Joint Outage Detection and Compensation for Self-Healing 5G RAN via Deep Reinforcement Learning
Pith reviewed 2026-06-30 05:10 UTC · model grok-4.3
The pith
A deep Q-network agent jointly detects and compensates base station outages in 5G networks, reaching 99.1 percent coverage and 54 percent full recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
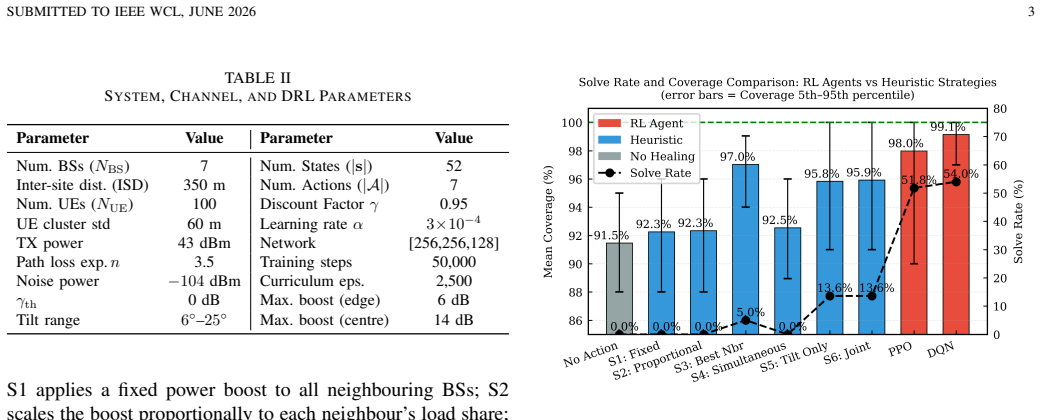
The proposed DQN agent achieves 99.1% coverage and 54% full-recovery rate, an 11× improvement over the best heuristic, while consuming less compensation energy than heuristic baselines and learning, without explicit geometric input, to prefer tilt-only compensation for centre-cell outage.
What carries the argument
A deep Q-Network (DQN) agent that jointly performs three-class cell outage detection and controls power and antenna tilt for compensation.
If this is right
- The agent recovers more than ten times as many outages as the strongest rule-based method.
- It uses less energy for compensation than the heuristic approaches.
- The learned policy favors antenna tilt adjustments alone for outages in the central cell.
- Three-class detection distinguishes normal, failed, and collaterally degraded cells.
Where Pith is reading between the lines
- If deployed, this could allow networks to maintain coverage with fewer human operators during failures.
- Similar reinforcement learning agents might apply to other self-optimizing network functions like load balancing.
- Testing the agent on networks with different cell layouts would show if the tilt preference generalizes.
Load-bearing premise
The simulation environment and outage scenarios used for training and testing accurately reflect real-world 5G RAN propagation, traffic, and failure dynamics.
What would settle it
Running the trained agent in a physical 5G test network and measuring whether it achieves similar coverage and recovery rates when actual base stations fail.
Figures



read the original abstract
Self-healing radio access network (RAN) requires autonomous detection and compensation of base station (BS) failures. This letter proposes an end-to-end framework combining three-class cell outage detection (COD), distinguishing normal, failed, and collaterally degraded cells, with a deep Q-Network (DQN) based deep reinforcement learning (DRL) agent that jointly controls power and antenna tilt for cell outage compensation (COC). Evaluation results show that the proposed DQN agent achieves 99.1% coverage and 54% full-recovery rate, an 11$\times$ improvement over the best heuristic, while consuming less compensation energy than heuristic baselines and learning, without explicit geometric input, to prefer tilt-only compensation for centre-cell outage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an end-to-end self-healing framework for 5G RAN that combines three-class cell outage detection (normal/failed/collaterally degraded) with a DQN-based DRL agent for joint power and tilt compensation. It reports that the agent achieves 99.1% coverage and 54% full-recovery rate (11× over the best heuristic), lower compensation energy, and learns to prefer tilt-only actions for center-cell outages without explicit geometric features.
Significance. If the simulation faithfully captures real 5G propagation, traffic, and failure statistics, the joint COD+COC formulation and the observed policy (tilt preference without geometry) would be a useful contribution to autonomous RAN management. The work ships a concrete DRL formulation and quantitative comparison against heuristics, but the absence of external validation or held-out traces limits the strength of the empirical claims.
major comments (3)
- [Evaluation] Evaluation section: the headline metrics (99.1% coverage, 54% full recovery, 11× heuristic gain) are obtained from a single custom simulation loop with no reported details on channel models (path-loss, shadowing correlation), traffic generation, BS failure statistics, handover margins, or the procedure used to generate the three-class labels. Without these, it is impossible to assess whether the DQN exploits simulator artifacts.
- [Evaluation] Evaluation section: all quantitative results (coverage, recovery rate, energy) derive from the same training/evaluation simulation; no held-out real traces, cross-validation against higher-fidelity tools, or external benchmark datasets are provided, making the circularity between model and policy a load-bearing concern for the claimed generalization.
- [Evaluation] The manuscript states that the DQN learns to prefer tilt-only compensation for centre-cell outage without explicit geometric input, yet no ablation or sensitivity analysis is shown that isolates the contribution of the three-class COD output versus the raw state representation.
minor comments (2)
- [Abstract] The abstract and evaluation should explicitly state the number of independent runs, confidence intervals, and exact definitions of the heuristic baselines (including any tunable parameters).
- [System Model] Notation for the three-class labels and the reward function components should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing evaluation rigor. We address each major comment below and outline revisions to enhance reproducibility and analysis depth.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline metrics (99.1% coverage, 54% full recovery, 11× heuristic gain) are obtained from a single custom simulation loop with no reported details on channel models (path-loss, shadowing correlation), traffic generation, BS failure statistics, handover margins, or the procedure used to generate the three-class labels. Without these, it is impossible to assess whether the DQN exploits simulator artifacts.
Authors: We agree that expanded reporting of simulation parameters is required for reproducibility. In the revised manuscript we will augment the Evaluation section with explicit details on the path-loss model, shadowing correlation, traffic generation, BS failure statistics, handover margins, and the three-class label generation procedure. This will enable readers to evaluate whether the reported gains rely on simulator-specific artifacts. revision: yes
-
Referee: [Evaluation] Evaluation section: all quantitative results (coverage, recovery rate, energy) derive from the same training/evaluation simulation; no held-out real traces, cross-validation against higher-fidelity tools, or external benchmark datasets are provided, making the circularity between model and policy a load-bearing concern for the claimed generalization.
Authors: The study is a simulation-based proposal of an end-to-end framework. We will add a limitations subsection that explicitly discusses the simulation assumptions, the absence of real traces, and the need for future validation against higher-fidelity tools or operator data. The current quantitative comparisons remain internally consistent because all agents (DQN and heuristics) are evaluated under identical conditions; the revision will clarify this scope while acknowledging the generalization concern. revision: partial
-
Referee: [Evaluation] The manuscript states that the DQN learns to prefer tilt-only compensation for centre-cell outage without explicit geometric input, yet no ablation or sensitivity analysis is shown that isolates the contribution of the three-class COD output versus the raw state representation.
Authors: We will incorporate an ablation study that trains and compares DQN agents with and without the three-class COD outputs in the state vector. The revised manuscript will report the resulting policy differences, particularly the tilt-only preference for center-cell outages, thereby isolating the contribution of the COD component. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical DRL framework for COD and COC evaluated via simulation, reporting performance metrics from training and testing the DQN agent against heuristics. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce any claimed result to its inputs by construction. The simulation-based evaluation is a standard empirical methodology and remains self-contained without reducing the central claims to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E-UTRAN; Self-configuring and self-optimizing network (SON) use cases and solutions,
3GPP, “E-UTRAN; Self-configuring and self-optimizing network (SON) use cases and solutions,”3GPP TR 36.902, v9.3.1, Apr. 2011
2011
-
[2]
AI-driven self optimization of 5G network coverage and capacity using multi-agent deep reinforcement learning,
A. Hasan and F. Khalid, “AI-driven self optimization of 5G network coverage and capacity using multi-agent deep reinforcement learning,” IEEE Access, vol. 14, pp. 47952–47967, 2026
2026
-
[3]
Multi-agent deep reinforcement learning for resilience optimization in 5G RAN,
S. Kaada, D.-H. Tran, N. Van Huynh, M.-L. Alberi Morel, S. Jelassi, and G. Rubino, “Multi-agent deep reinforcement learning for resilience optimization in 5G RAN,”arXiv preprint arXiv:2407.18066, 2024
-
[4]
Coverage optimization for large-scale mobile networks with digital twin and multi-agent rein- forcement learning,
H. Liu, T. Li, F. Jiang, W. Su, and Z. Wang, “Coverage optimization for large-scale mobile networks with digital twin and multi-agent rein- forcement learning,”IEEE Transactions on Wireless Communications, vol. 23, no. 12, pp. 18316–18330, Dec. 2024
2024
-
[5]
AI-powered resilience: A dual-approach for outage management in dense cellular networks,
W. Raza, M. U. B. Farooq, A. Ijaz, M. Manalastas, and A. Im- ran, “AI-powered resilience: A dual-approach for outage management in dense cellular networks,”Computer Communications, vol. 236, Art. no. 108129, Apr. 2025
2025
-
[6]
A cell outage management framework for dense heterogeneous networks,
O. Onireti, A. Zoha, J. Moysen, A. Imran, L. Giupponi, M. A. Imran, and A. Abu-Dayya, “A cell outage management framework for dense heterogeneous networks,”IEEE Transactions on V ehicular Technology, vol. 65, no. 4, pp. 2097–2113, Apr. 2016
2097
-
[7]
E-UTRA; Radio frequency (RF) system scenarios,
3GPP, “E-UTRA; Radio frequency (RF) system scenarios,”3GPP TR 36.942, v19.0.0, Oct. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.