Hierarchical Decision Making with Structured Policies: A Principled Design via Inverse Optimization
Pith reviewed 2026-06-30 09:22 UTC · model grok-4.3
The pith
Inverse optimization from expert demonstrations structures lower-level policies in hierarchical RL-OC systems so they align with long-term upper-level goals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that adopting inverse optimization to inform the structure of the lower-level problem from expert demonstrations produces a hierarchical RL-OC architecture in which the lower-level policy objective remains aligned with the overall long-term task goal, yielding higher efficiency and decision quality than baselines on resource allocation and collision avoidance tasks.
What carries the argument
Inverse optimization applied to expert demonstrations to recover and embed the lower-level objective within the hierarchical framework.
If this is right
- The framework guarantees stricter constraint satisfaction than pure RL-based hierarchical methods.
- Lower-level policies avoid the myopic objectives common in standard optimal-control formulations.
- The approach systematically integrates upper-level goal abstraction with structured lower-level decision making.
- Empirical gains appear on both discrete network resource allocation and continuous collision avoidance tasks.
Where Pith is reading between the lines
- The same inverse-optimization step could be applied to any hierarchical control setting where expert trajectories are available, such as multi-agent coordination or long-horizon planning.
- If the recovered objective only matches demonstrations on the training distribution, generalization to new environments may still produce drift; a natural test would be out-of-distribution task variants.
- The method suggests a route to hybridize RL and optimal control without hand-crafted subgoals, which could be checked by comparing against subgoal-generation baselines on the same domains.
Load-bearing premise
Expert demonstrations exist and are sufficient for inverse optimization to recover a lower-level objective whose solutions stay aligned with the upper-level long-term goal.
What would settle it
On a held-out task, measure whether policies produced by the method achieve lower long-term cumulative reward or higher constraint violation rates than a myopic baseline; consistent underperformance would falsify the alignment claim.
Figures

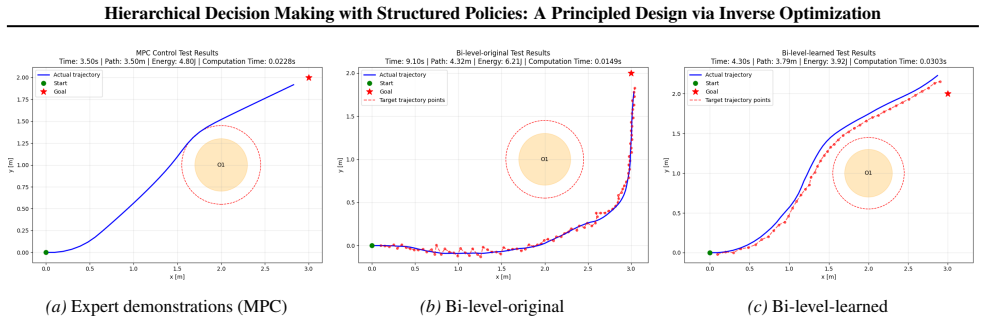
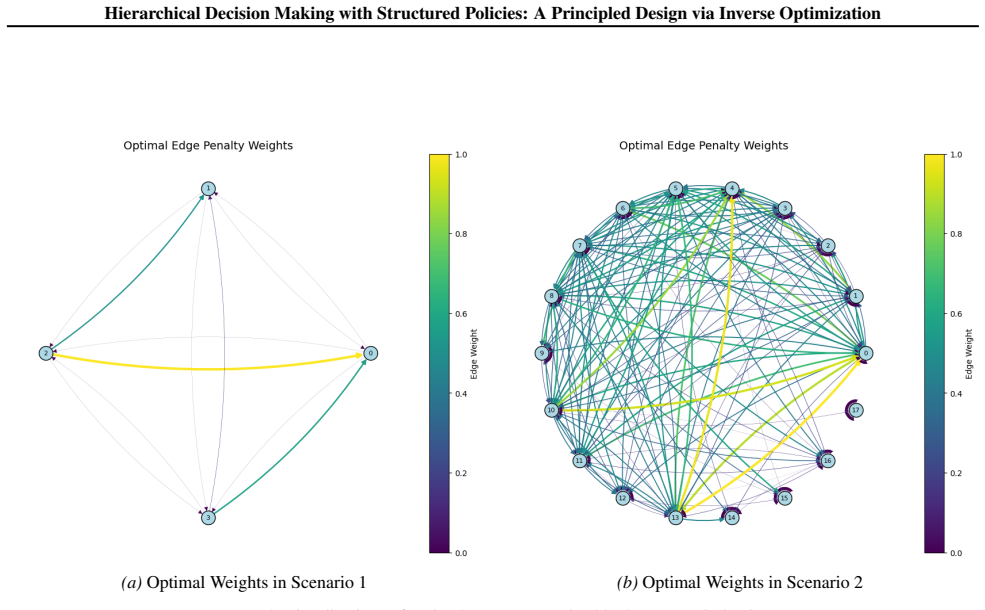
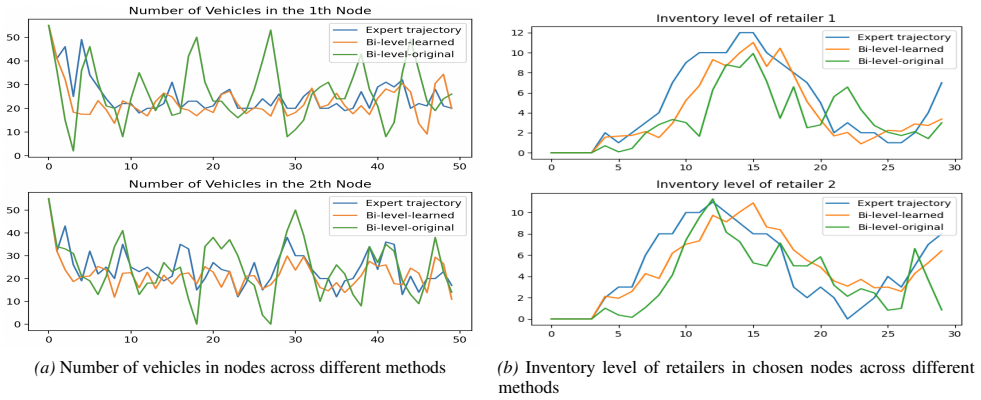


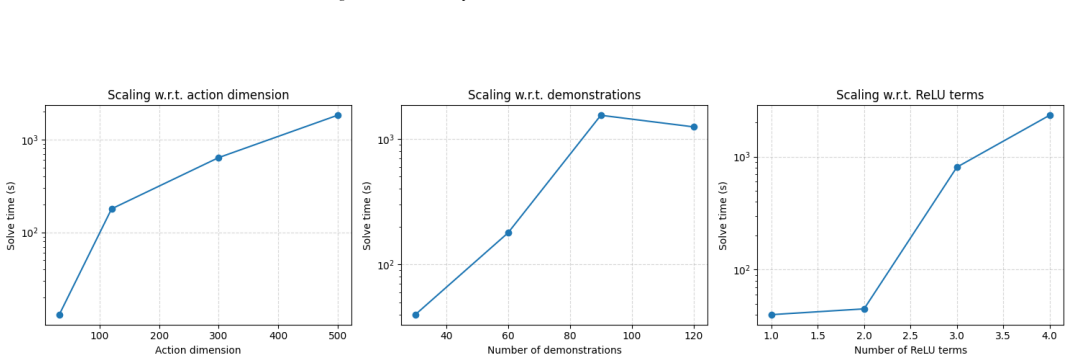
read the original abstract
Hierarchical decision-making frameworks are pivotal for addressing complex control tasks, enabling agents to decompose intricate problems into manageable subgoals. Despite their promise, existing hierarchical policies face critical limitations: (i) reinforcement learning (RL)-based methods struggle to guarantee strict constraint satisfaction, and (ii) optimal control (OC)-based approaches often rely on myopic and computationally prohibitive formulations. To reconcile these trade-offs, hierarchical RL-OC architectures have emerged as a promising paradigm. However, the formulation of the lower-level optimization within these frameworks remains underexplored, often relying on heuristic or myopic objectives. In this work, we propose a principled framework that systematically integrates upper-level goal abstraction with structured lower-level decision making. We adopt an inverse optimization approach to inform the structure of the lower-level problem from expert demonstrations, ensuring that the objective of the lower-level policy remains aligned with the overall long-term task goal. To validate the approach, our framework is evaluated on distinct decision making tasks: network-based resource allocation and continuous collision avoidance. Empirical results demonstrate that our method consistently outperforms strong baselines based on end-to-end RL, learning-augmented optimal control, and existing hierarchical RL approaches in both efficiency and decision quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical RL-OC framework for complex control tasks that uses inverse optimization on expert demonstrations to structure the lower-level optimization problem. This is intended to ensure the lower-level objective aligns with the upper-level long-term goal, addressing limitations of pure RL (constraint satisfaction) and OC (myopia, computation). The method is evaluated on network resource allocation and continuous collision avoidance, with claims of consistent outperformance over end-to-end RL, learning-augmented OC, and existing hierarchical RL baselines in efficiency and decision quality.
Significance. If the inverse-optimization step reliably produces lower-level objectives that preserve long-term alignment rather than embedding myopic behavior, the framework would provide a principled alternative to heuristic lower-level designs in hierarchical settings. The two-task empirical evaluation and explicit contrast with multiple baseline families would strengthen the case for practical utility in constrained sequential decision problems.
major comments (1)
- [Abstract] Abstract (proposed framework paragraph): the assertion that inverse optimization 'ensuring that the objective of the lower-level policy remains aligned with the overall long-term task goal' is load-bearing for the central claim, yet the abstract supplies no mechanism (regularization toward long-term value, bilevel consistency constraints, or post-recovery verification) that would prevent recovery of myopic objectives when demonstrations arise from suboptimal or short-horizon experts. This assumption is not shown to hold for the two evaluation domains.
minor comments (1)
- [Abstract] Abstract: no equations, dataset details, error bars, or description of the inverse problem are supplied, making it impossible to assess the concrete formulation or statistical reliability of the reported outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (proposed framework paragraph): the assertion that inverse optimization 'ensuring that the objective of the lower-level policy remains aligned with the overall long-term task goal' is load-bearing for the central claim, yet the abstract supplies no mechanism (regularization toward long-term value, bilevel consistency constraints, or post-recovery verification) that would prevent recovery of myopic objectives when demonstrations arise from suboptimal or short-horizon experts. This assumption is not shown to hold for the two evaluation domains.
Authors: We agree that the abstract should more explicitly state the key assumption. Inverse optimization recovers the lower-level objective that best rationalizes the provided expert demonstrations (standard formulation in inverse optimization literature). In our setting, the demonstrations are generated from policies that optimize the long-term hierarchical objective (see experimental setups in Sections 4.1 and 4.2 for both domains). Consequently, the recovered objective aligns with the long-term goal by construction under the assumption that experts are (near-)optimal for the overall task. The method does not include additional regularization or bilevel constraints to correct for myopic experts; it inherits the standard limitations of inverse optimization regarding demonstration quality. We will revise the abstract to state this assumption clearly and add a brief discussion of the assumption in the method section. revision: yes
Circularity Check
No circularity detected; derivation self-contained
full rationale
The provided abstract and description contain no equations, parameter-fitting procedures, or self-citations that reduce any claimed result to its inputs by construction. The inverse-optimization step is presented as an empirical method whose alignment property is asserted to hold under the (external) assumption that expert demonstrations encode long-term goals; this is a modeling assumption rather than a definitional or fitted-input reduction. Evaluation on separate tasks supplies independent content. No load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results is visible. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine Learning and Knowledge Extraction , volume=
Hierarchical reinforcement learning: A survey and open research challenges , author=. Machine Learning and Knowledge Extraction , volume=. 2022 , publisher=
2022
-
[2]
Learning for Dynamics and Control , pages=
Learning without knowing: Unobserved context in continuous transfer reinforcement learning , author=. Learning for Dynamics and Control , pages=. 2021 , organization=
2021
-
[3]
arXiv preprint arXiv:2305.09129 , year=
Graph reinforcement learning for network control via bi-level optimization , author=. arXiv preprint arXiv:2305.09129 , year=
-
[4]
The Eleventh International Conference on Learning Representations , year=
Causal imitation learning via inverse reinforcement learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
Computers & Operations Research , volume=
Reinforcement learning for combinatorial optimization: A survey , author=. Computers & Operations Research , volume=. 2021 , publisher=
2021
-
[6]
arXiv preprint arXiv:1908.06976 , year=
A survey on intrinsic motivation in reinforcement learning , author=. arXiv preprint arXiv:1908.06976 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Learning to delegate for large-scale vehicle routing , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2405.13509 , year=
Learn to formulate: A surrogate model framework for generalized assignment problem with routing constraints , author=. arXiv preprint arXiv:2405.13509 , year=
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Combining reinforcement learning and constraint programming for combinatorial optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[10]
Mathematical Programming , volume=
A polyhedral approach to online bipartite matching , author=. Mathematical Programming , volume=. 2018 , publisher=
2018
-
[11]
, author=
DeepMPC: Learning deep latent features for model predictive control. , author=. Robotics: Science and Systems , volume=. 2015 , organization=
2015
-
[12]
Annual Review of Control, Robotics, and Autonomous Systems , volume=
Learning-based model predictive control: Toward safe learning in control , author=. Annual Review of Control, Robotics, and Autonomous Systems , volume=. 2020 , publisher=
2020
-
[13]
Advances in neural information processing systems , volume=
A hierarchical reinforcement learning based optimization framework for large-scale dynamic pickup and delivery problems , author=. Advances in neural information processing systems , volume=
-
[14]
International conference on machine learning , pages=
Hierarchical imitation and reinforcement learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[15]
Advances in neural information processing systems , volume=
Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation , author=. Advances in neural information processing systems , volume=
-
[16]
2021 60th IEEE Conference on Decision and Control (CDC) , pages=
Learning convex terminal costs for complexity reduction in MPC , author=. 2021 60th IEEE Conference on Decision and Control (CDC) , pages=. 2021 , organization=
2021
-
[17]
2023 IEEE 19th international conference on automation science and engineering (CASE) , pages=
Bi-level optimization augmented with conditional variational autoencoder for autonomous driving in dense traffic , author=. 2023 IEEE 19th international conference on automation science and engineering (CASE) , pages=. 2023 , organization=
2023
-
[18]
International conference on machine learning , pages=
Feudal networks for hierarchical reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[19]
Advances in neural information processing systems , volume=
Data-efficient hierarchical reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[20]
2024 American Control Conference (ACC) , pages=
Neural Horizon Model Predictive Control-Increasing Computational Efficiency with Neural Networks , author=. 2024 American Control Conference (ACC) , pages=. 2024 , organization=
2024
-
[21]
6th Annual Learning for Dynamics & Control Conference , pages=
Mpc-inspired reinforcement learning for verifiable model-free control , author=. 6th Annual Learning for Dynamics & Control Conference , pages=. 2024 , organization=
2024
-
[22]
Computers & chemical engineering , volume=
Model predictive control: past, present and future , author=. Computers & chemical engineering , volume=. 1999 , publisher=
1999
-
[23]
The International Journal of Advanced Manufacturing Technology , volume=
Review on model predictive control: An engineering perspective , author=. The International Journal of Advanced Manufacturing Technology , volume=. 2021 , publisher=
2021
-
[24]
Neural networks , volume=
Multilayer feedforward networks are universal approximators , author=. Neural networks , volume=. 1989 , publisher=
1989
-
[25]
IEEE Robotics and Automation Letters , year=
Transformer-based model predictive control: Trajectory optimization via sequence modeling , author=. IEEE Robotics and Automation Letters , year=
-
[26]
Operations research , volume=
Quantile inverse optimization: Improving stability in inverse linear programming , author=. Operations research , volume=. 2022 , publisher=
2022
-
[27]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Robotic table wiping via reinforcement learning and whole-body trajectory optimization , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[28]
Learning for Dynamics and Control , pages=
Practical reinforcement learning for mpc: Learning from sparse objectives in under an hour on a real robot , author=. Learning for Dynamics and Control , pages=. 2020 , organization=
2020
-
[29]
2017 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Learning from the hindsight plan—episodic mpc improvement , author=. 2017 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2017 , organization=
2017
-
[30]
Learning for Dynamics and Control , pages=
Optimal cost design for model predictive control , author=. Learning for Dynamics and Control , pages=. 2021 , organization=
2021
-
[31]
2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , pages=
Trajectory planning for autonomous vehicles using hierarchical reinforcement learning , author=. 2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , pages=. 2021 , organization=
2021
-
[32]
arXiv preprint arXiv:2410.07933 , year=
Offline hierarchical reinforcement learning via inverse optimization , author=. arXiv preprint arXiv:2410.07933 , year=
-
[33]
Advances in neural information processing systems , volume=
Differentiable convex optimization layers , author=. Advances in neural information processing systems , volume=
-
[34]
Computers & chemical engineering , volume=
A symbolic reformulation/spatial branch-and-bound algorithm for the global optimisation of nonconvex MINLPs , author=. Computers & chemical engineering , volume=. 1999 , publisher=
1999
-
[35]
IEEE/CAA journal of automatica sinica , volume=
Hierarchical reinforcement learning with automatic sub-goal identification , author=. IEEE/CAA journal of automatica sinica , volume=. 2021 , publisher=
2021
-
[36]
Proceedings of the AAAI symposium series , volume=
Human-AI collaborative sub-goal optimization in hierarchical reinforcement learning , author=. Proceedings of the AAAI symposium series , volume=
-
[37]
Operations Research , volume=
Inverse optimization: Theory and applications , author=. Operations Research , volume=. 2025 , publisher=
2025
-
[38]
Nature Machine Intelligence , volume=
Intelligent problem-solving as integrated hierarchical reinforcement learning , author=. Nature Machine Intelligence , volume=. 2022 , publisher=
2022
-
[39]
Proceedings of the AAAI conference on artificial intelligence , volume=
Hierarchical reinforcement learning for integrated recommendation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[40]
Energy , volume=
Hierarchical reinforcement learning based energy management strategy for hybrid electric vehicle , author=. Energy , volume=. 2022 , publisher=
2022
-
[41]
IEEE Transactions on Intelligent Transportation Systems , volume=
Safe-state enhancement method for autonomous driving via direct hierarchical reinforcement learning , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2023 , publisher=
2023
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Earnhft: Efficient hierarchical reinforcement learning for high frequency trading , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
Transportation Research Part C: Emerging Technologies , volume=
Integrating big data analytics in autonomous driving: An unsupervised hierarchical reinforcement learning approach , author=. Transportation Research Part C: Emerging Technologies , volume=. 2024 , publisher=
2024
-
[44]
IEEE Transactions on Neural Networks and Learning Systems , year=
Goal-conditioned hierarchical reinforcement learning with high-level model approximation , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Spatial-temporal interplay in human mobility: A hierarchical reinforcement learning approach with hypergraph representation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[46]
Automatica , volume=
Closed-loop data-enabled predictive control and its equivalence with closed-loop subspace predictive control , author=. Automatica , volume=. 2026 , publisher=
2026
-
[47]
2019 18th European control conference (ECC) , pages=
Data-enabled predictive control: In the shallows of the DeePC , author=. 2019 18th European control conference (ECC) , pages=. 2019 , organization=
2019
-
[48]
IEEE Transactions on Automatic Control , volume=
Regret Analysis of Learning-Based MPC With Partially Unknown Cost Function , author=. IEEE Transactions on Automatic Control , volume=. 2023 , publisher=
2023
-
[49]
IEEE Transactions on Industrial Informatics , year=
Inverse model predictive control: Learning optimal control cost functions for MPC , author=. IEEE Transactions on Industrial Informatics , year=
-
[50]
IFAC-PapersOnLine , volume=
Stability-informed Bayesian Optimization for MPC Cost Function Learning , author=. IFAC-PapersOnLine , volume=. 2024 , publisher=
2024
-
[51]
IEEE Transactions on Industrial Electronics , volume=
LSTM-MPC: A deep learning based predictive control method for multimode process control , author=. IEEE Transactions on Industrial Electronics , volume=. 2022 , publisher=
2022
-
[52]
IEEE Transactions on Intelligent Vehicles , year=
Enhancing system-level safety in mixed-autonomy platoon via safe reinforcement learning , author=. IEEE Transactions on Intelligent Vehicles , year=
-
[53]
IEEE Transactions on Intelligent Transportation Systems , year=
Interaction-aware trajectory prediction for safe motion planning in autonomous driving: A transformer-transfer learning approach , author=. IEEE Transactions on Intelligent Transportation Systems , year=
-
[54]
Applied Energy , volume=
Multi-agent hierarchical reinforcement learning for energy management , author=. Applied Energy , volume=. 2023 , publisher=
2023
-
[55]
In 2020 IEEE , author=
Learning high-level policies for model predictive control. In 2020 IEEE , author=. RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
2020
-
[56]
Unmanned Systems , volume=
Hierarchical MPC-based motion planning for automated vehicles in parallel autonomy , author=. Unmanned Systems , volume=. 2024 , publisher=
2024
-
[57]
IFAC-PapersOnLine , volume=
Hierarchical learning for model predictive collision avoidance , author=. IFAC-PapersOnLine , volume=. 2022 , publisher=
2022
-
[58]
IEEE Industrial Electronics Magazine , volume=
Direct model predictive control: A review of strategies that achieve long prediction intervals for power electronics , author=. IEEE Industrial Electronics Magazine , volume=. 2014 , publisher=
2014
-
[59]
Journal of Process Control , volume=
Adaptive horizon economic nonlinear model predictive control , author=. Journal of Process Control , volume=. 2020 , publisher=
2020
-
[60]
2020 , publisher=
Model predictive control: theory, computation, and design , author=. 2020 , publisher=
2020
-
[61]
Plan Online, Learn Offline: Efficient Learning and Exploration via Model-Based Control
Plan online, learn offline: Efficient learning and exploration via model-based control , author=. arXiv preprint arXiv:1811.01848 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
2021 60th IEEE Conference on Decision and Control (CDC) , pages=
Graph neural network reinforcement learning for autonomous mobility-on-demand systems , author=. 2021 60th IEEE Conference on Decision and Control (CDC) , pages=. 2021 , organization=
2021
-
[63]
Available at SSRN , year=
Conformal inverse optimization for adherence-aware prescriptive analytics , author=. Available at SSRN , year=
-
[64]
Advances in neural information processing systems , volume=
Hindsight experience replay , author=. Advances in neural information processing systems , volume=
-
[65]
Advances in neural information processing systems , volume=
Goal-conditioned imitation learning , author=. Advances in neural information processing systems , volume=
-
[66]
arXiv preprint arXiv:2302.03122 , year=
State-wise safe reinforcement learning: A survey , author=. arXiv preprint arXiv:2302.03122 , year=
-
[67]
Frontiers of Information Technology & Electronic Engineering , volume=
Deep reinforcement learning: a survey , author=. Frontiers of Information Technology & Electronic Engineering , volume=. 2020 , publisher=
2020
-
[68]
Acta Automatica Sinica , volume=
Model predictive control—status and challenges , author=. Acta Automatica Sinica , volume=. 2013 , publisher=
2013
-
[69]
Mathematical Programming , volume=
Data-driven estimation in equilibrium using inverse optimization , author=. Mathematical Programming , volume=. 2015 , publisher=
2015
-
[70]
Optimization Letters , volume=
Inverse integer programming , author=. Optimization Letters , volume=. 2009 , publisher=
2009
-
[71]
Excitation of control-affine systems and Koopman error bounds
On excitation of control-affine systems and its use for data-driven Koopman approximants , author=. arXiv preprint arXiv:2511.03734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
6th Annual Learning for Dynamics & Control Conference , pages=
Random features approximation for control-affine systems , author=. 6th Annual Learning for Dynamics & Control Conference , pages=. 2024 , organization=
2024
- [73]
-
[74]
Ifac-PapersOnline , volume=
Successive convexification of non-convex optimal control problems with state constraints , author=. Ifac-PapersOnline , volume=. 2017 , publisher=
2017
-
[75]
Automatica , volume=
Nonlinear model-based predictive control of control nonaffine systems , author=. Automatica , volume=. 1997 , publisher=
1997
-
[76]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[77]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[78]
M. J. Kearns , title =
-
[79]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[80]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.