UB-SMoE: Universally Balanced Sparse Mixture-of-Experts for Resource-adaptive Federated Fine-tuning of Foundation Models
Pith reviewed 2026-05-20 19:01 UTC · model grok-4.3
The pith
A sparse mixture-of-experts layer with balanced routing and pseudo-gradients lets low-resource clients fine-tune foundation models using far less computation while converging faster than rank-adaptive baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
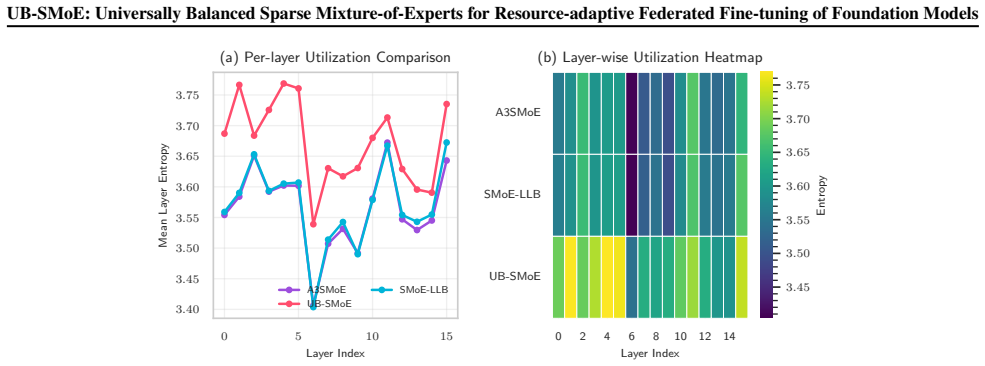
Expert utilization imbalance and non-differentiability of Top-K routing are the dominant causes of degraded convergence when sparse mixture-of-experts is used in heterogeneous federated fine-tuning; Dynamic Modulated Routing rebalances expert activation while Universal Pseudo-Gradient reconstructs learning signals for inactive experts, forming a self-reinforcing cycle that maintains expert viability for every client regardless of resource level.
What carries the argument
Dynamic Modulated Routing (DMR) together with Universal Pseudo-Gradient (PG), which together restore balanced expert utilization and differentiable signals for all experts in a heterogeneous federated setting.
If this is right
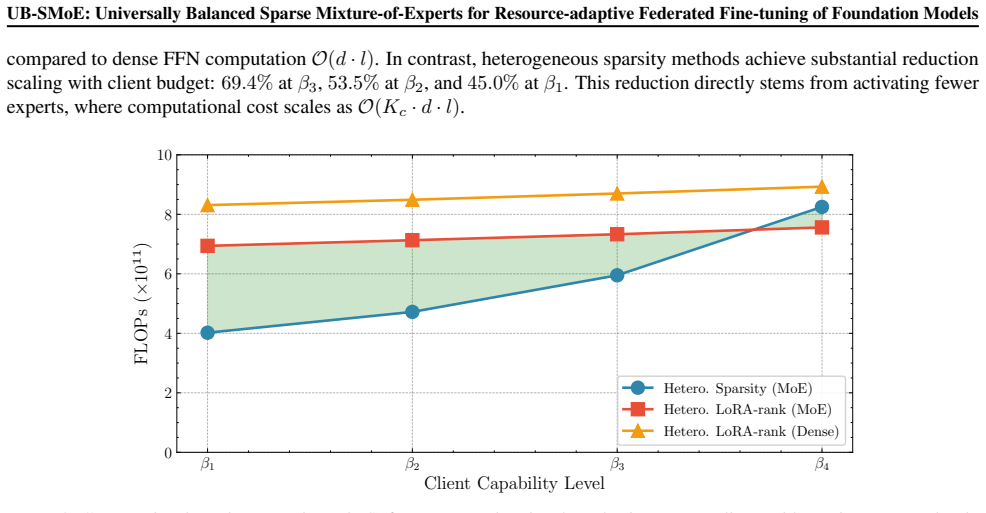
- Low-resource clients obtain up to 45 percent computational reduction while reaching higher accuracy than existing heterogeneous LoRA methods.
- The same routing layer works for every client without needing client-specific model architectures.
- Expert utilization becomes roughly uniform across devices of different capabilities.
- Non-activated experts still receive usable gradient information, preserving their contribution to the overall model.
Where Pith is reading between the lines
- The same balancing mechanisms could be applied to other conditional-computation layers that suffer from routing collapse in distributed training.
- Federated systems might reduce reliance on per-client rank selection if balanced sparse layers prove robust at larger scales.
- Testing the method on vision or multimodal foundation models would reveal whether the self-reinforcing cycle generalizes beyond language tasks.
Load-bearing premise
The two discordances of expert imbalance and non-differentiable routing are the main obstacles to convergence on constrained clients, and fixing them with DMR and PG creates a stable self-reinforcing training cycle across all devices.
What would settle it
A controlled run in which low-resource clients still show worse final accuracy or slower convergence than the LoRA-rank baseline even after DMR and PG are added would falsify the central claim.
Figures





read the original abstract
Heterogeneous LoRA-rank methods address system heterogeneity in federated fine-tuning of foundation models by assigning client-specific ranks based on computational capabilities. However, these methods achieve only marginal computational savings, as dense feed-forward computations dominate. Sparse Mixture-of-Experts (SMoE) provides a promising alternative through conditional computation, yet we identify that its naive application to heterogeneous federated settings introduces two critical discordances: (i) expert utilization imbalance and (ii) non-differentiability of Top-K routing. Our convergence analysis demonstrates that these discordances lead to degraded convergence, particularly for resource-constrained clients. To address these challenges, we propose Universally Balanced Sparse Mixture-of-Experts (UB-SMoE), which introduces Dynamic Modulated Routing (DMR) to rebalance expert utilization, and Universal Pseudo-Gradient (PG) to reconstruct learning signals for non-activated experts. These mechanisms form a self-reinforcing cycle that maintains expert viability across heterogeneous clients. Experiments on benchmarks show that UB-SMoE achieves up to $45.0\%$ computational reduction on low-resource clients while improving their performance by $8.7 \times$ compared to existing heterogeneous LoRA-rank methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Universally Balanced Sparse Mixture-of-Experts (UB-SMoE) for resource-adaptive federated fine-tuning of foundation models. It identifies two discordances in naive SMoE application to heterogeneous federated settings—expert utilization imbalance and non-differentiability of Top-K routing—and provides a convergence analysis showing these degrade performance especially for low-resource clients. Dynamic Modulated Routing (DMR) is introduced to rebalance expert utilization and Universal Pseudo-Gradient (PG) to reconstruct learning signals for non-activated experts, forming a self-reinforcing cycle. Experiments on benchmarks report up to 45% computational reduction on low-resource clients and 8.7× performance improvement relative to heterogeneous LoRA-rank methods, with controls for client resources and ablations isolating each component.
Significance. If the results hold, this work advances federated fine-tuning of large models by enabling effective sparse conditional computation across heterogeneous devices, substantially lowering the burden on resource-constrained clients while improving performance. The convergence analysis supplies theoretical grounding for the mechanisms, and the experiments include resource-level controls plus ablations that isolate DMR and PG contributions. Credit is given for the explicit derivation of mechanisms from identified discordances and for maintaining expert viability without introducing new instabilities.
major comments (2)
- [§3] §3 (Convergence Analysis): the analysis establishes that the two discordances degrade convergence for low-resource clients, yet the quantitative bound or rate at which DMR + PG restores viability and yields the reported 45% compute reduction is not derived explicitly; a direct link from the corrected gradient flow to the observed savings would strengthen the central claim.
- [§5] §5 (Experiments): performance tables report the 8.7× improvement and consistent gains across benchmarks, but lack error bars, number of independent runs, or data-exclusion criteria; without these, the statistical reliability of the cross-client and cross-baseline claims cannot be fully verified from the text.
minor comments (2)
- [§3.3] The notation and update rules for DMR modulation strength and PG reconstruction could be presented with a compact algorithm box or diagram to improve readability of the self-reinforcing cycle.
- [§2] A few sentences in the related-work section would benefit from explicit comparison to recent non-federated SMoE balancing techniques to clarify the federated-specific novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below with clarifications and proposed changes to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Convergence Analysis): the analysis establishes that the two discordances degrade convergence for low-resource clients, yet the quantitative bound or rate at which DMR + PG restores viability and yields the reported 45% compute reduction is not derived explicitly; a direct link from the corrected gradient flow to the observed savings would strengthen the central claim.
Authors: We appreciate this observation. Section 3 derives that the discordances (imbalanced utilization and non-differentiable routing) produce suboptimal gradient flow and slower convergence for low-resource clients. The mechanisms DMR and PG are shown to restore balanced utilization and differentiable signals, forming the self-reinforcing cycle. While an explicit closed-form bound tying the corrected flow directly to the empirical 45% compute reduction is not provided (the savings are measured experimentally under controlled resource heterogeneity), the analysis supplies the necessary theoretical grounding. In revision we will insert a short discussion paragraph after Theorem 3.2 that qualitatively connects the restored per-expert gradient norms to the observed reduction in active parameters on low-resource clients, thereby tightening the theory-experiment link without altering the core proofs. revision: partial
-
Referee: §5 (Experiments): performance tables report the 8.7× improvement and consistent gains across benchmarks, but lack error bars, number of independent runs, or data-exclusion criteria; without these, the statistical reliability of the cross-client and cross-baseline claims cannot be fully verified from the text.
Authors: This is a valid point. All reported results were obtained from five independent runs with distinct random seeds for client sampling, data shuffling, and initialization; means and standard deviations were computed but omitted from the tables for space. No data points were excluded. In the revised manuscript we will augment the tables in §5 with error bars (mean ± std), explicitly state the number of runs, and add a sentence in the experimental setup clarifying the absence of exclusion criteria. These additions will make the statistical reliability transparent while preserving the existing figures and tables. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper identifies two specific discordances (expert utilization imbalance and Top-K non-differentiability) through convergence analysis, then derives DMR and PG mechanisms to restore balance and gradient flow. These steps are motivated by explicitly stated problems rather than being defined in terms of the reported performance gains or fitted to target metrics by construction. No load-bearing self-citations, self-definitional loops, or fitted inputs renamed as predictions appear in the derivation. Experiments include controls for client resources and ablations isolating components, rendering the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- modulation strength and routing bias parameters in DMR
axioms (1)
- domain assumption Convergence analysis assumptions that the self-reinforcing cycle of DMR and PG maintains expert viability
invented entities (2)
-
Dynamic Modulated Routing (DMR)
no independent evidence
-
Universal Pseudo-Gradient (PG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify two critical discordances: (i) expert utilization imbalance and (ii) non-differentiability of Top-K routing. Our convergence analysis demonstrates that these discordances lead to degraded convergence...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1 (Global Convergence Rate under Heterogeneous Sparsity)... bias error term B_SMoE = 2||B(Θ*)||² / μ'
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[2]
International Conference on Machine Learning , pages=
LoRA+: Efficient Low Rank Adaptation of Large Models , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[3]
Nature Machine Intelligence , volume=
Parameter-efficient fine-tuning of large-scale pre-trained language models , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[4]
The Twelfth International Conference on Learning Representations , year=
Improving LoRA in Privacy-preserving Federated Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[5]
arXiv preprint arXiv:2504.21099 , year=
A survey on parameter-efficient fine-tuning for foundation models in federated learning , author=. arXiv preprint arXiv:2504.21099 , year=
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Heterogeneous LoRA for Federated Fine-tuning of On-Device Foundation Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[7]
Federated fine-tuning of large language models under heterogeneous tasks and client resources
Federated fine-tuning of large language models under heterogeneous tasks and client resources , author=. arXiv preprint arXiv:2402.11505 , year=
-
[8]
arXiv preprint arXiv:2502.15436 , year=
Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-Tuning , author=. arXiv preprint arXiv:2502.15436 , year=
-
[9]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Feddat: An approach for foundation model finetuning in multi-modal heterogeneous federated learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
arXiv preprint arXiv:2506.09199 , year=
FLoRIST: Singular Value Thresholding for Efficient and Accurate Federated Fine-Tuning of Large Language Models , author=. arXiv preprint arXiv:2506.09199 , year=
-
[12]
Revisiting Sparse Mixture of Experts for Resource-adaptive Federated Fine-tuning Foundation Models , author=. ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning , year=
work page 2025
-
[13]
International Conference on Learning Representations , year=
On the Convergence of FedAvg on Non-IID Data , author=. International Conference on Learning Representations , year=
-
[14]
International Conference on Artificial Intelligence and Statistics , pages=
Communication-Efficient Learning of Deep Networks from Decentralized Data , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2017 , organization=
work page 2017
-
[15]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
St-moe: Designing stable and transferable sparse expert models , author=. arXiv preprint arXiv:2202.08906 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models , author=. arXiv preprint arXiv:2501.11873 , year=
-
[17]
Sparse Backpropagation for MoE Training , author=. Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (WANT@ NeurIPS 2023) , year=
work page 2023
-
[18]
Workshop on Machine Learning and Compression, NeurIPS 2024 , year=
Dense Backpropagation Improves Routing for Sparsely-Gated Mixture-of-Experts , author=. Workshop on Machine Learning and Compression, NeurIPS 2024 , year=
work page 2024
-
[19]
Mean value theorems and functional equations , author=. 1998 , publisher=
work page 1998
-
[20]
Illinois Journal of Mathematics , volume=
A converse to the dominated convergence theorem , author=. Illinois Journal of Mathematics , volume=. 1963 , publisher=
work page 1963
-
[21]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[22]
arXiv preprint arXiv:2501.13985 , year=
Pilot: Building the Federated Multimodal Instruction Tuning Framework , author=. arXiv preprint arXiv:2501.13985 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Federated learning from vision-language foundation models: Theoretical analysis and method , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the ACM Web Conference 2023 , pages=
Pfedprompt: Learning personalized prompt for vision-language models in federated learning , author=. Proceedings of the ACM Web Conference 2023 , pages=
work page 2023
-
[25]
Advances in Mathematics , volume=
Best constants in Young's inequality, its converse, and its generalization to more than three functions , author=. Advances in Mathematics , volume=. 1976 , publisher=
work page 1976
-
[26]
Advances in Neural Information Processing Systems , volume=
Bridging discrete and backpropagation: Straight-through and beyond , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Zhang, Jianyi and Vahidian, Saeed and Kuo, Martin and Li, Chunyuan and Zhang, Ruiyi and Yu, Tong and Wang, Guoyin and Chen, Yiran , booktitle=. Towards Building the. 2024 , organization=
work page 2024
-
[28]
arXiv preprint arXiv:2405.17267 , year=
FedHPL: Efficient Heterogeneous Federated Learning with Prompt Tuning and Logit Distillation , author=. arXiv preprint arXiv:2405.17267 , year=
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Efficient model personalization in federated learning via client-specific prompt generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[30]
FedSelect: Customized Selection of Parameters for Fine-Tuning during Personalized Federated Learning , author=. Federated Learning and Analytics in Practice: Algorithms, Systems, Applications, and Opportunities , year=
-
[31]
International conference on machine learning , pages=
Scaffold: Stochastic controlled averaging for federated learning , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[32]
International Conference on Learning Representations , year=
On the convergence of fedavg on non-iid data , author=. International Conference on Learning Representations , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Convergence analysis of sequential federated learning on heterogeneous data , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
International conference on machine learning , pages=
A unified theory of decentralized SGD with changing topology and local updates , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
- [35]
-
[36]
Advances in Neural Information Processing Systems , volume=
Biased stochastic first-order methods for conditional stochastic optimization and applications in meta learning , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Conference on Learning Theory , pages=
Non-asymptotic analysis of biased stochastic approximation scheme , author=. Conference on Learning Theory , pages=. 2019 , organization=
work page 2019
-
[38]
Optimization methods for large-scale machine learning , author=. SIAM review , volume=. 2018 , publisher=
work page 2018
-
[39]
International conference on machine learning , pages=
SGD: General analysis and improved rates , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[40]
Advances in Neural Information Processing Systems , volume=
A guide through the zoo of biased SGD , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Introductory lectures on convex optimization: A basic course , author=. 2013 , publisher=
work page 2013
-
[42]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
work page 2016
-
[43]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[45]
International conference on machine learning , pages=
Glam: Efficient scaling of language models with mixture-of-experts , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[46]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Dmitry Lepikhin and HyoukJoong Lee and Yuanzhong Xu and Dehao Chen and Orhan Firat and Yanping Huang and Maxim Krikun and Noam Shazeer and Zhifeng Chen , booktitle=. 2021 , url=
work page 2021
-
[49]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Auxiliary-loss-free load balancing strategy for mixture-of-experts , author=. arXiv preprint arXiv:2408.15664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Han and Yuan Zhong , booktitle=
X.Y. Han and Yuan Zhong , booktitle=. A Theoretical Framework for Auxiliary-Loss-Free Load-Balancing of Sparse Mixture-of-Experts in Large-Scale. 2025 , url=
work page 2025
-
[51]
Grin: Gradient-informed moe , author=. arXiv preprint arXiv:2409.12136 , year=
-
[52]
ReMoE: Fully Differentiable Mixture-of-Experts with Re
Ziteng Wang and Jun Zhu and Jianfei Chen , booktitle=. ReMoE: Fully Differentiable Mixture-of-Experts with Re. 2025 , url=
work page 2025
-
[53]
arXiv preprint arXiv:2504.12463 , year=
Dense backpropagation improves training for sparse mixture-of-experts , author=. arXiv preprint arXiv:2504.12463 , year=
-
[54]
A Theoretical Understanding of Gradient Bias in Meta-Reinforcement Learning , volume =
Liu, Bo and Feng, Xidong and Ren, Jie and Mai, Luo and Zhu, Rui and Zhang, Haifeng and Wang, Jun and Yang, Yaodong , booktitle =. A Theoretical Understanding of Gradient Bias in Meta-Reinforcement Learning , volume =
-
[55]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[56]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2018
-
[57]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[58]
SocialIQA: Commonsense Reasoning about Social Interactions
Socialiqa: Commonsense reasoning about social interactions , author=. arXiv preprint arXiv:1904.09728 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[59]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[61]
Wino G rande: An adversarial winograd schema challenge at scale
Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin , title =. 2021 , issue_date =. doi:10.1145/3474381 , journal =
-
[62]
First Workshop on Scalable Optimization for Efficient and Adaptive Foundation Models , year=
FedEx-LoRA: Exact Aggregation for Federated and Efficient Fine-Tuning of Foundation Models , author=. First Workshop on Scalable Optimization for Efficient and Adaptive Foundation Models , year=
-
[63]
arXiv preprint arXiv:2411.19557 , year=
Initialization using update approximation is a silver bullet for extremely efficient low-rank fine-tuning , author=. arXiv preprint arXiv:2411.19557 , year=
-
[64]
OLMoE: Open Mixture-of-Experts Language Models
Olmoe: Open mixture-of-experts language models , author=. arXiv preprint arXiv:2409.02060 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
OLMo: Accelerating the science of language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[66]
Bidirectional encoder representations from transformers (bert) for question answering in the telecom domain.: Adapting a bert-like language model to the telecom domain using the electra pre-training approach , author=
-
[67]
Advances in Neural Information Processing Systems , volume=
Exact and linear convergence for federated learning under arbitrary client participation is attainable , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Analysis of regularized federated learning , author=. Neurocomputing , volume=. 2025 , publisher=
work page 2025
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
EFSkip: A new error feedback with linear speedup for compressed federated learning with arbitrary data heterogeneity , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
Advances in Neural Information Processing Systems , volume=
Every parameter matters: Ensuring the convergence of federated learning with dynamic heterogeneous models reduction , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
Convergence analysis of split federated learning on heterogeneous data , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
arXiv preprint arXiv:2404.08003 , year=
Asynchronous federated reinforcement learning with policy gradient updates: Algorithm design and convergence analysis , author=. arXiv preprint arXiv:2404.08003 , year=
-
[73]
ACM Transactions on Knowledge Discovery from Data , volume=
Convergence-Guaranteed Federated Learning through Gradient Trajectory Smoothing with Triple-Objective Decomposition , author=. ACM Transactions on Knowledge Discovery from Data , volume=. 2025 , publisher=
work page 2025
-
[74]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[75]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Measuring the effects of non-identical data distribution for federated visual classification , author=. arXiv preprint arXiv:1909.06335 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[76]
International conference on machine learning , pages=
Bayesian nonparametric federated learning of neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[77]
ACM Computing Surveys , volume=
Federated learning for computationally constrained heterogeneous devices: A survey , author=. ACM Computing Surveys , volume=. 2023 , publisher=
work page 2023
-
[78]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.