WARP: Weight-Space Analysis for Recovering Training Data Portfolios
Pith reviewed 2026-07-03 17:52 UTC · model grok-4.3
The pith
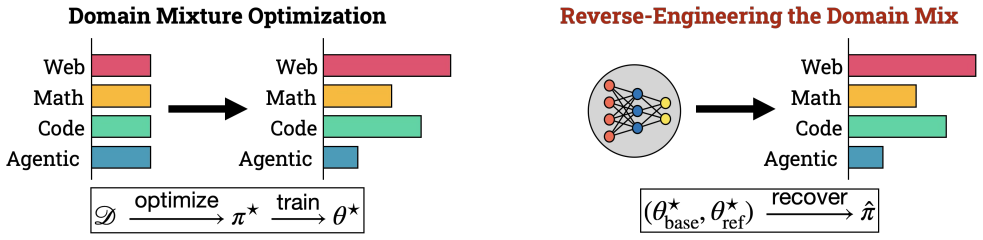
WARP recovers domain mixture weights of fine-tuned models from their released weights alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
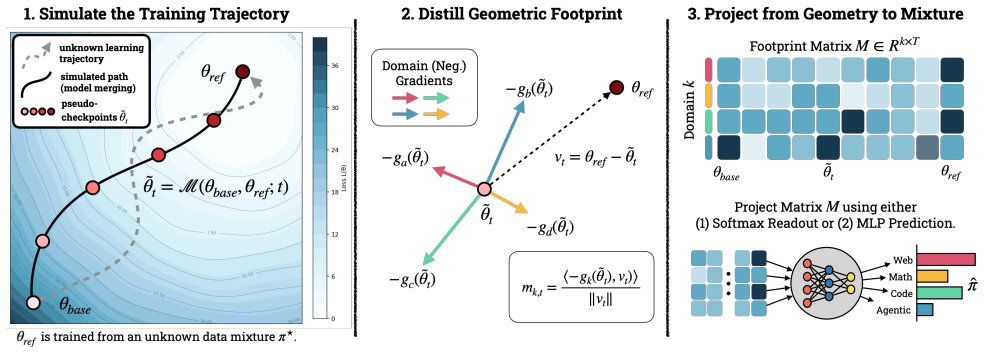
WARP recovers a fine-tuned model's training mixtures directly from its released weights. It does so by interpolating between the base and fine-tuned models using model merging, generating pseudo-checkpoints that approximate the missing training trajectory and expose a geometric footprint of the training data in the weight space. From these simulated footprints, WARP extracts geometric features and maps them to domain proportions using either a parameter-free softmax readout or an MLP projector trained on synthetic mixtures.
What carries the argument
Model merging to create pseudo-checkpoints that simulate the training trajectory and reveal geometric features in weight space encoding domain mixtures.
Load-bearing premise
Interpolating base and fine-tuned models with merging produces pseudo-checkpoints that closely approximate the actual training path and carry a detectable geometric signature of the data domains.
What would settle it
Measuring the correlation between the extracted geometric features from merged models and the known domain proportions; if the correlation is near zero, the central claim would fail.
Figures
read the original abstract
Foundation models are routinely released to the public, yet the data recipes used to train them -- such as domain mixture weights that determine how different sources are sampled -- are rarely disclosed. This creates an access asymmetry: researchers study the resulting models but lack visibility into the training distribution that produces them. Prior works for inferring training data, such as membership inference, detect at the level of individual samples and thus cannot characterize the global composition of the training corpus. We introduce WARP, a framework that recovers a fine-tuned model's training mixtures directly from its released weights. WARP interpolates between the base and fine-tuned models using model merging, generating pseudo-checkpoints that approximate the missing training trajectory and expose a geometric footprint of the training data in the weight space. From these simulated footprints, WARP extracts geometric features and maps them to domain proportions using either a parameter-free softmax readout or an MLP projector trained on synthetic mixtures. In controlled experiments with BERT and GPT-2, WARP recovers domain mixtures with an average MAE as low as 0.046 and 0.104 respectively, outperforming membership inference and a variant with access to the true training trajectory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WARP, a framework for recovering the domain mixture proportions used to train fine-tuned foundation models directly from their weights. The approach generates pseudo-checkpoints by linearly interpolating between a base model and the fine-tuned model via model merging, extracts geometric features from the weight space along this path, and then uses either a parameter-free softmax or an MLP projector (trained on synthetic mixtures) to map these features to the domain proportions. Controlled experiments on BERT and GPT-2 report average mean absolute errors (MAE) of 0.046 and 0.104 respectively, claiming to outperform both membership inference attacks and a variant that has access to the true training trajectory.
Significance. If the central claims hold, WARP would offer a practical method to infer training data portfolios from publicly released model weights, which has significant implications for transparency and reproducibility in foundation model research. The idea of using model merging to simulate training trajectories is creative, and the reported outperformance, including over a true-trajectory baseline, is noteworthy. The parameter-free readout option is particularly appealing as it avoids additional training dependencies.
major comments (3)
- [Abstract and §3] Abstract and §3: The core assumption that linear interpolation between base and fine-tuned models approximates the nonlinear SGD training trajectory and thereby exposes a geometric footprint determined by domain proportions (rather than by the interpolation operator) is load-bearing but lacks direct validation. The manuscript should include comparisons between features extracted from the linear path and those from actual intermediate checkpoints during fine-tuning to rule out artifacts.
- [Abstract] Abstract: The claim of outperformance over 'a variant with access to the true training trajectory' is surprising and requires clarification on how the true trajectory variant is implemented and why the pseudo-checkpoint approach yields lower MAE; this could indicate either a strength of the method or an issue in the baseline construction.
- [Abstract] Abstract: The MLP projector is trained on synthetic mixtures; if the synthetic generation process does not match the statistical properties of real domain mixtures, the mapping may reduce to a fitted quantity by construction rather than recovering an independent geometric signal (this is especially relevant given the reported outperformance over the true-trajectory baseline).
minor comments (1)
- The abstract would benefit from a one-sentence definition of the specific geometric features (e.g., which layer-wise statistics or directions are extracted) to improve readability before the full methods section.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of WARP's significance and for the constructive major comments. We address each point below with clarifications and have revised the manuscript accordingly to strengthen the presentation and validation of our claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The core assumption that linear interpolation between base and fine-tuned models approximates the nonlinear SGD training trajectory and thereby exposes a geometric footprint determined by domain proportions (rather than by the interpolation operator) is load-bearing but lacks direct validation. The manuscript should include comparisons between features extracted from the linear path and those from actual intermediate checkpoints during fine-tuning to rule out artifacts.
Authors: We agree that direct validation against actual training checkpoints would provide stronger evidence for the core assumption. In the controlled experiments, we trained the BERT and GPT-2 models ourselves and saved intermediate checkpoints, allowing us to perform such comparisons. We have added a new subsection in §3 (and corresponding results in the experiments) that extracts geometric features from both the linear interpolation path and the true training trajectory checkpoints, showing that the domain-proportion signal is preserved and not an artifact of the interpolation operator. This revision directly addresses the concern. revision: yes
-
Referee: [Abstract] Abstract: The claim of outperformance over 'a variant with access to the true training trajectory' is surprising and requires clarification on how the true trajectory variant is implemented and why the pseudo-checkpoint approach yields lower MAE; this could indicate either a strength of the method or an issue in the baseline construction.
Authors: We thank the referee for highlighting the need for clarification. The true-trajectory variant is implemented by extracting the identical geometric features from the actual saved intermediate checkpoints along the real SGD fine-tuning path (rather than the linear merge path) and feeding them into the same readout (parameter-free softmax or MLP). We have expanded the abstract and added a detailed paragraph in §4.2 explaining the implementation. The lower MAE for the pseudo-checkpoint approach appears to stem from the linear path providing a smoother, more consistent trajectory that reduces the impact of SGD noise and optimizer-specific artifacts present in the real checkpoints; we include additional analysis plots in the revision to illustrate this difference. revision: yes
-
Referee: [Abstract] Abstract: The MLP projector is trained on synthetic mixtures; if the synthetic generation process does not match the statistical properties of real domain mixtures, the mapping may reduce to a fitted quantity by construction rather than recovering an independent geometric signal (this is especially relevant given the reported outperformance over the true-trajectory baseline).
Authors: We acknowledge the importance of ensuring the synthetic mixtures reflect real statistical properties. The synthetic data are generated by fine-tuning on the exact same domain corpora and mixture proportions as the real experiments (using the same data loaders and preprocessing), with the MLP trained only on synthetic mixtures and evaluated on held-out real mixtures. We have added a new appendix section detailing the synthetic generation procedure, including statistics confirming distributional match, and additional ablation results showing that the geometric signal remains predictive even when the MLP is replaced by the parameter-free softmax. This supports that the mapping recovers an independent signal rather than fitting by construction. revision: yes
Circularity Check
No significant circularity: recovery derives from independent interpolation and mapping steps.
full rationale
The derivation chain begins with linear interpolation via model merging to create pseudo-checkpoints, followed by extraction of geometric features (layer-wise norms/directions) from those weights, then mapping to domain proportions via either a fixed softmax readout or an MLP trained on separately generated synthetic mixtures with known labels. Neither the interpolation operator nor the feature-to-proportion mapping reduces the output proportions to the input weights by algebraic construction or self-referential fitting; the MLP is a standard supervised model on external synthetic data, and the parameter-free option requires no training. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing. The controlled experiments measure MAE against held-out known mixtures, confirming the pipeline has independent content rather than tautological equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data Mixing for Large Language Models Pretraining: A Survey and Outlook
Chen, Z.; Miao, Y .; Xiong, D.; others Data Mixing for Large Language Models Pretraining: A Survey and Outlook. arXiv preprint arXiv:2604.163802026,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
M.; Pham, H.; Dong, X.; Du, N.; Liu, H.; Lu, Y .; Liang, P
Xie, S. M.; Pham, H.; Dong, X.; Du, N.; Liu, H.; Lu, Y .; Liang, P. S.; Le, Q. V .; Ma, T.; Yu, A. W. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems2023,36, 69798–69818
- [3]
- [4]
-
[5]
Doge: Domain reweighting with generalization estimation.arXiv preprint arXiv:2310.153932023,
Fan, S.; Pagliardini, M.; Jaggi, M. Doge: Domain reweighting with generalization estimation.arXiv preprint arXiv:2310.153932023,
-
[6]
Time Travel in LLMs: Tracing Data Contamination in Large Language Models.CoRR2023, abs/2308.08493
Golchin, S.; Surdeanu, M. Time Travel in LLMs: Tracing Data Contamination in Large Language Models.CoRR2023, abs/2308.08493. 8
-
[7]
Golchin, S.; Surdeanu, M. Data Contamination Quiz: A Tool to Detect and Estimate Contamination in Large Language Models.CoRR2023,abs/2311.06233
-
[8]
Data contamination: From memorization to exploitation
Magar, I.; Schwartz, R. Data contamination: From memorization to exploitation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers). 2022; pp 157–165
2022
-
[9]
P.; Galley, M.; Caruana, R.; Gao, J
Singh, C.; Inala, J. P.; Galley, M.; Caruana, R.; Gao, J. Rethinking interpretability in the era of large language models. arXiv preprint arXiv:2402.017612024,
-
[10]
MixAtlas: Uncertainty-aware Data Mixture Optimization for Multimodal LLM Midtraining
Wen, B.; Salekin, S.; Kang, F.; Howe, B.; Wang, L. L.; Movellan, J.; Bilkhu, M. MixAtlas: Uncertainty-aware Data Mixture Optimization for Multimodal LLM Midtraining.arXiv preprint arXiv:2604.141982026,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Regmix: Data mixture as regression for language model pre-training
Liu, Q.; Zheng, X.; Muennighoff, N.; Zeng, G.; Dou, L.; Pang, T.; Jiang, J.; Lin, M. Regmix: Data mixture as regression for language model pre-training. International Conference on Learning Representations. 2025; pp 38305–38339
2025
-
[12]
Autoscale: Scale-aware data mixing for pre-training llms.arXiv preprint arXiv:2407.201772024,
Kang, F.; Sun, Y .; Wen, B.; Chen, S.; Song, D.; Mahmood, R.; Jia, R. Autoscale: Scale-aware data mixing for pre-training llms.arXiv preprint arXiv:2407.201772024,
-
[13]
Scaling laws for optimal data mixtures.Advances in Neural Information Processing Systems2026,38, 129554–129579
Shukor, M.; Bethune, L.; Busbridge, D.; Grangier, D.; Fini, E.; El-Nouby, A.; Ablin, P. Scaling laws for optimal data mixtures.Advances in Neural Information Processing Systems2026,38, 129554–129579
-
[14]
Membership inference attacks against fine-tuned large language models via self-prompt calibration.Advances in Neural Information Processing Systems2024,37, 134981–135010
Fu, W.; Wang, H.; Gao, C.; Liu, G.; Li, Y .; Jiang, T. Membership inference attacks against fine-tuned large language models via self-prompt calibration.Advances in Neural Information Processing Systems2024,37, 134981–135010
-
[15]
Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.078412024,
Duan, M.; Suri, A.; Mireshghallah, N.; Min, S.; Shi, W.; Zettlemoyer, L.; Tsvetkov, Y .; Choi, Y .; Evans, D.; Hajishirzi, H. Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.078412024,
-
[16]
Membership inference attacks against language models via neighbourhood comparison
Mattern, J.; Mireshghallah, F.; Jin, Z.; Schölkopf, B.; Sachan, M.; Berg-Kirkpatrick, T. Membership inference attacks against language models via neighbourhood comparison. Findings of the Association for Computational Linguistics: ACL 2023. 2023; pp 11330–11343
2023
-
[17]
Membership Inference Attacks against Machine Learning Models
Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V . Membership Inference Attacks against Machine Learning Models. 2017;https://arxiv.org/abs/1610.05820
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Morris, J. X.; Yin, J. O.; Kim, W.; Shmatikov, V .; Rush, A. M. Approximating Language Model Training Data from Weights.arXiv preprint arXiv:2506.155532025,
-
[19]
A.; Zhu, J.-Y
Cazenavette, G.; Wang, T.; Torralba, A.; Efros, A. A.; Zhu, J.-Y . Dataset distillation by matching training trajectories. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022; pp 4750–4759
2022
-
[20]
Evaluating Sample Utility for Efficient Data Selection by Mimicking Model Weights
Huang, T.-H.; Bilkhu, M.; Cooper, J.; Sala, F.; Movellan, J. Evaluating Sample Utility for Efficient Data Selection by Mimicking Model Weights.arXiv preprint arXiv:2501.067082025,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Bert: Pre-training of deep bidirectional transformers for language understanding
Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019; pp 4171–4186
2019
-
[22]
Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I.; others Language models are unsupervised multitask learners.OpenAI blog2019,1, 9
-
[23]
F.; Murray, T.; Heineman, D.; Jordan, M.; Hajishirzi, H.; Ré, C.; Soldaini, L.; Lo, K
Chen, M. F.; Murray, T.; Heineman, D.; Jordan, M.; Hajishirzi, H.; Ré, C.; Soldaini, L.; Lo, K. Olmix: A framework for data mixing throughout lm development.arXiv preprint arXiv:2602.122372026, 9
- [24]
-
[25]
LLM Dataset Inference: Did you train on my dataset? 2024
Maini, P.; Jia, H.; Papernot, N.; Dziedzic, A. LLM Dataset Inference: Did you train on my dataset? 2024
2024
-
[26]
Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities.ACM Computing Surveys2026,58, 1–41
Yang, E.; Shen, L.; Guo, G.; Wang, X.; Cao, X.; Zhang, J.; Tao, D. Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities.ACM Computing Surveys2026,58, 1–41
-
[27]
Arcee’s MergeKit: A Toolkit for Merging Large Language Models
Goddard, C.; Siriwardhana, S.; Ehghaghi, M.; Meyers, L.; Karpukhin, V .; Benedict, B.; McQuade, M.; Solawetz, J. Arcee’s MergeKit: A Toolkit for Merging Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. Miami, Florida, US, 2024; pp 477–485
2024
-
[28]
Editing Models with Task Arithmetic
Ilharco, G.; Ribeiro, M. T.; Wortsman, M.; Gururangan, S.; Schmidt, L.; Hajishirzi, H.; Farhadi, A. Editing models with task arithmetic.arXiv preprint arXiv:2212.040892022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Ainsworth, S. K.; Hayase, J.; Srinivasa, S. Git re-basin: Merging models modulo permutation symmetries.arXiv preprint arXiv:2209.048362022,
-
[30]
Jordan, K.; Sedghi, H.; Saukh, O.; Entezari, R.; Neyshabur, B. Repair: Renormalizing permuted activations for interpolation repair.arXiv preprint arXiv:2211.084032022,
-
[31]
A.; Bansal, M
Yadav, P.; Tam, D.; Choshen, L.; Raffel, C. A.; Bansal, M. Ties-merging: Resolving interference when merging models. Advances in neural information processing systems2023,36, 7093–7115
-
[32]
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch
Yu, L.; Yu, B.; Yu, H.; Huang, F.; Li, Y . Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch. International Conference on Machine Learning. 2024
2024
-
[33]
Localize-and-stitch: Efficient model merging via sparse task arithmetic
He, Y .; Hu, Y .; Lin, Y .; Zhang, T.; Zhao, H. Localize-and-stitch: Efficient model merging via sparse task arithmetic. arXiv preprint arXiv:2408.136562024,
-
[34]
Y .; Roelofs, R.; Gontijo-Lopes, R.; Morcos, A
Wortsman, M.; Ilharco, G.; Gadre, S. Y .; Roelofs, R.; Gontijo-Lopes, R.; Morcos, A. S.; Namkoong, H.; Farhadi, A.; Carmon, Y .; Kornblith, S.; others Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. International conference on machine learning. 2022; pp 23965–23998
2022
-
[35]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications, and Opportunities.ACM Comput
Yang, E.; Shen, L.; Guo, G.; Wang, X.; Cao, X.; Zhang, J.; Tao, D. Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications, and Opportunities.ACM Comput. Surv.2026,58
2026
-
[36]
Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.Transactions of the Association for Computational Linguistics2014,2, 67–78
-
[37]
Zhang, X.; Zhao, J.; LeCun, Y . Character-level convolutional networks for text classification.Advances in neural information processing systems2015,28. 10 Appendix Roadmap Our appendix is structured as follows. We use Appendix A to summarize our full framework in pseudocode. Appendix B documents the experimental setup and training configurations. Finally...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.