Closed-form solutions to some generalized variational inference problems
Pith reviewed 2026-06-25 20:21 UTC · model grok-4.3
The pith
Generalized variational inference admits explicit measure-level solutions for f-divergences, Bregman divergences, and Rényi penalties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For f-divergence penalties the optimal density satisfies a scalar inverse-gradient formula obtained from a one-dimensional dual identity; the Kullback-Leibler, Cressie-Read, and squared-Hellinger cases are worked out explicitly. Bregman penalties between densities yield solutions containing a scalar mass multiplier. Rényi penalties of order r greater than 1 produce a normalized truncated-power density together with a threshold equation satisfied by every global optimizer. Reverse f-divergences and mixed forward/reverse Kullback-Leibler penalties follow from the same separable-integral reduction.
What carries the argument
The separable integral principle that reduces the measure-valued objective to a scalar equation solved by an inverse-gradient density formula or a one-dimensional dual identity.
If this is right
- Kullback-Leibler, Cressie-Read, and squared-Hellinger penalties each produce an explicit optimal measure.
- Bregman penalties between densities admit density-space solutions containing only a scalar mass multiplier.
- Rényi penalties of order r>1 are solved by a normalized truncated-power density satisfying a threshold equation.
- Reverse f-divergences and mixed forward/reverse Kullback-Leibler penalties are obtained from the same separable-integral reduction.
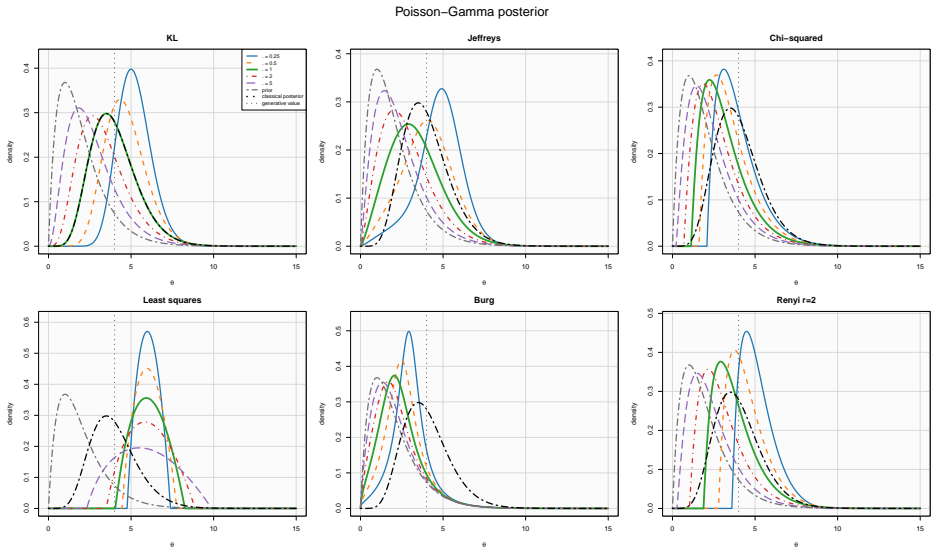
- Finite model-weight formulas and conjugate Bayesian examples realize the closed forms in practice.
Where Pith is reading between the lines
- The closed forms allow direct comparison of inference results across different divergence choices inside the same model without numerical optimization.
- Whenever a new divergence class satisfies the separability condition, the same reduction technique may supply closed forms.
- The explicit solutions make it possible to study how the choice of divergence affects posterior concentration without confounding effects from variational approximation error.
Load-bearing premise
The variational objective separates over the underlying space so that the measure-valued problem reduces to a scalar equation via the inverse-gradient or dual identity for the chosen divergence class.
What would settle it
A concrete loss function, prior, and divergence (for example squared-Hellinger) for which the proposed density formula fails to attain the minimum value of the variational objective.
Figures

read the original abstract
The Donsker--Varadhan formula characterizes the ordinary Bayesian posterior as the solution of an unrestricted $\mathsf{KL}$-regularized variational problem. Generalized variational inference replaces this regularizer by other divergences, but the resulting measure-valued optimization problem is often studied only after restriction to a parametric variational family. This paper studies the unrestricted measure-level problem. Given a measurable space $(\mathcal{Z},\mathfrak{Z})$, a prior probability measure $P$, a measurable loss $\ell:\mathcal{Z}\to(-\infty,\infty]$, a regularization strength $\alpha>0$, and a divergence $\mathsf{D}(Q\Vert P)$, we seek probability measures in \[ \underset{Q\in\mathcal{P}(\mathcal{Z})}{\mathrm{arg\,min}}\left\{\int_{\mathcal{Z}} \ell\,\mathrm{d}Q+\alpha\mathsf{D}(Q\Vert P)\right\}. \] For $f$-divergence penalties we derive a scalar inverse-gradient density formula and a one-dimensional dual identity; the Kullback--Leibler, Cressie--Read, and squared-Hellinger problems are treated as examples. Reverse $f$-divergences and mixed forward/reverse Kullback--Leibler penalties follow from the same separable integral principle. For Bregman divergences between densities we obtain a density-space solution with a scalar mass multiplier, including least-squares, density-power, and Burg/Itakura--Saito examples. For R\'enyi penalties of order $r>1$ we derive a normalized truncated-power characterization and a threshold equation for every global optimizer. Finite model-weight formulas and simple conjugate Bayesian model illustrations show how these closed forms are realized in practice and differ from the traditional solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives closed-form solutions to the unrestricted measure-valued variational problem min_Q ∫ ℓ dQ + α D(Q||P) for f-divergences (including KL, Cressie-Read, squared-Hellinger), reverse f-divergences, mixed KL penalties, Bregman divergences between densities (least-squares, density-power, Burg), and Rényi penalties of order r>1, yielding explicit scalar formulas such as inverse-gradient densities, dual identities, mass multipliers, and normalized truncated-power characterizations, together with finite-model illustrations that differ from standard posteriors.
Significance. If the derivations are valid under the stated conditions, the explicit closed forms provide exact, non-parametric characterizations of the optimizers for several common regularizers, enabling direct comparison with Bayesian posteriors and exact solutions in conjugate finite-model settings; this strengthens the theoretical foundation of generalized variational inference beyond parametric restrictions.
major comments (2)
- [treatment of the unrestricted measure-valued problem (abstract and §3)] The central reductions for f-divergences (scalar inverse-gradient density formula and one-dimensional dual identity) and Bregman cases (density-space solution with scalar mass multiplier) rest on the assumption that the integral objective separates sufficiently to permit reduction to a scalar equation for arbitrary measurable ℓ and general measurable spaces (Z, Z). This separability is invoked without an explicit statement of the required conditions on ℓ (e.g., measurability, lower semicontinuity, or atomicity of the space) that guarantee the global optimizer is captured by the derived scalar multiplier; if the assumption fails for some ℓ, the claimed closed forms would not characterize the argmin.
- [Rényi penalties section] §4 (Rényi penalties): the normalized truncated-power characterization and threshold equation are stated to hold for every global optimizer, but the derivation does not address whether multiple solutions to the threshold equation can exist or how to select among them when the loss ℓ induces non-unique mass allocations; this leaves open whether the formula always yields the global minimizer or only candidate points.
minor comments (2)
- [Introduction] Notation for the divergence D(Q||P) and the loss ℓ is introduced without an early table or list clarifying the domain and range assumptions (e.g., whether ℓ can take +∞).
- [finite model-weight formulas] The finite-model illustrations are presented as differing from traditional solutions, but the explicit numerical comparison (e.g., posterior weights) is only summarized rather than tabulated for the conjugate examples.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [treatment of the unrestricted measure-valued problem (abstract and §3)] The central reductions for f-divergences (scalar inverse-gradient density formula and one-dimensional dual identity) and Bregman cases (density-space solution with scalar mass multiplier) rest on the assumption that the integral objective separates sufficiently to permit reduction to a scalar equation for arbitrary measurable ℓ and general measurable spaces (Z, Z). This separability is invoked without an explicit statement of the required conditions on ℓ (e.g., measurability, lower semicontinuity, or atomicity of the space) that guarantee the global optimizer is captured by the derived scalar multiplier; if the assumption fails for some ℓ, the claimed closed forms would not characterize the argmin.
Authors: We agree that an explicit statement of conditions is warranted. The manuscript already assumes ℓ is measurable (as stated in the problem setup), which permits the pointwise separation of the integral objective used in the derivations. However, to guarantee existence of a minimizer and that the scalar formula captures the global argmin in general measurable spaces, lower semicontinuity of the objective functional is typically needed. We will add a dedicated remark in §3 clarifying these conditions and noting the settings (e.g., Polish spaces with continuous ℓ) under which the reductions are rigorous. revision: yes
-
Referee: [Rényi penalties section] §4 (Rényi penalties): the normalized truncated-power characterization and threshold equation are stated to hold for every global optimizer, but the derivation does not address whether multiple solutions to the threshold equation can exist or how to select among them when the loss ℓ induces non-unique mass allocations; this leaves open whether the formula always yields the global minimizer or only candidate points.
Authors: The derivation shows that any global optimizer must take the normalized truncated-power form and satisfy the threshold equation. When the threshold equation admits multiple roots, these yield distinct candidate measures; the global minimizer is identified by evaluating the original objective at each candidate and selecting the lowest value. We will revise §4 to state this selection procedure explicitly and note that the formula therefore supplies all candidate points rather than automatically returning the unique global minimizer in every case. revision: yes
Circularity Check
No circularity: derivations follow from separability and standard divergence identities without reduction to inputs by construction
full rationale
The paper derives scalar inverse-gradient formulas, dual identities, and normalized characterizations for f-divergences, Bregman divergences, and Rényi penalties by reducing the measure-valued optimization under the assumption that the integral objective separates. These steps invoke standard properties of the divergences (e.g., the form of D(Q||P)) and the separability of the loss integral, without the resulting closed forms being equivalent to fitted parameters or self-defined quantities. No self-citation chains, uniqueness theorems from the authors, or renamings of known results are load-bearing. The central claims remain independent mathematical reductions under the stated assumptions, consistent with the reader's assessment of low circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption f-divergences, Bregman divergences, and Rényi divergences admit the separable integral representations and dual identities used to obtain the scalar formulas.
- domain assumption The loss function ℓ is measurable and the optimization problem over P(Z) admits a solution of the claimed form.
Reference graph
Works this paper leans on
-
[1]
Syed Mumtaz Ali and Samuel D. Silvey. A general class of coefficients of divergence of one distribution from another. Journal of the Royal Statistical Society: Series B, 28 0 (1): 0 131--142, 1966
1966
-
[2]
Foundations and Trends® in Machine Learning , author =
Pierre Alquier. User-friendly introduction to PAC-Bayes bounds. Foundations and Trends in Machine Learning, 17 0 (2): 0 174--303, 2024. doi:10.1561/2200000100
-
[3]
A variational characterization of R \'e nyi divergences
Venkat Anantharam. A variational characterization of R \'e nyi divergences. IEEE Transactions on Information Theory, 64 0 (11): 0 6979--6989, 2018
2018
-
[4]
Robust bounds on risk-sensitive functionals via R \'e nyi divergence
Rami Atar, Kamaljit Chowdhary, and Paul Dupuis. Robust bounds on risk-sensitive functionals via R \'e nyi divergence. SIAM/ASA Journal on Uncertainty Quantification, 3 0 (1): 0 18--33, 2015
2015
-
[5]
Statistical Inference: The Minimum Distance Approach
Ayanendranath Basu, Hiroyuki Shioya, and Chanseok Park. Statistical Inference: The Minimum Distance Approach. CRC Press, 2011
2011
-
[6]
Bauschke and Jonathan M
Heinz H. Bauschke and Jonathan M. Borwein. Legendre functions and the method of random Bregman projections. Journal of Convex Analysis, 4 0 (1): 0 27--67, 1997
1997
-
[7]
Mirror descent and nonlinear projected subgradient methods for convex optimization
Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization. Operations Research Letters, 31 0 (3): 0 167--175, 2003
2003
-
[8]
Katsoulakis, Luc Rey-Bellet, and Jie Wang
Jeremiah Birrell, Paul Dupuis, Markos A. Katsoulakis, Luc Rey-Bellet, and Jie Wang. Variational representations and neural network estimation of R \'e nyi divergences. SIAM Journal on Mathematics of Data Science, 3 0 (4): 0 1093--1116, 2021
2021
-
[9]
Katsoulakis, Yannis Pantazis, and Luc Rey-Bellet
Jeremiah Birrell, Paul Dupuis, Markos A. Katsoulakis, Yannis Pantazis, and Luc Rey-Bellet. (f, ) -divergences: Interpolating between f -divergences and integral probability metrics. Journal of Machine Learning Research, 23 0 (39): 0 1--70, 2022
2022
-
[10]
Holmes, and Stephen G
Pier Giovanni Bissiri, Chris C. Holmes, and Stephen G. Walker. A general framework for updating belief distributions. Journal of the Royal Statistical Society: Series B, 78 0 (5): 0 1103--1130, 2016
2016
-
[11]
Borwein and Adrian S
Jonathan M. Borwein and Adrian S. Lewis. Convex Analysis and Nonlinear Optimization: Theory and Examples. Springer, second edition, 2006
2006
-
[12]
L. M. Bregman. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Computational Mathematics and Mathematical Physics, 7: 0 200--217, 1967
1967
-
[13]
Measuring distribution model risk
Thomas Breuer and Imre Csiszar. Measuring distribution model risk. Mathematical Finance, 26 0 (2): 0 395--411, 2016
2016
-
[14]
Minimization of divergences on sets of signed measures
Michel Broniatowski and Amor Keziou. Minimization of divergences on sets of signed measures. Studia Scientiarum Mathematicarum Hungarica, 43 0 (4): 0 403--442, 2006
2006
-
[15]
Parametric estimation and tests through divergences and the duality technique
Michel Broniatowski and Amor Keziou. Parametric estimation and tests through divergences and the duality technique. Journal of Multivariate Analysis, 100 0 (1): 0 16--36, 2009
2009
-
[16]
Maximum entropy spectral analysis
John Parker Burg. Maximum entropy spectral analysis. In Proceedings of the 37th Annual International Meeting of the Society of Exploration Geophysicists, Oklahoma City, OK, 1967
1967
-
[17]
Noel Cressie and Timothy R. C. Read. Multinomial goodness-of-fit tests. Journal of the Royal Statistical Society: Series B (Methodological), 46 0 (3): 0 440--464, 1984
1984
-
[18]
Information-type measures of difference of probability distributions and indirect observations
Imre Csisz \'a r. Information-type measures of difference of probability distributions and indirect observations. Studia Scientiarum Mathematicarum Hungarica, 2: 0 299--318, 1967
1967
-
[19]
Generalized projections for non-negative functions
Imre Csisz \'a r. Generalized projections for non-negative functions. Acta Mathematica Hungarica, 68 0 (1--2): 0 161--185, 1995
1995
-
[20]
Hoeting, David Madigan, Adrian E
Jennifer A. Hoeting, David Madigan, Adrian E. Raftery, and Chris T. Volinsky. Bayesian model averaging: A tutorial. Statistical Science, 14 0 (4): 0 382--401, 1999. doi:10.1214/ss/1009212519
-
[21]
Analysis synthesis telephony based on the maximum likelihood method
Fumitada Itakura and Shuzo Saito. Analysis synthesis telephony based on the maximum likelihood method. In Proceedings of the 6th International Congress on Acoustics, pages C17--C20, 1968
1968
-
[22]
An invariant form for the prior probability in estimation problems
Harold Jeffreys. An invariant form for the prior probability in estimation problems. Proceedings of the Royal Society of London. Series A, 186 0 (1007): 0 453--461, 1946
1946
-
[23]
Robert E. Kass and Adrian E. Raftery. Bayes factors. Journal of the American Statistical Association, 90 0 (430): 0 773--795, 1995. doi:10.1080/01621459.1995.10476572
-
[24]
An optimization-centric view on Bayes ' rule: Reviewing and generalizing variational inference
Jeremias Knoblauch, Jack Jewson, and Theodoros Damoulas. An optimization-centric view on Bayes ' rule: Reviewing and generalizing variational inference. Journal of Machine Learning Research, 23 0 (132): 0 1--109, 2022
2022
-
[25]
Andre F. T. Martins and Ramon Fernandez Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classification. In Proceedings of the 33rd International Conference on Machine Learning, volume 48 of PMLR, pages 1614--1623, 2016
2016
-
[26]
Andre F. T. Martins, Marcos Treviso, Antonio Farinhas, Pedro M. Q. Aguiar, Mario A. T. Figueiredo, Mathieu Blondel, and Vlad Niculae. Sparse continuous distributions and Fenchel--Young losses. Journal of Machine Learning Research, 23 0 (257): 0 1--74, 2022
2022
-
[27]
Jeffrey W. Miller. Asymptotic normality, concentration, and coverage of generalized posteriors. Journal of Machine Learning Research, 22 0 (168): 0 1--53, 2021
2021
-
[28]
Hongseok Namkoong and John C. Duchi. Stochastic gradient methods for distributionally robust optimization with f -divergences. In Advances in Neural Information Processing Systems 29, 2016
2016
-
[29]
On the large-sample limits of some Bayesian model evaluation statistics
Hien Duy Nguyen, Mayetri Gupta, Jacob Westerhout, and TrungTin Nguyen. On the large-sample limits of some Bayesian model evaluation statistics. Econometrics and Statistics, 2026. doi:10.1016/j.ecosta.2026.05.001. To appear
-
[30]
Wainwright, and Michael I
XuanLong Nguyen, Martin J. Wainwright, and Michael I. Jordan. Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory, 56 0 (11): 0 5847--5861, 2010
2010
-
[31]
f - GAN : Training generative neural samplers using variational divergence minimization
Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f - GAN : Training generative neural samplers using variational divergence minimization. In Advances in Neural Information Processing Systems 29, 2016
2016
-
[32]
Frank W. J. Olver, Daniel W. Lozier, Ronald F. Boisvert, and Charles W. Clark, editors. NIST Handbook of Mathematical Functions . Cambridge University Press, Cambridge, 2010
2010
-
[33]
Information Theory: From Coding to Learning
Yury Polyanskiy and Yihong Wu. Information Theory: From Coding to Learning. Cambridge University Press, 2024. Prepublication version, August 2024
2024
-
[34]
On measures of entropy and information
Alfr \'e d R \'e nyi. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 547--561, 1961
1961
-
[35]
Tyrrell Rockafellar
R. Tyrrell Rockafellar. Conjugate Duality and Optimization. SIAM, 1974
1974
-
[36]
Reid, Dario Garcia-Garcia, and James Petterson
Avraham Ruderman, Mark D. Reid, Dario Garcia-Garcia, and James Petterson. Tighter variational representations of f -divergences via restriction to probability measures. In Proceedings of the 29th International Conference on Machine Learning, pages 671--678, 2012
2012
-
[37]
Machine Learning for Engineers: Principles and Algorithms
Osvaldo Simeone. Machine Learning for Engineers: Principles and Algorithms. Cambridge University Press, 2023
2023
-
[38]
Stephen G. Walker. Bayesian inference via a minimization rule. Sankhya: The Indian Journal of Statistics, 68 0 (4): 0 542--553, 2006
2006
-
[39]
Using stacking to average Bayesian predictive distributions
Yuling Yao, Aki Vehtari, Daniel Simpson, and Andrew Gelman. Using stacking to average Bayesian predictive distributions. Bayesian Analysis, 13 0 (3): 0 917--1007, 2018. doi:10.1214/17-BA1091
-
[40]
Information-theoretic upper and lower bounds for statistical estimation
Tong Zhang. Information-theoretic upper and lower bounds for statistical estimation. IEEE Transactions on Information Theory, 52 0 (4): 0 1307--1321, 2006
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.