GSRQ: Gain-Shape Residual Quantization for Sub-1-bit KV Cache
Pith reviewed 2026-07-02 15:53 UTC · model grok-4.3
The pith
Gain-Shape Residual Quantization fixes directional loss in KV cache compression by replacing standard k-means with a gain-shape variant inside the residual pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
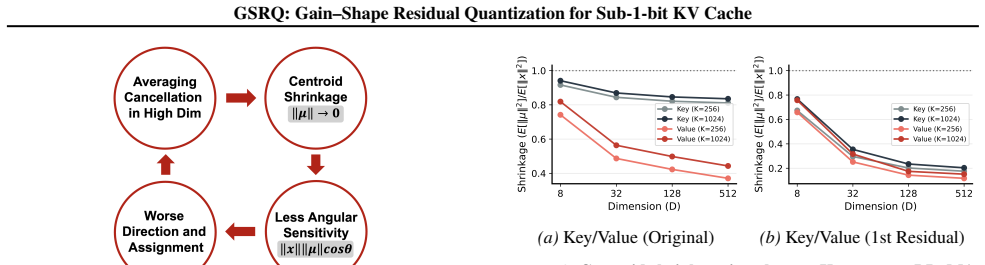
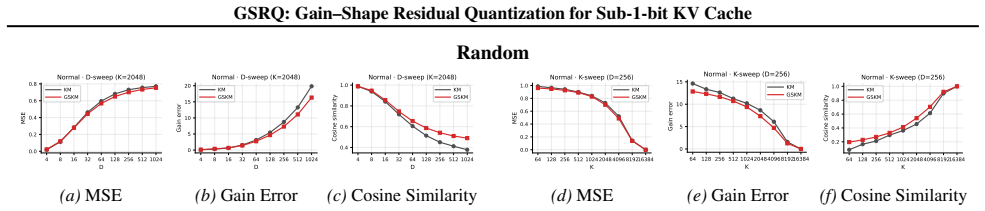
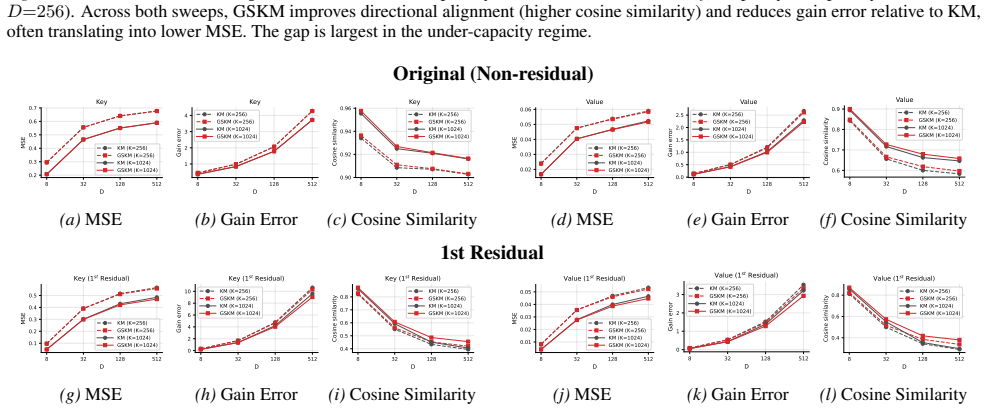
Standard l2 k-means induces centroid shrinkage that degrades the angular term in the distortion metric for KV cache vectors; Gain-Shape K-means separates gain and shape to restore directional fidelity without raising l2 error, and its weighted use inside a residual quantization pipeline yields GSRQ, which raises average LongBench accuracy from 11.34 to 33.54 at 1 bit on LLaMA-3-8B.
What carries the argument
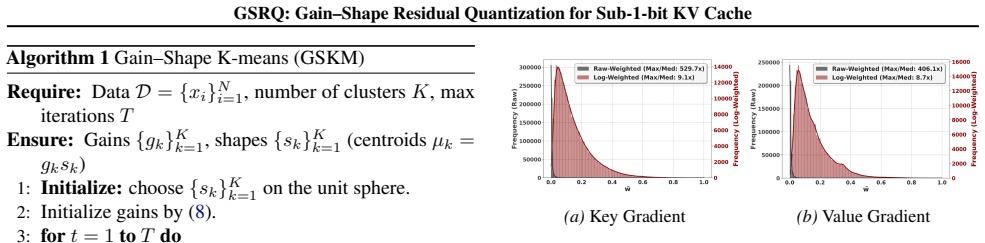
Gain-Shape K-means (GSKM), a replacement for l2 k-means that computes separate gain and shape centroids to improve angular alignment in the quantization of KV cache entries.
If this is right
- At 1-bit KV cache the method lifts average LongBench accuracy by 22.20 points over VQLLM.
- Accuracy gains appear across multiple bit rates below 2 bits on LLaMA-3-8B.
- GSKM functions as a direct substitute for k-means inside any residual quantization pipeline for KV caches.
Where Pith is reading between the lines
- The same gain-shape adjustment could be tested on weight quantization or activation compression where directional structure also dominates.
- If the improvement persists at 0.5 bits it would directly enable context windows several times longer on fixed hardware budgets.
- Residual pipelines using GSKM might be combined with existing outlier-handling techniques to push effective bit rates even lower.
Load-bearing premise
Centroid shrinkage from Euclidean averaging is the dominant source of directional error in KV-cache vector quantization, and switching to gain-shape centroids removes that error without creating offsetting problems downstream in the residual chain.
What would settle it
Run the same LongBench evaluation at 1 bit on a different model family; if the 22-point gap over VQLLM vanishes while measured angular alignment stays unchanged, the directional-preservation account does not hold.
Figures
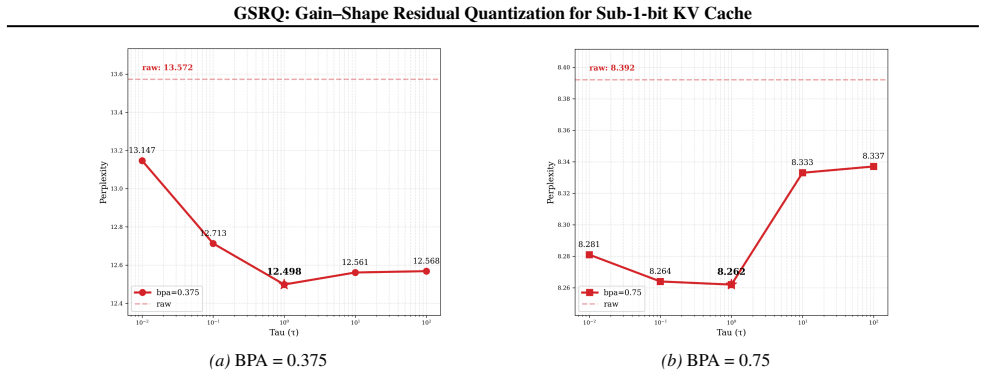
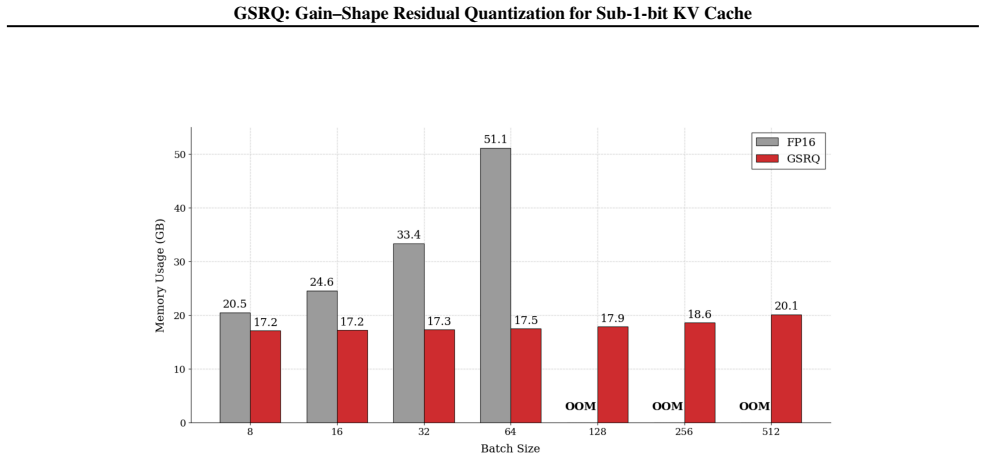
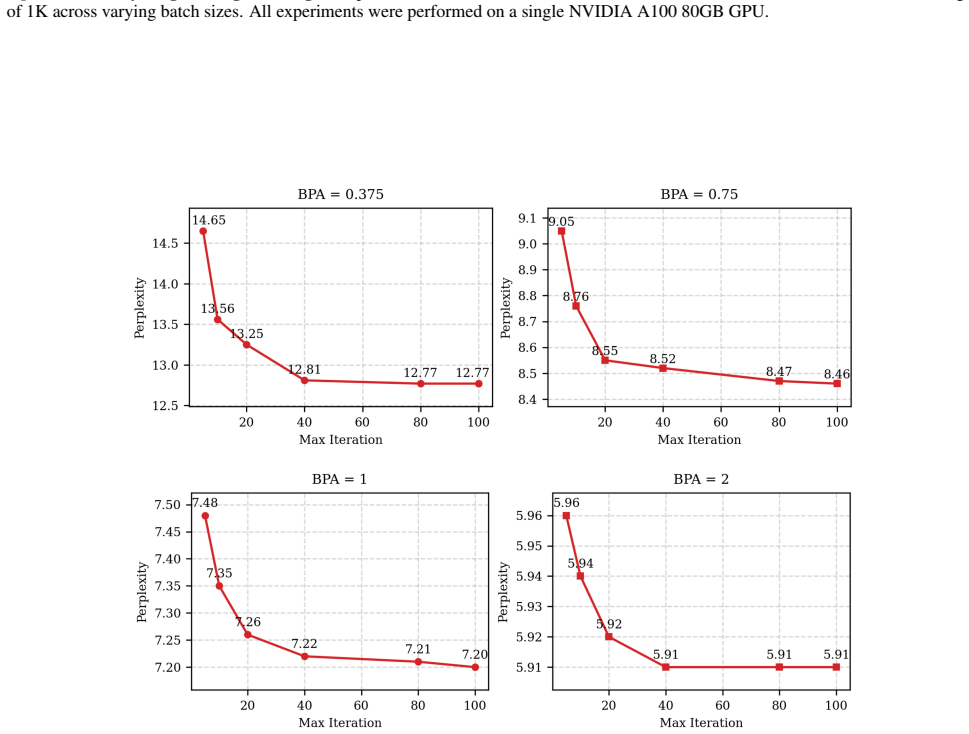
read the original abstract
The deployment of Large Language Models (LLMs) with extended context windows is increasingly constrained by the linear growth of Key-Value (KV) cache memory. Vector Quantization (VQ), particularly Residual Quantization (RQ), is a promising approach for pushing KV cache storage toward the sub-1-bit regime by progressively encoding residuals with small codebooks. However, most VQ methods still rely on standard $\ell_2$ $K$-means as the core codebook-learning primitive. We identify a subtle high-dimensional issue of this primitive: Euclidean centroid averaging can induce centroid shrinkage, which weakens the angular alignment term in the $\ell_2$ distortion and makes directional preservation harder. To address this issue, we propose Gain-Shape $K$-means (GSKM), a drop-in replacement for $K$-means that improves directional fidelity while matching, and in some regimes improving, $\ell_2$ distortion. We then build Gain-Shape Residual Quantization (GSRQ) by incorporating a weighted extension of GSKM into an RQ pipeline. On LLaMA-3-8B, GSRQ substantially improves over strong KV cache quantization baselines across bit rates. At 1-bit, it improves the average accuracy across LongBench tasks from 11.34 to 33.54, a gain of 22.20 percentage points over VQLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies centroid shrinkage in standard ℓ2 K-means as a high-dimensional pathology that weakens directional preservation in KV-cache vector quantization. It proposes Gain-Shape K-means (GSKM) as a drop-in replacement and incorporates a weighted version into a residual quantization pipeline to form GSRQ. On LLaMA-3-8B, GSRQ is reported to deliver large accuracy gains over baselines such as VQLLM, including an average LongBench improvement from 11.34 to 33.54 at 1-bit (a 22.20 pp gain).
Significance. If the reported gains prove robust and causally attributable to GSKM rather than other pipeline choices or tuning, the work would constitute a meaningful engineering advance for sub-1-bit KV-cache compression, directly addressing memory bottlenecks in long-context LLM inference.
major comments (4)
- [Abstract] Abstract: the 22.20 pp LongBench gain is stated as a point estimate with no error bars, no mention of multiple random seeds, and no dataset/task breakdown, making it impossible to judge whether the improvement is statistically reliable or sensitive to hyper-parameter choices.
- [§3] §3 (motivation): the assertion that centroid shrinkage is the dominant failure mode for directional fidelity in KV tensors is unsupported by any quantitative measurement (e.g., per-stage cosine-similarity or norm-error statistics) on actual Key or Value activations.
- [§4] §4 (experiments): no ablation is presented that replaces only the K-means primitive with GSKM while freezing all other components of the GSRQ pipeline (codebook size, weighting, residual stages, etc.), so the attribution of the 22 pp jump to the proposed gain-shape reformulation remains unsecured.
- [Table 2 (LongBench)] Table reporting LongBench results: average accuracy figures are given without variance across runs or statistical significance tests, and the baseline VQLLM numbers are not accompanied by the same hyper-parameter search protocol used for GSRQ.
minor comments (2)
- [§2] The notation distinguishing gain and shape vectors in the GSKM objective could be introduced earlier and used consistently.
- [§4.1] LongBench task list and exact prompt templates should be stated explicitly rather than referenced only by name.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results and strengthen the attribution of gains to the proposed method. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 22.20 pp LongBench gain is stated as a point estimate with no error bars, no mention of multiple random seeds, and no dataset/task breakdown, making it impossible to judge whether the improvement is statistically reliable or sensitive to hyper-parameter choices.
Authors: We agree that the abstract would benefit from additional statistical context. In the revision we will report error bars computed over multiple random seeds and add a per-task breakdown (either in the main text or appendix) while retaining the average for brevity. revision: yes
-
Referee: [§3] §3 (motivation): the assertion that centroid shrinkage is the dominant failure mode for directional fidelity in KV tensors is unsupported by any quantitative measurement (e.g., per-stage cosine-similarity or norm-error statistics) on actual Key or Value activations.
Authors: We accept that direct quantitative evidence on KV activations would strengthen the motivation section. We will insert per-stage cosine-similarity and norm-error statistics computed on actual Key and Value tensors from LLaMA-3-8B to document the shrinkage phenomenon. revision: yes
-
Referee: [§4] §4 (experiments): no ablation is presented that replaces only the K-means primitive with GSKM while freezing all other components of the GSRQ pipeline (codebook size, weighting, residual stages, etc.), so the attribution of the 22 pp jump to the proposed gain-shape reformulation remains unsecured.
Authors: This is a valid concern for causal attribution. We will add an ablation that substitutes only the K-means primitive with GSKM while holding codebook size, weighting, residual stages, and all other pipeline choices fixed, thereby isolating the contribution of the gain-shape reformulation. revision: yes
-
Referee: [Table 2 (LongBench)] Table reporting LongBench results: average accuracy figures are given without variance across runs or statistical significance tests, and the baseline VQLLM numbers are not accompanied by the same hyper-parameter search protocol used for GSRQ.
Authors: We will augment Table 2 with run-to-run variance and statistical significance tests. We will also clarify the experimental protocol to confirm that VQLLM was re-tuned under a search budget comparable to that used for GSRQ; any residual differences will be explicitly noted. revision: partial
Circularity Check
No significant circularity; derivation is self-contained empirical engineering.
full rationale
The paper identifies centroid shrinkage in ℓ2 K-means as a directional issue, proposes GSKM as a drop-in replacement, and incorporates a weighted extension into an RQ pipeline to form GSRQ. Performance deltas (e.g., LongBench accuracy at 1-bit) are reported as empirical outcomes on LLaMA-3-8B. No equations, self-citations, or fitted-parameter renamings are shown that reduce any claim to its inputs by construction. The method is presented as an independent algorithmic change whose validity rests on external benchmarks rather than a closed loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Euclidean centroid averaging in high dimensions induces centroid shrinkage that weakens the angular term in ℓ2 distortion
Reference graph
Works this paper leans on
-
[1]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
H _2 O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author =. arXiv preprint arXiv:2306.14048 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2305.17118 , year =
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time , author =. arXiv preprint arXiv:2305.17118 , year =
-
[3]
International Conference on Learning Representations (ICLR) , year =
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations (ICLR) , year =
-
[4]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[5]
arXiv preprint arXiv:2401.18079 , year =
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization , author =. arXiv preprint arXiv:2401.18079 , year =
-
[6]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI-25) , year =
RotateKV: Accurate and Robust 2-Bit KV Cache Quantization for LLMs via Outlier-Aware Adaptive Rotations , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI-25) , year =
-
[7]
arXiv preprint arXiv:2405.14256 , year =
ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification , author =. arXiv preprint arXiv:2405.14256 , year =
-
[8]
arXiv preprint arXiv:2303.06865 , year =
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU , author =. arXiv preprint arXiv:2303.06865 , year =
-
[9]
arXiv preprint arXiv:2207.00032 , year =
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale , author =. arXiv preprint arXiv:2207.00032 , year =
-
[10]
IEEE transactions on information theory , volume=
Quantization , author=. IEEE transactions on information theory , volume=. 2002 , publisher=
2002
-
[11]
Proceedings of the IEEE , volume =
Vector Quantization in Speech Coding , author =. Proceedings of the IEEE , volume =
-
[12]
1992 , publisher=
Vector Quantization and Signal Compression , author=. 1992 , publisher=
1992
-
[13]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Product Quantization for Nearest Neighbor Search , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2011 , doi =
2011
-
[14]
Advances in Neural Information Processing Systems , volume=
Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2410.15704 , year =
Residual vector quantization for KV cache compression in large language model , author =. arXiv preprint arXiv:2410.15704 , year =
-
[16]
arXiv preprint arXiv:2506.19505 , year=
AnTKV: Anchor Token-Aware Sub-Bit Vector Quantization for KV Cache in Large Language Models , author=. arXiv preprint arXiv:2506.19505 , year=
-
[17]
IEEE Transactions on Acoustics, Speech, and Signal Processing , volume =
Product Code Vector Quantizers for Waveform and Voice Coding , author =. IEEE Transactions on Acoustics, Speech, and Signal Processing , volume =. 1984 , month = jun, doi =
1984
-
[18]
IEEE ASSP Magazine , volume =
Vector Quantization , author =. IEEE ASSP Magazine , volume =. 1984 , month = apr, doi =
1984
-
[19]
IEEE Assp Magazine , volume=
Vector quantization , author=. IEEE Assp Magazine , volume=. 1984 , publisher=
1984
-
[20]
Proceedings of the European Signal Processing Conference (EUSIPCO) , year =
Generalized Gain-Shape Vector Quantization for Multispectral Image Coding , author =. Proceedings of the European Signal Processing Conference (EUSIPCO) , year =
-
[21]
Machine Learning , volume =
Concept Decompositions for Large Sparse Text Data Using Clustering , author =. Machine Learning , volume =. 2001 , doi =
2001
-
[22]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Geometric representation of high dimension, low sample size data , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2005 , publisher=
2005
-
[23]
and Ghosh, Joydeep , journal =
Banerjee, Arindam and Merugu, Srujana and Dhillon, Inderjit S. and Ghosh, Joydeep , journal =. Clustering with
-
[24]
arXiv preprint arXiv:2306.07629 , year=
Squeezellm: Dense-and-sparse quantization , author=. arXiv preprint arXiv:2306.07629 , year=
-
[25]
International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. International Conference on Learning Representations , year=
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[30]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[31]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. arXiv preprint arXiv:2308.14508 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
and Hubeen, Mahesh and Reyna, Reuben , year =
Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert and Steinhardt, Jacob R. and Hubeen, Mahesh and Reyna, Reuben , year =
-
[34]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[35]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[37]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[38]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[39]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[40]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[41]
Mathqa: Towards interpretable math word problem solving with operation-based formalisms , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers) , pages=
2019
-
[42]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Additive Quantization for Extreme Vector Compression , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2014 , doi =
2014
-
[43]
Stacked Quantizers for Compositional Vector Compression
Stacked Quantizers for Compositional Vector Compression , author =. arXiv preprint arXiv:1411.2173 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
ECCV Workshops , year =
Revisiting Additive Quantization , author =. ECCV Workshops , year =
-
[45]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
Online Additive Quantization , author =. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.