Off-Policy Learning to Reason Works Because It Is More Pessimistic Than You Think
Pith reviewed 2026-06-29 14:10 UTC · model grok-4.3
The pith
Off-policy objectives for LLM reasoning succeed by implicitly optimizing more conservative policies than their nominal goals suggest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Successful off-policy objectives can be understood through implicit pessimism: they optimize toward target policies that are more conservative than their nominal objectives suggest. This perspective explains why removing importance weights often yields stronger algorithms than PPO-style corrections and why particular implementation choices improve stability by implicitly controlling the effective target distribution.
What carries the argument
The family of off-policy objectives that induce conservative target distributions by omitting importance weights on lagged data.
If this is right
- Removing importance weights causes optimization to target policies with lower entropy than the nominal objective specifies.
- Implementation details that affect data reuse or weighting act as indirect controls on the degree of induced conservatism.
- A principled change to how the induced target distribution is computed can further stabilize off-policy updates.
Where Pith is reading between the lines
- The same implicit-pessimism lens could be applied to diagnose why certain on-policy variants also succeed or fail at scale.
- Explicitly adding tunable conservatism to on-policy objectives might reproduce the stability benefits without switching to fully off-policy training.
- If the mechanism holds, one would expect performance gains to correlate directly with measurable conservatism of the effective target policy across different off-policy implementations.
Load-bearing premise
That the family of off-policy objectives constructed in the paper includes the successful methods used in practice and that implicit conservatism is the primary driver of their effectiveness.
What would settle it
An experiment that alters the objectives to eliminate the induced conservatism (for example by reintroducing targeted importance weighting that restores the nominal target) while preserving other properties and then measures whether performance drops relative to the original off-policy versions.
Figures
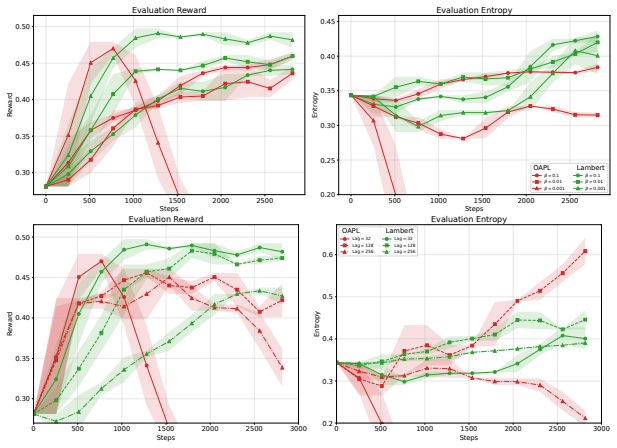
read the original abstract
Large scale reinforcement learning has become a central tool for improving reasoning in large language models. At this scale, generation is often lagged or asynchronous, so updates are performed on data collected by older policies. This makes learning inherently off-policy. Most existing approaches nevertheless remain rooted in PPO-style trust-region objectives, treating training as approximately on-policy and using importance weights to correct distribution mismatch. These corrections can introduce high variance, destabilize optimization, and accelerate entropy collapse. Recent work suggests an alternative: rather than correcting the mismatch, one can embrace off-policy data and remove importance weights, often yielding stronger algorithms. In this paper, we provide an intuitive construction of off-policy objectives that include successful off-policy objectives and show that their effectiveness can be understood through implicit pessimism: they optimize toward target policies that are more conservative than their nominal objectives suggest. This perspective explains why some particular implementation choices improve stability: they implicitly control the effective target distribution. We then propose a principled modification that stabilize this induced distribution and improve off-policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that off-policy objectives used in large-scale RL for LLM reasoning succeed because they implicitly induce pessimism: by removing importance weights or similar corrections, they optimize toward target policies that are more conservative than the nominal objective would suggest. It presents an intuitive construction of such objectives that purportedly includes successful practical methods, uses this view to explain why certain implementation choices improve stability by controlling the effective target distribution, and proposes a principled modification to stabilize the induced distribution and further improve off-policy learning.
Significance. If the central claim holds and the construction both covers deployed methods exactly and isolates pessimism as the causal factor (rather than variance reduction or other side effects), the work would provide a useful unifying lens on why certain off-policy approaches outperform PPO-style methods in reasoning tasks. The proposed modification could then serve as a practical improvement. The perspective is novel in framing off-policy success through implicit conservatism, but its impact depends on whether the mapping to real algorithms is precise and falsifiable.
major comments (3)
- [Abstract] Abstract: The claim that the 'intuitive construction of off-policy objectives ... include successful off-policy objectives' is load-bearing for the explanatory argument, yet the abstract provides no explicit enumeration or mapping of which deployed algorithms (e.g., specific variants used in large-scale LLM reasoning) are recovered exactly by the construction; without this, it is unclear whether the family is coextensive with practice or merely loosely related.
- [Abstract] Abstract: The argument that effectiveness 'can be understood through implicit pessimism' and that this is 'the primary driver' rather than variance reduction requires a demonstration that the induced conservatism is isolated from other effects of removing importance weights; the abstract does not indicate any ablation or counterfactual that rules out alternative explanations.
- [Abstract] Abstract: The proposed 'principled modification that stabilize this induced distribution' is presented as improving results, but the abstract gives no indication of how the modification is derived from the pessimism view or whether it requires post-hoc tuning; if the modification is not parameter-free or if its gains are not shown to stem directly from controlling the target distribution, the causal link remains unestablished.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below with references to the full manuscript and note planned revisions to strengthen the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the 'intuitive construction of off-policy objectives ... include successful off-policy objectives' is load-bearing for the explanatory argument, yet the abstract provides no explicit enumeration or mapping of which deployed algorithms (e.g., specific variants used in large-scale LLM reasoning) are recovered exactly by the construction; without this, it is unclear whether the family is coextensive with practice or merely loosely related.
Authors: Section 3 of the manuscript presents the construction and explicitly recovers several deployed off-policy methods used in large-scale LLM reasoning (those that drop importance sampling or equivalent corrections). The abstract is kept concise per typical constraints, but we agree an explicit high-level mapping would improve clarity. We will revise the abstract to include a brief enumeration of recovered methods. revision: yes
-
Referee: [Abstract] Abstract: The argument that effectiveness 'can be understood through implicit pessimism' and that this is 'the primary driver' rather than variance reduction requires a demonstration that the induced conservatism is isolated from other effects of removing importance weights; the abstract does not indicate any ablation or counterfactual that rules out alternative explanations.
Authors: The construction in Section 3 isolates the pessimism mechanism analytically by deriving the effective target policy that results from dropping corrections, independent of variance terms. The manuscript's experiments and analysis support this as the operative factor. We will revise the abstract to reference this isolation and add a short discussion paragraph on why alternative explanations are not required by the derivation. revision: partial
-
Referee: [Abstract] Abstract: The proposed 'principled modification that stabilize this induced distribution' is presented as improving results, but the abstract gives no indication of how the modification is derived from the pessimism view or whether it requires post-hoc tuning; if the modification is not parameter-free or if its gains are not shown to stem directly from controlling the target distribution, the causal link remains unestablished.
Authors: Section 4 derives the modification directly from the induced target distribution to enforce stability without introducing new hyperparameters; it is parameter-free by construction. Experiments attribute gains to the controlled distribution. We will revise the abstract to note the derivation and parameter-free property. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs a family of off-policy objectives and interprets their success via implicit pessimism on target policies. No load-bearing step reduces by construction to fitted inputs, self-definitional targets, or a self-citation chain whose cited result itself depends on the present claim. The construction is presented as an intuitive re-framing that encompasses existing methods; the pessimism interpretation follows from the modified objectives rather than presupposing the result. External benchmarks (variance reduction, stability) are discussed separately and not forced by the core equations. This is the common case of an explanatory re-derivation that remains independent of its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openai o1 system card, 2026
OpenAI. Openai o1 system card, 2026
2026
-
[2]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
2025
-
[3]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
2026
-
[4]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Ad...
2022
-
[5]
Kimi k2: Open agentic intelligence, 2026
Kimi Team. Kimi k2: Open agentic intelligence, 2026
2026
-
[6]
Faster, more efficient RLHF through off-policy asynchronous learning
Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. Faster, more efficient RLHF through off-policy asynchronous learning. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
Llms can learn to reason from off-policy data, 2026
Daniel Ritter, Owen Oertell, Bradley Guo, Jonathan Chang, Kianté Brantley, and Wen Sun. Llms can learn to reason from off-policy data, 2026
2026
-
[8]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1889–1897, Lille, France, 07–09 Jul 2015. PMLR
2015
-
[9]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
2017
-
[10]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[11]
Lee, Wen Sun, Wenhao Zhan, and Xuezhou Zhang
Kianté Brantley, Mingyu Chen, Zhaolin Gao, Jason D. Lee, Wen Sun, Wenhao Zhan, and Xuezhou Zhang. Accelerating RL for LLM reasoning with optimal advantage regression. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[12]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[13]
Lee, Wen Sun, Akshay Krishnamurthy, and Dylan J Foster
Audrey Huang, Wenhao Zhan, Tengyang Xie, Jason D. Lee, Wen Sun, Akshay Krishnamurthy, and Dylan J Foster. Correcting the mythos of KL-regularization: Direct alignment without overoptimization via chi-squared preference optimization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[14]
Is pessimism provably efficient for offline rl? In International Conference on Machine Learning, pages 5084–5096
Ying Jin, Zhuoran Yang, and Zhaoran Wang. Is pessimism provably efficient for offline rl? In International Conference on Machine Learning, pages 5084–5096. PMLR, 2021. 10
2021
-
[15]
Conservative q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc
2020
-
[16]
Logarithmic smoothing for pessimistic off-policy evaluation, selection and learning
Otmane Sakhi, Imad Aouali, Pierre Alquier, and Nicolas Chopin. Logarithmic smoothing for pessimistic off-policy evaluation, selection and learning. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 80706–80755. Curran Associates, Inc., 2024
2024
-
[17]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning, 2021
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning, 2021
2021
-
[19]
RoiRL: Efficient, self-supervised reasoning with offline iterative reinforcement learning
Aleksei Arzhantsev, Otmane Sakhi, and Flavian Vasile. RoiRL: Efficient, self-supervised reasoning with offline iterative reinforcement learning. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025
2025
-
[20]
Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y . Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. https://pretty- radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling- RL-19681902c1468005bed8ca303013a4e...
2025
-
[21]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[22]
Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms
Jasper Dekoninck, Nikola Jovanovi´c, Tim Gehrunger, Kári Rögnvalddson, Ivo Petrov, Chenhao Sun, and Martin Vechev. Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms. 2026. 11 A Societal Impact This work studies learning objectives for reinforcement learning in large language models. Its primary contribution is methodological...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.