Learning to Reason with Curriculum II: Compositional Generalization
Pith reviewed 2026-06-29 05:19 UTC · model grok-4.3
The pith
Recursive decomposition via autocurriculum lets a learner simulate T-step computations with only 2 to the O of square root log T tokens of supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
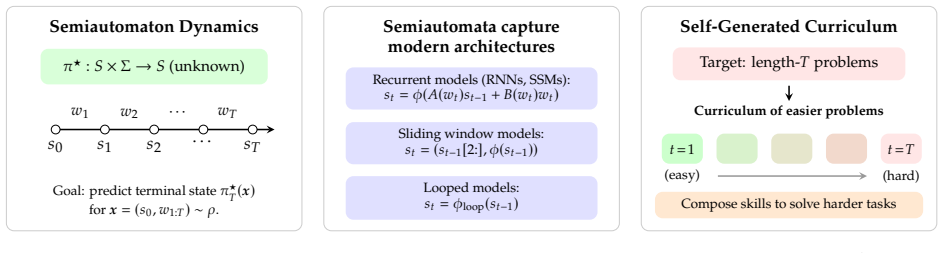
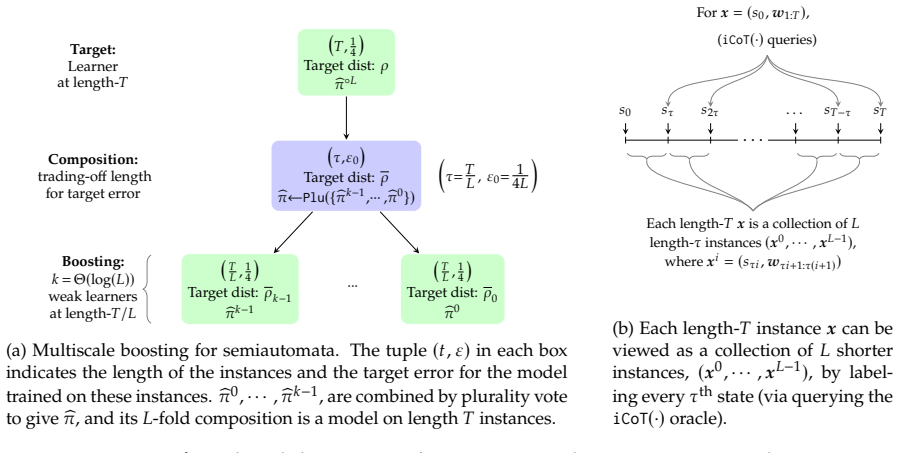
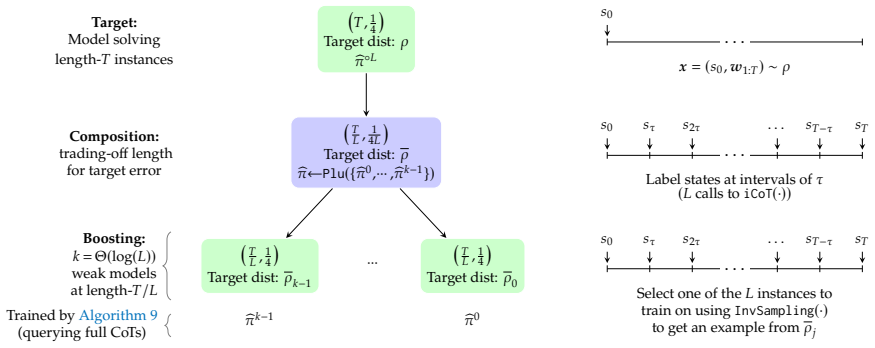
An autocurriculum that recursively decomposes longer sequences into shorter sub-problems, learns to solve them, and composes the solutions achieves 2 to the O of square root of log T tokens of supervision under interactive feedback, overcoming the Omega of T token barrier of direct simulation, and reduces the coverage requirement on a reference model from full length T to a shorter block length B much less than T under verifiable-reward reinforcement learning.
What carries the argument
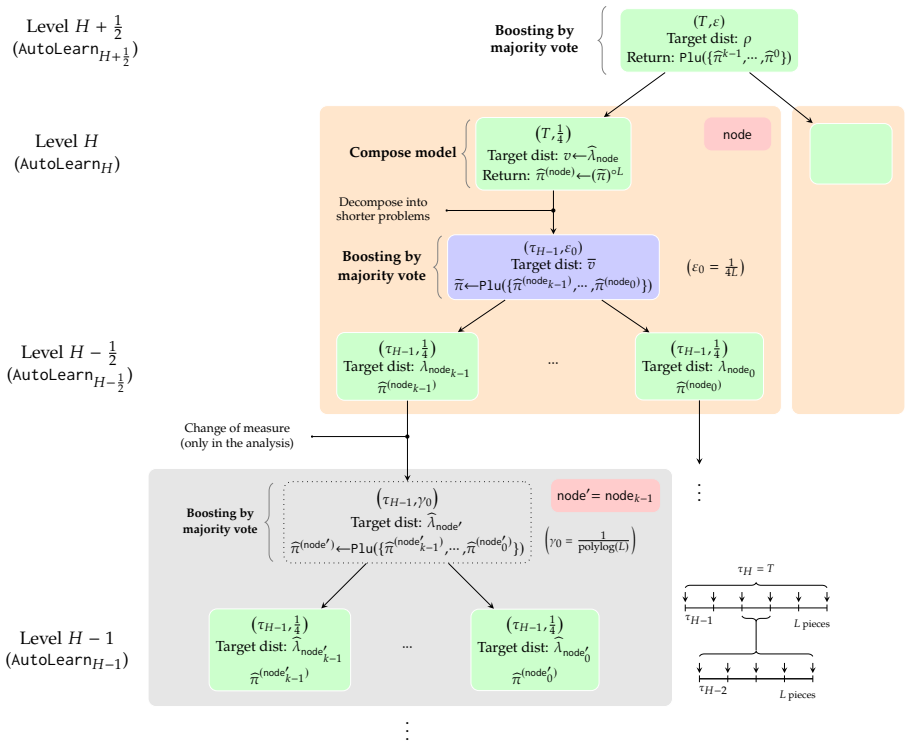
The autocurriculum that recursively decomposes longer sequences into shorter sub-problems, learns solutions to those sub-problems, and composes them.
If this is right
- In supervised-fine-tuning-style interactive settings, subpolynomial tokens suffice to learn T-step simulation.
- In reinforcement-learning-with-verifiable-rewards settings, a reference model needs coverage only at block length B rather than at full length T.
- The same decomposition applies to state tracking, regular-language recognition, and modular arithmetic.
Where Pith is reading between the lines
- The same recursive decomposition may improve sample efficiency for other chain-of-thought tasks that involve long sequential computation.
- Models trained with this curriculum could generalize to sequence lengths much longer than those seen during training.
- The block-length reduction in the reinforcement-learning setting suggests a practical way to train on very long horizons when only short-horizon coverage is available.
Load-bearing premise
The mechanisms that govern learning to simulate semiautomata also govern compositional generalization and chain-of-thought reasoning in general.
What would settle it
An experiment in which the curriculum method still requires Omega of T tokens of interactive supervision, or in which direct simulation succeeds with o of T tokens, would show the claimed statistical improvement does not hold.
Figures

read the original abstract
Compositional generalization, the ability to solve complex problems by combining solutions to simpler sub-problems, is a fundamental capability of both natural and artificial intelligence, and a key mechanism underlying chain-of-thought reasoning. However, the theoretical underpinnings of compositional generalization remain poorly understood: when and why does decomposing a problem into parts yield more efficient learning than solving it directly? We study this question through the canonical problem of learning to simulate semiautomata (predicting the outcome of $T$ steps of sequential computation), a model that captures state tracking, regular language recognition, and modular arithmetic. We show that an autocurriculum-based approach building on Part I of this series, recursively decomposing longer sequences into shorter sub-problems, learning to solve them, and composing the solutions, achieves dramatically better statistical complexity than direct methods. (i) For a setting inspired by supervised fine-tuning (SFT) where the learner receives interactive feedback on intermediate states of the computation, curriculum facilitates learning from only $2^{\mathcal{O}(\sqrt{\log T})}$ tokens of supervision; i.e., subpolynomial in the sequence length $T$, overcoming the $\Omega(T)$ token barrier required by direct simulation. (ii) For a setting inspired by reinforcement learning with verifiable rewards (RLVR), where the learner improves a pre-trained reference model using an outcome verifier, we show that curriculum reduces the requirement on the reference model from coverage at the full sequence length $T$ to coverage at a shorter block length $B \ll T$, an exponentially weaker condition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes compositional generalization via the canonical task of learning to simulate semiautomata (predicting T steps of sequential computation). It introduces an autocurriculum that recursively decomposes long sequences into shorter sub-problems, claiming that this yields 2^{O(sqrt(log T))} tokens of interactive supervision (subpolynomial in T) versus the Omega(T) barrier of direct simulation, and that it relaxes the reference-model coverage requirement from length T to a shorter block length B in the RLVR setting.
Significance. If the stated bounds are rigorously derived, the work supplies a precise theoretical account of when recursive decomposition improves statistical complexity over direct methods. This is a scoped but load-bearing result for understanding curriculum effects in state-tracking and modular tasks that underlie chain-of-thought reasoning. The manuscript ships a scoped theoretical result on statistical complexity for the semiautomata simulation task under an autocurriculum.
major comments (1)
- [Abstract] Abstract: the central complexity claims (2^{O(sqrt(log T))} supervision tokens and the exponential relaxation of coverage length) are stated without any derivation steps, proof sketches, or experimental validation. Without these, the support for the stated bounds cannot be assessed and the improvement cannot be verified as arising from the recursive decomposition rather than from unstated assumptions.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below, clarifying the role of the abstract versus the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central complexity claims (2^{O(sqrt(log T))} supervision tokens and the exponential relaxation of coverage length) are stated without any derivation steps, proof sketches, or experimental validation. Without these, the support for the stated bounds cannot be assessed and the improvement cannot be verified as arising from the recursive decomposition rather than from unstated assumptions.
Authors: Abstracts are concise summaries and conventionally omit derivation steps or proof sketches; those appear in the full manuscript (Sections 3 and 4). There we formally define the autocurriculum, prove the 2^{O(sqrt(log T))} interactive sample complexity bound by induction on the recursive decomposition, and show that the coverage requirement relaxes from length T to block length B by composing solutions over shorter segments. The comparison to direct methods (which require Omega(T) tokens or full-length coverage) is made explicit with no unstated assumptions. The work is theoretical rather than empirical, so experimental validation is not provided; the mathematical derivations directly establish that the improvement stems from the recursive structure. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and context describe a theoretical statistical complexity result for semiautomata simulation via recursive autocurriculum decomposition, claiming subpolynomial supervision tokens versus linear. No equations, fitted parameters, or self-referential reductions are exhibited that would make the 2^{O(sqrt(log T))} bound equivalent to its inputs by construction. The reference to Part I is a normal series citation and does not load-bear the central claim without a quoted reduction to a prior self-result. The derivation is presented as arising from the compositional structure itself and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The semiautomata simulation task captures the essential structure of compositional generalization and chain-of-thought reasoning.
Reference graph
Works this paper leans on
-
[1]
Exploring length generalization in large language models.Advances in Neural Information Processing Systems, 35:38546–38556, 2022
36 Cem Anil, Yuhuai Wu, Anders Andreassen, Aitor Lewkowycz, Vedant Misra, Vinay Ramasesh, Ambrose Slone, Guy Gur-Ari, Ethan Dyer, and Behnam Neyshabur. Exploring length generalization in large language models.Advances in Neural Information Processing Systems, 35:38546–38556, 2022. 9 David A Barrington. Bounded-width polynomial-size branching programs reco...
2022
-
[2]
Statisticalinferenceforprobabilisticfunctionsoffinitestatemarkovchains
5, 8 LeonardEBaumandTedPetrie. Statisticalinferenceforprobabilisticfunctionsoffinitestatemarkovchains. The annals of mathematical statistics, 37(6):1554–1563, 1966. 29 YoshuaBengio,JérômeLouradour,RonanCollobert,andJasonWeston. Curriculumlearning. InProceedings of the 26th International Conference on Machine Learning (ICML), 2009. 2 Adam Block and Yury Po...
-
[3]
Enumeratingregularexpressionsandtheirlanguages,
5, 36 HermannGruber,JonathanLee,andJeffreyOShallit. Enumeratingregularexpressionsandtheirlanguages,
-
[4]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
5, 17 Yanjun Han, Soham Jana, and Yihong Wu. Optimal prediction of markov chains with and without spectral gap.IEEE Transactions on Information Theory, 69(6):3920–3959, 2023. 29 John E Hopcroft, Rajeev Motwani, and Jeffrey D Ullman. Introduction to automata theory, languages, and computation.Acm Sigact News, 32(1):60–65, 2001. 36 JianHu,XibinWu,ZilinZhu,W...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Analysing Mathematical Reasoning Abilities of Neural Models
2, 3, 4, 5, 8, 11, 16, 17, 19, 20, 21, 22, 24, 60 RonaldLRivestandRobertESchapire. Inferenceoffiniteautomatausinghomingsequences. InProceedings of the twenty-first annual ACM symposium on Theory of computing, pages 411–420, 1989. 36 David Saxton, Edward Grefenstette, Felix Hill, and Pushmeet Kohli. Analysing mathematical reasoning abilities of neural mode...
work page internal anchor Pith review Pith/arXiv arXiv 1989
-
[6]
3, 9 Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025. 2 John Von Neumann et al. Various techniques used in connection with random digits.John von Neumann, Collected Works, 5(768-77...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
good distribution
Thus(𝑏, 𝑎, 𝑎, 𝑏)is accepted because its terminal subset is{2,4}, which contains the accepting position4. This is correct asRegExrecognizes the set of strings which end in𝑎𝑏. B Analyzing a Simpler Variant of Algorithm 1:AutoLearn.warmup ThissectionpresentsacompletedescriptionandanalysisforthesimplifiedversionofAutoLearnsketchedin Section5,whichusesonlyasin...
2025
-
[8]
42 B.2 Proving Theorem 3.4: relevant lemmata Having established the broader program, we introduce the lemmas mentioned above
This uses a bound which shows that𝛽0,𝑘 0 decays exponentially fast in 𝑘(Lemma B.9). 42 B.2 Proving Theorem 3.4: relevant lemmata Having established the broader program, we introduce the lemmas mentioned above. We will focus on the non-aborted iterations first, and then discuss the aborted iterations next. B.2.1 Non-aborted iterations e𝑝 𝑗 ⩾𝑝 ★ 𝑗 . In iter...
2025
-
[9]
This implies, with probability at least1−𝛿, Pr𝒙∼𝜌 b𝜋(𝒙)≠𝜋★ 𝑇(𝒙) ⩽ 1 4
In any iteration𝑗whereABORT[𝑗]does not occur, by Lemma B.6, with probability1−𝛿 𝑘,err 𝑗 ⩽err ★. This implies, with probability at least1−𝛿, Pr𝒙∼𝜌 b𝜋(𝒙)≠𝜋★ 𝑇(𝒙) ⩽ 1 4 . Bound on sample complexity ofAutoLearn.warmup.The bound on the size of the instance dataset required to establish the above guarantee for the depth-1construction is demonstrated in Lemma B....
-
[10]
It is a short calculation to see that𝛽0,𝑘 0 equals the probability that at most𝑘 2 of them come up heads. Since the expected number of heads is3𝑘 4 , by standard concentration arguments (say, Hoeffding’s inequality), the statement of the lemma is established.□ C Analysis ofAutoLearn(Algorithm 2): Proof of Theorem 3.4 This section presents the full analysi...
-
[11]
A union bound completes the bound on accuracy
By Lemma C.13, with probability 1−2𝛿, in any iteration𝑗∉𝒥ABORT[node],err𝑗 ⩽err ★. A union bound completes the bound on accuracy. Query and sample complexity ofAutoLearnℎ+1.The sample complexity ofAutoLearn ℎ+1 is𝑛 sample ℎ+ 1,2𝑘𝛿 =𝑛 ★ sample(ℎ+1 2 ,𝛿)·𝐶2 𝑘7/2log(𝐿)asrequiredbyLemmaC.12. ThequerycomplexityofAutoLearn ℎ+1 is then bounded as, 𝑛★ query ℎ+1,2𝑘...
2026
-
[12]
non-Lipschitz
error under𝜈. To achieve such a guarantee, it suffices for the learner to generate a sample from some other distributionb𝜈which satisfies the followingapproximate coverageguarantee: Pr𝑋∼𝜈 𝜈(𝑋) b𝜈(𝑋)⩾𝐶 cov ⩽𝛿 cov (54) Inparticular,undertheaboveassumption,aslongas𝛿 cov < 1 4,amodelwhichachieveserror𝜀=𝐶 −1 cov(1 4−𝛿cov) under the distribution over inputsb𝜈al...
-
[13]
Then the distributionb𝜈realized byAlgmust incur, max 𝜇∈𝝁 TV(b𝜈,𝜈)⩾ 1 2 where𝜈is the distribution∝𝜇(·)𝑤(·)
Forasufficientlysmallabsoluteconstant𝑐>0,consideranysamplingalgorithmAlgwhichdrawsatmost𝑁= 𝑐 √ 𝐿samples drawn from the distribution𝜇∈𝝁to generate a sample from some distributionb𝜈∈Δ{0,1,···,𝐿+1}, and such thatb𝜈is well defined for every base distribution𝜇∈𝝁. Then the distributionb𝜈realized byAlgmust incur, max 𝜇∈𝝁 TV(b𝜈,𝜈)⩾ 1 2 where𝜈is the distribution∝𝜇(·)𝑤(·)
-
[14]
1− 𝐿−1Ö 𝑖=0 1− 𝛼 𝑗,𝑘 rank𝑗(𝑋𝑖) 𝛼 𝑗,𝑘 max ! ℋ𝑗−1,𝒦𝑗−1 # ⩾ E
Furthermore, ifAlgdraws at most𝑁=𝑐 ′𝐿1/3samples from𝜇∈𝝁for a sufficiently small constant𝑐′>0, then the distributionb𝜈realized byAlgmust incur, max 𝜇∈𝝁 Pr𝑋∼𝜈 𝜈(𝑋) b𝜈(𝑋)⩾𝑐′𝐿1/3 ⩾ 1 2 Proof.The proof of this result is discussed in Section F.6.□ E.3𝒦𝑗 is a High Probability Event: Proof of Lemma B.4 We first introduce an auxiliary lemma which will be helpful t...
2025
-
[15]
Nowsuppose𝜎 ★ 0 issupportedonasetofNdim(𝒢)pointswhichareNatarajan-shatteredby𝒢
Furthermore, note that any fully labeled state sequence(𝑠0,𝒘)↦→𝜋𝑔★,1:𝑇((𝑠0,𝒘))can be constructed from the singular labeling𝑠0↦→𝑔★(𝑠0)and vice versa. Nowsuppose𝜎 ★ 0 issupportedonasetofNdim(𝒢)pointswhichareNatarajan-shatteredby𝒢. Thisimplies thatAlgmust query at least𝑐Ndim(𝒢)instances to be able to achieve error1 4 with probability at least1 2 for some abs...
2012
-
[16]
□ Lemma F.11.For a class of next-state/token predictorsΠfrom𝑆×Σ→𝑆,Ldim(Π)⩽Ndim(Π)log(|𝑆||Σ|)
Repeating this argument inductively, this implies that for all𝑡⩽𝑇,𝑠𝑡 =𝑠 ★ 𝑡 , which proves the claim. □ Lemma F.11.For a class of next-state/token predictorsΠfrom𝑆×Σ→𝑆,Ldim(Π)⩽Ndim(Π)log(|𝑆||Σ|). Proof.By a counting argumentLdim(Π)⩽log2|Π|, since a complete mistake tree of depth𝑚requires 2𝑚 distinct hypotheses, one for each root-to-leaf path. On the other...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.