Set Diffusion: Interpolating Token Orderings Between Autoregression and Diffusion for Fast and Flexible Decoding
Pith reviewed 2026-07-03 17:28 UTC · model grok-4.3
The pith
Set diffusion lets language models generate tokens in arbitrarily ordered sets by factorizing over flexible token sets instead of fixed blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
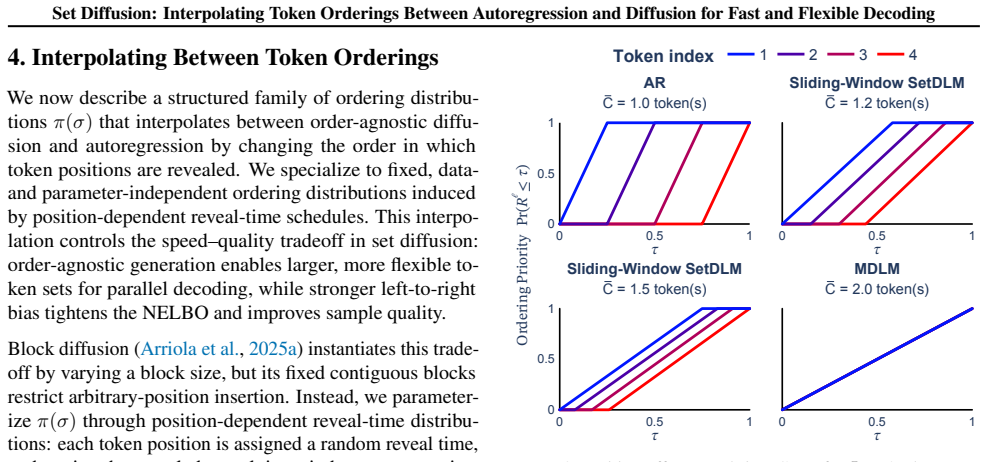
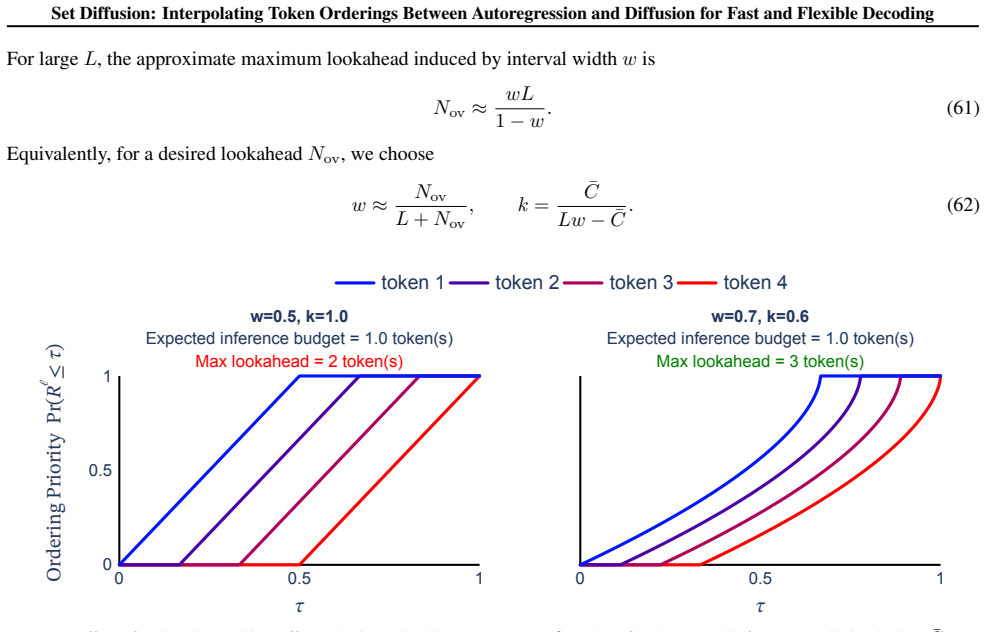
Set diffusion is defined by a likelihood parameterization that factorizes over flexible-position, flexible-length token sets and a set-causal diffusion architecture that supports KV cache updates after every inference step. By factorizing over token sets instead of fixed-size blocks, tokens can be decoded in arbitrarily-ordered sets, including sliding-window sets, enabling faster inference and support for any-order decoding.
What carries the argument
the likelihood parameterization that factorizes over flexible-position, flexible-length token sets
Load-bearing premise
A set-causal diffusion architecture can maintain coherent generation and effective KV-cache updates when the likelihood is factorized over flexible-position, flexible-length token sets rather than fixed blocks or full sequences.
What would settle it
An experiment showing that set diffusion with sliding-window token sets yields lower coherence scores or inconsistent KV cache states compared with block diffusion on the same tasks.
Figures


read the original abstract
Discrete diffusion models have steadily improved in quality relative to autoregressive (AR) models. However, these models are normally constrained to fixed-length generation and do not support key-value (KV) caching. Block diffusion partially bridges diffusion and AR by generating token blocks left-to-right, but its fixed-size sequential blocks limit decoding flexibility and parallelism. Here, we present a new class of language models, set diffusion, comprised of (i) a likelihood parameterization that factorizes over flexible-position, flexible-length token sets and (ii) a set-causal diffusion architecture that supports KV cache updates after every inference step. By factorizing over token sets instead of fixed-size blocks, tokens can be decoded in arbitrarily-ordered sets, including sliding-window sets, enabling faster inference and support for any-order decoding. Set diffusion achieves better speed-quality tradeoffs on mathematical reasoning, summarization, and unconditional generation compared to prior diffusion language models while offering stronger infilling performance than block diffusion. We provide the code, along with the model weights and blog post on the project page: https://m-arriola.com/setdlms/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces set diffusion, a new class of language models that factorizes the likelihood over flexible-position, flexible-length token sets (instead of fixed-size blocks) and employs a set-causal diffusion architecture supporting KV-cache updates after each step. This enables decoding in arbitrarily ordered sets, including sliding-window configurations, for faster inference and any-order generation. Experiments on mathematical reasoning, summarization, and unconditional generation report improved speed-quality tradeoffs versus prior diffusion LMs, with stronger infilling than block diffusion; code, weights, and a blog post are released.
Significance. If the claims hold, the work meaningfully interpolates between autoregressive and diffusion paradigms by relaxing block constraints while preserving KV caching, which could improve flexible decoding in LLMs. Explicit release of code, model weights, and a project blog post is a clear strength supporting reproducibility.
major comments (2)
- [§3.2] §3.2 (set-causal architecture): the description of position-independent attention and cache invalidation for variable-length, non-contiguous sets does not explicitly address how masking or positional encodings avoid implicit left-to-right assumptions; if violated, this would undermine coherence and KV-cache validity for the sliding-window and any-order regimes claimed in the abstract.
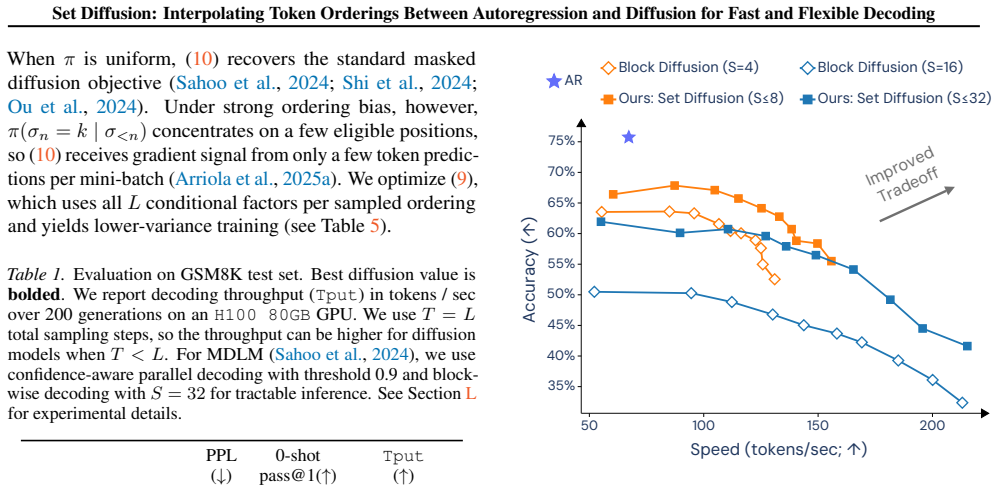
- [§4] §4 (experiments): the speed-quality tradeoffs are reported without visible error bars, data-selection rules, or ablation isolating the contribution of flexible set factorization versus the architecture; this makes it difficult to confirm that the gains are load-bearing for the central claim rather than implementation-specific.
minor comments (2)
- [Eq. (3)–(5)] Notation for set membership and ordering in Eq. (3)–(5) could be clarified with an explicit example of a sliding-window set.
- [Figure 2] Figure 2 caption does not state whether the visualized attention masks are for training or inference.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (set-causal architecture): the description of position-independent attention and cache invalidation for variable-length, non-contiguous sets does not explicitly address how masking or positional encodings avoid implicit left-to-right assumptions; if violated, this would undermine coherence and KV-cache validity for the sliding-window and any-order regimes claimed in the abstract.
Authors: We agree that greater explicitness would strengthen the presentation. Section 3.2 defines set-causal attention via a mask that permits attention only to tokens already generated in prior steps (regardless of their positions in the original sequence) together with absolute positional encodings taken from the input sequence. No relative positional bias or left-to-right ordering is imposed inside the mask or the encodings; the only ordering is the generation order of the sets themselves. We will add a dedicated paragraph and a small diagram clarifying the mask construction and confirming that the same mechanism applies unchanged to sliding-window and arbitrary-order regimes, thereby preserving KV-cache validity. revision: yes
-
Referee: [§4] §4 (experiments): the speed-quality tradeoffs are reported without visible error bars, data-selection rules, or ablation isolating the contribution of flexible set factorization versus the architecture; this makes it difficult to confirm that the gains are load-bearing for the central claim rather than implementation-specific.
Authors: We acknowledge that the current experimental section would benefit from these additions. In the revision we will (i) report means and standard deviations over at least three random seeds for all speed-quality curves, (ii) state the exact data-selection and prompting protocols used for each benchmark, and (iii) include an ablation that holds the architecture fixed while varying only the set-factorization component (fixed-size blocks versus flexible sets). These changes will be placed in an expanded Section 4 and the associated appendix. revision: yes
Circularity Check
No circularity: new parameterization and architecture presented as independent contributions
full rationale
The paper defines a new likelihood factorization over flexible-position, flexible-length token sets together with a set-causal diffusion architecture that enables KV-cache updates. These elements are introduced directly rather than obtained by fitting parameters to a target quantity and then relabeling the fit as a prediction, or by reducing to a self-citation chain. No equations are shown that equate a claimed result to its own inputs by construction, and the speed-quality and any-order claims are stated to follow from the explicit factorization and masking choices. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Thirteenth International Conference on Learning Representations , year=
Interpolating Autoregressive and Discrete Denoising Diffusion Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[2]
Nature methods , volume=
Effective gene expression prediction from sequence by integrating long-range interactions , author=. Nature methods , volume=. 2021 , publisher=
2021
-
[3]
Advances in Neural Information Processing Systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Adaptive Input Representations for Neural Language Modeling
Adaptive input representations for neural language modeling , author=. arXiv preprint arXiv:1809.10853 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
A continuous time framework for discrete denoising models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple llm inference acceleration framework with multiple decoding heads , author=. arXiv preprint arXiv:2401.10774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Maskgit: Masked generative image transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
Advances in Neural Information Processing Systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
The Twelfth International Conference on Learning Representations , year=
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning , author=. The Twelfth International Conference on Learning Representations , year=
-
[10]
Database (GenBank or RefSeq) , year=
Genome reference consortium human build 37 (grch37 , author=. Database (GenBank or RefSeq) , year=
-
[11]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[12]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-xl: Attentive language models beyond a fixed-length context , author=. arXiv preprint arXiv:1901.02860 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[13]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
BMC Genomic Data , volume=
Genomic benchmarks: a collection of datasets for genomic sequence classification , author=. BMC Genomic Data , volume=. 2023 , publisher=
2023
-
[15]
The Thirteenth International Conference on Learning Representations , year=
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[16]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces , author=. arXiv preprint arXiv:2312.00752 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Advances in Neural Information Processing Systems , volume=
Likelihood-based diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2504.20456 , year=
Reviving any-subset autoregressive models with principled parallel sampling and speculative decoding , author=. arXiv preprint arXiv:2504.20456 , year=
-
[19]
arXiv preprint arXiv:2305.14771 , year=
David helps Goliath: Inference-Time Collaboration Between Small Specialized and Large General Diffusion LMs , author=. arXiv preprint arXiv:2305.14771 , year=
-
[20]
arXiv preprint arXiv:2211.15029 , year=
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models , author=. arXiv preprint arXiv:2211.15029 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Argmax flows and multinomial diffusion: Learning categorical distributions , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Autoregressive diffusion models , author=. arXiv preprint arXiv:2110.02037 , year=
-
[23]
arXiv preprint arXiv:2505.14455 , year=
Ctrldiff: Boosting large diffusion language models with dynamic block prediction and controllable generation , author=. arXiv preprint arXiv:2505.14455 , year=
-
[24]
arXiv preprint arXiv:2509.01025 , year=
Any-Order Flexible Length Masked Diffusion , author=. arXiv preprint arXiv:2509.01025 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Understanding diffusion objectives as the elbo with simple data augmentation , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Variational diffusion models , author=. Advances in neural information processing systems , volume=
-
[27]
2024 , url=
Siqi Kou and Lanxiang Hu and Zhezhi He and Zhijie Deng and Hao Zhang , booktitle=. 2024 , url=
2024
-
[28]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion language modeling by estimating the ratios of the data distribution , author=. arXiv preprint arXiv:2310.16834 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2110.15797 , year=
Discovering non-monotonic autoregressive orderings with variational inference , author=. arXiv preprint arXiv:2110.15797 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Advances in neural information processing systems , volume=
Hyenadna: Long-range genomic sequence modeling at single nucleotide resolution , author=. Advances in neural information processing systems , volume=
-
[32]
Arnaud Pannatier and Evann Courdier and Francois Fleuret , year=. 2404.09562 , archivePrefix=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[34]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[35]
International Conference on Machine Learning , pages=
Adaptive antithetic sampling for variance reduction , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[36]
Advances in Neural Information Processing Systems , volume=
Sticking the landing: Simple, lower-variance gradient estimators for variational inference , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
The Eleventh International Conference on Learning Representations , year=
Backpropagation through Combinatorial Algorithms: Identity with Projection Works , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
arXiv preprint arXiv:2312.13236 , year=
Diffusion Models With Learned Adaptive Noise , author=. arXiv preprint arXiv:2312.13236 , year=
-
[39]
Advances in neural information processing systems , volume=
Mesh-tensorflow: Deep learning for supercomputers , author=. Advances in neural information processing systems , volume=
-
[40]
International Conference on Machine Learning , year=
Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling , author=. International Conference on Machine Learning , year=
-
[41]
arXiv preprint arXiv:2403.03234 , year=
Caduceus: Bi-directional equivariant long-range dna sequence modeling , author=. arXiv preprint arXiv:2403.03234 , year=
-
[42]
RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. arXiv preprint arXiv:2104.09864 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
International Conference on Machine Learning , pages=
Omninet: Omnidirectional representations from transformers , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[44]
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
BERT has a mouth, and it must speak: BERT as a Markov random field language model , author=. arXiv preprint arXiv:1902.04094 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[45]
2023 , editor =
Wang, Yingheng and Schiff, Yair and Gokaslan, Aaron and Pan, Weishen and Wang, Fei and De Sa, Christopher and Kuleshov, Volodymyr , booktitle =. 2023 , editor =
2023
-
[46]
International Conference on Machine Learning , pages=
A deep and tractable density estimator , author=. International Conference on Machine Learning , pages=. 2014 , organization=
2014
-
[47]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[48]
arXiv preprint arXiv:2208.04202 , year=
Analog bits: Generating discrete data using diffusion models with self-conditioning , author=. arXiv preprint arXiv:2208.04202 , year=
-
[49]
arXiv preprint arXiv:2210.17432 , year=
Ssd-lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control , author=. arXiv preprint arXiv:2210.17432 , year=
-
[50]
arXiv preprint arXiv:2211.04236 , year=
Self-conditioned embedding diffusion for text generation , author=. arXiv preprint arXiv:2211.04236 , year=
-
[51]
Continuous diffusion for categorical data
Continuous diffusion for categorical data , author=. arXiv preprint arXiv:2211.15089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Advances in Neural Information Processing Systems , volume=
Latent diffusion for language generation , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[54]
arXiv preprint arXiv:2211.16750 , year=
Score-based continuous-time discrete diffusion models , author=. arXiv preprint arXiv:2211.16750 , year=
-
[55]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Computational linguistics , volume=
Building a large annotated corpus of English: The Penn Treebank , author=. Computational linguistics , volume=
-
[57]
2016 , eprint=
Pointer Sentinel Mixture Models , author=. 2016 , eprint=
2016
-
[58]
2014 , eprint=
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling , author=. 2014 , eprint=
2014
-
[59]
Paperno, Denis and Kruszewski, Germ\'. The. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2016 , address =
2016
-
[60]
NIPS , year=
Character-level Convolutional Networks for Text Classification , author=. NIPS , year=
-
[61]
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents , url=
Cohan, Arman and Dernoncourt, Franck and Kim, Doo Soon and Bui, Trung and Kim, Seokhwan and Chang, Walter and Goharian, Nazli , year=. A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents , url=. doi:10.18653/v1/n18-2097 , journal=
-
[62]
OpenWebText Corpus , author=
-
[63]
Advances in neural information processing systems , volume=
Reverse-complement equivariant networks for DNA sequences , author=. Advances in neural information processing systems , volume=
-
[64]
Machine Learning in Computational Biology , pages=
Towards a better understanding of reverse-complement equivariance for deep learning models in genomics , author=. Machine Learning in Computational Biology , pages=. 2022 , organization=
2022
-
[65]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[66]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[67]
2024 , eprint=
MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining , author=. 2024 , eprint=
2024
-
[68]
Bowman , booktitle=
Alex Wang and Amanpreet Singh and Julian Michael and Felix Hill and Omer Levy and Samuel R. Bowman , booktitle=. 2019 , url=
2019
-
[69]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. J. Mach. Learn. Res. , month =. 2020 , issue_date =
2020
-
[70]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[71]
Proceedings of the 38th International Conference on Machine Learning , pages =
Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[72]
2023 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , eprint=
2023
-
[73]
Probabilistically Masked Language Model Capable of Autoregressive Generation in Arbitrary Word Order
Liao, Yi and Jiang, Xin and Liu, Qun. Probabilistically Masked Language Model Capable of Autoregressive Generation in Arbitrary Word Order. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.24
-
[74]
Mask-Predict: Parallel Decoding of Conditional Masked Language Models
Ghazvininejad, Marjan and Levy, Omer and Liu, Yinhan and Zettlemoyer, Luke. Mask-Predict: Parallel Decoding of Conditional Masked Language Models. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1633
-
[75]
Advances in neural information processing systems , volume=
Generative modeling by estimating gradients of the data distribution , author=. Advances in neural information processing systems , volume=
-
[76]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Styleswin: Transformer-based gan for high-resolution image generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[77]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author=. arXiv preprint arXiv:2406.03736 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
2022 , eprint=
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , author=. 2022 , eprint=
2022
-
[79]
arXiv preprint arXiv:2209.14734 , year=
Digress: Discrete denoising diffusion for graph generation , author=. arXiv preprint arXiv:2209.14734 , year=
-
[80]
Advances in Neural Information Processing Systems , volume=
Difusco: Graph-based diffusion solvers for combinatorial optimization , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.