Self-explainable Operator Learning for Discovering Spatial Patterns in Functional Data
Pith reviewed 2026-07-03 16:45 UTC · model grok-4.3
The pith
Reformulating neural operators as linear combinations of integral equations embeds direct spatial interpretability into the model itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
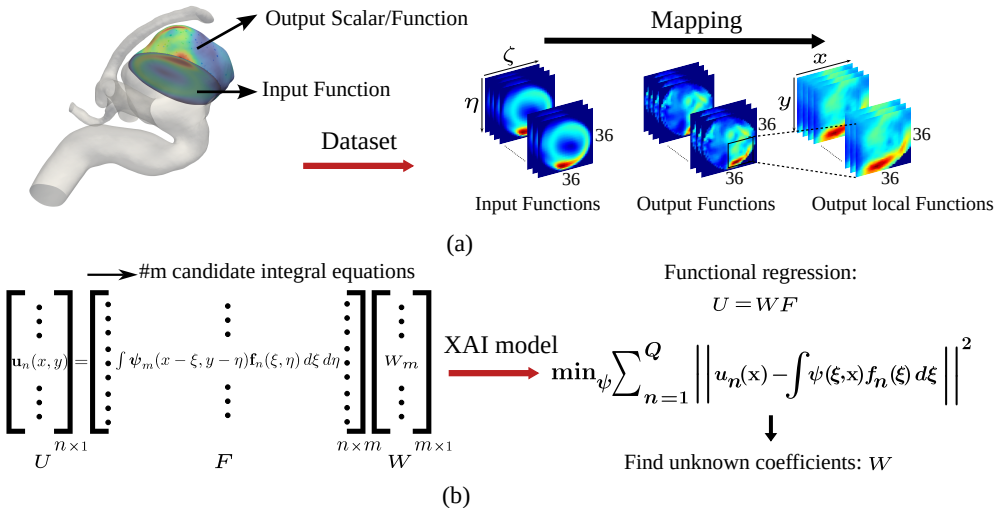
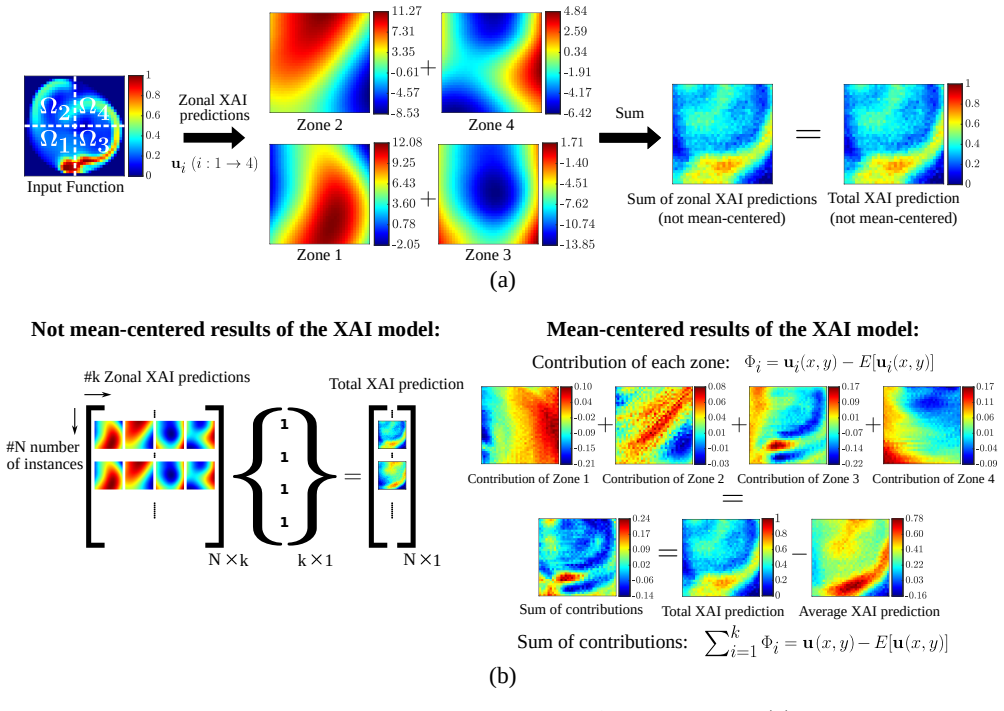
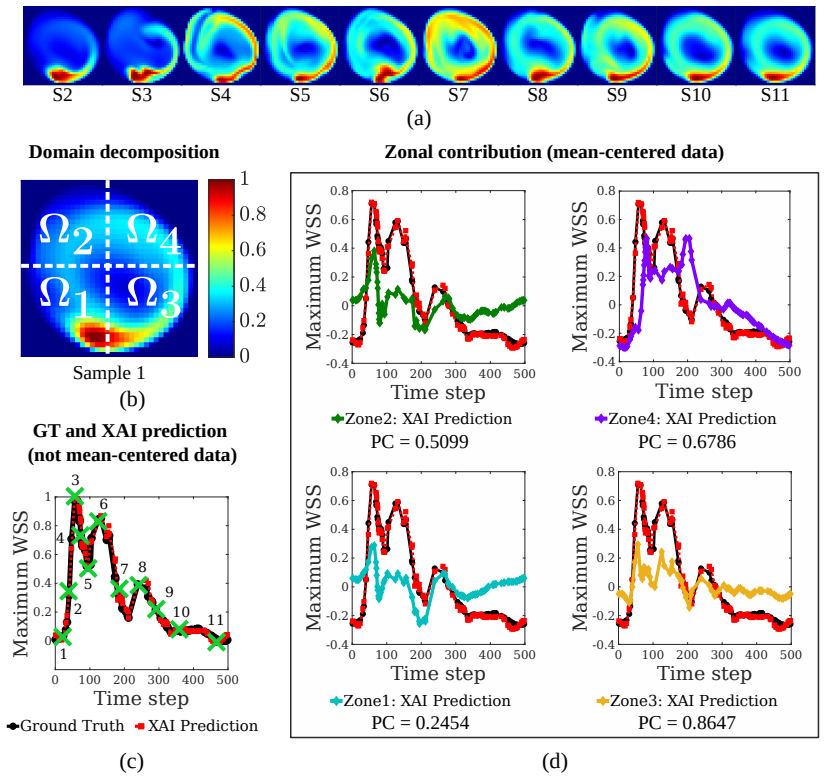
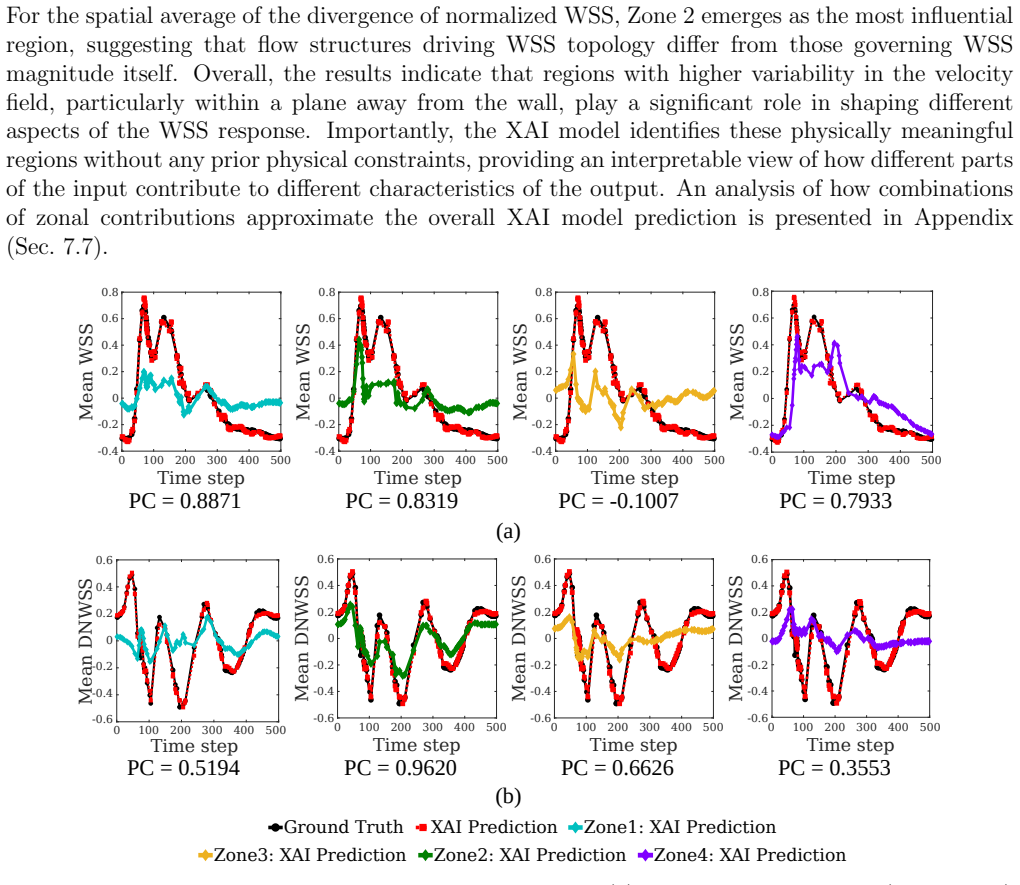
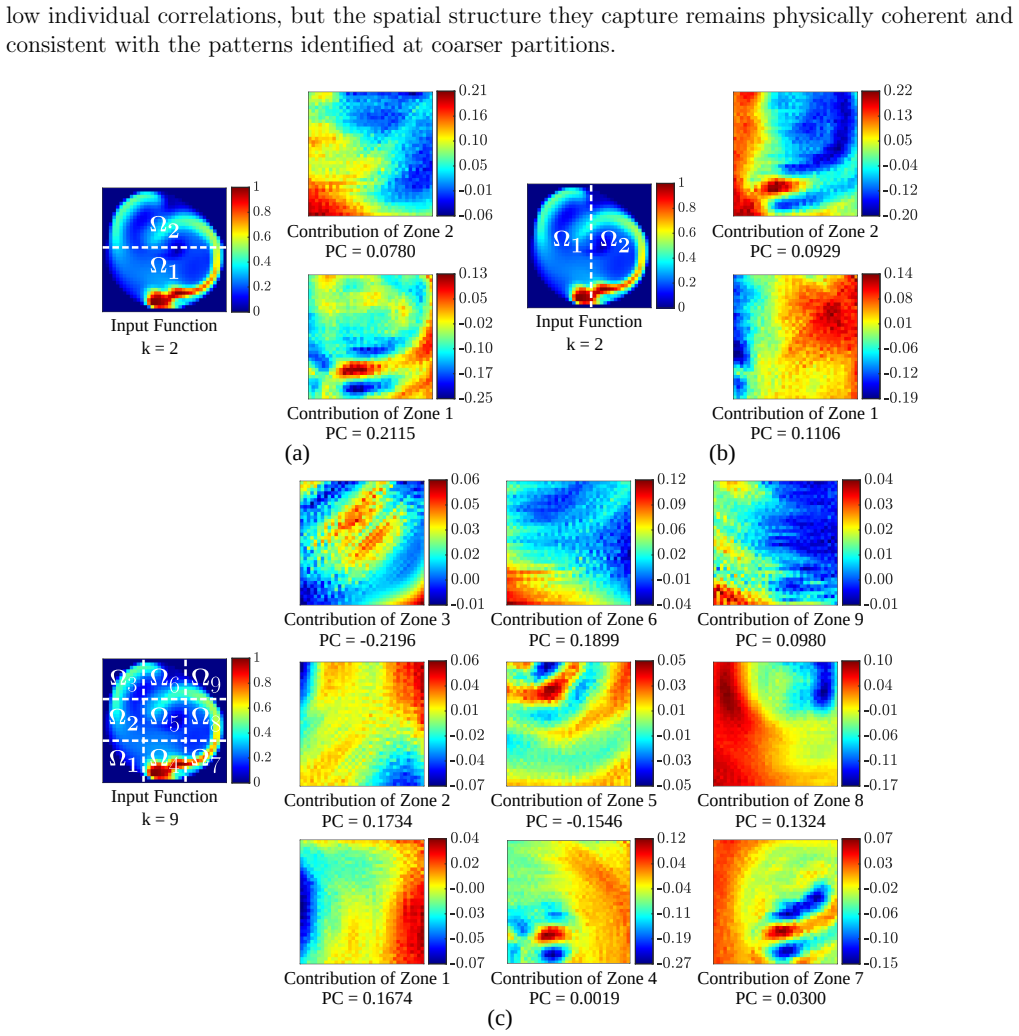
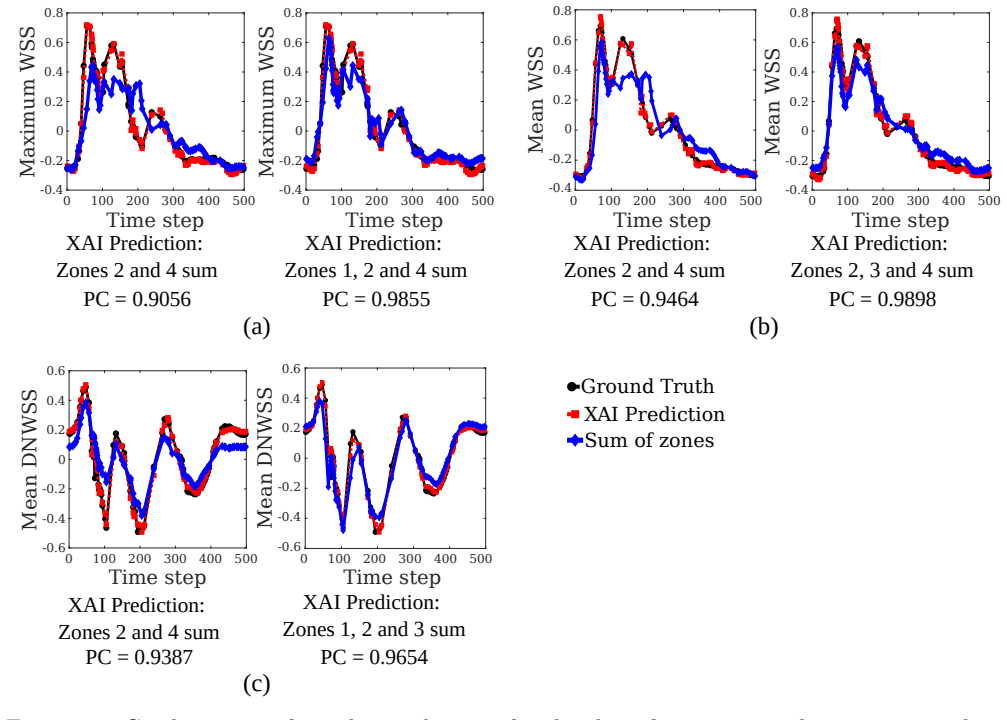
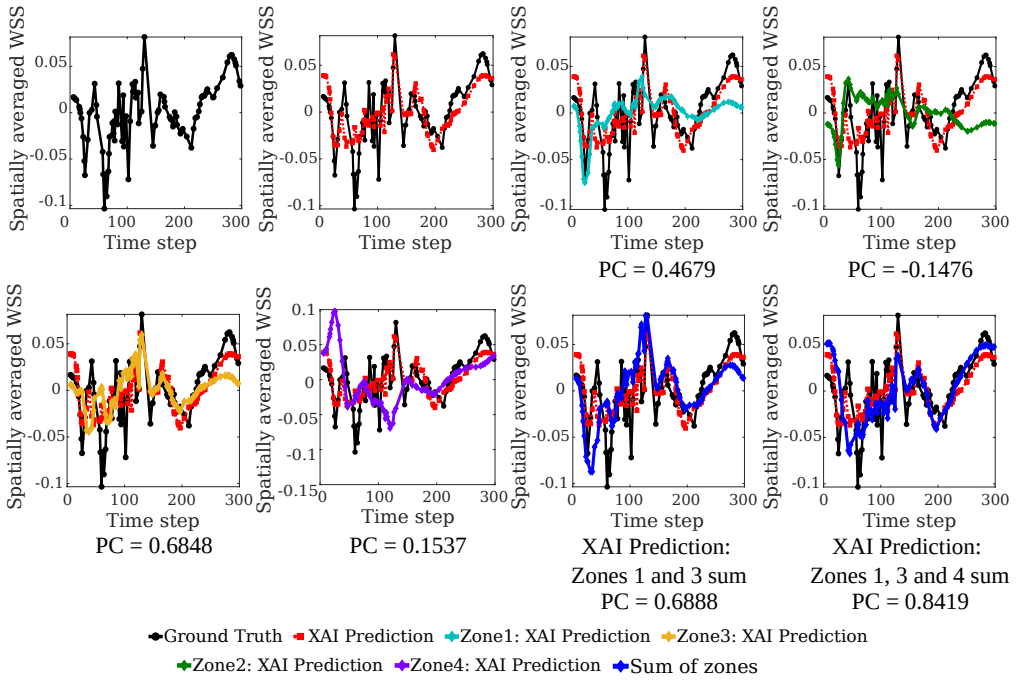
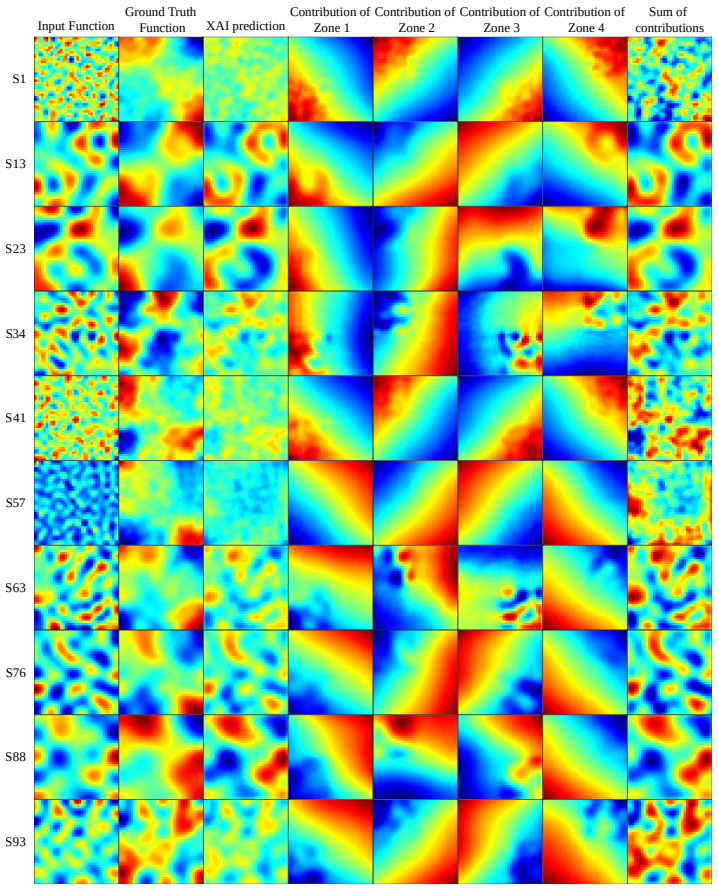
The operator is reformulated as a linear combination of generalized functional linear models expressed through integral equations. Exploiting the additive decomposability of these integral equations, the input domain is divided into subdomains and localized integrals are computed to evaluate the contribution of each region to the final prediction. This decomposition enables direct interpretability where the model explains both inputs and outputs by linking specific input regions to corresponding output patterns, thereby revealing which spatial features drive predictions.
What carries the argument
Additive decomposition of the integral equations into localized subdomain contributions.
If this is right
- Each input subdomain's localized integral directly quantifies its contribution to the output, producing an intrinsic explanation.
- In the fluid examples the operator consistently assigns highest weight to regions containing strong feature gradients.
- Explainability is obtained without any external post-hoc method and remains valid for both function-to-scalar and function-to-function tasks.
- The same decomposition works for any operator that can be expressed in the required integral form while keeping predictive fidelity.
Where Pith is reading between the lines
- The approach could be tested on operator-learning tasks outside fluids, such as heat transfer or structural mechanics, to check whether the gradient emphasis generalizes.
- Direct comparison of the localized integrals against known analytical Green's functions in linear problems would provide an independent check on the decomposition.
- If the method scales to high-dimensional inputs it might serve as a built-in feature-selection step before training larger operators.
Load-bearing premise
The neural operator can be rewritten as the stated linear combination of integral equations while preserving its original predictive accuracy and without introducing new fitting artifacts.
What would settle it
Apply both the original neural operator and the reformulated integral version to identical test inputs and observe whether the output predictions differ or whether the regions flagged as influential contradict established physical understanding of the flow problem.
Figures
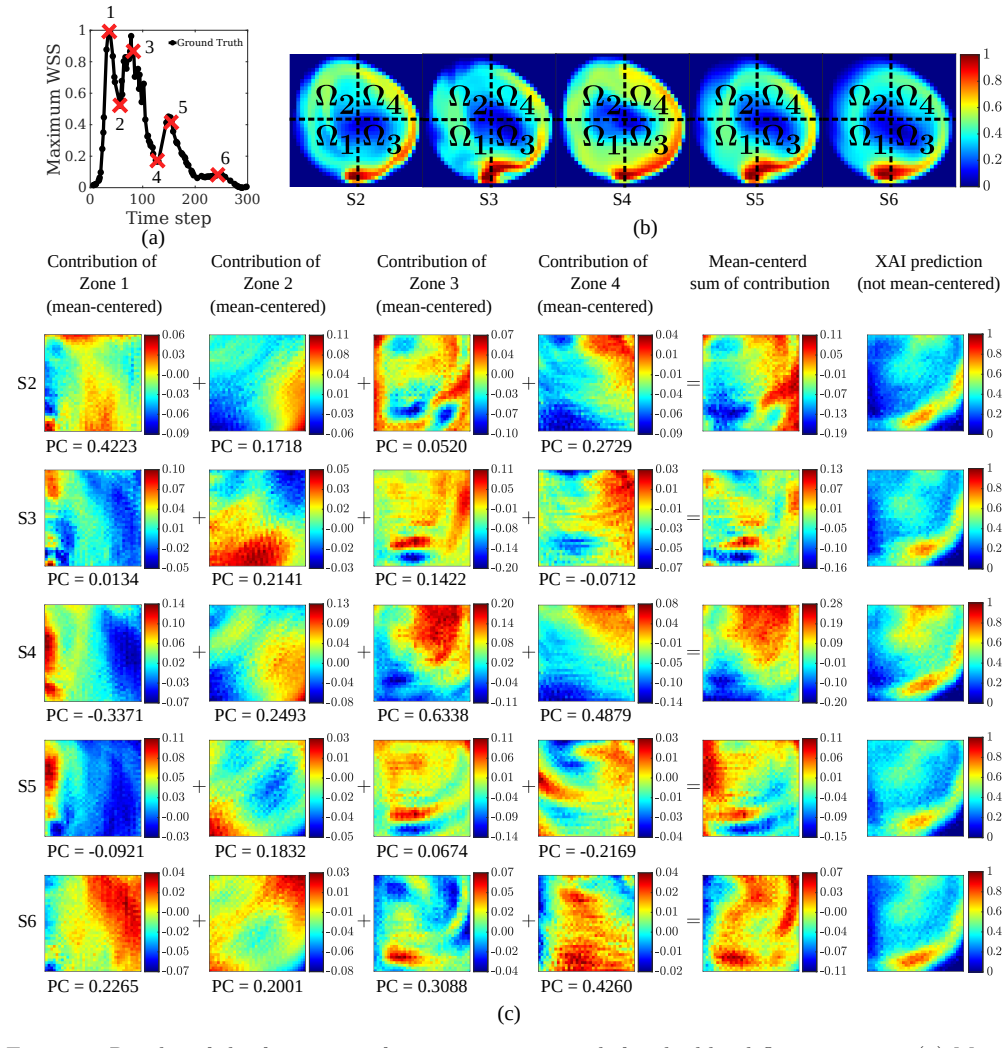

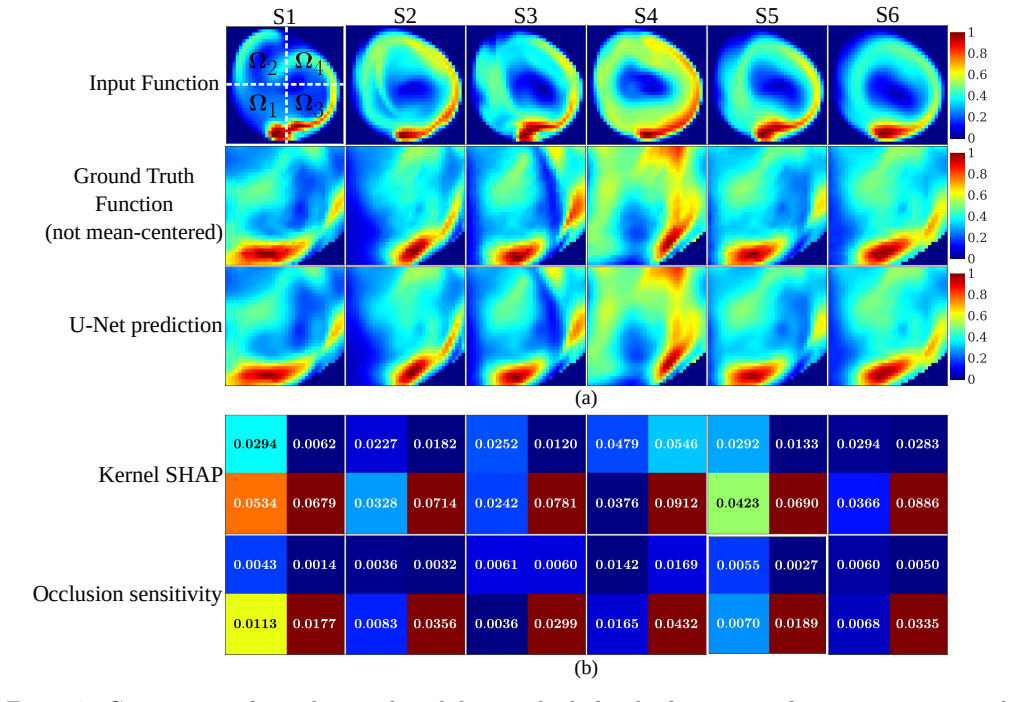
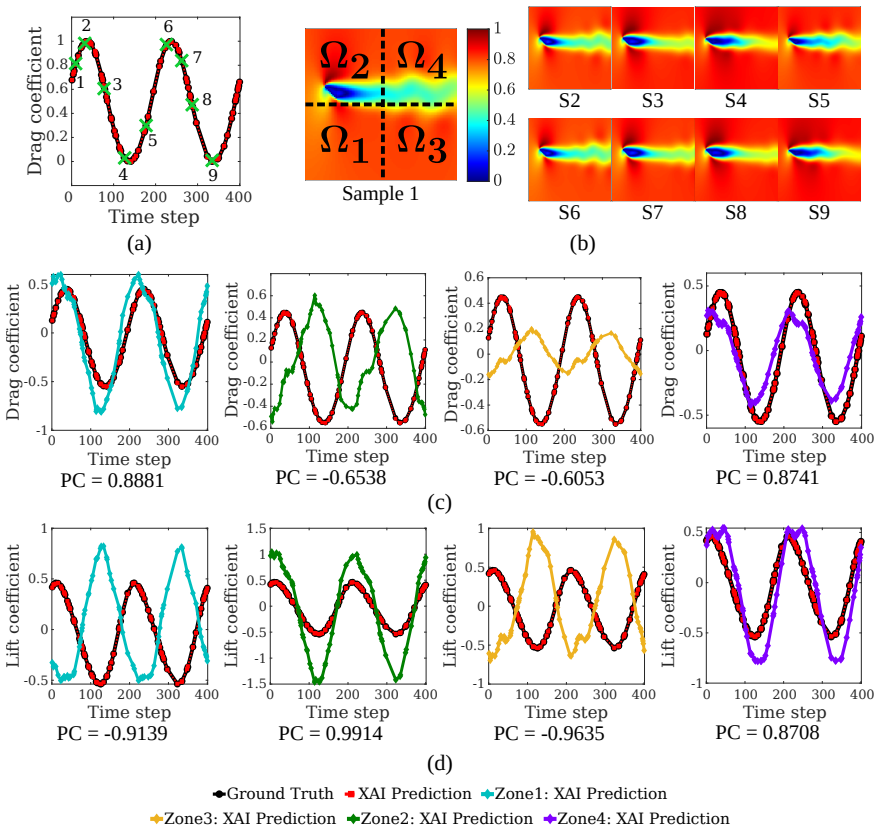
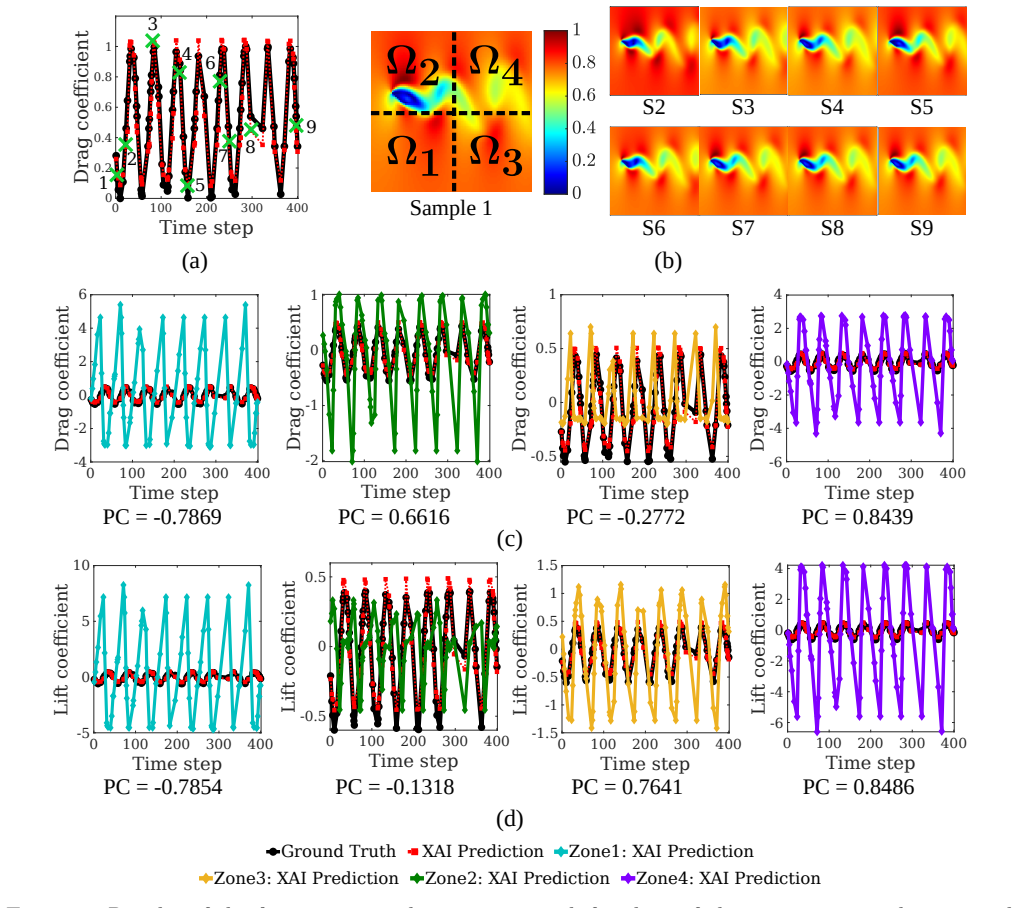



read the original abstract
Operator learning has emerged as a powerful tool for modeling complex physical systems in functional spaces. However, their neural network-based architectures make them opaque models, obscuring the reasoning behind their predictions. In this work, we introduce a self-explainable operator learning framework that overcomes this challenge by reformulating operator learning as a linear combination of generalized functional linear models expressed through integral equations. Exploiting the additive decomposability of these integral equations, we divide the input domain into subdomains and compute localized integrals to evaluate the contribution of each region to the final prediction. This decomposition enables direct interpretability where the model explains both inputs and outputs by linking specific input regions to corresponding output patterns, thereby revealing which spatial features drive predictions. We demonstrate the framework on function-to-scalar and function-to-function mappings in fluid flow problems involving blood flow and unsteady aerodynamics. The results show that the operator most often prioritizes regions with strong feature gradients, providing physically meaningful insight into the model's decision-making process. Comparisons with established post-hoc explainability methods demonstrate qualitative agreement while highlighting the key advantage of the proposed approach: explainability is embedded directly within the operator structure itself and does not require an external tool. Therefore, our framework provides a mathematically transparent and physically interpretable approach to uncover relationships within data, fostering trust in machine learning for scientific applications by enabling more informed data-driven analysis of physical systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-explainable operator learning framework that reformulates neural operators as linear combinations of generalized functional linear models expressed through integral equations. By exploiting additive decomposability, the input domain is partitioned into subdomains whose localized integrals quantify each region's contribution to the output prediction. The approach is demonstrated on function-to-scalar and function-to-function mappings for blood-flow and unsteady-aerodynamics problems, with the claim that attributions align with strong gradients, agree qualitatively with post-hoc explainers, and are obtained intrinsically without external tools.
Significance. If the reformulation is faithful to the original nonlinear operator class and the decomposition introduces no measurable degradation in predictive accuracy, the framework would supply a mathematically grounded route to intrinsic interpretability for scientific operator learning, reducing dependence on post-hoc attribution methods.
major comments (3)
- [Abstract] Abstract: the central claim that the operator can be rewritten as a linear combination of generalized functional linear models while preserving original predictive accuracy is unsupported by any reported error metrics, ablation of the decomposition step, or side-by-side comparison of the original versus reformulated model on the blood-flow or aerodynamics tasks.
- [Abstract] Abstract: no equations, kernel definitions, or fitting procedure are supplied for the subdomain integrals or linear coefficients, leaving open whether the decomposition is exact for the target operator class or an approximation whose error could be misread as physically meaningful spatial attributions.
- [Abstract] Abstract: the reported demonstrations show gradient-aligned attributions but supply neither quantitative fidelity measures (e.g., correlation with known physical features, perturbation-based explanation tests) nor verification that the attributions remain stable under changes to the subdomain partition.
minor comments (1)
- The abstract would be strengthened by naming the concrete neural-operator architectures (FNO, DeepONet, etc.) to which the reformulation is applied.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the presentation of the self-explainable operator learning framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the operator can be rewritten as a linear combination of generalized functional linear models while preserving original predictive accuracy is unsupported by any reported error metrics, ablation of the decomposition step, or side-by-side comparison of the original versus reformulated model on the blood-flow or aerodynamics tasks.
Authors: The reformulation is constructed to be exact for the target operator class by exploiting the additive decomposability of the integral equations, implying preservation of predictive accuracy by design. We acknowledge, however, that explicit empirical verification strengthens the claim. In the revised manuscript we will add a direct comparison of predictive errors (relative L2 norms) between the original neural operator and the reformulated self-explainable version on both the blood-flow and aerodynamics tasks, together with an ablation isolating the decomposition step. revision: yes
-
Referee: [Abstract] Abstract: no equations, kernel definitions, or fitting procedure are supplied for the subdomain integrals or linear coefficients, leaving open whether the decomposition is exact for the target operator class or an approximation whose error could be misread as physically meaningful spatial attributions.
Authors: Abstracts conventionally omit detailed equations to preserve readability. The full manuscript supplies the integral-equation reformulation, kernel definitions, and the procedure for obtaining the linear coefficients in Sections 2 and 3; the decomposition is exact by the additive property of the generalized functional linear models. We will revise the abstract to include a brief pointer to these sections. revision: partial
-
Referee: [Abstract] Abstract: the reported demonstrations show gradient-aligned attributions but supply neither quantitative fidelity measures (e.g., correlation with known physical features, perturbation-based explanation tests) nor verification that the attributions remain stable under changes to the subdomain partition.
Authors: We agree that quantitative fidelity and stability analyses would provide stronger support. The current demonstrations already show qualitative agreement with gradients and post-hoc explainers. In the revision we will add Pearson correlations between attribution maps and known physical features (gradient magnitudes), perturbation-based tests, and results demonstrating attribution stability across multiple subdomain partitions for both application domains. revision: yes
Circularity Check
No significant circularity; reformulation is an architectural choice, not a reduction to fitted inputs.
full rationale
The paper proposes reformulating neural operators as linear combinations of generalized functional linear models via integral equations to embed subdomain-based interpretability. This is presented as a direct modeling decision that exploits additive decomposability, with explanations arising by construction from the chosen structure rather than from any post-hoc fitting or self-referential derivation. No load-bearing self-citation, uniqueness theorem, or fitted parameter renamed as a prediction is evident. The central claim of embedded explainability without external tools follows from the framework definition itself and remains independent of the training data or prior results. Demonstrations are qualitative and do not reduce any claimed spatial attribution to a tautological fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Operator learning models can be reformulated as linear combinations of generalized functional linear models expressed through integral equations.
Reference graph
Works this paper leans on
-
[1]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead
C. Rudin. “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead”. In:Nature machine intelligence1.5 (2019), pp. 206–215
2019
-
[2]
Interpretability of machine-learning models in physical sciences
L. M. Ghiringhelli. “Interpretability of machine-learning models in physical sciences”. In: arXiv preprint arXiv:2104.10443(2021)
-
[3]
Scientific inference with in- terpretable machine learning: Analyzing models to learn about real-world phenomena
T. Freiesleben, G. K¨ onig, C. Molnar, and A. Tejero-Cantero. “Scientific inference with in- terpretable machine learning: Analyzing models to learn about real-world phenomena”. In: Minds and Machines34.3 (2024), p. 32
2024
-
[4]
Interpretable models for extrapolation in scientific machine learning
E. S. Muckley, J. E. Saal, B. Meredig, C. S. Roper, and J. H. Martin. “Interpretable models for extrapolation in scientific machine learning”. In:Digital Discovery2.5 (2023), pp. 1425– 1435
2023
-
[5]
Learning operators with coupled attention
G. Kissas, J. H. Seidman, L. F. Guilhoto, V. M. Preciado, G. J. Pappas, and P. Perdikaris. “Learning operators with coupled attention”. In:Journal of Machine Learning Research 23.215 (2022), pp. 1–63
2022
-
[6]
Neural operator: Learning maps between function spaces with applications to PDEs
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, and A. Anandku- mar. “Neural operator: Learning maps between function spaces with applications to PDEs”. In:Journal of Machine Learning Research24.89 (2023), pp. 1–97
2023
-
[7]
An explainable operator approximation framework un- der the guideline of Green’s function
J. Gu, L. Wen, Y. Chen, and S. Chen. “An explainable operator approximation framework un- der the guideline of Green’s function”. In:Journal of Computational Physics(2025), p. 114244
2025
-
[8]
How to understand masked autoencoders
S. Cao, P. Xu, and D. A. Clifton. “How to understand masked autoencoders”. In:arXiv preprint arXiv:2202.03670(2022)
-
[9]
Scalable transformer for PDE surrogate modeling
Z. Li, D. Shu, and A. Barati Farimani. “Scalable transformer for PDE surrogate modeling”. In:Advances in Neural Information Processing Systems36 (2023), pp. 28010–28039
2023
-
[10]
Interpreting and generalizing deep learning in physics-based problems with functional linear models
A. Arzani, L. Yuan, P. Newell, and B. Wang. “Interpreting and generalizing deep learning in physics-based problems with functional linear models”. In:Engineering with Computers41.1 (2025), pp. 135–157
2025
-
[11]
Horv´ ath and P
L. Horv´ ath and P. Kokoszka.Inference for functional data with applications. Vol. 200. Springer Science & Business Media, 2012
2012
-
[12]
Fourier Neural Operator for Parametric Partial Differential Equations
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandku- mar. “Fourier neural operator for parametric partial differential equations”. In:arXiv preprint arXiv:2010.08895(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
L. Lu, P. Jin, and G. E. Karniadakis. “Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators”. In:arXiv preprint arXiv:1910.03193(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[14]
The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery
Z. C. Lipton. “The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery.” In:Queue16.3 (2018), pp. 31–57
2018
-
[15]
W. Samek, T. Wiegand, and K.-R. M¨ uller. “Explainable artificial intelligence: Understand- ing, visualizing and interpreting deep learning models”. In:arXiv preprint arXiv:1708.08296 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Kernel methods in machine learning
T. Hofmann, B. Sch¨ olkopf, and A. J. Smola. “Kernel methods in machine learning”. In:The Annals of Statistics36.3 (2008), pp. 1171–1220. p. 45
2008
-
[17]
Explainable machine learning for scientific insights and discoveries
R. Roscher, B. Bohn, M. F. Duarte, and J. Garcke. “Explainable machine learning for scientific insights and discoveries”. In:Ieee Access8 (2020), pp. 42200–42216
2020
-
[18]
Interpretable machine learning: definitions, methods, and applications
W. J. Murdoch, C. Singh, K. Kumbier, R. Abbasi-Asl, and B. Yu. “Interpretable machine learning: definitions, methods, and applications”. In:arXiv preprint arXiv:1901.04592(2019)
-
[19]
Interpretable and explainable machine learning: A methods- centric overview with concrete examples
R. Marcinkeviˇ cs and J. E. Vogt. “Interpretable and explainable machine learning: A methods- centric overview with concrete examples”. In:Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery13.3 (2023), e1493
2023
-
[20]
Informed machine learning–a taxonomy and sur- vey of integrating prior knowledge into learning systems
L. Von Rueden, S. Mayer, K. Beckh, B. Georgiev, S. Giesselbach, R. Heese, B. Kirsch, J. Pfrommer, A. Pick, R. Ramamurthy, et al. “Informed machine learning–a taxonomy and sur- vey of integrating prior knowledge into learning systems”. In:IEEE Transactions on Knowl- edge and Data Engineering35.1 (2021), pp. 614–633
2021
-
[21]
Automated, predictive, and interpretable in- ference of Caenorhabditis elegans escape dynamics
B. C. Daniels, W. S. Ryu, and I. Nemenman. “Automated, predictive, and interpretable in- ference of Caenorhabditis elegans escape dynamics”. In:Proceedings of the National Academy of Sciences116.15 (2019), pp. 7226–7231
2019
-
[22]
Learning integral operators via neural integral equations
E. Zappala, A. H. d. O. Fonseca, J. O. Caro, A. H. Moberly, M. J. Higley, J. Cardin, and D. v. Dijk. “Learning integral operators via neural integral equations”. In:Nature Machine Intelligence6.9 (2024), pp. 1046–1062
2024
-
[23]
Interpretable learning of effective dynamics for multiscale systems
E. Menier, S. Kaltenbach, M. Yagoubi, M. Schoenauer, and P. Koumoutsakos. “Interpretable learning of effective dynamics for multiscale systems”. In:Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences481.2305 (2025)
2025
-
[24]
Design of distributed rule-based models in the presence of large data
E Hanyu, Y. Cui, W. Pedrycz, and Z. Li. “Design of distributed rule-based models in the presence of large data”. In:IEEE Transactions on Fuzzy Systems31.7 (2022), pp. 2479–2486
2022
-
[25]
Supersparse linear integer models for optimized medical scoring systems
B. Ustun and C. Rudin. “Supersparse linear integer models for optimized medical scoring systems”. In:Machine Learning102.3 (2016), pp. 349–391
2016
-
[26]
Generalized additive models
T. Hastie and R. Tibshirani. “Generalized additive models”. In:Statistical science1.3 (1986), pp. 297–310
1986
-
[27]
Sparse additive models
P. Ravikumar, J. Lafferty, H. Liu, and L. Wasserman. “Sparse additive models”. In:Journal of the Royal Statistical Society Series B: Statistical Methodology71.5 (2009), pp. 1009–1030
2009
-
[28]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
M. Cranmer. “Interpretable machine learning for science with PySR and SymbolicRegression. jl”. In:arXiv preprint arXiv:2305.01582(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Explainable AI: A review of machine learning interpretability methods
P. Linardatos, V. Papastefanopoulos, and S. Kotsiantis. “Explainable AI: A review of machine learning interpretability methods”. In:Entropy23.1 (2020), p. 18
2020
-
[30]
Feature importance ranking for deep learning
M. Wojtas and K. Chen. “Feature importance ranking for deep learning”. In:Advances in neural information processing systems33 (2020), pp. 5105–5114
2020
-
[31]
” Why should I trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin. “” Why should I trust you?” Explaining the predic- tions of any classifier”. In:Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016, pp. 1135–1144
2016
-
[32]
A unified approach to interpreting model predictions
S. M. Lundberg and S.-I. Lee. “A unified approach to interpreting model predictions”. In: Advances in neural information processing systems30 (2017)
2017
-
[33]
Axiomatic attribution for deep networks
M. Sundararajan, A. Taly, and Q. Yan. “Axiomatic attribution for deep networks”. In:Inter- national conference on machine learning. PMLR. 2017, pp. 3319–3328. p. 46
2017
-
[34]
Explainable AI (XAI): Core ideas, techniques, and solutions
R. Dwivedi, D. Dave, H. Naik, S. Singhal, R. Omer, P. Patel, B. Qian, Z. Wen, T. Shah, G. Morgan, et al. “Explainable AI (XAI): Core ideas, techniques, and solutions”. In:ACM computing surveys55.9 (2023), pp. 1–33
2023
-
[35]
Visualizing and understanding convolutional networks
M. D. Zeiler and R. Fergus. “Visualizing and understanding convolutional networks”. In: European conference on computer vision. Springer. 2014, pp. 818–833
2014
-
[36]
Grad-CAM: visual explanations from deep networks via gradient-based localization
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. “Grad-CAM: visual explanations from deep networks via gradient-based localization”. In:International journal of computer vision128.2 (2020), pp. 336–359
2020
-
[37]
Evaluation of post-hoc interpretability methods in time-series classification
H. Turb´ e, M. Bjelogrlic, C. Lovis, and G. Mengaldo. “Evaluation of post-hoc interpretability methods in time-series classification”. In:Nature Machine Intelligence5.3 (2023), pp. 250– 260
2023
-
[38]
The level of strength of an explanation: A quantitative evaluation technique for post-hoc XAI methods
M. Bello, R. Amador, M.-M. Garc´ ıa, J. Del Ser, P. Mesejo, and ´O. Cord´ on. “The level of strength of an explanation: A quantitative evaluation technique for post-hoc XAI methods”. In:Pattern Recognition161 (2025), p. 111221
2025
-
[39]
Identifying regions of importance in wall- bounded turbulence through explainable deep learning
A. Cremades, S. Hoyas, R. Deshpande, P. Quintero, M. Lellep, W. J. Lee, J. P. Monty, N. Hutchins, M. Linkmann, I. Marusic, et al. “Identifying regions of importance in wall- bounded turbulence through explainable deep learning”. In:Nature Communications15.1 (2024), p. 3864
2024
-
[40]
Explainable AI in aerospace for enhanced system performance
S. Sutthithatip, S. Perinpanayagam, S. Aslam, and A. Wileman. “Explainable AI in aerospace for enhanced system performance”. In:2021 IEEE/AIAA 40th Digital Avionics Systems Con- ference (DASC). IEEE. 2021, pp. 1–7
2021
-
[41]
Explainable AI in drug discovery: self-interpretable graph neural network for molecular property prediction using concept whitening
M. Proietti, A. Ragno, B. L. Rosa, R. Ragno, and R. Capobianco. “Explainable AI in drug discovery: self-interpretable graph neural network for molecular property prediction using concept whitening”. In:Machine Learning113.4 (2024), pp. 2013–2044
2024
-
[42]
Optimization of wearable biosensor data for stress classification using machine learning and explainable AI
D. Sethia, S Indu, et al. “Optimization of wearable biosensor data for stress classification using machine learning and explainable AI”. In:IEEE Access(2024)
2024
-
[43]
Scientific exploration and explainable artificial intelligence
C. Zednik and H. Boelsen. “Scientific exploration and explainable artificial intelligence”. In: Minds and Machines32.1 (2022), pp. 219–239
2022
-
[44]
From kepler to newton: Explainable AI for science discovery
Z. Li, J. Ji, and Y. Zhang. “From kepler to newton: Explainable AI for science discovery”. In: arXiv preprint arXiv:2111.12210(2021)
-
[45]
Explainable AI-driven IoMT fusion: Unravelling techniques, opportunities, and challenges with Explainable AI in healthcare
N. A. Wani, R. Kumar, J. Bedi, I. Rida, et al. “Explainable AI-driven IoMT fusion: Unravelling techniques, opportunities, and challenges with Explainable AI in healthcare”. In:Information Fusion110 (2024), p. 102472
2024
-
[46]
Explainable artificial intelligence for botnet detection in internet of things
M. Saied and S. Guirguis. “Explainable artificial intelligence for botnet detection in internet of things”. In:Scientific Reports15.1 (2025), p. 7632
2025
-
[47]
SFX-GAN: sustainable and explainable multi-modal spectral fusion for image dehazing in complex systems
P. Dwivedia, V. Agarwal, N. A. Wani, M. Kajal, and A. Bennour. “SFX-GAN: sustainable and explainable multi-modal spectral fusion for image dehazing in complex systems”. In:Complex & Intelligent Systems(2026)
2026
-
[48]
How can I choose an explainer? An application-grounded evaluation of post-hoc explanations
S. Jesus, C. Bel´ em, V. Balayan, J. Bento, P. Saleiro, P. Bizarro, and J. Gama. “How can I choose an explainer? An application-grounded evaluation of post-hoc explanations”. In: Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. 2021, pp. 805–815. p. 47
2021
-
[49]
On the tractability of SHAP explanations
G. Van den Broeck, A. Lykov, M. Schleich, and D. Suciu. “On the tractability of SHAP explanations”. In:Journal of Artificial Intelligence Research74 (2022), pp. 851–886
2022
-
[50]
Fooling LIME and SHAP: Adversar- ial attacks on post hoc explanation methods
D. Slack, S. Hilgard, E. Jia, S. Singh, and H. Lakkaraju. “Fooling LIME and SHAP: Adversar- ial attacks on post hoc explanation methods”. In:Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society. 2020, pp. 180–186
2020
-
[51]
M. Lowery, J. Turnage, Z. Morrow, J. D. Jakeman, A. Narayan, S. Zhe, and V. Shankar. “Kernel neural operators (KNOs) for scalable, memory-efficient, geometrically-flexible opera- tor learning”. In:arXiv preprint arXiv:2407.00809(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Functional linear model
H. Cardot, F. Ferraty, and P. Sarda. “Functional linear model”. In:Statistics & Probability Letters45.1 (1999), pp. 11–22
1999
-
[53]
Functional data analysis
J.-L. Wang, J.-M. Chiou, and H.-G. M¨ uller. “Functional data analysis”. In:Annual Review of Statistics and its application3.1 (2016), pp. 257–295
2016
-
[54]
P. J. Phillips, C. A. Hahn, P. C. Fontana, A. Yates, K. Greene, D. A. Broniatowski, and M. A. Przybocki.Four principles of explainable artificial intelligence. Tech. rep. National Institute of Standards and Technology, 2021
2021
-
[55]
Functional generalized additive models
M. W. McLean, G. Hooker, A.-M. Staicu, F. Scheipl, and D. Ruppert. “Functional generalized additive models”. In:Journal of Computational and Graphical Statistics23.1 (2014), pp. 249– 269
2014
-
[56]
Lift & learn: Physics-informed machine learning for large-scale nonlinear dynamical systems
E. Qian, B. Kramer, B. Peherstorfer, and K. Willcox. “Lift & learn: Physics-informed machine learning for large-scale nonlinear dynamical systems”. In:Physica D: Nonlinear Phenomena 406 (2020), p. 132401
2020
-
[57]
Exact and inexact lifting transformations of nonlinear dynamical systems: Transfer functions, equivalence, and complexity reduction
I. V. Gosea. “Exact and inexact lifting transformations of nonlinear dynamical systems: Transfer functions, equivalence, and complexity reduction”. In:Applied Sciences12.5 (2022), p. 2333
2022
-
[58]
ADAM-SINDy: An efficient optimiza- tion framework for parameterized nonlinear dynamical system identification
S. Viknesh, Y. Tatari, C. Christenson, and A. Arzani. “ADAM-SINDy: An efficient optimiza- tion framework for parameterized nonlinear dynamical system identification”. In:Physical review research8.1 (2026), p. 013040
2026
-
[59]
Analysis of fluid flows via spectral properties of the Koopman operator
I. Mezi´ c. “Analysis of fluid flows via spectral properties of the Koopman operator”. In:Annual review of fluid mechanics45.1 (2013), pp. 357–378
2013
-
[60]
A kernel-based method for data-driven Koopman spectral analysis
M. O. Williams, C. W. Rowley, and I. G. Kevrekidis. “A kernel-based method for data-driven Koopman spectral analysis”. In:Journal of Computational Dynamics2.2 (2015), pp. 247–265. doi:10.3934/jcd.2015005
-
[61]
A review and comparison of bandwidth selection methods for kernel regression
M. K¨ ohler, A. Schindler, and S. Sperlich. “A review and comparison of bandwidth selection methods for kernel regression”. In:International Statistical Review82.2 (2014), pp. 243–274
2014
-
[62]
Bandwidth selection for kernel distribution function estimation
N. Altman and C. Leger. “Bandwidth selection for kernel distribution function estimation”. In:Journal of Statistical Planning and Inference46.2 (1995), pp. 195–214
1995
-
[63]
Molnar.Interpretable machine learning
C. Molnar.Interpretable machine learning. Lulu. com, 2020
2020
-
[64]
U-net: Convolutional networks for biomedical im- age segmentation
O. Ronneberger, P. Fischer, and T. Brox. “U-net: Convolutional networks for biomedical im- age segmentation”. In:International Conference on Medical image computing and computer- assisted intervention. Springer. 2015, pp. 234–241
2015
-
[65]
Comparing different nonlinear dimensionality reduction techniques for data-driven unsteady fluid flow modeling
H. Csala, S. Dawson, and A. Arzani. “Comparing different nonlinear dimensionality reduction techniques for data-driven unsteady fluid flow modeling”. In:Physics of Fluids34.11 (2022). p. 48
2022
-
[66]
The story of wall shear stress in coronary artery atherosclerosis: biochemical transport and mechanotransduction
M. Mahmoudi, A. Farghadan, D. R. McConnell, A. J. Barker, J. J. Wentzel, M. J. Budoff, and A. Arzani. “The story of wall shear stress in coronary artery atherosclerosis: biochemical transport and mechanotransduction”. In:Journal of biomechanical engineering143.4 (2021), p. 041002
2021
-
[67]
Wall shear stress topological skeleton independently predicts long-term restenosis after carotid bifurcation endarterectomy
U. Morbiducci, V. Mazzi, M. Domanin, G. De Nisco, C. Vergara, D. A. Steinman, and D. Gallo. “Wall shear stress topological skeleton independently predicts long-term restenosis after carotid bifurcation endarterectomy”. In:Annals of biomedical engineering48.12 (2020), pp. 2936–2949
2020
-
[68]
Drag prediction of rough-wall turbulent flow using data-driven regression
Z. Shi, S. M. H. Khorasani, H. Shin, J. Yang, S. Lee, and S. Bagheri. “Drag prediction of rough-wall turbulent flow using data-driven regression”. In:Flow5 (2025), E5
2025
-
[69]
A database for reduced-complexity modeling of fluid flows
A. Towne, S. T. Dawson, G. A. Br` es, A. Lozano-Dur´ an, T. Saxton-Fox, A. Parthasarathy, A. R. Jones, H. Biler, C.-A. Yeh, H. D. Patel, et al. “A database for reduced-complexity modeling of fluid flows”. In:AIAA journal61.7 (2023), pp. 2867–2892
2023
-
[70]
Neural operators with localized integral and differential kernels
M. Liu-Schiaffini, J. Berner, B. Bonev, T. Kurth, K. Azizzadenesheli, and A. Anandkumar. “Neural operators with localized integral and differential kernels”. In:Proceedings of the 41st International Conference on Machine Learning (ICML). 2024, pp. 32576–32594
2024
-
[71]
Discovering governing equations from data by sparse identification of nonlinear dynamical systems
S. L. Brunton, J. L. Proctor, and J. N. Kutz. “Discovering governing equations from data by sparse identification of nonlinear dynamical systems”. In:Proceedings of the national academy of sciences113.15 (2016), pp. 3932–3937
2016
-
[72]
Neural additive models: Interpretable machine learning with neural nets
R. Agarwal, L. Melnick, N. Frosst, X. Zhang, B. Lengerich, R. Caruana, and G. E. Hinton. “Neural additive models: Interpretable machine learning with neural nets”. In:Advances in neural information processing systems34 (2021), pp. 4699–4711
2021
-
[73]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anand- kumar. “Neural operator: Graph kernel network for partial differential equations”. In:arXiv preprint arXiv:2003.03485(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[74]
C. K. Williams and C. E. Rasmussen.Gaussian processes for machine learning. Vol. 2. 3. MIT press Cambridge, MA, 2006
2006
-
[75]
Deep Convolutional Networks as shal- low Gaussian Processes
A. Garriga-Alonso, C. E. Rasmussen, and L. Aitchison. “Deep Convolutional Networks as shal- low Gaussian Processes”. In:International Conference on Learning Representations (ICLR). 2019
2019
-
[76]
Discriminative feature attributions: Bridging post hoc explainability and inherent interpretability
U. Bhalla, S. Srinivas, and H. Lakkaraju. “Discriminative feature attributions: Bridging post hoc explainability and inherent interpretability”. In:Advances in Neural Information Process- ing Systems36 (2023), pp. 44105–44122
2023
-
[77]
Sanity checks for saliency maps
J. Adebayo, J. Gilmer, M. Muelly, I. Goodfellow, M. Hardt, and B. Kim. “Sanity checks for saliency maps”. In:Advances in neural information processing systems31 (2018)
2018
-
[78]
The (un)reliability of saliency methods
P.-J. Kindermans, S. Hooker, J. Adebayo, M. Alber, K. T. Sch¨ utt, S. D¨ ahne, D. Erhan, and B. Kim. “The (un)reliability of saliency methods”. In:Explainable AI: Interpreting, Explaining and Visualizing Deep Learning. Springer, 2019, pp. 267–280
2019
-
[79]
RISE: Randomized input sampling for explanation of black-box models
V. Petsiuk, A. Das, and K. Saenko. “RISE: Randomized input sampling for explanation of black-box models”. In:British Machine Vision Conference (BMVC). 2018
2018
-
[80]
Interpretable explanations of black boxes by meaningful per- turbation
R. C. Fong and A. Vedaldi. “Interpretable explanations of black boxes by meaningful per- turbation”. In:Proceedings of the IEEE international conference on computer vision. 2017, pp. 3429–3437. p. 49
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.