Aligned Training: A Parameter-Free Method to Improve Feature Quality and Stability of Sparse Autoencoders (SAE)
Pith reviewed 2026-05-20 12:11 UTC · model grok-4.3
The pith
Reparameterizing sparse autoencoders to force the inner product of each encoder and decoder direction to equal one removes a source of training degeneracy and yields better features without new hyperparameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
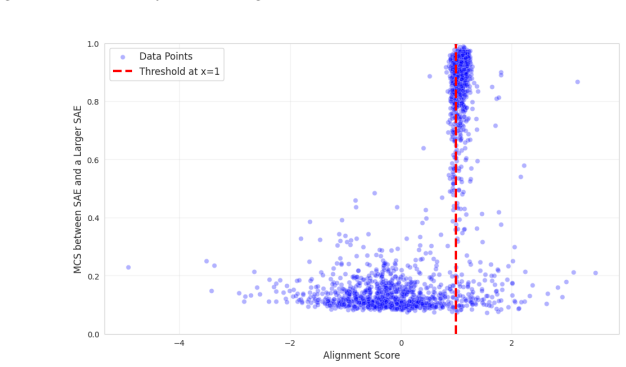
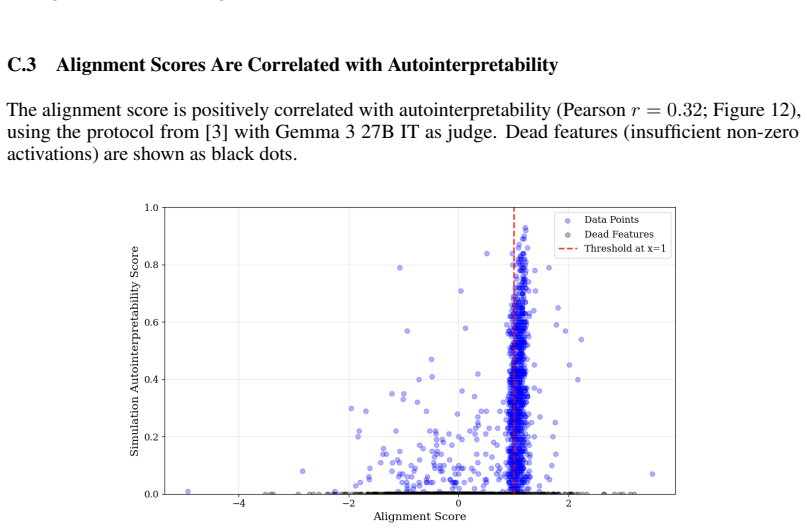
The paper establishes that the overlooked bimodality in alignment scores (inner product of encoder and decoder directions) is a controllable source of degeneracy. By enforcing the geometric constraint that this inner product equals one for every feature through a simple reparameterization, the training dynamics are altered so that dead features disappear, reconstruction quality rises, and run-to-run stability improves, all without introducing hyperparameters or extra computational cost.
What carries the argument
The aligned training reparameterization, which directly constrains the encoder-decoder inner product to equal one for each feature and thereby fixes the geometric relationship between the learned directions.
If this is right
- SAEs trained with the constraint achieve Pareto improvements on reconstruction-versus-sparsity trade-offs.
- Dead features are eliminated across multiple model families and sparsity regimes without resampling or auxiliary losses.
- Feature sets become more stable across different random seeds, reducing the need for seed averaging.
- The method composes directly with Top-K, BatchTop-K, and p-annealing architectures.
- The same reparameterization applies at different dictionary sizes without retuning.
Where Pith is reading between the lines
- The same inner-product constraint could be tested in other overcomplete dictionary learning settings beyond SAEs.
- Monitoring alignment scores during training might serve as an early diagnostic for whether a run will produce many dead features.
- If the bimodality arises from gradient dynamics, similar geometric fixes might apply to related representation-learning methods.
- Post-hoc feature pruning steps common in interpretability workflows could become less necessary.
Load-bearing premise
The assumption that the observed bimodal alignment distribution is a fixable degeneracy whose removal does not prevent the SAE from accurately representing the original activations.
What would settle it
Run aligned training and standard training on the same activation dataset; if the aligned version still produces a substantial fraction of dead features or shows worse reconstruction loss than the baseline, the claim that the constraint removes the root degeneracy would be falsified.
Figures



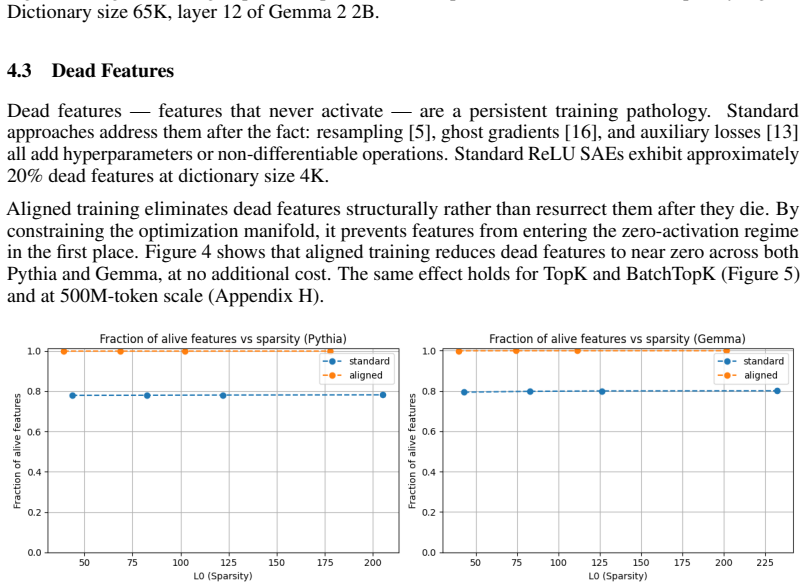
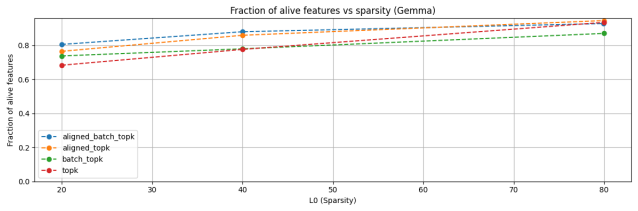
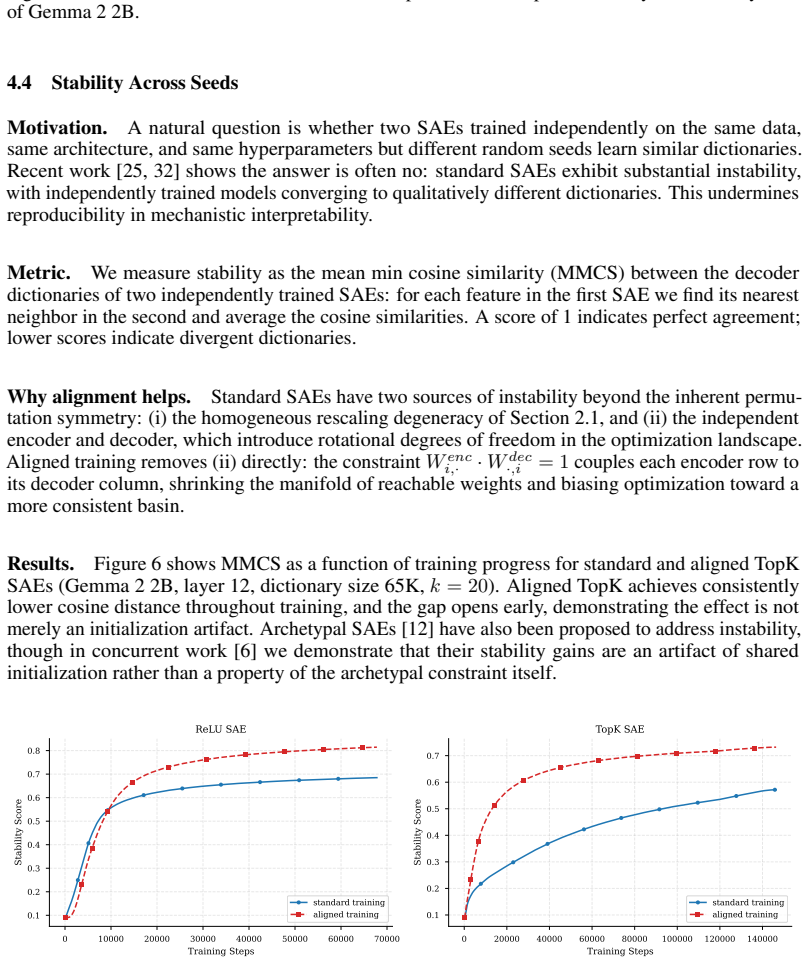


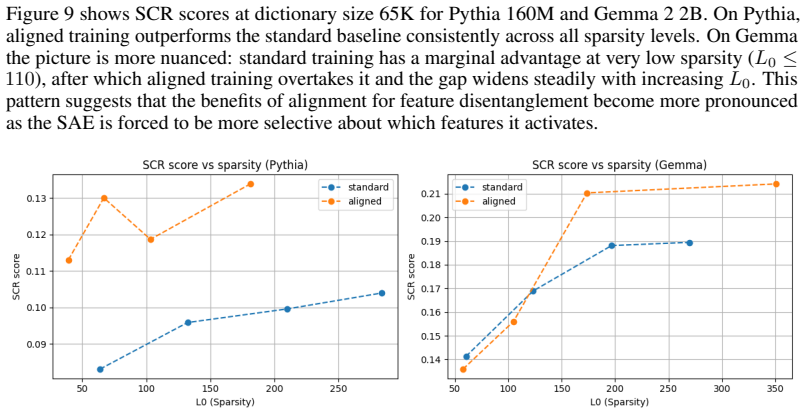









read the original abstract
Sparse autoencoders (SAEs) are one of the main methods to interpret the inner workings of deep neural networks (DNNs), decomposing activations into higher-dimensional features. However, they exhibit critical shortcomings where a large fraction of features are never activated and are unstable. Despite variants of SAEs that attempt to mitigate these issues, they require additional data, resampling, or training. We propose the \textbf{aligned training}, a parameter-free reparameterization of SAEs that simultaneously improves reconstruction quality, eliminates dead features, and significantly enhances stability across training seeds. Our approach is motivated by an overlooked observation that SAE feature quality, measured by the inner product between encoder and decoder directions (which we call the \textbf{alignment score}), follows a bimodal distribution across all modern architectures. The proposed aligned training enforces a geometric constraint between the encoder and decoder such that their inner product equals one for every feature, which removes a source of degeneracy in the SAE training without adding any hyperparameters. Across multiple models, dictionary sizes, and sparsity levels, the aligned training shows Pareto improvements on the SAEBench benchmarks. Beyond improving dead features, stability and reconstruction, our method readily integrates with techniques in mechanical interpretability such as Top/BatchTop-K architectures and p-Annealing. Overall, the aligned training substantially improves feature quality and stability of SAE without computational complexity or cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes aligned training, a parameter-free reparameterization of sparse autoencoders (SAEs) that enforces the inner product between encoder and decoder directions to equal exactly one for each feature. Motivated by an observed bimodal distribution of alignment scores, the method claims to remove a source of degeneracy in SAE training. It reports simultaneous improvements in reconstruction quality, elimination of dead features, and enhanced stability across training seeds, along with Pareto improvements on SAEBench benchmarks across models, dictionary sizes, and sparsity levels. The approach integrates with techniques such as Top-K and p-Annealing without added hyperparameters or computational cost.
Significance. If the central claim holds—that the hard geometric constraint directly fixes a degeneracy rather than merely altering optimization dynamics—this would represent a simple, hyperparameter-free improvement to a widely used tool in mechanistic interpretability. The reported compatibility with existing SAE variants and the absence of new hyperparameters are practical strengths that could facilitate adoption if the gains prove robust and mechanistically attributable to the alignment enforcement.
major comments (2)
- [Method] Method section (reparameterization description): The aligned training ties the decoder direction to the encoder such that their inner product is fixed at 1, which necessarily reduces the number of independent parameters relative to the standard untied SAE formulation. The paper attributes observed gains to removal of the low-alignment mode in the bimodal distribution, yet no ablation is described that enforces the same alignment=1 constraint via a soft penalty or post-update projection while preserving the original untied parameterization. Without this comparison, it remains unclear whether improvements stem from the claimed geometric degeneracy fix or from changes in gradient flow and effective degrees of freedom.
- [Experiments] Experiments and results sections: The central claim of Pareto improvements on SAEBench (reconstruction, dead features, stability) is load-bearing, but the manuscript does not report an explicit test of whether forcing alignment=1 compromises the SAE's ability to represent the underlying data distribution (e.g., via held-out reconstruction error or feature activation statistics under the constraint). The weakest assumption—that the bimodal distribution represents a fixable degeneracy rather than a natural outcome of optimization—requires direct empirical support through such a comparison.
minor comments (1)
- [Abstract] The abstract states improvements 'across all modern architectures' without listing the specific models, layers, or datasets used; adding this detail in the introduction or experimental setup would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, offering clarifications on the method and experiments while indicating revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (reparameterization description): The aligned training ties the decoder direction to the encoder such that their inner product is fixed at 1, which necessarily reduces the number of independent parameters relative to the standard untied SAE formulation. The paper attributes observed gains to removal of the low-alignment mode in the bimodal distribution, yet no ablation is described that enforces the same alignment=1 constraint via a soft penalty or post-update projection while preserving the original untied parameterization. Without this comparison, it remains unclear whether improvements stem from the claimed geometric degeneracy fix or from changes in gradient flow and effective degrees of freedom.
Authors: We acknowledge that the reparameterization reduces the number of independent parameters by design, as this is the mechanism by which the unit inner product is strictly enforced. Our central claim is that this hard geometric constraint directly eliminates the low-alignment mode observed in the bimodal distribution, rather than merely altering optimization dynamics. A soft penalty or post-hoc projection would require an additional hyperparameter (e.g., penalty weight or projection frequency), which would violate the parameter-free property of the method. We will revise the method section to explicitly discuss the relationship between the hard constraint, parameter count, and the observed degeneracy, including a clearer justification for preferring the reparameterization over soft alternatives. revision: partial
-
Referee: [Experiments] Experiments and results sections: The central claim of Pareto improvements on SAEBench (reconstruction, dead features, stability) is load-bearing, but the manuscript does not report an explicit test of whether forcing alignment=1 compromises the SAE's ability to represent the underlying data distribution (e.g., via held-out reconstruction error or feature activation statistics under the constraint). The weakest assumption—that the bimodal distribution represents a fixable degeneracy rather than a natural outcome of optimization—requires direct empirical support through such a comparison.
Authors: The reported Pareto improvements on SAEBench already include enhanced reconstruction quality across multiple settings, which is measured on data not used for training and thus provides indirect evidence that the constraint does not harm the ability to represent the data distribution. To directly address the concern, we will add an explicit comparison of held-out reconstruction error and feature activation statistics between aligned and standard SAEs in the revised experiments section. This addition will supply the requested empirical support for interpreting the bimodal distribution as a fixable degeneracy. revision: yes
Circularity Check
No circularity: aligned training is a direct reparameterization with empirical validation
full rationale
The paper introduces aligned training as a parameter-free reparameterization that directly enforces the encoder-decoder inner product to equal 1 for each feature. This is motivated by an observed bimodal distribution of alignment scores but does not derive any result or prediction from fitted parameters or prior outputs. The claimed Pareto improvements on SAEBench are presented as empirical outcomes across models and settings, not as quantities that reduce to the constraint by construction. No self-citation chain, uniqueness theorem, or ansatz smuggling supports the central mechanism; the approach is self-contained as an engineering change to the SAE parameterization without load-bearing external citations or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SAE feature quality is measured by the inner product between encoder and decoder directions following a bimodal distribution.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / Jcost_unit0 echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The proposed aligned training enforces a geometric constraint between the encoder and decoder such that their inner product equals one for every feature... W_enc_i,· · W_dec_·,i = 1 for every feature i by construction.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Toy model... perfect reconstruction forces the alignment score to one.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.