TabCausal: Pretraining Across Causal Environments for Tabular Causal Discovery
Pith reviewed 2026-06-28 23:37 UTC · model grok-4.3
The pith
Pretraining a model across many synthetic causal environments lets it recover causal graphs from tabular data in one pass and outperform classical baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabCausal is a causal discovery foundation model trained by composing diverse graph priors, structural mechanisms, noise models, dimensions, sample sizes, and intervention regimes into varied discovery tasks; on large-scale synthetic benchmarks it records higher macro-averaged performance than a range of classical causal discovery methods, and it maintains robust structure recovery on out-of-distribution semantic environments, with the largest gains appearing when interventional evidence is supplied.
What carries the argument
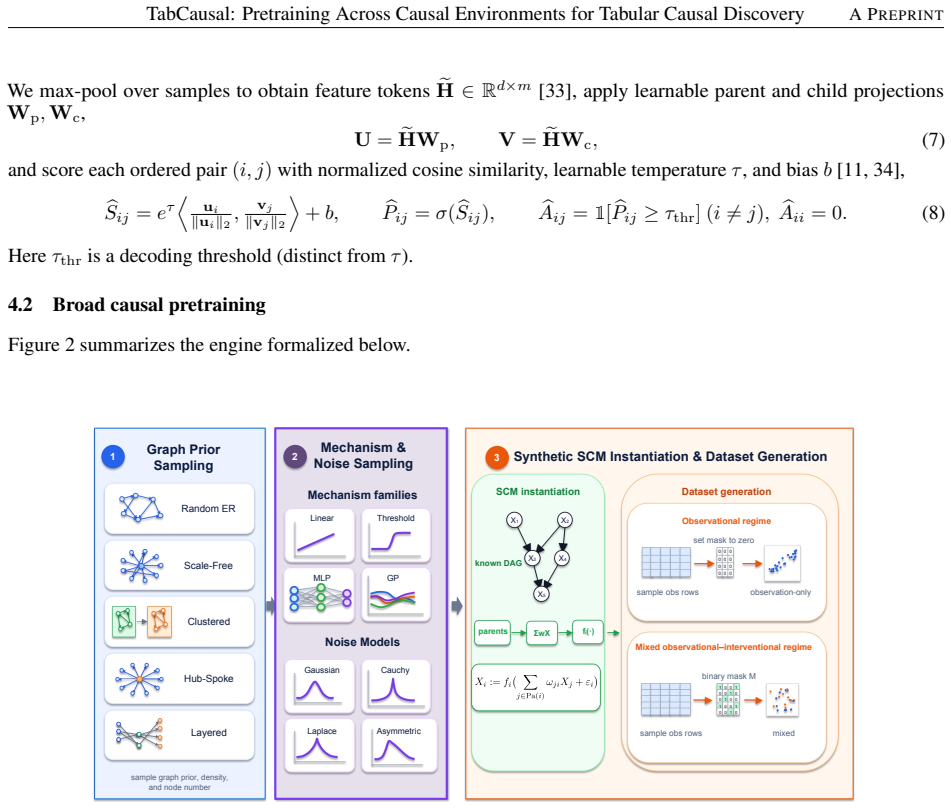
Dynamic task construction strategy that assembles varied causal environments into training tasks mixing observational and interventional data for amortized graph recovery.
If this is right
- A single pretrained model can replace repeated per-dataset optimization or search for causal structure.
- Performance improves when interventional samples are available during inference.
- The same model handles both purely synthetic and domain-grounded semantic causal environments without retraining.
- Macro-averaged scores across many graph and data regimes exceed those of diverse classical baselines.
Where Pith is reading between the lines
- If the pretraining distribution is broad enough, the model could serve as a fast initializer for downstream causal effect estimation tasks that still require some refinement.
- The approach suggests that causal discovery performance may scale with the diversity and volume of synthetic environments rather than with hand-designed inductive biases alone.
- Extending the same pretraining recipe to non-tabular modalities would test whether the amortization benefit is specific to tabular data or general.
Load-bearing premise
The chosen collection of graph priors, mechanisms, noise models, dimensions, sample sizes, and intervention regimes produces training distributions representative enough for the model to generalize to unseen real causal problems.
What would settle it
On a held-out collection of real tabular datasets with known ground-truth graphs, if TabCausal's edge recovery accuracy falls below that of the strongest classical baselines when both are given the same observational and interventional samples, the central claim would be falsified.
Figures







read the original abstract
Causal discovery aims to recover directed causal relations from observational and interventional data, providing a basis for mechanistic understanding and reliable decision-making. Causal discovery foundation models (CDFMs) seek to amortize this problem by mapping a dataset directly to a causal graph in a single forward pass, avoiding per-dataset testing, search, or optimization. However, existing CDFMs remain limited, often failing to consistently match strong classical methods, and we find that a key bottleneck is how causal pretraining tasks are constructed. Based on this observation, we propose TabCausal, a data-driven CDFM trained with broad causal pretraining over diverse graph priors, structural mechanisms, noise models, dimensions, sample sizes, and intervention regimes. A dynamic task construction strategy composes these causal environments into varied discovery tasks, enabling more transferable structural learning from observational and mixed-interventional data. On large-scale synthetic benchmarks, TabCausal achieves better macro-averaged performance than a diverse set of causal discovery baselines. To further bridge abstract synthetic generators and realistic causal reasoning scenarios, we introduce a protocol-guided and LLM-audited semantic causal environment benchmark, where domain-grounded SCMs generate interpretable observational and interventional datasets for out-of-distribution analysis. Across both synthetic and semantic environments, TabCausal demonstrates robust structure recovery, especially under interventional evidence, highlighting broad causal pretraining as a key ingredient for transferable amortized causal discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabCausal, a causal discovery foundation model (CDFM) pretrained across diverse causal environments for tabular data. It uses a dynamic task construction strategy to compose varied discovery tasks from graph priors, structural mechanisms, noise models, dimensions, sample sizes, and intervention regimes. The central empirical claim is that TabCausal achieves superior macro-averaged performance over a range of baselines on large-scale synthetic benchmarks and demonstrates robust structure recovery on both synthetic and a new protocol-guided, LLM-audited semantic causal environment benchmark, with particular gains under interventional evidence.
Significance. If the performance gains and robustness claims hold after standard controls and ablations, the work would strengthen the case for broad pretraining as a route to more transferable amortized causal discovery, addressing a noted bottleneck in existing CDFMs. The semantic benchmark protocol is a constructive addition for moving beyond purely abstract generators toward more interpretable scenarios. The paper does not report machine-checked proofs or fully parameter-free derivations, but the emphasis on reproducible task construction and mixed observational/interventional regimes is a positive methodological feature.
major comments (2)
- [§4] §4 (Experimental Evaluation) and the semantic benchmark description: the claim of robust recovery and transferability to 'unseen real-world causal discovery problems' rests on the assumption that the dynamic composition of synthetic and LLM-audited semantic SCMs produces representative training distributions. However, both regimes share the same core generative assumptions (acyclic graphs, specified mechanisms and noise models) and omit real-data features such as missingness patterns, selection biases, or non-i.i.d. sampling. This makes the OOD analysis internal to the synthetic paradigm and weakens the generalization argument for practical tabular settings.
- [Abstract, §4.1] Abstract and §4.1 (Synthetic Benchmarks): the assertion of 'better macro-averaged performance than a diverse set of causal discovery baselines' is presented without reference to specific quantitative tables, error bars, baseline hyperparameter details, or ablation results in the provided abstract; if the full experimental section lacks these controls or reports only aggregate scores, the superiority claim cannot be assessed for statistical robustness or sensitivity to data-selection choices.
minor comments (2)
- [§3] Notation for the dynamic task construction procedure could be clarified with an explicit algorithm box or pseudocode to make the composition of environments reproducible from the text alone.
- [§4] The paper would benefit from an explicit statement of the precise macro-averaged metric (e.g., which combination of precision, recall, or SHD variants) and how ties or multiple runs are aggregated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major concerns below, with planned revisions where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Evaluation) and the semantic benchmark description: the claim of robust recovery and transferability to 'unseen real-world causal discovery problems' rests on the assumption that the dynamic composition of synthetic and LLM-audited semantic SCMs produces representative training distributions. However, both regimes share the same core generative assumptions (acyclic graphs, specified mechanisms and noise models) and omit real-data features such as missingness patterns, selection biases, or non-i.i.d. sampling. This makes the OOD analysis internal to the synthetic paradigm and weakens the generalization argument for practical tabular settings.
Authors: We agree that both the synthetic and semantic benchmarks operate under shared generative assumptions (acyclic graphs, specified mechanisms, and noise models) and do not incorporate real-data features such as missingness, selection bias, or non-i.i.d. sampling. The semantic benchmark is designed to introduce domain-grounded, interpretable scenarios via LLM-audited SCMs rather than to simulate full real-world data distributions. We will revise the manuscript language in the abstract and §4 to replace references to 'realistic causal reasoning scenarios' and 'unseen real-world' with 'unseen semantic environments' to avoid overstating generalization. This change will be reflected in the next version. revision: partial
-
Referee: [Abstract, §4.1] Abstract and §4.1 (Synthetic Benchmarks): the assertion of 'better macro-averaged performance than a diverse set of causal discovery baselines' is presented without reference to specific quantitative tables, error bars, baseline hyperparameter details, or ablation results in the provided abstract; if the full experimental section lacks these controls or reports only aggregate scores, the superiority claim cannot be assessed for statistical robustness or sensitivity to data-selection choices.
Authors: The full §4.1 contains the requested details: quantitative tables reporting macro-averaged performance with error bars across multiple random seeds, baseline hyperparameter configurations, and ablation studies on task construction components. The abstract provides only a high-level summary, which is standard practice. We will add an explicit cross-reference in the abstract to the tables and figures in §4.1 to improve traceability. revision: yes
Circularity Check
No circularity: empirical performance claims on external benchmarks
full rationale
The paper presents TabCausal as an amortized CDFM trained on dynamically composed synthetic and semantic causal environments, with central claims consisting of macro-averaged performance comparisons against external baselines on held-out synthetic and LLM-audited semantic benchmarks. No derivation chain, equation, or result reduces to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work to force its conclusions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Greenewald, Chandler Squires, Akash Srivastava, Karthikeyan Shanmugam, and Caroline Uhler
Jiaqi Zhang, Kristjan H. Greenewald, Chandler Squires, Akash Srivastava, Karthikeyan Shanmugam, and Caroline Uhler. Identifiability guarantees for causal disentanglement from soft interventions. InNeurIPS, 2023
2023
-
[2]
Inferring causation from time series in earth system sciences.Nature Communications, 10(1):2553, 2019
Jakob Runge, Sebastian Bathiany, Erik Bollt, Gustau Camps-Valls, Dim Coumou, Ethan Deyle, Clark Glymour, Marlene Kretschmer, Miguel D Mahecha, Jordi Muñoz-Marí, et al. Inferring causation from time series in earth system sciences.Nature Communications, 10(1):2553, 2019
2019
-
[3]
Causal discovery in financial markets: A framework for nonstationary time-series data, 2024
Agathe Sadeghi, Achintya Gopal, and Mohammad Fesanghary. Causal discovery in financial markets: A framework for nonstationary time-series data, 2024. arXiv preprint arXiv:2312.17375
-
[4]
Peters, D
J. Peters, D. Janzing, and B. Schölkopf.Elements of Causal Inference: F oundations and Learning Algorithms. MIT Press, 2017
2017
-
[5]
MIT Press, 2000
Peter Spirtes, Clark N Glymour, and Richard Scheines.Causation, prediction, and search. MIT Press, 2000
2000
-
[6]
Optimal structure identification with greedy search.Journal of Machine Learning Research, 3:507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of Machine Learning Research, 3:507–554, 2002
2002
-
[7]
Hoyer, Dominik Janzing, Joris M
Patrik O. Hoyer, Dominik Janzing, Joris M. Mooij, Jonas Peters, and Bernhard Schölkopf. Nonlinear causal discovery with additive noise models. InNeurIPS, 2008
2008
-
[8]
Review of causal discovery methods based on graphical models
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of causal discovery methods based on graphical models. Frontiers in Genetics, 10, 2019
2019
-
[9]
Geometry of the faithfulness assumption in causal inference.The Annals of Statistics, 41(2):436–463, 2013
Caroline Uhler, Garvesh Raskutti, Peter Bühlmann, Bin Yu, et al. Geometry of the faithfulness assumption in causal inference.The Annals of Statistics, 41(2):436–463, 2013
2013
-
[10]
De- mystifying amortized causal discovery with transformers.arXiv preprint arXiv:2405.16924, 2024
Francesco Montagna, Max Cairney-Leeming, Dhanya Sridhar, and Francesco Locatello. Demystifying amortized causal discovery with transformers, 2024. arXiv preprint arXiv:2405.16924
-
[11]
Amortized inference for causal structure learning
Lars Lorch, Scott Sussex, Jonas Rothfuss, Andreas Krause, and Bernhard Schölkopf. Amortized inference for causal structure learning. InNeurIPS, 2022
2022
-
[12]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InICLR, 2023
2023
-
[13]
Accurate predictions on small data with a tabular foundation model.Nature, 01 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 01 2025
2025
-
[14]
V owels, Necati Cihan Camgöz, and Richard Bowden
Matthew J. V owels, Necati Cihan Camgöz, and Richard Bowden. D’ya like DAGs? A survey on structure learning and causal discovery.ACM Comput. Surv., 55(4):82:1–82:36, 2023
2023
-
[15]
Andersson, David Madigan, and Michael D
Steen A. Andersson, David Madigan, and Michael D. Perlman. A characterization of markov equivalence classes for acyclic digraphs.The Annals of Statistics, 25(2):505–541, 1997
1997
-
[16]
Yang, and Caroline Uhler
Yuhao Wang, Liam Solus, Karren D. Yang, and Caroline Uhler. Permutation-based causal inference algorithms with interventions. InNeurIPS, 2017
2017
-
[17]
Characterization and greedy learning of interventional Markov equivalence classes of directed acyclic graphs.Journal of Machine Learning Research, 13:2409–2464, 2012
Alain Hauser and Peter Bühlmann. Characterization and greedy learning of interventional Markov equivalence classes of directed acyclic graphs.Journal of Machine Learning Research, 13:2409–2464, 2012. 10 TabCausal: Pretraining Across Causal Environments for Tabular Causal DiscoveryA PREPRINT
2012
-
[18]
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing. DAGs with NO TEARS: Continuous optimization for structure learning. InNeurIPS, 2018
2018
-
[19]
Sethuraman, Romain Lopez, Rahul Mohan, Faramarz Fekri, Tommaso Biancalani, and Jan- Christian Hütter
Muralikrishnna G. Sethuraman, Romain Lopez, Rahul Mohan, Faramarz Fekri, Tommaso Biancalani, and Jan- Christian Hütter. NoDAGS-Flow: Nonlinear cyclic causal structure learning. InAISTATS, 2023
2023
-
[20]
DAGMA: Learning DAGs via m-matrices and a log- determinant acyclicity characterization
Kevin Bello, Bryon Aragam, and Pradeep Ravikumar. DAGMA: Learning DAGs via m-matrices and a log- determinant acyclicity characterization. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 8226–8239. Cur- ran Associates, Inc., 2022. URL https://proceedings.neuri...
2022
-
[21]
Stable differentiable causal discovery, 2024
Achille Nazaret, Justin Hong, Elham Azizi, and David Blei. Stable differentiable causal discovery, 2024. arXiv preprint arXiv:2311.10263
-
[22]
Maathuis
Diego Colombo and Marloes H. Maathuis. Order-independent constraint-based causal structure learning.Journal of Machine Learning Research, 15(1):3741–3782, 2014
2014
-
[23]
Hoyer, Aapo Hyvärinen, and Antti Kerminen
Shohei Shimizu, Patrik O. Hoyer, Aapo Hyvärinen, and Antti Kerminen. A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(72):2003–2030, 2006
2003
-
[24]
Beware of the simulated DAG! Causal discovery benchmarks may be easy to game
Alexander Reisach, Christof Seiler, and Sebastian Weichwald. Beware of the simulated DAG! Causal discovery benchmarks may be easy to game. InNeurIPS, 2021
2021
-
[25]
Sample, estimate, aggregate: A recipe for causal discovery foundation models, 2025
Menghua Wu, Yujia Bao, Regina Barzilay, and Tommi Jaakkola. Sample, estimate, aggregate: A recipe for causal discovery foundation models, 2025. arXiv preprint arXiv:2402.01929
-
[26]
A meta-learning approach to bayesian causal discovery
Anish Dhir, Matthew Ashman, James Requeima, and Mark van der Wilk. A meta-learning approach to bayesian causal discovery. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 14158–14178, 2025. URL https://proceedings.iclr.cc/paper_ files/paper/2025/file/24faedc5853648d5857f2cf08...
2025
-
[27]
Arrow: A Foundation Model for Causal Discovery
Ryan Thompson, He Zhao, Daniel M. Steinberg, and Edwin V . Bonilla. Arrow: A foundation model for causal discovery, 2026. arXiv preprint arXiv:2605.07204
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
CauScale: Neural Causal Discovery at Scale
Bo Peng, Sirui Chen, Jiaguo Tian, Yu Qiao, and Chaochao Lu. CauScale: Neural causal discovery at scale, 2026. arXiv preprint arXiv:2602.08629
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Causal inference in statistics: An overview.Statistics Surveys, 3:96–146, 2009
Judea Pearl. Causal inference in statistics: An overview.Statistics Surveys, 3:96–146, 2009
2009
-
[30]
Structural intervention distance for evaluating causal graphs.Neural Comput., 27(3):771–799, 2015
Jonas Peters and Peter Bühlmann. Structural intervention distance for evaluating causal graphs.Neural Comput., 27(3):771–799, 2015
2015
-
[31]
Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. InNeurIPS, 2017
2017
-
[32]
arXiv preprint arXiv:1912.12180 (Dec 2019)
Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidimensional transformers, 2019. arXiv preprint arXiv:1912.12180
-
[33]
Deep sets
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets. InNeurIPS, 2017
2017
-
[34]
Timothy Dozat and Christopher D. Manning. Deep biaffine attention for neural dependency parsing. InICLR, 2017
2017
-
[35]
When selection meets intervention: Additional complexities in causal discovery
Haoyue Dai, Ignavier Ng, Jianle Sun, Zeyu Tang, Gongxu Luo, Xinshuai Dong, Peter Spirtes, and Kun Zhang. When selection meets intervention: Additional complexities in causal discovery. InICLR, 2025
2025
-
[36]
Differentiable causal discovery from interventional data
Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable causal discovery from interventional data. InNeurIPS, 2020
2020
-
[37]
Scalable causal discovery with score matching
Francesco Montagna, Nicoletta Noceti, Lorenzo Rosasco, Kun Zhang, and Francesco Locatello. Scalable causal discovery with score matching. InProceedings of the Second Conference on Causal Learning and Reasoning, 2023
2023
-
[38]
real-world
Arthur E. Hoerl and Robert W. Kennard. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 42(1):80–86, 2000. 11 TabCausal: Pretraining Across Causal Environments for Tabular Causal DiscoveryA PREPRINT A Model Architecture and Training Details A.1 Model Architecture TabCausal employs a transformer-based encoder-decoder architect...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.