Extreme Adaptive Transformer for Time Series Forecasting
Pith reviewed 2026-07-03 16:29 UTC · model grok-4.3
The pith
Exformer adds an extreme-specific attention component to better forecast rare peaks in imbalanced time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
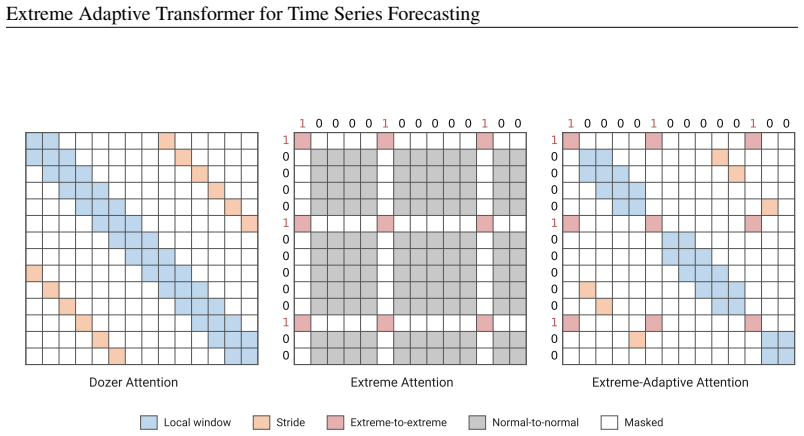
Exformer introduces an extreme-adaptive attention mechanism composed of Local, Stride, and Extreme sparse components. The Extreme component selectively models event-aware dependencies between normal and extreme streamflow patterns, enabling superior performance in forecasting imbalanced time series with rare consequential events.
What carries the argument
extreme-adaptive attention mechanism with Local, Stride, and Extreme sparse components that capture short-term, periodic, and event-aware dependencies respectively
Load-bearing premise
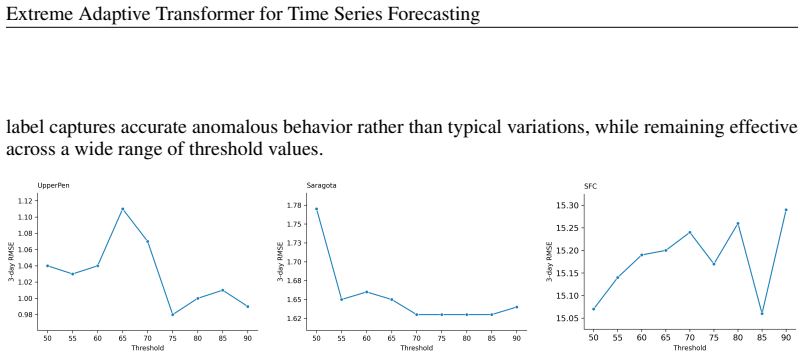
The extreme component selectively models event-aware dependencies between normal and extreme patterns in a way that holds beyond the four tested datasets and the specific definition of extremes used.
What would settle it
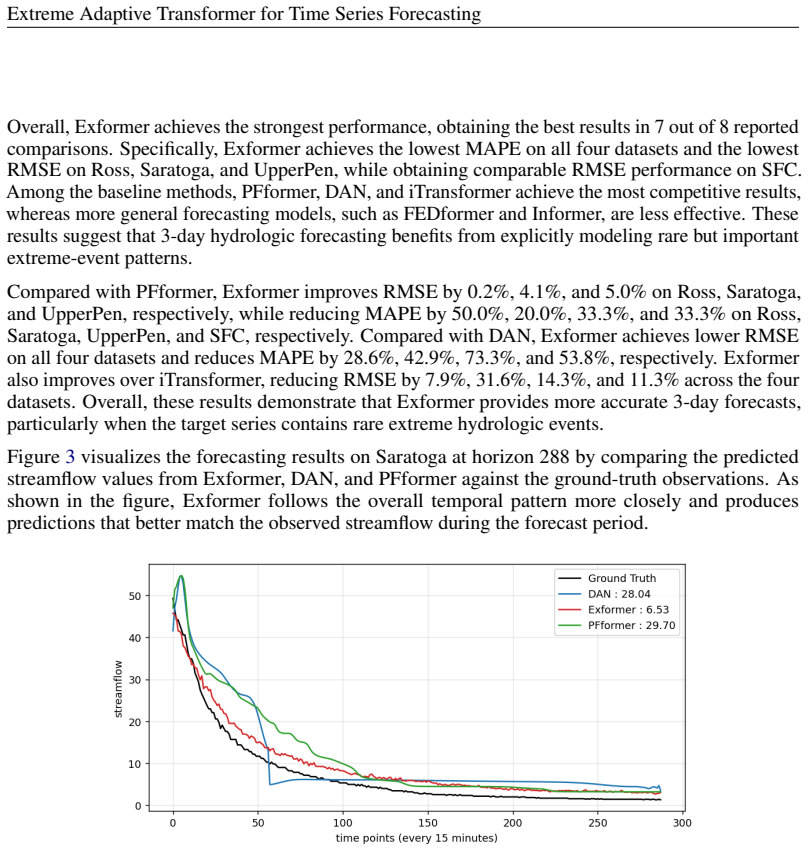
If a new hydrologic streamflow dataset with a different extreme threshold shows Exformer no longer outperforming baselines on 3-day forecasts, the central performance claim would be refuted.
Figures

read the original abstract
Time series forecasting remains challenging when the underlying data contain rare but critical extreme events. This issue is particularly important in hydrologic forecasting, where streamflow distributions are often highly skewed and extreme peaks can have substantial impacts on flood monitoring, water resource management, and early warning systems. Although Transformer-based forecasting models have achieved strong performance by modeling long-range temporal dependencies, they typically treat all time points uniformly and may therefore underrepresent rare extreme patterns. In this paper, we propose the Extreme-Adaptive Transformer (Exformer), a forecasting framework designed to explicitly model temporal dependencies involving both normal and extreme events. Exformer introduces an extreme-adaptive attention mechanism composed of three sparse components: Local, Stride, and Extreme. The Local and Stride components capture short-term and periodic temporal dependencies, respectively, while the Extreme component selectively models event-aware dependencies between normal and extreme streamflow patterns. Experiments on four real-world hydrologic streamflow datasets show that Exformer achieves superior 3-day forecasting performance compared with state-of-the-art baselines. Our findings demonstrate that explicitly incorporating extreme-aware attention improves the forecasting capacity of Transformer models on imbalanced time series with rare but consequential events.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Extreme-Adaptive Transformer (Exformer) for time series forecasting on imbalanced data containing rare extreme events, with a focus on hydrologic streamflow. It introduces an extreme-adaptive attention mechanism consisting of three sparse components (Local for short-term dependencies, Stride for periodic dependencies, and Extreme for event-aware dependencies between normal and extreme patterns). The central empirical claim is that Exformer achieves superior 3-day forecasting performance on four real-world hydrologic datasets relative to state-of-the-art baselines.
Significance. If the performance gains are shown to be statistically significant with appropriate controls and error bars, the work offers a targeted extension of Transformer attention for skewed time series, which could improve applications in flood monitoring and water resource management. The bounded claim on four specific datasets is directly testable and does not rely on parameter-free derivations or machine-checked proofs.
minor comments (3)
- [Abstract] Abstract: the claim of 'superior 3-day forecasting performance' is stated without any quantitative metrics (e.g., MAE, RMSE), error bars, statistical tests, or details on how extreme events were labeled or how the three attention components are combined; this weakens the ability to evaluate the central empirical result.
- [Methods] The manuscript would benefit from a dedicated methods subsection clarifying the integration of the Extreme component with the Local and Stride components and the precise definition of 'event-aware dependencies.'
- [Experiments] Experiments section: include a table reporting per-dataset metrics with standard deviations across multiple runs and baseline comparisons to support the superiority claim.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation of minor revision. We appreciate the recognition that the bounded empirical claim on four hydrologic datasets is directly testable. We will incorporate statistical significance testing and error bars as noted in the significance assessment.
Circularity Check
No significant circularity; empirical claim only
full rationale
The paper advances an empirical claim: on four specific hydrologic streamflow datasets, Exformer outperforms listed baselines at the 3-day horizon. No derivation chain, equations, or first-principles predictions appear in the abstract or description. The model description (extreme-adaptive attention with Local/Stride/Extreme components) is presented as an architectural choice, not as a result derived from prior fitted quantities or self-citations that reduce to the target performance numbers. The reader's weakest_assumption concerns external generalization, which is an external-validity issue rather than an internal reduction of the reported results to their own inputs. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard multi-head attention can be sparsified into independent Local, Stride, and Extreme heads without destroying gradient flow or expressivity.
invented entities (1)
-
Extreme attention component
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Li, Yanhong and Xu, Jack and Anastasiu, David C. , title =. 2024 , isbn =. doi:10.1609/aaai.v38i1.27768 , articleno =
-
[2]
Sparse transformer with local and seasonal adaptation for multivariate time series forecasting
Zhang, Yifan and Wu, Rui and Dascalu, Sergiu M and Harris, Jr, Frederick C. Sparse transformer with local and seasonal adaptation for multivariate time series forecasting. Sci. Rep
-
[3]
2022 , volume =
Zhou, Tian and Ma, Ziqing and Wen, Qingsong and Wang, Xue and Sun, Liang and Jin, Rong , booktitle =. 2022 , volume =
2022
-
[4]
2021 , isbn =
Wu, Haixu and Xu, Jiehui and Wang, Jianmin and Long, Mingsheng , title =. 2021 , isbn =
2021
-
[5]
2023 , url=
Huiqiang Wang and Jian Peng and Feihu Huang and Jince Wang and Junhui Chen and Yifei Xiao , booktitle=. 2023 , url=
2023
-
[6]
and Harris, Frederick C
Zhang, Yifan and Wu, Rui and Dascalu, Sergiu M. and Harris, Frederick C. , journal=. Multi-Scale Transformer Pyramid Networks for Multivariate Time Series Forecasting , year=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i12.17325 , number=
-
[8]
2023 , eprint=
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. 2023 , eprint=
2023
-
[9]
The Eleventh International Conference on Learning Representations , year=
Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
2024 , eprint=
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. 2024 , eprint=
2024
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
An Extreme-Adaptive Time Series Prediction Model Based on Probability-Enhanced LSTM Neural Networks , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , month=. doi:10.1609/aaai.v37i7.26045 , number=
-
[12]
2020 , eprint=
Longformer: The Long-Document Transformer , author=. 2020 , eprint=
2020
-
[13]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Zaheer, Manzil and Guruganesh, Guru and Dubey, Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and Ahmed, Amr , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[14]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence,
Transformers in Time Series: A Survey , author =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence,. 2023 , month =. doi:10.24963/ijcai.2023/759 , url =
-
[15]
2021 , eprint=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
2021
-
[16]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[17]
PFformer: A Position-Free Transformer Variant for Extreme-Adaptive Multivariate Time Series Forecasting
Li, Yanhong and Anastasiu, David C. PFformer: A Position-Free Transformer Variant for Extreme-Adaptive Multivariate Time Series Forecasting. Data Science: Foundations and Applications. 2025
2025
-
[18]
G. E. P. Box and David A. Pierce , title =. Journal of the American Statistical Association , volume =. 1970 , publisher =. doi:10.1080/01621459.1970.10481180 , URL =
-
[19]
Lai, Guokun and Chang, Wei-Cheng and Yang, Yiming and Liu, Hanxiao , title =. 2018 , isbn =. doi:10.1145/3209978.3210006 , booktitle =
-
[20]
2020 , eprint=
N-BEATS: Neural basis expansion analysis for interpretable time series forecasting , author=. 2020 , eprint=
2020
-
[21]
Wu, Zonghan and Pan, Shirui and Long, Guodong and Jiang, Jing and Chang, Xiaojun and Zhang, Chengqi , title =. 2020 , isbn =. doi:10.1145/3394486.3403118 , booktitle =
-
[22]
2022 , eprint=
Are Transformers Effective for Time Series Forecasting? , author=. 2022 , eprint=
2022
-
[23]
Traffic Flow Prediction With Big Data: A Deep Learning Approach , year=
Lv, Yisheng and Duan, Yanjie and Kang, Wenwen and Li, Zhengxi and Wang, Fei-Yue , journal=. Traffic Flow Prediction With Big Data: A Deep Learning Approach , year=
-
[24]
Hewage, Pradeep and Trovati, Marcello and Pereira, Ella and Behera, Ardhendu , title =. Pattern Anal. Appl. , month = feb, pages =. 2021 , issue_date =. doi:10.1007/s10044-020-00898-1 , abstract =
-
[25]
, booktitle=
Mohan, Saloni and Mullapudi, Sahitya and Sammeta, Sudheer and Vijayvergia, Parag and Anastasiu, David C. , booktitle=. Stock Price Prediction Using News Sentiment Analysis , year=
-
[26]
Zhang, Yifan and Wu, Rui and Dascalu, Sergiu M. and Harris, Frederick C. , title=. Scientific Reports , year=. doi:10.1038/s41598-024-53460-y , url=
-
[27]
Earth Science Informatics , year=
Yan, Le and Chen, Changwei and Hang, Tingting and Hu, Youchuan , title=. Earth Science Informatics , year=. doi:10.1007/s12145-021-00571-z , url=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.