and analysis platform for natural language understanding. In Tal Linzen, Grzegorz Chrupa a, and Afra Alishahi (eds.), Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pp.\ 353--355, ...
-
[56]
Sheared LL a MA : Accelerating language model pre-training via structured pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. Sheared LL a MA : Accelerating language model pre-training via structured pruning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=09iOdaeOzp
2024
-
[57]
Beyond perplexity: Multi-dimensional safety evaluation of LLM compression
Zhichao Xu, Ashim Gupta, Tao Li, Oliver Bentham, and Vivek Srikumar. Beyond perplexity: Multi-dimensional safety evaluation of LLM compression. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 15359--15396, Miami, Florida, USA, November 2024. Association for Computatio...
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025. URL https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[60]
Investigating layer importance in large language models
Yang Zhang, Yanfei Dong, and Kenji Kawaguchi. Investigating layer importance in large language models. In Yonatan Belinkov, Najoung Kim, Jaap Jumelet, Hosein Mohebbi, Aaron Mueller, and Hanjie Chen (eds.), Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp.\ 469--479, Miami, Florida, US, November 2024 b . A...
-
[61]
Finercut: Finer-grained interpretable layer pruning for large language models, 2024 c
Yang Zhang, Yawei Li, Xinpeng Wang, Qianli Shen, Barbara Plank, Bernd Bischl, Mina Rezaei, and Kenji Kawaguchi. Finercut: Finer-grained interpretable layer pruning for large language models, 2024 c . URL https://arxiv.org/abs/2405.18218
arXiv 2024
-
[62]
Plug-and-play: An efficient post-training pruning method for large language models
Yingtao Zhang, Haoli Bai, Haokun Lin, Jialin Zhao, Lu Hou, and Carlo Vittorio Cannistraci. Plug-and-play: An efficient post-training pruning method for large language models. In The Twelfth International Conference on Learning Representations, 2024 d . URL https://openreview.net/forum?id=Tr0lPx9woF
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.