Global convergence analysis of mixtures of Exponential densities
Pith reviewed 2026-06-29 02:02 UTC · model grok-4.3
The pith
The EM algorithm approximates mixtures of two exponential distributions at a sub-exponential rate in at most log(n) iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A mixture of two Exponential distributions can be approximated by the EM algorithm at the sub-Exponential rate of convergence in at most log(n) iterations. Extending the analysis away from Gaussian mixture models does not change the statistical performance of the EM algorithm. The paper supplies generalizations of the minimum mean-separation and signal-to-noise ratio assumptions to the sub-Exponential setting.
What carries the argument
EM algorithm iterations driven by generalized minimum mean-separation and signal-to-noise ratio conditions for exponential component densities.
If this is right
- Statistical performance of EM stays the same when the model class changes from Gaussian to exponential mixtures.
- The adapted separation conditions suffice to control the global convergence rate.
- Simulation results align with the theoretical iteration bound for exponential mixtures.
Where Pith is reading between the lines
- The same proof strategy might extend to other sub-exponential families such as gamma distributions with fixed shape.
- The log(n) iteration count implies that EM remains computationally cheap even for very large exponential-mixture data sets.
- Reliability or survival-analysis applications that routinely use exponential mixtures could now cite the same convergence guarantees previously available only for Gaussians.
Load-bearing premise
The generalized minimum mean-separation and signal-to-noise ratio conditions must hold for the two exponential components.
What would settle it
A simulation or calculation in which the separation condition is satisfied yet the EM iterates require more than log(n) steps to reach sub-exponential accuracy would disprove the claimed rate.
Figures
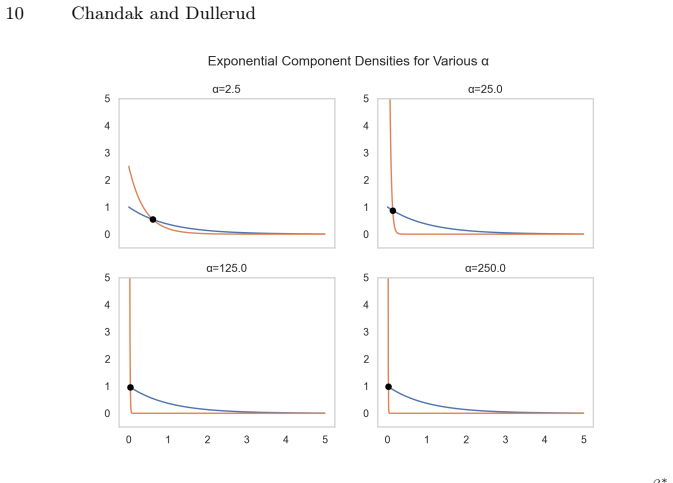
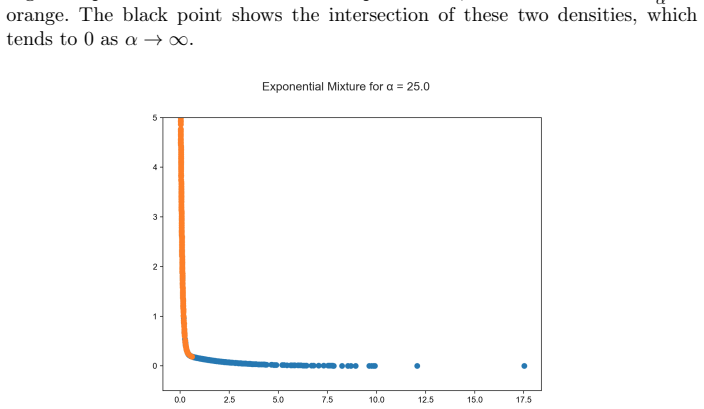
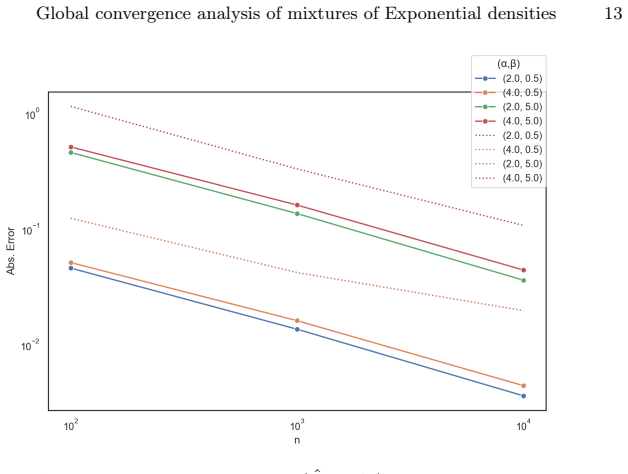
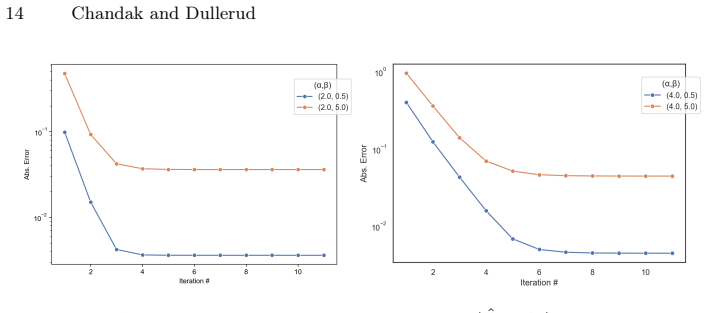
read the original abstract
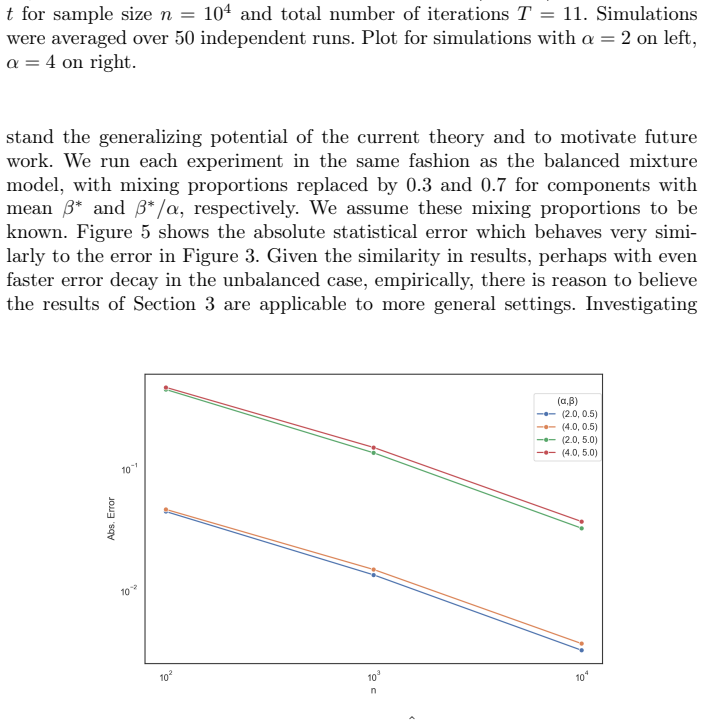
The theoretical foundations of the EM algorithm are often thought of in the context of Gaussian mixture models, However, the practical use cases of the EM algorithm span beyond Gaussian models. This paper establishes the first step towards understanding the behavior of the EM algorithm under mixtures of non-Gaussian densities. We show that a mixture of two Exponential distributions can be approximated by the EM algorithm at the sub-Exponential rate of convergence in at most $\log(n)$ iterations. The results here show that extending away from Gaussian mixture models does not affect the statistical performance of the EM algorithm. Furthermore, we present generalizations of typical assumptions in the Gaussian setting like minimum mean-separation and signal-to-noise ratio to the sub-Exponential setting. A simulation study is used to highlight the empirical performance of EM for mixtures of exponentials with promising results for the extension of existing theory to a larger class of mixture models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish the first global convergence result for the EM algorithm on a two-component mixture of exponential distributions. Under suitably generalized minimum mean-separation and signal-to-noise ratio conditions adapted from the Gaussian setting, it asserts that EM converges at a sub-exponential rate and reaches statistical accuracy in at most O(log n) iterations from arbitrary initialization. The work also includes a simulation study and argues that the extension beyond Gaussians preserves the statistical performance of EM.
Significance. If the adaptation of the separation and SNR conditions can be shown to control the contraction of the EM operator for exponentials, the result would provide a concrete first step toward non-Gaussian global convergence analyses. The simulation evidence is presented as supporting the theory, but the significance is limited by the absence of explicit verification that the adapted quantities bound the relevant Lipschitz constants or population operator for the exponential family.
major comments (2)
- [Section defining the generalized conditions and the main convergence theorem] The central claim (abstract and final paragraph) that the generalized minimum mean-separation and SNR conditions suffice for an O(log n) iteration bound rests on an unverified adaptation. Because exponentials are supported on [0,∞) with variance equal to the mean, it is not immediate that the same functional form controls the EM map contraction as in the Gaussian case; the manuscript must supply the explicit bound on the population EM operator (or the relevant Lipschitz constant) under these conditions.
- [Proof of the main convergence result] The iteration complexity statement requires a quantitative contraction factor that is strictly less than 1 and independent of n (or decaying appropriately). No such explicit factor is derived from the adapted conditions in the provided analysis; without it the O(log n) claim cannot be substantiated.
minor comments (2)
- [Abstract] The abstract contains a sentence fragment after the first comma and inconsistent capitalization of 'sub-Exponential'.
- [Section 2 or 3] Notation for the mixture weights, rate parameters, and the EM update map should be introduced with explicit definitions before the statement of the generalized conditions.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The comments correctly identify that the current manuscript does not contain an explicit derivation of the contraction properties of the EM operator under the proposed generalized conditions. We will revise the paper to supply the missing quantitative bounds while preserving the overall claims about sub-exponential convergence for exponential mixtures.
read point-by-point responses
-
Referee: [Section defining the generalized conditions and the main convergence theorem] The central claim (abstract and final paragraph) that the generalized minimum mean-separation and SNR conditions suffice for an O(log n) iteration bound rests on an unverified adaptation. Because exponentials are supported on [0,∞) with variance equal to the mean, it is not immediate that the same functional form controls the EM map contraction as in the Gaussian case; the manuscript must supply the explicit bound on the population EM operator (or the relevant Lipschitz constant) under these conditions.
Authors: We agree that an explicit bound on the population EM operator (or the associated Lipschitz constant) must be derived from the generalized mean-separation and SNR conditions. In the revised manuscript we will insert a new lemma immediately after the definition of the conditions that computes the contraction modulus of the population EM map for the two-component exponential mixture and shows that the modulus is strictly less than one whenever the generalized conditions hold. revision: yes
-
Referee: [Proof of the main convergence result] The iteration complexity statement requires a quantitative contraction factor that is strictly less than 1 and independent of n (or decaying appropriately). No such explicit factor is derived from the adapted conditions in the provided analysis; without it the O(log n) claim cannot be substantiated.
Authors: We acknowledge that the present proof does not exhibit a concrete contraction factor derived from the adapted conditions. The revision will augment the main convergence theorem with an explicit upper bound on the contraction factor (obtained from the new lemma on the population operator) that is strictly less than one and independent of sample size n, thereby rigorously establishing the O(log n) iteration complexity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available text present a theoretical derivation of EM convergence rates for two-component exponential mixtures under generalized minimum mean-separation and SNR conditions adapted from the Gaussian case. No equations, fitted parameters, or self-citations are exhibited that reduce any claimed prediction or rate to an input by construction. The load-bearing steps consist of verifying that the adapted conditions control the EM operator contraction, which is an independent analytic claim rather than a tautology or renamed fit. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Mannor, S., Srebro, N., Williamson, R.C
Anandkumar, A., Hsu, D., Kakade, S.M.: A Method of Moments for Mixture Mod- els and Hidden Markov Models. In: Mannor, S., Srebro, N., Williamson, R.C. (eds.) Proceedings of the 25th Annual Conference on Learning Theory. Proceedings of Machine Learning Research, vol. 23, pp. 33.1–33.34. PMLR, Edinburgh, Scotland (25–27 Jun 2012), https://proceedings.mlr.pr...
2012
-
[2]
URLhttps://doi.org/10.1214/16-AOS1435
Balakrishnan, S., Wainwright, M.J., Yu, B.: Statistical guarantees for the EM algorithm: From population to sample-based analysis. The Annals of Statistics 45(1), 77 – 120 (2017). https://doi.org/10.1214/16-AOS1435
-
[3]
The Annals of Mathematical Statistics41(1), 164–171 (1970), http://www.jstor.org/stable/ 2239727
Baum, L.E., Petrie, T., Soules, G., Weiss, N.: A Maximization Technique Occurring in the Statistical Analysis of Probabilistic Functions of Markov Chains. The Annals of Mathematical Statistics41(1), 164–171 (1970), http://www.jstor.org/stable/ 2239727
1970
-
[4]
In: Ad- vances in Neural Information Processing Systems
Blei, D., Ng, A., Jordan, M.: Latent Dirichlet Allocation. In: Ad- vances in Neural Information Processing Systems. vol. 14. MIT Press (2001), https://proceedings.neurips.cc/paper_files/paper/2001/file/ 296472c9542ad4d4788d543508116cbc-Paper.pdf
2001
-
[5]
The Annals of Statistics 48(1), 27–42 (2020)
Candès, E.J., Sur, P.: The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression. The Annals of Statistics 48(1), 27–42 (2020)
2020
-
[6]
In: Kale, S., Shamir, O
Daskalakis, C., Tzamos, C., Zampetakis, M.: Ten Steps of EM Suffice for Mix- tures of Two Gaussians. In: Kale, S., Shamir, O. (eds.) Proceedings of the 2017 Conference on Learning Theory. Proceedings of Machine Learning Research, vol. 65, pp. 704–710. PMLR (07–10 Jul 2017), https://proceedings.mlr.press/v65/ daskalakis17b.html
2017
-
[7]
Cambridge University Press (2008)
Davison, A.: Statistical Models. Cambridge University Press (2008)
2008
-
[8]
Sanchez-Blazquez,et al., MILES: A Medium Resolution INT Library of Empirical Spectra
Dempster, A.P., Laird, N.M., Rubin, D.B.: Maximum Likelihood from Incomplete Data Via the EM Algorithm. Journal of the Royal Statistical Society: Series B (Methodological)39(1), 1–22 (1977). https://doi.org/https://doi.org/10.1111/j. 2517-6161.1977.tb01600.x
work page doi:10.1111/j 1977
-
[9]
The Annals of Statistics 48(6), pp
Dwivedi, R., Ho, N., Khamaru, K., Wainwright, M.J., Jordan, M.I., Yu, B.: Singu- larity, misspecification and the convergence rate of EM. The Annals of Statistics 48(6), pp. 3161–3182 (2020), https://www.jstor.org/stable/27028739
-
[10]
Bioinformatics18(2), 275–286 (2002)
Ghosh, D., Chinnaiyan, A.M.: Mixture modelling of gene expression data from microarray experiments. Bioinformatics18(2), 275–286 (2002). https://doi.org/ https://doi.org/10.1093/bioinformatics/18.2.275
-
[11]
URLhttps://doi.org/10.1080/01621459.1993.10476353
Jamshidian, M., Jennrich, R.I.: Conjugate gradient acceleration of the EM algo- rithm. Journal of the American Statistical Association88(421), 221–228 (1993). https://doi.org/10.1080/01621459.1993.10594313
-
[12]
Jin, C., Zhang, Y., Balakrishnan, S., Wainwright, M.J., Jordan, M.: Local maxima in the likelihood of gaussian mixture models: Structural results and algorithmic consequences29(2016), https://proceedings.neurips.cc/paper_files/paper/2016/ file/3875115bacc48cca24ac51ee4b0e7975-Paper.pdf
-
[13]
In: International conference on computational learning theory (COLT)
Kannan, R., Salmasian, H., Vempala, S.: The spectral method for general mixture models. In: International conference on computational learning theory (COLT). pp. 444–457. Springer (2005). https://doi.org/https://doi.org/10.1007/11503415_30 Global convergence analysis of mixtures of Exponential densities 17
-
[14]
In: Conference on Learning Theory
Kwon, J., Caramanis, C.: The EM algorithm gives sample-optimality for learn- ing mixtures of well-separated Gaussians. In: Conference on Learning Theory. pp. 2425–2487. PMLR (2020)
2020
-
[15]
In: Chiappa, S., Calandra, R
Kwon, J., Caramanis, C.: EM Converges for a Mixture of Many Linear Regres- sions. In: Chiappa, S., Calandra, R. (eds.) Proceedings of the Twenty Third In- ternational Conference on Artificial Intelligence and Statistics. Proceedings of Machine Learning Research, vol. 108, pp. 1727–1736. PMLR (26–28 Aug 2020), https://proceedings.mlr.press/v108/kwon20a.html
2020
-
[16]
In: Pro- ceedings of the Thirty-Second Conference on Learning Theory
Kwon, J., Qian, W., Caramanis, C., Chen, Y., Davis, D.: Global convergence of the EM algorithm for mixtures of two component linear regression. In: Pro- ceedings of the Thirty-Second Conference on Learning Theory. Proceedings of Machine Learning Research, vol. 99, pp. 2055–2110. PMLR (25–28 Jun 2019), https://proceedings.mlr.press/v99/kwon19a.html
2055
-
[17]
Lindsay, B.G.: Mixture models: theory, geometry, and applications. Inst. Math. Stat. (1995)
1995
-
[18]
John Wiley & Sons (1997)
McLachlan, G.J., Krishnan, T.: The EM Algorithm and Extensions. John Wiley & Sons (1997)
1997
-
[19]
Annual Re- view of Statistics and its Application6(1), 355–378 (2019)
McLachlan, G.J., Lee, S.X., Rathnayake, S.I.: Finite mixture models. Annual Re- view of Statistics and its Application6(1), 355–378 (2019). https://doi.org/https: //doi.org/10.1146/annurev-statistics-031017-100325
-
[20]
SIAM Review26(2), 195–239 (1984)
Redner, R.A., Walker, H.F.: Mixture Densities, Maximum Likelihood and the EM Algorithm. SIAM Review26(2), 195–239 (1984). https://doi.org/10.1137/1026034
-
[21]
In: International Conference on Artificial Intelligence and Statistics
Reisizadeh, A., Gatmiry, K., Ozdaglar, A.: Em for mixture of linear regression with clustered data. In: International Conference on Artificial Intelligence and Statistics. pp. 2341–2349. PMLR (2024)
2024
-
[22]
Scandinavian Journal of Statistics pp
Sundberg, R.: Maximum likelihood theory for incomplete data from an exponential family. Scandinavian Journal of Statistics pp. 49–58 (1974), http://www.jstor.org/ stable/4615553
-
[23]
arXiv preprint arXiv:2408.05819 (2026)
Tao, Z., Chandak, R., Kulkarni, S.: Fast convergence of a federated Expectation- Maximization algorithm. arXiv preprint arXiv:2408.05819 (2026)
-
[24]
Journal of Computer and System Sciences68(4), 841–860 (2004)
Vempala, S., Wang, G.: A spectral algorithm for learning mixture models. Journal of Computer and System Sciences68(4), 841–860 (2004). https://doi.org/https: //doi.org/10.1016/j.jcss.2003.11.008, Special Issue on FOCS 2002
-
[25]
University of California, Irvine 10(11), 31 (2020)
Vershynin, R.: High-Dimensional Probability. University of California, Irvine 10(11), 31 (2020)
2020
-
[26]
Statistics and Computing12(4), 315–330 (2002)
Viele, K., Tong, B.: Modeling with mixtures of linear regressions. Statistics and Computing12(4), 315–330 (2002)
2002
-
[27]
The Annals of Statistics11(1), 95–103 (1983), http://www.jstor.org/stable/2240463
Wu, C.J.: On the convergence properties of the EM algorithm. The Annals of Statistics11(1), 95–103 (1983), http://www.jstor.org/stable/2240463
-
[28]
Mathematical Statistics and Learning4, 143–220 (2021)
Wu, Y., Zhou, H.H.: Randomly initialized EM algorithm for two-component Gaus- sian mixture achieves near optimality ino(√n)iterations. Mathematical Statistics and Learning4, 143–220 (2021). https://doi.org/10.4171/MSL/29
-
[29]
In: International Conference on Machine Learning
Wu, Y., Zhang, S., Yu, W., Liu, Y., Gu, Q., Zhou, D., Chen, H., Cheng, W.: Personalized federated learning under mixture of distributions. In: International Conference on Machine Learning. pp. 37860–37879. PMLR (2023)
2023
-
[30]
In: Proceedings of the 30th International Conference on Neural Information Processing Systems
Xu, J., Hsu, D., Maleki, A.: Global analysis of expectation maximization for mixtures of two gaussians. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. vol. 29, p. 2684–2692. Curran Asso- ciates Inc., Red Hook, NY, USA (2016), https://proceedings.neurips.cc/paper_ files/paper/2016/file/792c7b5aae4a79e78aaeda8...
2016
-
[31]
arXiv preprint arXiv:2011.02258 (2020)
Zhang, H., Chen, S.X.: Concentration inequalities for statistical inference. arXiv preprint arXiv:2011.02258 (2020)
-
[32]
Zhang,H.,Wei,H.:Sharpersub-weibullconcentrations.Mathematics10(13), 2252 (2022)
2022
-
[33]
Electronic Journal of Statistics14(1), 632–660 (2020)
Zhao, R., Li, Y., Sun, Y.: Statistical convergence of the EM algorithm on Gaussian mixture models. Electronic Journal of Statistics14(1), 632–660 (2020). https:// doi.org/10.1214/19-EJS1660 Appendix A Proofs of main results Here we provide detailed proofs of each of the results in Section 3. Proof of Proposition 1 We begin from the complete log-likelihood...
-
[34]
Rewriting our iterates in terms ofg, we have ˆβt+1 = 1 n nX i=1 g(Xi, ˆβt)and, βt+1 =E[g(X, β t)]
Iterative structure:We start by defining g(X, β) =αX−(α−1)X(1 +αe (1−α)X/β)−1, whereX∼P β∗ as defined in (1). Rewriting our iterates in terms ofg, we have ˆβt+1 = 1 n nX i=1 g(Xi, ˆβt)and, βt+1 =E[g(X, β t)]. Global convergence analysis of mixtures of Exponential densities 21 We will use this formulation to show concentration of the sample iterates around...
-
[35]
The argument for ˆβt ≥β t follows by reversing the same argument given below
Concentration of(I):We assume, without loss of generality, thatˆβt ≤β t. The argument for ˆβt ≥β t follows by reversing the same argument given below. By the Mean Value Theorem and continuity ofgwith respect to its second argument, we have |g(X, ˆβt)−g(X, β t)| | ˆβt −β t| = ∂g(X, β) ∂β ˜β∈[ ˆβt,βt] ≤max β∈[ ˆβt,βt] ∂g(X, β) ∂β ⇐ ⇒ |g(X, ˆβt)−g(X, β t)| ≤...
-
[36]
nδ2 ∥g(Xi, βt)−E[g(X, β t)]∥2 ψ1 , nδ ∥g(Xi, βt)−E[g(X, β t)]∥ψ1 #) ≤2 exp ( −cnmin
Concentration of(II):For term (II) of (5), we invoke sub-Exponential concentration results which involve computing the sub-Exponential norm of a random variable, as defined in [25, Definition 2.8.4]. The first technical result we need to proceed is the fact that a mixture of exponentially distributed random variables is sub-Exponential. We capture this, a...
-
[37]
Recursion:Now putting together the bounds for(I)and(II), we have for anyt >0, | ˆβt+1 −β t+1| ≲ (α−1) 2αβ∗2 [min{ ˆβt, βt}]2 1 + 1 α2 + 4Cθ max{1, α−2} r η n | ˆβt −β t| +β ∗ r log(2/δ) n + log(2/δ) n . This sets up a recursion in terms of|ˆβt −β t|, which we solve to obtain that at iterationt, given an initial estimate ˆβ0 =β 0, the absolute loss is boun...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.