Rethinking Neural Width for Alternating Current Optimal Power Flow Proxies
Pith reviewed 2026-06-28 11:35 UTC · model grok-4.3
The pith
A loss-guided densification algorithm finds neural networks that approximate the ACOPF manifold with up to ten times fewer neurons per layer than standard baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
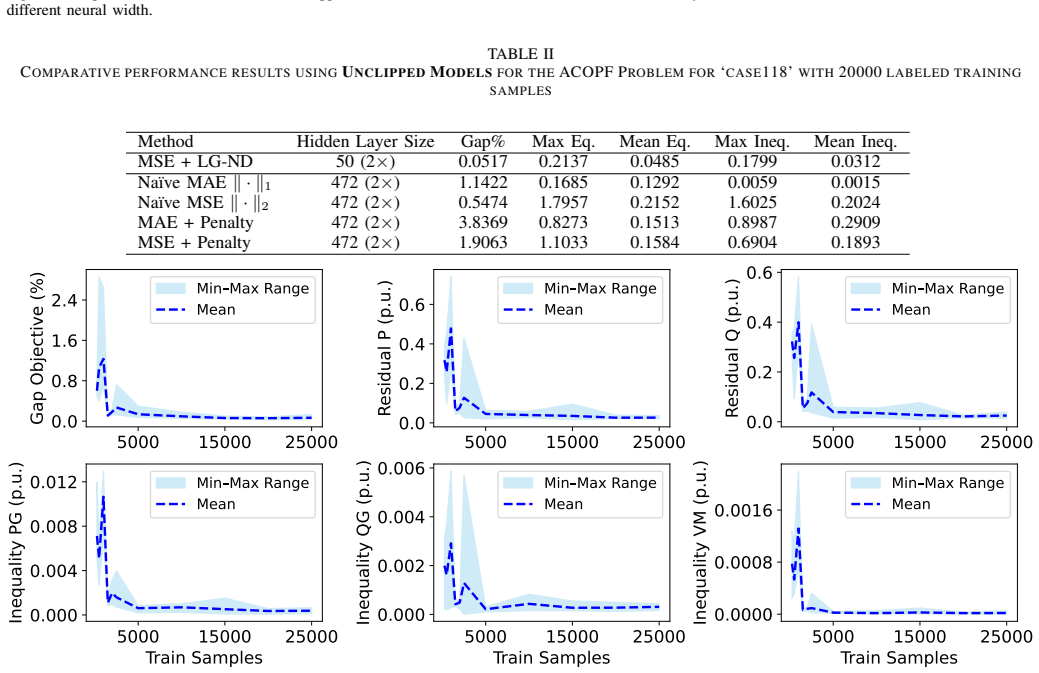
The Loss-Guided Neural Densification (LG-ND) procedure incrementally expands network capacity only when further training yields no loss reduction, thereby locating architectures that match literature baseline performance on ACOPF instances while requiring up to ten times fewer neurons per layer on the examined IEEE systems.
What carries the argument
Loss-Guided Neural Densification (LG-ND), an iterative widening rule that adds neurons to a layer only after loss improvement ceases on the current topology.
If this is right
- The discovered widths supply concrete upper bounds on the neuron count needed for accurate ACOPF proxies.
- Smaller verified networks lower the barrier to deploying provably safe deep-learning controllers in power systems.
- The incremental procedure replaces manual width selection with an automated, loss-driven search.
- Performance parity holds across the range of IEEE test systems examined in the experiments.
Where Pith is reading between the lines
- The same stopping rule might be tested on other manifold-structured regression tasks in optimization.
- Combining LG-ND with pruning after densification could yield even tighter final architectures.
- Running the procedure on larger or stochastic ACOPF instances would test whether the reported neuron savings persist at scale.
Load-bearing premise
That expanding the network only when loss plateaus will locate the smallest viable architecture rather than missing a still-smaller one that could reach the same accuracy.
What would settle it
An exhaustive enumeration or search that identifies any network with fewer neurons than the LG-ND result yet achieves equal or better accuracy on the same IEEE test cases would falsify the claim.
Figures

read the original abstract
Deep learning proxies for Alternating Current Optimal Power Flow (ACOPF) lack systematic methods for determining architectural size. This paper conducts a constructive thought experiment to answer a fundamental inquiry: how wide must a neural network be to almost accurately approximate the ACOPF manifold? We introduce a Loss-Guided Neural Densification (LG-ND) algorithm that incrementally discovers necessary capacity by expanding only when the current deep neural network topology fails to improve further. Empirical results across various IEEE systems show that LG-ND achieves performance parity with literature baselines using up to ten times fewer neurons per layer. Such architectural minimalism is critical for the formal verification required in safety-critical grid operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Loss-Guided Neural Densification (LG-ND), a greedy incremental algorithm that expands neural network width only when loss plateaus on the current topology, to determine minimal widths for deep learning proxies of ACOPF. It claims that the resulting architectures achieve performance parity with literature baselines on multiple IEEE test systems while using up to ten times fewer neurons per layer, with implications for formal verification in grid operations.
Significance. If the widths discovered by LG-ND are near-minimal and the empirical parity holds under rigorous controls, the work would usefully address the lack of systematic architecture sizing for ACOPF proxies and support reduced model sizes for verification. The constructive framing around 'how wide must a network be' is a positive contribution if supported by reproducible experiments.
major comments (2)
- [LG-ND algorithm and empirical evaluation sections] The central empirical claim (performance parity with up to 10x fewer neurons) rests on LG-ND discovering near-minimal viable widths. However, the algorithm only grows the current topology when loss stops improving and performs no backtracking or enumeration of alternative layer-width combinations with equal or fewer total neurons; this leaves open the possibility that more compact architectures exist but were never evaluated. See the description of LG-ND and the experimental results.
- [Experimental results] No ablation or comparison is reported against non-greedy search strategies (e.g., random search over width tuples or pruning-based methods) that could falsify the claim that the discovered widths are minimal or near-minimal. Without such controls, the 'ten times fewer' factor cannot be interpreted as a lower bound on required capacity.
minor comments (2)
- [Introduction / Method] The abstract and introduction would benefit from explicit statements of the loss function, optimizer, and convergence criteria used inside LG-ND, as these directly affect when expansion is triggered.
- [Results tables] Tables reporting neuron counts and test errors should include standard deviations over multiple random seeds to allow assessment of whether the reported parity is statistically reliable.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which highlight important limitations in how the minimality of LG-ND architectures can be interpreted. We respond to each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [LG-ND algorithm and empirical evaluation sections] The central empirical claim (performance parity with up to 10x fewer neurons) rests on LG-ND discovering near-minimal viable widths. However, the algorithm only grows the current topology when loss stops improving and performs no backtracking or enumeration of alternative layer-width combinations with equal or fewer total neurons; this leaves open the possibility that more compact architectures exist but were never evaluated. See the description of LG-ND and the experimental results.
Authors: We agree that LG-ND is a greedy incremental algorithm without backtracking or enumeration of alternative topologies, and therefore does not establish that the discovered widths are minimal or near-minimal. The manuscript frames LG-ND as a constructive method for determining sufficient widths that achieve parity with baselines, rather than as an optimality proof. We will revise the abstract, introduction, and discussion sections to remove any suggestion of near-minimality and instead describe the results as performance parity achieved with substantially reduced widths relative to literature baselines. This revision will be made while preserving the reported empirical outcomes. revision: yes
-
Referee: [Experimental results] No ablation or comparison is reported against non-greedy search strategies (e.g., random search over width tuples or pruning-based methods) that could falsify the claim that the discovered widths are minimal or near-minimal. Without such controls, the 'ten times fewer' factor cannot be interpreted as a lower bound on required capacity.
Authors: The referee is correct that the absence of comparisons to non-greedy methods (such as random search or pruning) means the reported width reductions cannot be interpreted as establishing a lower bound on required capacity. LG-ND is presented as an efficient heuristic tailored to the ACOPF setting. We will update the experimental discussion and conclusions to explicitly note the greedy nature of the algorithm and to frame the 'ten times fewer' factor strictly as an empirical reduction relative to the cited baselines, without claiming it as a capacity lower bound. We view this as a clarification rather than a change to the core contribution. revision: yes
Circularity Check
No circularity; purely empirical algorithm with no derivation or self-referential fitting
full rationale
The paper introduces the LG-ND algorithm as a constructive procedure for incrementally growing network width when loss plateaus, then reports empirical parity with baselines on IEEE test cases using fewer neurons. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on experimental comparison rather than any reduction of outputs to inputs by construction, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opfdata: Large-scale datasets for ac optimal power flow with topological perturbations,
S. Lovett, M. Zgubi ˇc, S. Liguoriet al., “Opfdata: Large-scale datasets for ac optimal power flow with topological perturbations,” arXiv, 2024
2024
-
[2]
Machine learning for ac optimal power flow,
N. Guha, Z. Wang, M. Wytock, and A. Majumdar, “Machine learning for ac optimal power flow,” arXiv:1910.08842, 2019
arXiv 1910
-
[3]
Machine learning-aided security constrained optimal power flow,
J. Rahman, C. Feng, and J. Zhang, “Machine learning-aided security constrained optimal power flow,” in2020 IEEE Power & Energy Society General Meeting (PESGM). IEEE, 2020, pp. 1–5
2020
-
[4]
Predicting ac optimal power flows: Combining deep learning and lagrangian dual methods,
F. Fioretto, T. W. K. Mak, and P. V . Hentenryck, “Predicting ac optimal power flows: Combining deep learning and lagrangian dual methods,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, 2020, pp. 630–637
2020
-
[5]
Deepopf: A feasibility- optimized deep neural network approach for ac optimal power flow problems,
X. Pan, M. Chen, T. Zhao, and S. H. Low, “Deepopf: A feasibility- optimized deep neural network approach for ac optimal power flow problems,” arXiv preprint arXiv:2007.01002, 2020
arXiv 2007
-
[6]
A survey on dynamic neural networks for natural language processing,
C. Xu and J. McAuley, “A survey on dynamic neural networks for natural language processing,” arXiv:1912.09818, 2019
arXiv 1912
-
[7]
Beta-crown: Efficient bound propagation with per-neuron split constraints for neural network robustness verification,
S. Wang, H. Zhanget al., “Beta-crown: Efficient bound propagation with per-neuron split constraints for neural network robustness verification,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 29 909–29 921
2021
-
[8]
A meta-learning approach to the optimal power flow problem under topology reconfigurations,
Y . Chen, S. Lakshminarayanaet al., “A meta-learning approach to the optimal power flow problem under topology reconfigurations,”IEEE Open Access Journal of Power and Energy, vol. 9, pp. 109–120, 2022
2022
-
[9]
Data-driven alternating current optimal power flow: A lagrange multiplier based approach,
X. Lei, J. Yu, H. Aini, and W. Wu, “Data-driven alternating current optimal power flow: A lagrange multiplier based approach,”Energy Reports, vol. 8, no. Supplement 8, pp. 748–755, 2022
2022
-
[10]
Deepopf: A feasibility- optimized deep neural network approach for ac optimal power flow problems,
X. Pan, M. Chen, T. Zhao, and S. H. Low, “Deepopf: A feasibility- optimized deep neural network approach for ac optimal power flow problems,”IEEE Systems Journal, vol. 17, no. 1, pp. 673–683, 2023
2023
-
[11]
Deepopf-u: A unified deep neural network to solve ac optimal power flow in multiple networks,
H. Liang and C. Zhao, “Deepopf-u: A unified deep neural network to solve ac optimal power flow in multiple networks,” arXiv:2309.12849
-
[12]
Physics-informed gradient estimation for accelerating deep learning-based ac-opf,
K. Chen, S. Bose, and Y . Zhang, “Physics-informed gradient estimation for accelerating deep learning-based ac-opf,”IEEE Transactions on Industrial Informatics, vol. 21, no. 6, pp. 4649–4660, 2025
2025
-
[13]
Deepopf-v: Solving ac- opf problems efficiently,
W. Huang, X. Pan, M. Chen, and S. H. Low, “Deepopf-v: Solving ac- opf problems efficiently,”IEEE Transactions on Power Systems, vol. 37, no. 1, pp. 800–803, 2022
2022
-
[14]
Fsnet: Feasibility-seeking neural network for constrained optimization with guarantees,
H. T. Nguyen and P. L. Donti, “Fsnet: Feasibility-seeking neural network for constrained optimization with guarantees,” arXiv preprint arXiv:2506.00362, 2025
arXiv 2025
-
[15]
Self-supervised primal-dual learning for constrained optimization,
S. Park and P. Van Hentenryck, “Self-supervised primal-dual learning for constrained optimization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 4, 2023, pp. 4052–4060
2023
-
[16]
Ml4opf: A machine learning library for optimal power flow problems,
AI4OPT, “Ml4opf: A machine learning library for optimal power flow problems,” https://github.com/AI4OPT/ML4OPF, 2023
2023
-
[17]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learning. MIT Press, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.