ArtifactLinker: Linking Scientific Artifacts for Automatic State-of-the-Art Discovery
Pith reviewed 2026-05-19 20:25 UTC · model grok-4.3
pith:4DIWYDSK Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{4DIWYDSK}
Prints a linked pith:4DIWYDSK badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
An artifact graph of models and datasets lets graph methods rank untested performance links to find new SOTA results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
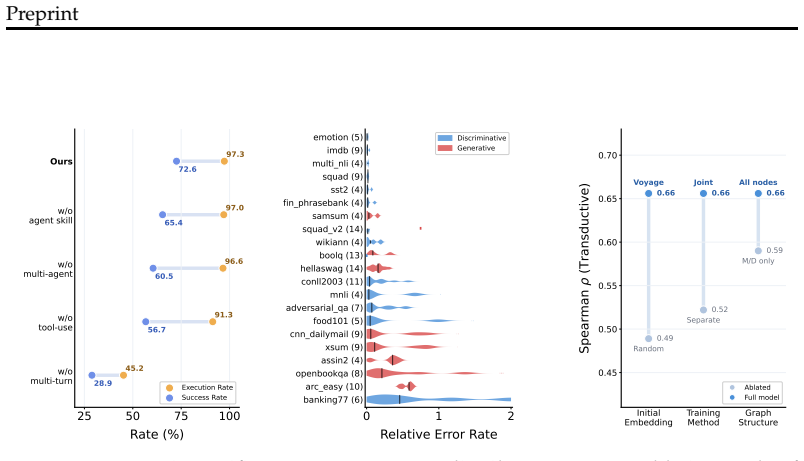
ArtifactLinker models Hugging Face as an artifact graph with models and datasets as nodes and evaluations as edges. The framework ranks missing links via GNNs or graph-augmented LLMs, then verifies top candidates through LLM-based agents that execute coding experiments. On the new ArtifactBench benchmark containing 14,053 artifacts and 51,337 relations, graph structure proves effective for missing link prediction, and the full pipeline identifies potential SOTA results together with research insights.
What carries the argument
The artifact graph, with models and datasets as nodes and known evaluations as edges, which carries the argument by enabling structure-based ranking of unobserved performance links.
If this is right
- Graph structures alone can predict which models will work well on which datasets without direct testing.
- Ranking candidates followed by automated verification surfaces new high-performing combinations.
- The method scales to large artifact collections such as those hosted on Hugging Face.
- End-to-end use generates both SOTA candidates and additional research insights from existing evaluations.
Where Pith is reading between the lines
- The same graph approach could extend to other artifact types such as papers or codebases to link related ideas across fields.
- As more evaluations are published the graph becomes denser, which should improve future prediction accuracy without changing the method.
- Automated systems could run continuously, monitoring new publications and suggesting the next experiments to run.
- Adding node features like model size or architecture details might further strengthen the link predictions beyond pure graph structure.
Load-bearing premise
Existing published evaluations already form a connected graph whose patterns allow accurate ranking of which unobserved model-dataset pairs would perform well.
What would settle it
Experimentally running the top-ranked links and finding that their actual performance falls below several already-published results on the same datasets would show the ranking step does not work.
Figures






read the original abstract
Scientific artifacts such as models and datasets are foundations for research. With the rapid growth of platforms like HuggingFace, researchers now have access to a large number of artifacts. Yet, a key challenge remains: how can we automatically discover the state-of-the-art (SOTA) model for a given dataset by fully leveraging existing artifacts? We formalize this task as automatic SOTA discovery by modeling HuggingFace as an artifact graph, where nodes are models/datasets and edges represent evaluations. We propose ArtifactLinker, a two-stage framework: (1) ranking promising unobserved model--dataset links using Graph Neural Networks (GNNs) or graph-augmented Large Language Models (LLMs), and (2) verifying top-ranked links via coding experiments with LLM-based agents. We further introduce a benchmark named ArtifactBench with 14,053 artifacts and 51,337 relations to evaluate the performance of both stages. Results show that (1) graph structures between existing artifacts are effective for missing link prediction; (2) end-to-end ranking and verification with ArtifactLinker help discover potential SOTA results and research insights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ArtifactLinker, a two-stage framework for automatic state-of-the-art (SOTA) discovery. It models Hugging Face as an artifact graph with models and datasets as nodes and evaluations as edges. Stage 1 ranks unobserved model-dataset links via GNNs or graph-augmented LLMs for missing-link prediction. Stage 2 verifies top-ranked links by having LLM-based coding agents execute experiments. The authors introduce ArtifactBench (14,053 artifacts, 51,337 relations) to evaluate both stages and claim that graph structure aids link prediction while the end-to-end pipeline surfaces potential SOTA results and insights.
Significance. If the central claims hold after addressing verification reliability, the work could meaningfully advance automated SOTA identification by exploiting existing evaluation graphs rather than exhaustive search. ArtifactBench is a concrete, reusable contribution that enables standardized testing of artifact-link prediction methods. The graph-based ranking approach is a natural and defensible extension of link-prediction techniques to this domain.
major comments (2)
- [Verification stage (method description following ranking)] The headline claim that 'end-to-end ranking and verification with ArtifactLinker help discover potential SOTA results' rests on the verification stage, yet no quantitative evaluation of LLM-agent accuracy (error rates, code-correctness metrics, agreement with human-run benchmarks, or sensitivity to metric-implementation errors) is reported. This is load-bearing because systematic over- or under-estimation by the agents would invalidate the discovered SOTA links.
- [Abstract and experimental results section] The abstract asserts that 'results show that graph structures between existing artifacts are effective for missing link prediction,' but supplies no concrete metrics, baselines, ablation controls, or error bars. The full experimental section must include these quantities (e.g., AUC, Hits@K, comparison to non-graph baselines) on ArtifactBench to substantiate the effectiveness claim.
minor comments (2)
- [Benchmark construction] Clarify the exact definition of 'unobserved' links and how the train/validation/test splits on ArtifactBench avoid leakage from the same model or dataset families.
- [Abstract] The abstract would benefit from a one-sentence statement of the strongest quantitative result (e.g., 'GNN achieves X% Hits@10 on ArtifactBench') to give readers immediate context.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of results and the verification stage.
read point-by-point responses
-
Referee: [Verification stage (method description following ranking)] The headline claim that 'end-to-end ranking and verification with ArtifactLinker help discover potential SOTA results' rests on the verification stage, yet no quantitative evaluation of LLM-agent accuracy (error rates, code-correctness metrics, agreement with human-run benchmarks, or sensitivity to metric-implementation errors) is reported. This is load-bearing because systematic over- or under-estimation by the agents would invalidate the discovered SOTA links.
Authors: We agree this is a substantive point. The original manuscript emphasized qualitative case studies of discovered SOTA results and insights from the verification stage. To address the concern directly, we have added a new quantitative evaluation subsection that measures LLM-agent accuracy on a held-out set of known model-dataset links. This includes code-execution success rates, agreement with human-run benchmark scores, and an analysis of sensitivity to common metric-implementation variations. These additions are now reported in the revised experimental section. revision: yes
-
Referee: [Abstract and experimental results section] The abstract asserts that 'results show that graph structures between existing artifacts are effective for missing link prediction,' but supplies no concrete metrics, baselines, ablation controls, or error bars. The full experimental section must include these quantities (e.g., AUC, Hits@K, comparison to non-graph baselines) on ArtifactBench to substantiate the effectiveness claim.
Authors: The full experimental section already reports AUC-ROC, Hits@K (including Hits@10), direct comparisons to non-graph baselines (random, MLP, and collaborative filtering), graph-structure ablations, and error bars from five independent runs on ArtifactBench. However, we acknowledge that the abstract remained too high-level. We have revised the abstract to include key quantitative results (e.g., 'GNN link prediction achieves AUC 0.87 and Hits@10 of 0.62, outperforming non-graph baselines by 12-18%') while preserving brevity. This makes the effectiveness claim concrete and directly supported by the experiments. revision: yes
Circularity Check
No circularity: empirical pipeline with new benchmark and standard link-prediction methods
full rationale
The paper introduces ArtifactBench as a new graph of artifacts and evaluations, then applies standard GNN or graph-augmented LLM link prediction followed by LLM-agent verification. No equations, fitted parameters, or self-citations are shown to reduce the claimed link-prediction performance or SOTA discoveries to quantities defined or fitted on the same evaluation data. The central results are presented as experimental outcomes on held-out or unobserved links within the introduced benchmark, keeping the derivation chain independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph neural networks or graph-augmented LLMs can rank unobserved model-dataset links from existing evaluation edges.
invented entities (2)
-
Artifact graph
no independent evidence
-
ArtifactBench
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize this task as automatic SOTA discovery by modeling HuggingFace as an artifact graph, where nodes are models/datasets and edges represent evaluations. We propose ArtifactLinker, a two-stage framework: (1) ranking promising unobserved model–dataset links using Graph Neural Networks (GNNs) or graph-augmented Large Language Models (LLMs), and (2) verifying top-ranked links via coding experiments with LLM-based agents.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The ranking stage addresses the search volume by using graph-based priors to prune the vast majority of unlikely links... ˆf(m,d)=P(Smd=1)·E[Ymd|Smd=1]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the suitability of hug- ging face hub for empirical studies.ArXiv, abs/2307.14841,
Adem Ait, Javier Luis Cánovas Izquierdo, and Jordi Cabot. On the suitability of hug- ging face hub for empirical studies.ArXiv, abs/2307.14841,
-
[2]
semanticscholar.org/CorpusId:260203268
URL https://api. semanticscholar.org/CorpusId:260203268. Joeran Beel, Min-Yen Kan, and Moritz Baumgart. Evaluating sakana’s ai scientist for autonomous research: Wishful thinking or an emerging reality towards ’artificial research intelligence’ (ari)?ArXiv, abs/2502.14297,
-
[3]
A large annotated corpus for learning natural language inference
Samuel Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. InProceedings of the 2015 conference on empirical methods in natural language processing, pp. 632–642,
work page 2015
-
[4]
Joel Castaño, Silverio Martínez-Fernández, Xavier Franch, and Justus Bogner. Analyzing the evolution and maintenance of ml models on hugging face.2024 IEEE/ACM 21st International Conference on Mining Software Repositories (MSR), pp. 607–618,
work page 2024
-
[5]
Joel Castaño, Rafael Cabañas, Antonio Salmer’on, David Lo, and Silverio Mart’inez- Fern’andez
URL https://api.semanticscholar.org/CorpusId:265351447. Joel Castaño, Rafael Cabañas, Antonio Salmer’on, David Lo, and Silverio Mart’inez- Fern’andez. How do machine learning models change?ArXiv, abs/2411.09645,
-
[6]
URLhttps://api.semanticscholar.org/CorpusId:274023512. Benjamin Paul Chamberlain, Sergey Shirobokov, Emanuele Rossi, Fabrizio Frasca, Thomas Markovich, Nils Hammerla, Michael M Bronstein, and Max Hansmire. Graph neural networks for link prediction with subgraph sketching.arXiv preprint arXiv:2209.15486,
-
[7]
Xnli: Evaluating cross-lingual sentence representations
Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel Bowman, Holger Schwenk, and Veselin Stoyanov. Xnli: Evaluating cross-lingual sentence representations. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 2475–2485,
work page 2018
-
[8]
Ned Cooper, Tiffanie N. Horne, Gillian R. Hayes, Courtney Heldreth, Michal Lahav, Jess Holbrook, and Lauren Wilcox. A systematic review and thematic analysis of community- collaborative approaches to computing research.Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems,
work page 2022
-
[9]
Sarah Gao and Andrew Gao. On the origin of llms: An evolutionary tree and graph for 15, 821 large language models.ArXiv, abs/2307.09793,
-
[10]
URL https://api.semanticscholar.org/CorpusId:220070385. Peter Alexander Jansen, Marc-Alexandre Côté, Tushar Khot, Erin Bransom, Bhavana Dalvi, Bodhisattwa Prasad Majumder, Oyvind Tafjord, and Peter Clark. Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.ArXiv, abs/2406.06769,
-
[11]
URL https://api.semanticscholar.org/CorpusId: 270380311. Peter Alexander Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bhavana Dalvi, Bodhisattwa Prasad Majumder, D. S. Weld, and Peter Clark. Codescientist: End-to-end semi-automated scientific discovery with code-based experimentation.ArXiv, abs/2503.22708,
-
[12]
Gyeongwon James Kim, Alex Wilf, Louis philippe Morency, and Daniel Fried
URL https: //api.semanticscholar.org/CorpusId:199001020. Gyeongwon James Kim, Alex Wilf, Louis philippe Morency, and Daniel Fried. From repro- duction to replication: Evaluating research agents with progressive code masking.ArXiv, abs/2506.19724,
-
[13]
Adam: A Method for Stochastic Optimization
URLhttps://api.semanticscholar.org/CorpusId:280000499. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Anatomy of a machine learning ecosystem: 2 million models on hugging face.ArXiv, abs/2508.06811,
Benjamin Laufer, Hamidah Oderinwale, and Jon Kleinberg. Anatomy of a machine learning ecosystem: 2 million models on hugging face.ArXiv, abs/2508.06811,
-
[15]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
URL https://api.semanticscholar.org/CorpusId: 234357246. Chris Lu, Cong Lu, R. T. Lange, J. Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.ArXiv, abs/2408.06292,
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
URL https://api.semanticscholar. org/CorpusId:263605602. Santiago Miret and Nandan M Krishnan. Are llms ready for real-world materials discovery? arXiv preprint arXiv:2402.05200,
-
[18]
URL https://openai.com/index/ introducing-gpt-5-2/. Accessed: 2026-01-06. Mohammad Shahedur Rahman, Peng Gao, and Yuede Ji. Hugginggraph: Understanding the supply chain of llm ecosystem.ArXiv, abs/2507.14240,
-
[19]
Minju Seo, Jinheon Baek, Seongyun Lee, and Sung Ju Hwang. Paper2code: Automating code generation from scientific papers in machine learning.ArXiv, abs/2504.17192,
-
[20]
URLhttps://api.semanticscholar.org/CorpusId:273366814. Yongliang Shen, Kaitao Song, Xu Tan, Wenqi Zhang, Kan Ren, Siyu Yuan, Weiming Lu, Dongsheng Li, and Y. Zhuang. Taskbench: Benchmarking large language models for task automation.ArXiv, abs/2311.18760,
-
[21]
URL https://api.semanticscholar.org/ CorpusId:265506220. Zachary S. Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan. Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark.Trans. Mach. Learn. Res., 2024,
work page 2024
-
[22]
URL https: //arxiv.org/pdf/2409.11363.pdf. Kanishka Silva, Marcel R. Ackermann, Heike Fliegl, G. Gesese, Fidan Limani, Philipp Mayr, Peter Mutschke, A. Oelen, Muhammad Asif Suryani, Sharmila Upadhyaya, Benjamin Zapilko, Harald Sack, and Stefan Dietze. Research knowledge graphs in nfdi4datascience: Key activities, achievements, and future directions.ArXiv,...
-
[23]
PaperBench: Evaluating AI's Ability to Replicate AI Research
URL https://api.semanticscholar.org/CorpusId:280421789. Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Paperbench: Evalu- ating ai’s ability to replicate ai research.arXiv preprint arXiv:2504.01848,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Testing the generalization power of neural net- work models across nli benchmarks
Aarne Talman and Stergios Chatzikyriakidis. Testing the generalization power of neural net- work models across nli benchmarks. InProceedings of the 2019 ACL workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, pp. 85–94,
work page 2019
-
[25]
URL https://api.semanticscholar.org/CorpusId:250048789. Petar Veliˇ ckovi´ c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman
URL https://api.semanticscholar.org/ CorpusId:267570328. Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. InProceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, pp. 353–355,
work page 2018
-
[27]
Neural common neighbor with comple- tion for link prediction.arXiv preprint arXiv:2302.00890,
Xiyuan Wang, Haotong Yang, and Muhan Zhang. Neural common neighbor with comple- tion for link prediction.arXiv preprint arXiv:2302.00890,
-
[28]
A broad-coverage challenge corpus for sentence understanding through inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers), pp. 1112–1122,
work page 2018
-
[29]
Yanzheng Xiang, Hanqi Yan, Shuyin Ouyang, Lin Gui, and Yulan He. Scireplicate-bench: Benchmarking llms in agent-driven algorithmic reproduction from research papers.ArXiv, abs/2504.00255,
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Xinyu Yang, Weixin Liang, and James Zou. Navigating dataset documentations in ai: A large-scale analysis of dataset cards on hugging face.ArXiv, abs/2401.13822,
-
[32]
URLhttps://doi.org/10.1038/s41392-022-00994-0. Haofei Yu, Keyang Xuan, Fenghai Li, Kunlun Zhu, Zijie Lei, Jiaxun Zhang, Ziheng Qi, Kyle Richardson, and Jiaxuan You. Tinyscientist: An interactive, extensible, and controllable framework for building research agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Sy...
-
[33]
15 Preprint A Visualization of Artifact Graph Figure 13 shows the full-size visualization of all nodes and edges we included in our collected artifact graph. Model (9827) Paper (1702) Codebase (1295) Dataset (1205) Figure 13:Visualization of collected artifact graph. B Limitations Computational considerations in verificationWhile our two-stage framework e...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.