Making Sense of Touch from the Child's View for Contrastive Learning
Pith reviewed 2026-07-01 06:25 UTC · model grok-4.3
The pith
A structured coding system for baby-centric touch events produces a 264k-clip dataset used to pretrain models probing how infants learn visual concepts from touch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce a structured coding system for baby-centric touch events that produces a dataset of 264k two-second clips; pretraining developmentally grounded contrastive models on this dataset then yields insights into the contribution of touch to infant visual concept learning.
What carries the argument
The structured coding system for baby-centric touch events, which labels interactions to create labeled clips for contrastive pretraining.
If this is right
- Touch events supply structured signals that support learning of visual concepts in the pretrained models.
- The dataset allows quantification of how much babies may rely on touch versus other senses for visual learning.
- Insights from the models can refine accounts of multimodal integration during infant development.
- The same coding approach can generate further data for testing specific touch-visual pairings.
Where Pith is reading between the lines
- The method could be adapted to code other infant senses such as sound or movement to study broader sensory contributions.
- If the models succeed on downstream visual tasks, it would support using touch-derived pretraining for general representation learning.
- Validation against real infant looking-time or grasping data would test whether the model insights match observed behavior.
- The dataset size suggests scaling similar child-centric labeling to other modalities could produce new developmental benchmarks.
Load-bearing premise
The proposed coding system accurately identifies touch events that are relevant to babies learning visual concepts.
What would settle it
Showing that models pretrained on the coded touch clips perform no better than baselines without touch data on visual concept tasks would falsify the claim that the dataset yields valid insights into baby learning.
Figures


read the original abstract
Is the sense of touch a mechanism for human babies' learning of visual concepts? If so, can we quantify its importance, and to what extent do babies rely on their sense of touch for visual learning? To approach these questions in a principled way, we propose a structured coding system for baby-centric touch events, yielding a dataset of 264k two-second clips of touch events coded according to this system. Using this dataset, we pretrain developmentally grounded models that reveal promising insights into the nature of baby learning from touch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a structured coding system for baby-centric touch events from video data, resulting in a dataset of 264k two-second clips. These data are then used to pretrain contrastive learning models that the authors claim provide insights into how human infants learn visual concepts through touch.
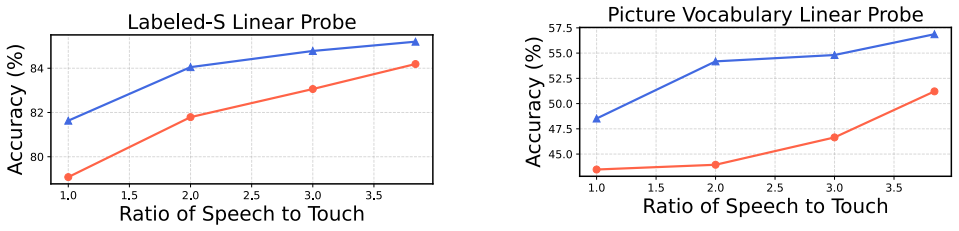
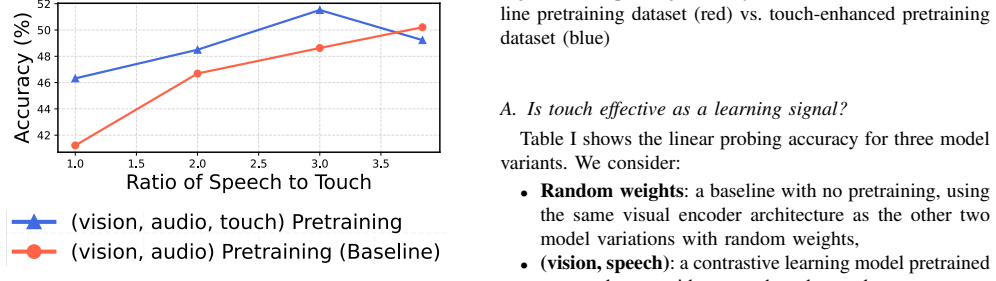
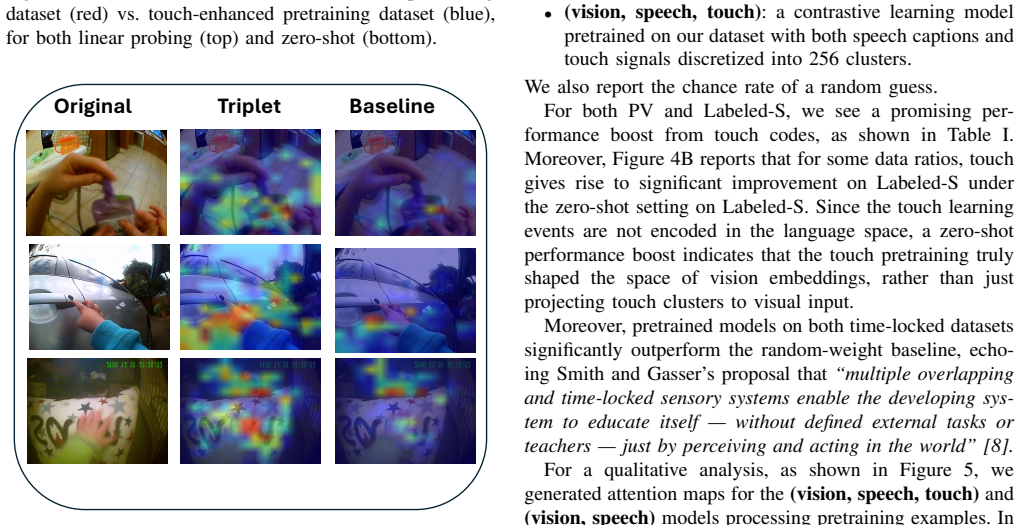
Significance. If the coding system proves reliable and the models yield validated, falsifiable connections to infant behavior, the work would contribute a large-scale dataset and developmentally grounded pretraining approach to multimodal learning research. The scale of the dataset (264k clips) is a clear strength for contrastive learning experiments.
major comments (1)
- [Abstract] Abstract: the central claim that the coding system and resulting models 'reveal promising insights into the nature of baby learning from touch' is not supported by any described validation, error analysis, or comparison to human developmental data; without these, the link between the touch-event coding and visual-concept learning remains an untested assumption.
Simulated Author's Rebuttal
We thank the referee for highlighting this important point about the abstract. We agree the current phrasing overreaches relative to the validation presented and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the coding system and resulting models 'reveal promising insights into the nature of baby learning from touch' is not supported by any described validation, error analysis, or comparison to human developmental data; without these, the link between the touch-event coding and visual-concept learning remains an untested assumption.
Authors: We acknowledge the concern. The manuscript introduces the coding system and 264k-clip dataset as a new resource and demonstrates its use for contrastive pretraining, but does not include direct validation against infant behavioral data or error analysis linking the touch codes to specific visual-concept acquisition. In the revised version we will (1) rephrase the abstract to describe the models as providing 'initial explorations that suggest potential directions for studying touch-based visual learning' rather than 'revealing promising insights,' (2) add an explicit limitations paragraph noting the absence of such validation, and (3) outline planned future comparisons to developmental benchmarks. These changes will be made without altering the core technical contributions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core contribution is the proposal of a structured coding system for baby-centric touch events, the resulting 264k-clip dataset, and subsequent model pretraining. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the provided abstract or described claims. The process is a data-collection and modeling pipeline without self-referential reductions where outputs are forced by construction from inputs. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Piaget and M
J. Piaget and M. T. Cook,The origins of intelligence in children. WW Norton & Company, 1952
1952
-
[2]
J. J. Gibson,The ecological approach to visual perception: classic edition. Psychology press, 2014
2014
-
[3]
Thelen and L
E. Thelen and L. B. Smith,A dynamic systems approach to the development of cognition and action. MIT press, 1994
1994
-
[4]
Systems in devel- opment: motor skill acquisition facilitates three-dimensional object completion
K. C. Soska, K. E. Adolph, and S. P. Johnson, “Systems in devel- opment: motor skill acquisition facilitates three-dimensional object completion.”Developmental psychology, vol. 46, no. 1, p. 129, 2010
2010
-
[5]
Self-generated variability in object images predicts vocabulary growth,
L. K. Slone, L. B. Smith, and C. Yu, “Self-generated variability in object images predicts vocabulary growth,”Developmental science, vol. 22, no. 6, p. e12816, 2019
2019
-
[6]
Gershkoff-Stowe and D
L. Gershkoff-Stowe and D. H. Rakison,Building object categories in developmental time. Psychology Press, 2005
2005
-
[7]
Reentry: a key mechanism for integration of brain function,
G. M. Edelman and J. A. Gally, “Reentry: a key mechanism for integration of brain function,”Frontiers in integrative neuroscience, vol. 7, p. 63, 2013
2013
-
[8]
The development of embodied cognition: Six lessons from babies,
L. B. Smith and M. Gasser, “The development of embodied cognition: Six lessons from babies,”Artificial Life, vol. 11, no. 1-2, pp. 13–29, 2005
2005
-
[9]
Grounded language acquisition through the eyes and ears of a single child,
W. K. V ong, W. Wang, A. E. Orhan, and B. M. Lake, “Grounded language acquisition through the eyes and ears of a single child,” Science (New York, N.Y.), vol. 383, no. 6682, pp. 504–511, Feb. 2024
2024
-
[10]
BabyVLM: Data-Efficient Pretraining of VLMs Inspired by Infant Learning,
S. Wang, A. Chandra, A. Liu, V . Saligrama, and B. Gong, “BabyVLM: Data-Efficient Pretraining of VLMs Inspired by Infant Learning,” Oct. 2025, arXiv:2504.09426 [cs]. [Online]. Available: http://arxiv.org/abs/2504.09426
-
[11]
S. Wang, W. Wang, Z. Wang, M. Whitton, M. Wakeham, A. Chandra, J. Huang, P. Zhu, H. Chen, D. Li, J. Li, S. Li, A. Zagula, A. Zhao, A. Zhu, S. Nakamura, Y . Yamamoto, J. J. Yokono, A. Mueller, B. A. Plummer, K. Saenko, V . Saligrama, and B. Gong, “BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models,” Dec. 20...
-
[12]
SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded From the Infant’s Perspective,
J. Sullivan, M. Mei, A. Perfors, E. Wojcik, and M. C. Frank, “SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded From the Infant’s Perspective,”Open Mind, vol. 5, pp. 20–29, May
-
[13]
Available: https://doi.org/10.1162/opmi a 00039
[Online]. Available: https://doi.org/10.1162/opmi a 00039
-
[14]
B. Long, R. Z. Sparks, V . Xiang, S. Stojanov, Z. Yin, G. E. Keene, A. W. M. Tan, S. Y . Feng, C. Zhuang, V . A. Marchman, D. L. K. Yamins, and M. C. Frank, “The BabyView dataset: High-resolution egocentric videos of infants’ and young children’s everyday experiences,” Jul. 2025, arXiv:2406.10447 [cs]. [Online]. Available: http://arxiv.org/abs/2406.10447
-
[15]
Stimulus structures and mental representations in expert comprehension of computer programs,
S. J. Lederman and R. L. Klatzky, “Hand movements: A window into haptic object recognition,”Cognitive Psychology, vol. 19, no. 3, pp. 342–368, Jul. 1987. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/0010028587900089
-
[16]
Gemini: A Family of Highly Capable Multimodal Models
G. D. Team, “Gemini: A family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacyet al., “Learning transferable visual models from natural language supervision,” inICML, 2021
2021
-
[18]
Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,” inICML, 2022
2022
-
[19]
Some methods of classification and analysis of multivariate observations,
J. B. McQueen, “Some methods of classification and analysis of multivariate observations,” inProc. of 5th Berkeley Symposium on Math. Stat. and Prob., 1967, pp. 281–297
1967
-
[20]
Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,
H. Akbari, L. Yuan, R. Qian, W.-H. Chuang, S.-F. Chang, Y . Cui, and B. Gong, “Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[21]
Nih baby toolbox® methodology and norms development,
Y . C. Han, E. M. Dworak, M. Mansolf, H. Adam, L. Yao, M. A. Novack, S. Pila, R. M. Flynn, A. M. Flagg, V . Ustsinovichet al., “Nih baby toolbox® methodology and norms development,”Infant Behavior and Development, vol. 80, p. 102117, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.