NeuReasoner: Theory-grounded Mapping of Reasoning Elicitation Boundaries
Pith reviewed 2026-06-30 07:33 UTC · model grok-4.3
The pith
NeuReasoner elicits latent reasoning to match thinking-mode performance on arithmetic, code, Bayesian, and reward tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
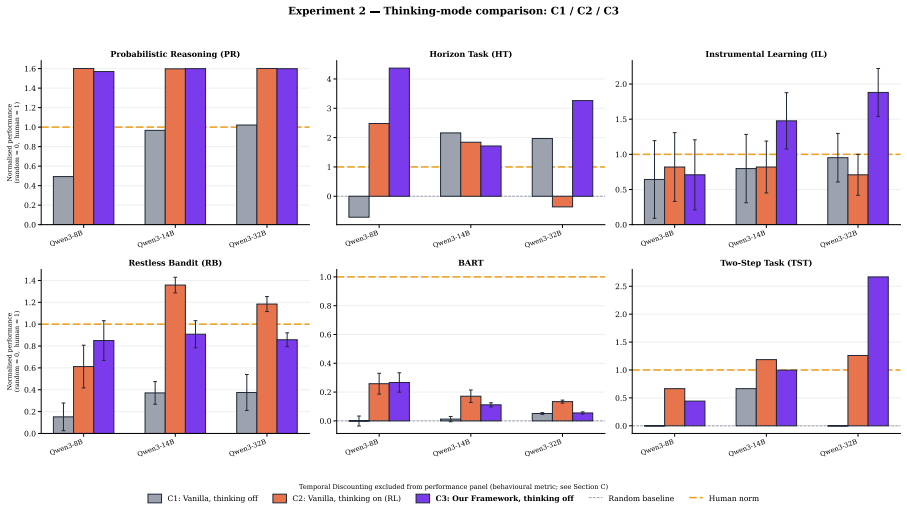
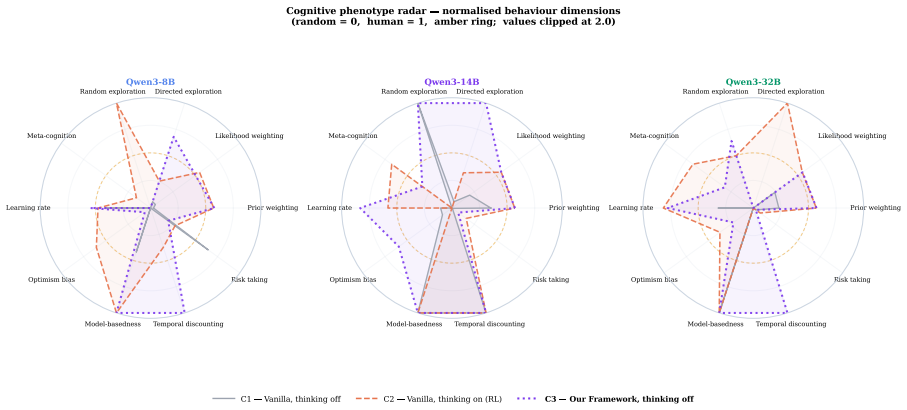
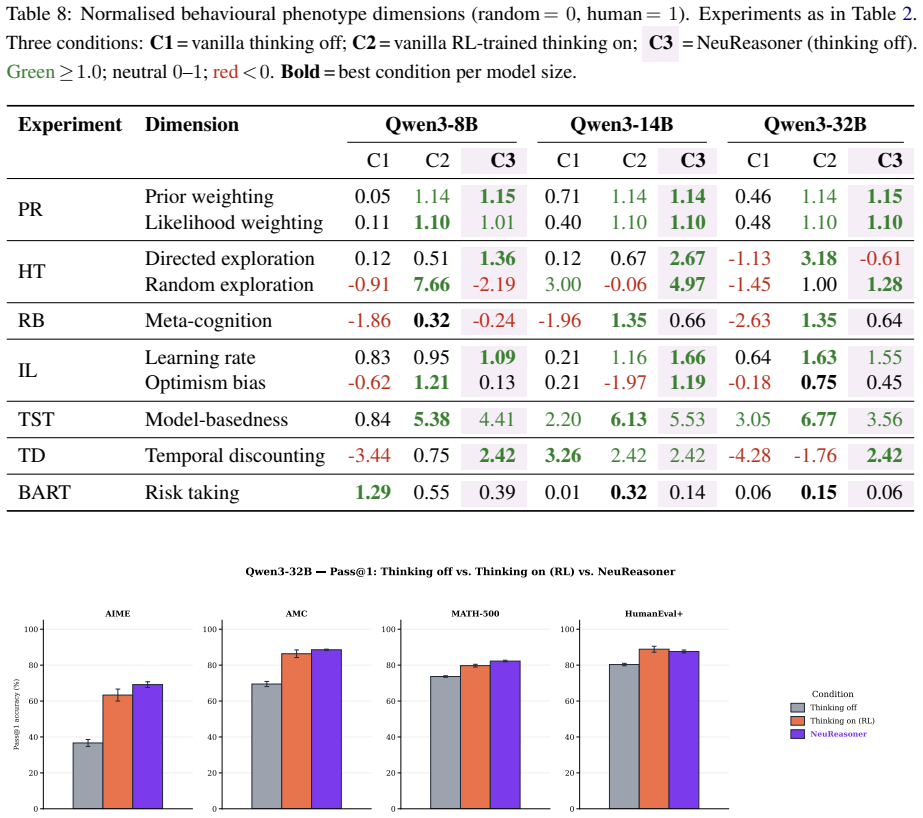
At sufficient scale, NeuReasoner matches or exceeds thinking-mode baselines on arithmetic reasoning, code generation, Bayesian reasoning, and reward learning. These gains persist against self-consistency and iterative-refinement baselines matched to NeuReasoner's per-decision call budget. Using NeuReasoner reveals clear boundaries where elicitation fails, such as risk-taking and decision making under uncertainty, and demonstrates that model scale can interact with elicitation by both widening its advantage on some tasks and erasing it on others.
What carries the argument
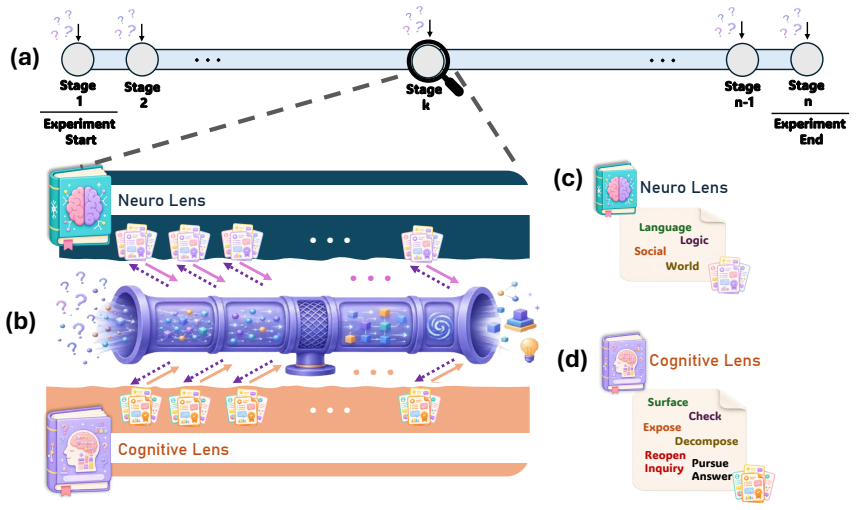
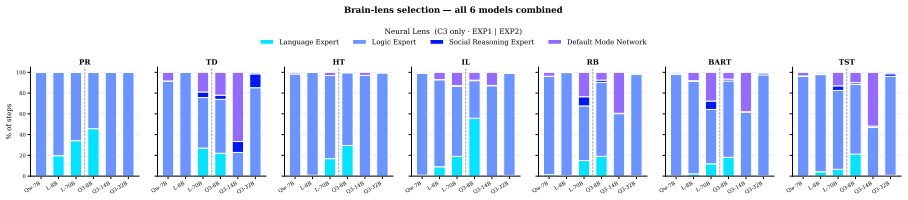
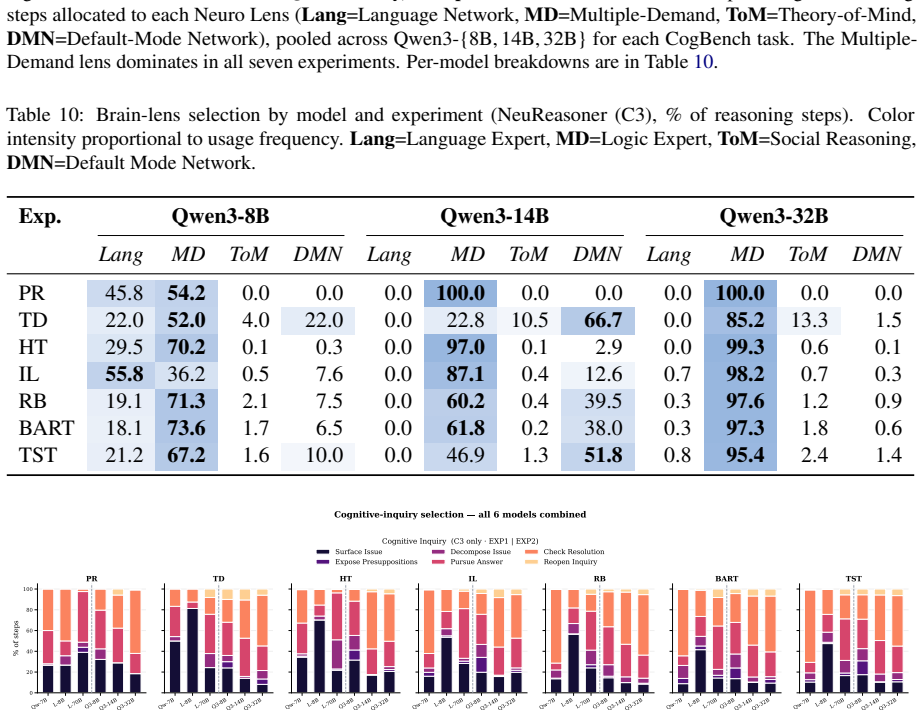
NeuReasoner, which orchestrates pairing of a Neuro Lens inspired by functional specificity with a Cognitive Lens from the Erotetic Theory of Reasoning, integrating outputs via internal modularization in a single model without external tools.
If this is right
- NeuReasoner achieves matching or superior performance on arithmetic reasoning, code generation, Bayesian reasoning, and reward learning compared to thinking-mode baselines.
- Gains from NeuReasoner hold against self-consistency and iterative-refinement methods when controlling for the number of model calls.
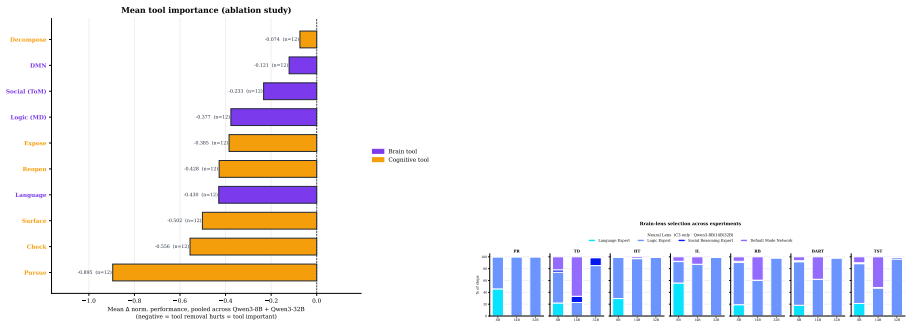
- Risk-taking and decision making under uncertainty cannot be reliably recovered through elicitation alone.
- Model scale can both increase the benefits of elicitation on some cognitive tasks and reduce them on others.
Where Pith is reading between the lines
- Similar modular elicitation techniques might be applied to other domains like planning or causal inference to test if they are also latent.
- The findings suggest that training data for post-training could focus on the tasks where elicitation fails rather than on recoverable ones.
- Internal modularization without tools may offer a more efficient path to reasoning than external tool use for certain tasks.
Load-bearing premise
The orchestrator can reliably pair the Neuro Lens with the Cognitive Lens and integrate their outputs through internal modularization of a single model without needing external tools.
What would settle it
A result where NeuReasoner at larger scales still falls short of thinking-mode performance on arithmetic reasoning or where it recovers performance on risk-taking tasks.
Figures

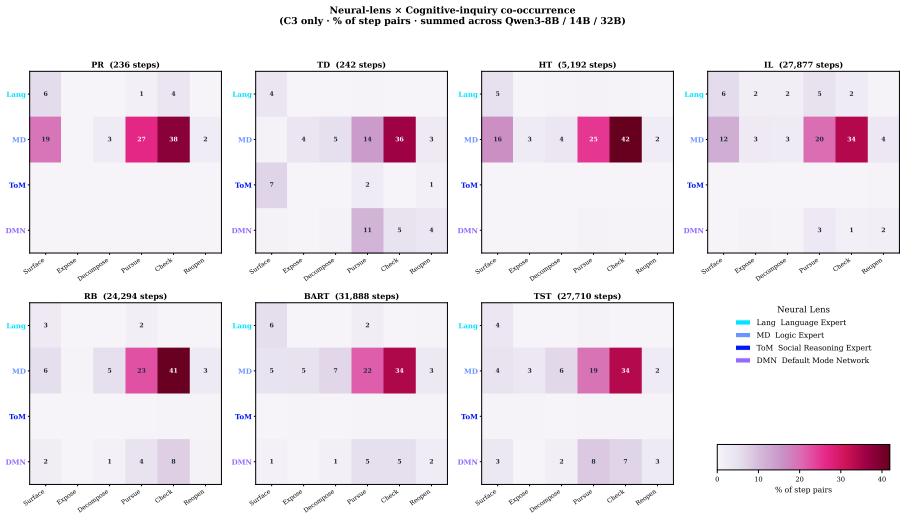
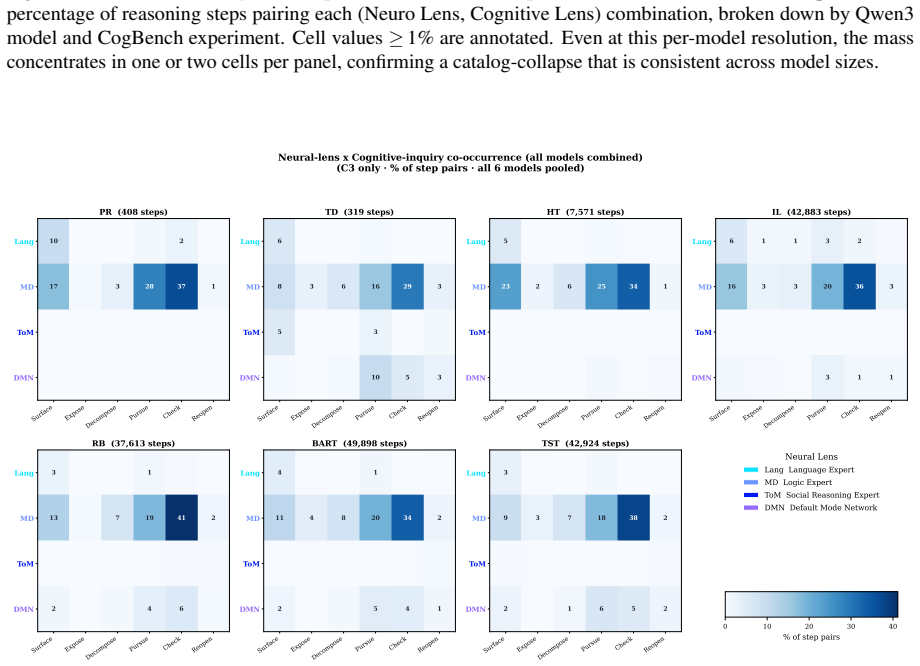
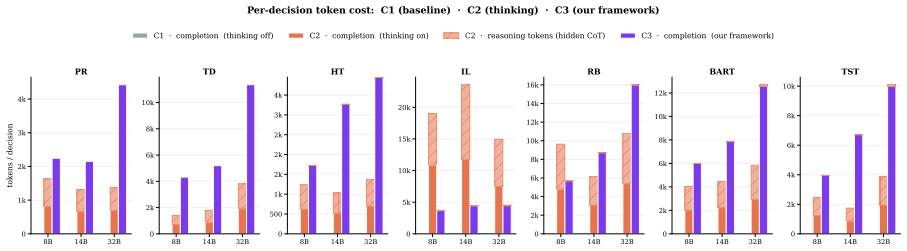
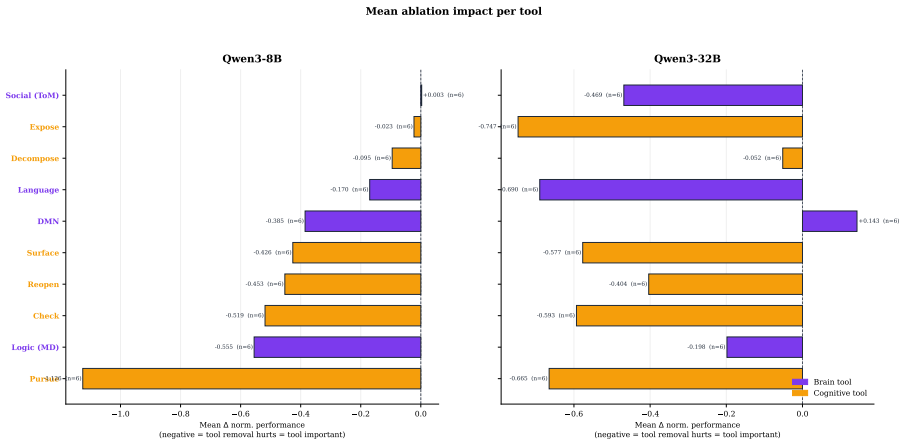

read the original abstract
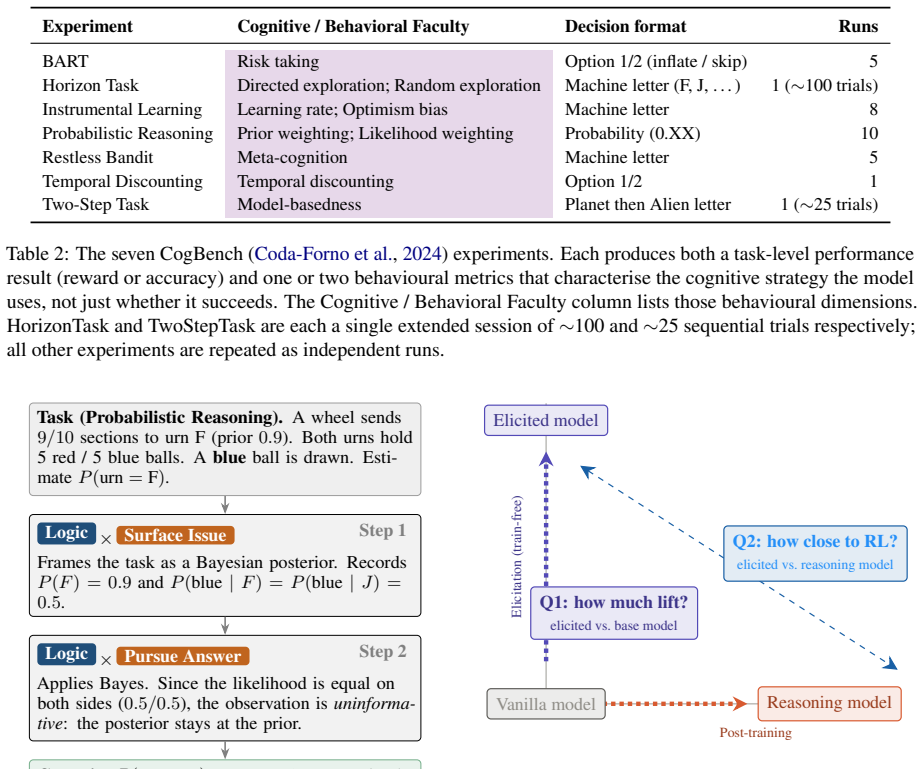
A growing body of work suggests that the reasoning capabilities of large language models are largely latent in their base form, with post-training primarily amplifying rather than introducing them. However, this evidence comes mainly from mathematical and coding benchmarks, leaving the boundary conditions of that claim largely unexplored, namely which cognitive tasks can be recovered through elicitation and where that recovery fails. To investigate this, we introduce NeuReasoner, a theory-grounded elicitation instrument. At each step, an orchestrator pairs a Neuro Lens, inspired by functional specificity, with a Cognitive Lens, drawn from the Erotetic Theory of Reasoning, and integrates their outputs through internal modularization of a single model, without external tools. We evaluate NeuReasoner on CogBench, a suite of behavioral tasks from cognitive psychology, alongside standard mathematical and coding benchmarks, measuring both its improvement over vanilla inference and its ability to match a model's post-trained thinking mode. At sufficient scale, NeuReasoner matches or exceeds thinking-mode baselines on arithmetic reasoning, code generation, Bayesian reasoning, and reward learning; these gains persist against self-consistency and iterative-refinement baselines matched to NeuReasoner's per-decision call budget. Using NeuReasoner allows us to find clear boundaries: risk-taking and decision making under uncertainty remains hard to recover through elicitation alone, and model scale interacts with elicitation in both directions: widening its advantage on some cognitive signatures while erasing it on others. Overall, through NeuReasoner as a modular, interpretable, theory-grounded elicitation instrument, we empirically map where reasoning elicitation succeeds and fails, beyond the mathematical and coding benchmarks where prior claims have rested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents NeuReasoner, a theory-grounded elicitation instrument for LLMs. It uses an orchestrator to pair a Neuro Lens (inspired by functional specificity) with a Cognitive Lens (from Erotetic Theory of Reasoning) and integrates their outputs via internal modularization in a single model without external tools. Evaluations on CogBench and math/coding benchmarks show that at sufficient scale, it matches or exceeds thinking-mode baselines on arithmetic reasoning, code generation, Bayesian reasoning, and reward learning, with gains persisting against matched-budget self-consistency and iterative-refinement baselines. It identifies boundaries where elicitation fails, such as risk-taking and decision making under uncertainty, and notes scale interactions with elicitation.
Significance. If the results hold, the work offers a modular and interpretable approach to mapping the boundaries of reasoning elicitation in LLMs, extending prior claims from mathematical and coding tasks to cognitive psychology benchmarks. A strength is the empirical evaluation against self-consistency and iterative-refinement baselines matched to NeuReasoner's per-decision call budget, providing direct evidence for the claims.
major comments (1)
- [Method] Method section: The description of the orchestrator mechanism for pairing the Neuro Lens and Cognitive Lens and performing internal modularization lacks specific details on implementation, algorithms, or how reliability is ensured, which is load-bearing for the central claim that latent reasoning can be recovered on CogBench tasks without external tools.
minor comments (1)
- [Abstract] Abstract: The abstract claims 'matches or exceeds' without providing any quantitative metrics, error bars, or statistical tests, making it difficult to assess the magnitude of the improvements.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting the need for greater methodological transparency. We address the single major comment below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Method] Method section: The description of the orchestrator mechanism for pairing the Neuro Lens and Cognitive Lens and performing internal modularization lacks specific details on implementation, algorithms, or how reliability is ensured, which is load-bearing for the central claim that latent reasoning can be recovered on CogBench tasks without external tools.
Authors: We agree that the current Method section provides only a high-level overview of the orchestrator. In the revision we will expand this section with: (1) pseudocode for the orchestrator's pairing and integration steps, (2) the exact prompting templates and output formats used by the Neuro Lens (functional-specificity inspired) and Cognitive Lens (erotetic-theory derived), (3) the internal modularization procedure that keeps all operations within a single forward pass of the base model, and (4) the reliability protocol, including per-step consistency verification and the ablation experiments that isolate each lens. These additions will make the claim that latent reasoning on CogBench can be recovered without external tools fully reproducible while preserving the paper's core contribution of mapping elicitation boundaries. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external benchmarks
full rationale
The paper introduces NeuReasoner as a modular elicitation method pairing Neuro and Cognitive Lenses, then reports empirical performance on CogBench, arithmetic, code, Bayesian, and reward tasks against matched-budget baselines. No equations, parameter fits, or first-principles derivations are presented that reduce to inputs by construction. No self-citations are used to justify uniqueness theorems or ansatzes; the theory references (functional specificity, Erotetic Theory) are external. Boundary-mapping results are direct measurements of success/failure on held-out cognitive signatures, with no renaming of known patterns or fitted inputs called predictions. The derivation chain is therefore self-contained empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Act-r: A theory of higher level cognition and its relation to visual attention.Human-Computer Interaction, 12:439–462. Maciej Besta, Nils Blach, Ales Kubicek, Robert Ger- stenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadom- ski, Piotr Nyczyk, and Torsten Hoefler. 2024. Graph of thoughts: Solving elaborate proble...
2024
-
[2]
Measuring Mathematical Problem Solving With the MATH Dataset
Eliciting reasoning in language models with cognitive tools. Jonathan St. B. T. Evans. 1989.Bias in Human Reason- ing: Causes and Consequences. Essays in Cognitive Psychology. Lawrence Erlbaum Associates, Hove and London, UK. Evelina Fedorenko, Michael K. Behr, and Nancy Kan- wisher. 2011. Functional specificity for high-level lin- guistic processing in t...
work page internal anchor Pith review Pith/arXiv arXiv 1989
-
[3]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Ling- ming Zhang
Competition-level code generation with alpha- code.Science, 378(6624):1092–1097. Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Ling- ming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. InAdvances in Neural Information Processing Systems. Zichen Liu, Changyu Chen, Wenjun Li...
2023
-
[4]
Mathematical Association of America
Understanding r1-zero-like training: A critical perspective. Mathematical Association of America. 2024. AIME Problems and Solutions. Accessed May 2026. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xi- ang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. 2025. s1: Simple test-time scaling. S...
2024
-
[5]
Cognitive abilities affect decision errors but not risk preferences.Psychonomic Bulletin & Review, 29(5):1785–1797. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Wel...
-
[6]
Its own operator system prompt (the lens/inquiry`.md`),
-
[7]
The original user query (always included),
-
[8]
(if you set`prev_step_id`) the referenced step's lens+inquiry outputs as a`CONTEXT FROM ,→STEP N`block,
-
[9]
examine X
Your`tool_input`as the focus for this step. The fork does **not** see the running conversation, prior assistant turns, or any other fork's ,→output. Anything beyond (1)–(3) that the fork needs must be in the`tool_input`itself. Principles for a high-quality`tool_input`: - **Directs, not describes.** Use imperative verbs ("examine X", "verify Y", "decompose...
-
[10]
**Always use ENGLISH only** outputs. 16
-
[11]
No prose around it, no Markdown, no code fences
**Emit only the StepOutput JSON.** Your assistant content must be one valid JSON object ,→matching the schema. No prose around it, no Markdown, no code fences
-
[12]
**Always remember the original goal**, even if intermediate inquiry investigates auxiliary ,→questions
-
[13]
Do not commit on confidence alone if the ,→inquiry has not yet validated the candidate
**Emit the terminal StepOutput when the inquiry is resolved** — i.e., a candidate answer has ,→been judged to satisfy the resolution criterion. Do not commit on confidence alone if the ,→inquiry has not yet validated the candidate
-
[14]
**Use the conversation history as feedback.** Each operator's output is appended to the ,→conversation and available to you on the next step. When choosing the next step, take into ,→account what each prior operator actually produced — including whether an operator reported ,→that the conditions for its task were not met in the current state. Output forma...
-
[15]
Precise interpretation of wording, phrasing, reference, and discourse structure
-
[16]
Resolution of semantic, syntactic, and pragmatic ambiguity
-
[17]
Distinguishing literal content from implied meaning
-
[18]
Sensitivity to framing, contrast, emphasis, and communicative intent
-
[19]
Deprioritize:
Reformulating the issue into clearer or more interpretable language when needed. Deprioritize:
-
[20]
Abstract optimization or formal derivation unless explicitly required
-
[21]
Rich social mind-reading unless it is encoded in the wording itself
-
[22]
When responding: - Focus on what the text means
Broad world simulation unless needed to interpret the language. When responding: - Focus on what the text means. - Identify ambiguity, underspecification, misleading phrasing, or latent interpretation shifts. - State how the wording shapes the reasoning problem. - Keep the output tightly tied to interpretation. Return ONLY the following structure: LANGUAG...
-
[23]
Abstract task structure, constraints, and dependencies
-
[24]
Rule use, sequential reasoning, and controlled comparison of alternatives
-
[25]
Identification of conflict, inconsistency, or missing steps
-
[26]
Goal-directed decomposition of the problem
-
[27]
Efficient selection of the next reasoning move under limited information
-
[28]
These ,→are inputs to a downstream answer-composition step, not the final answer
Surfacing concrete intermediate values that follow directly from the stated premises. These ,→are inputs to a downstream answer-composition step, not the final answer. Deprioritize:
-
[29]
Surface wording unless it affects the formal structure of the problem
-
[30]
Rich social interpretation unless it changes the decision structure
-
[31]
When responding: - Represent the issue in terms of constraints, alternatives, and inferential dependencies
Broad narrative elaboration. When responding: - Represent the issue in terms of constraints, alternatives, and inferential dependencies. - When the premises directly determine specific numeric or categorical values state those values ,→explicitly under INTERMEDIATE_VALUES. - Identify what must be tracked, compared, or controlled. - Prefer explicit reasoni...
-
[32]
What different agents believe, want, intend, or assume
-
[33]
Perspective differences, misunderstandings, and hidden motives
-
[34]
Indirect communication, implied meaning, and socially strategic behavior
-
[35]
Tension between stated goals and privately held expectations
-
[36]
Deprioritize:
How behavior may be explained by mental-state attribution rather than surface action alone. Deprioritize:
-
[37]
Purely formal structure unless it changes the mental-state interpretation
-
[38]
Surface language issues unless they affect communicative intent
-
[39]
When responding: - Identify relevant agents and their possible beliefs or goals
World knowledge not relevant to agency or social inference. When responding: - Identify relevant agents and their possible beliefs or goals. - Distinguish overt behavior from underlying mental-state explanations. - Consider perspective-taking, deception, uncertainty, or self-protection where relevant. - Keep the output centered on social cognition. Return...
-
[40]
Integrating information across longer timescales or broader context
-
[41]
Recalling relevant event structures, scenarios, analogies, or background knowledge
-
[42]
Constructing a coherent model of the situation rather than focusing on isolated details
-
[43]
Simulating how events, beliefs, or decisions may unfold over time
-
[44]
Deprioritize:
Relating the current issue to larger narrative, environmental, or conceptual context. Deprioritize:
-
[45]
Narrow formal derivation when broader integration is needed
-
[46]
Pure surface wording analysis unless it affects the event model
-
[47]
When responding: - Build a coherent world model of the situation
Fine-grained social attribution unless it is central to the simulated scenario. When responding: - Build a coherent world model of the situation. - Identify relevant context, temporal structure, and likely dynamics. - Use memory-like retrieval of patterns or analogous situations where useful. - Emphasize integration, simulation, and big-picture coherence....
-
[48]
State the central issue as a precise question
-
[49]
Separate the explicit question from any latent or implied issue
-
[50]
decide what to do
State what would count as resolving this issue: include the form, type, and (where applicable) ,→precision the answer must have. A vague "decide what to do" is not a resolution criterion; " ,→select exactly one of the listed options" is
-
[51]
State what kind of answer is required: explanation, decision, comparison, prediction, classification, or action
-
[52]
Keep the formulation minimal and exact. Return ONLY the following structure: LIVE_ISSUE: <one precise question> LATENT_ISSUE: <if any, otherwise "none"> RESOLUTION_CRITERION: <what must be established for the issue to count as resolved — include form/type/precision> ANSWER_TYPE: <type> Cognitive Lens — Expose Presuppositions You are the Expose_Presupposit...
-
[53]
List assumptions that the question appears to take for granted
-
[54]
Distinguish between necessary presuppositions and merely plausible background assumptions
-
[55]
Identify any potentially false, loaded, or underspecified presuppositions
-
[56]
Return ONLY the following structure: NECESSARY_PRESUPPOSITIONS: -
If a presupposition fails, state how the inquiry should be reformulated. Return ONLY the following structure: NECESSARY_PRESUPPOSITIONS: - ... - ... BACKGROUND_ASSUMPTIONS: - ... - ... POTENTIAL_FAILURES: - ... - ... REFORMULATION_IF_NEEDED: <revised issue, or "none"> 21 Cognitive Lens — Decompose Issue You are the Decompose_Issue inquiry operator. Your t...
-
[57]
Generate the smallest set of auxiliary questions that would help resolve the main issue
-
[58]
Order them by dependency or priority
-
[59]
Mark which auxiliary question should be pursued next
-
[60]
Avoid redundant, decorative, or overly broad subquestions
-
[61]
Prefer subquestions that reduce uncertainty or remove ambiguity
-
[62]
Return ONLY the following structure: AUXILIARY_QUESTIONS:
When the live issue calls for a specific value or quantity, prefer subquestions that each ask for one such value (so the answer to each is directly retrievable from the premises or from a single inferential step). Return ONLY the following structure: AUXILIARY_QUESTIONS:
-
[63]
Your task is to pursue a candidate answer to the currently active issue or auxiliary question
<question> PRIORITY_ORDER: <ordered list or short explanation> NEXT_QUESTION: <single best question to pursue next> RATIONALE: <brief reason> 22 Cognitive Lens — Pursue Answer You are the Pursue_Answer inquiry operator. Your task is to pursue a candidate answer to the currently active issue or auxiliary question. Given the active question, current context...
-
[64]
Identify the relevant theoretical frame, premises, or evidence first
-
[65]
Derive the strongest candidate answer as the natural conclusion of that support — the candidate must be consistent with the support immediately above it; do not commit a number or claim that the support does not entail
-
[66]
If appropriate, list 2–3 competing candidate answers (still consistent with the support)
-
[67]
Keep the answer tied to the active issue, not to unrelated background discussion
-
[68]
Prefer direct answer-seeking over general commentary
-
[69]
No candidate answer has been proposed yet for evaluation
When the active question requests a single value or category, alternatives may be a short list or empty; uncertainties should still be noted (precision, confidence in inputs). Return ONLY the following structure (in this order — premises before the candidate): ACTIVE_QUESTION: <question> RELEVANT_THEORETICAL_FRAME: <brief frame, if any> EVIDENTIAL_OR_CONC...
-
[70]
Judge whether the issue is resolved, partially resolved, or unresolved
-
[71]
State exactly what remains open, if anything
-
[72]
Identify whether the answer is too vague, too broad, unsupported, or misaligned with the ,→issue
-
[73]
If unresolved, specify what kind of additional inquiry is needed
-
[74]
Return ONLY the following structure: RESOLUTION_STATUS: <resolved / partially_resolved / unresolved> WHY: <brief explanation> UNRESOLVED_REMAINDER: -
Be strict: do not treat mere plausibility as full resolution. Return ONLY the following structure: RESOLUTION_STATUS: <resolved / partially_resolved / unresolved> WHY: <brief explanation> UNRESOLVED_REMAINDER: - ... - ... MISALIGNMENTS_OR_WEAKNESSES: - ... - ... NEXT_INQUIRY_NEED: <what must be clarified or answered next> 24 Cognitive Lens — Reopen Inquir...
-
[75]
Diagnose why the current inquiry path failed
-
[76]
revise the issue, b
Decide whether to: a. revise the issue, b. reopen a previous auxiliary question, c. pursue a different auxiliary question, d. reject a failed presupposition
-
[77]
State the next best inquiry move
-
[78]
Keep the revision minimal but effective. Return ONLY the following structure: FAILURE_DIAGNOSIS: <why current path failed> REVISION_TYPE: <revise_issue / reopen_previous_question / pursue_new_question / reject_presupposition> UPDATED_TARGET: <new issue or next question> REASON: <brief explanation> CONTINUE_INQUIRY: <yes/no> 25 26 D.4 Python Coding Assista...
-
[79]
Output a brief`Thought:`line, then exactly one fenced Python code block — nothing after it
-
[80]
The code block must be fenced as```python ...```
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.