Limits of Resolution Equivariance in Fourier Neural Operators
Pith reviewed 2026-06-28 19:26 UTC · model grok-4.3
The pith
Fourier Neural Operators show limited resolution equivariance because direct fine-grid inference does not reliably outperform low-grid inference followed by upsampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
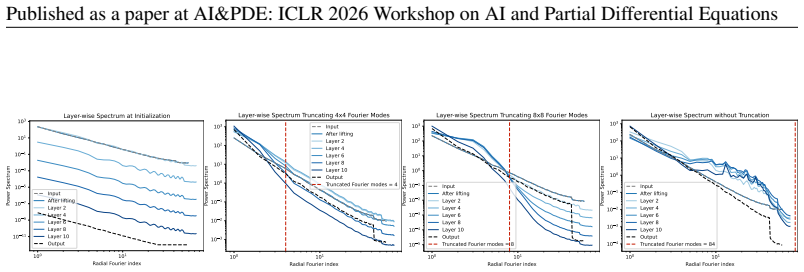
On Darcy flow, direct fine-grid inference is not reliably beneficial and can be worse than the low-grid-plus-upsampling baseline. Under Fourier truncation, intermediate representations increasingly concentrate energy in low frequencies, with high-frequency output produced mainly by late nonlinear/decoder stages. This offers a mechanistic explanation for why FNO can perform well while retaining few modes, yet remain sensitive under resolution shifts.
What carries the argument
The head-to-head comparison of direct high-resolution FNO inference against low-resolution inference plus Fourier zero-padding upsampling, together with layerwise spectral energy analysis.
If this is right
- A low-resolution inference plus Fourier upsampling baseline should be included in any cross-resolution FNO evaluation.
- Nonlinear aliasing prevents true zero-shot resolution equivariance in FNOs.
- FNO success with few retained modes stems from progressive low-frequency concentration across layers.
- High-frequency output details depend primarily on the final nonlinear and decoder stages.
Where Pith is reading between the lines
- The same early-layer low-frequency concentration pattern may appear in other spectral operator architectures and limit their cross-resolution behavior.
- Regularization or architectural changes that reduce nonlinear aliasing could improve resolution generalization without changing the number of modes.
- Repeating the layerwise spectrum analysis on Navier-Stokes or other benchmark datasets would test whether the Darcy flow findings are dataset-specific.
- The interaction between chosen truncation levels and the underlying PDE physics may drive part of the observed sensitivity.
Load-bearing premise
The Darcy flow dataset and chosen truncation levels are representative of FNO behavior under resolution shifts in general.
What would settle it
An experiment in which direct fine-grid inference consistently and substantially outperforms the low-grid-plus-upsampling baseline across multiple resolutions and additional PDE datasets would falsify the central observation.
Figures

read the original abstract
Fourier Neural Operators are often assumed to generalize across spatial resolutions, enabling training on a coarse grid and deployment on a finer grid. We test this assumption by contrasting two inference-time choices when moving from training resolution $s$ to test resolution $S>s$: running FNO directly at $S$, or running at $s$ and upsampling the prediction to $S$ via Fourier zero-padding. On Darcy flow, we observe that direct fine-grid inference is not reliably beneficial and can be worse than the low-grid-plus-upsampling baseline. We further analyze layerwise spectra and find that, under Fourier truncation, intermediate representations increasingly concentrate energy in low frequencies, with high-frequency output produced mainly by late nonlinear/decoder stages. This offers a mechanistic explanation for why FNO can perform well while retaining few modes, yet remain sensitive under resolution shifts. Our findings highlight a simple but strong baseline for cross-resolution evaluation and point to nonlinear aliasing as a key obstacle to zero-shot resolution equivariance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that FNOs do not reliably benefit from direct fine-grid inference when moving from training resolution s to test resolution S > s on Darcy flow; instead, low-grid inference followed by Fourier zero-padding upsampling can perform as well or better. Layerwise spectral analysis is used to argue that intermediate layers concentrate energy in low frequencies under truncation, with high frequencies generated mainly in late nonlinear stages, providing a mechanistic account for why FNOs remain sensitive to resolution shifts despite retaining few modes. The work positions nonlinear aliasing as a key obstacle to zero-shot resolution equivariance and recommends the upsampling baseline for cross-resolution evaluation.
Significance. If the empirical observation and spectral analysis hold under proper statistical controls, the result supplies a simple, strong baseline for resolution-shift evaluation in neural operators and identifies a concrete limitation that could guide architecture or training modifications for PDE surrogate modeling. The absence of parameter fitting or circular derivations is a strength of the empirical framing.
major comments (2)
- [paragraph on experimental setup] Paragraph on experimental setup (as referenced in the abstract): the claim that direct fine-grid inference 'is not reliably beneficial and can be worse' is presented without error bars, dataset sizes, number of runs, or statistical tests. This makes it impossible to determine whether observed differences exceed variability or arise from post-hoc truncation choices.
- [Abstract / layerwise spectra analysis] Abstract and layerwise spectra discussion: the step from the Darcy-specific performance gap to the general claim that 'nonlinear aliasing [is] a key obstacle to zero-shot resolution equivariance' lacks controls (e.g., varying truncation levels or high-frequency content to modulate the direct-vs-upsample gap) or results on additional PDEs. Without such evidence the causal link between the observed spectra and the resolution-shift behavior remains unsecured.
minor comments (1)
- The abstract would be clearer if it stated the specific truncation levels (number of modes) and grid sizes used for the Darcy experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve statistical reporting and strengthen the evidential basis for our claims where feasible.
read point-by-point responses
-
Referee: Paragraph on experimental setup (as referenced in the abstract): the claim that direct fine-grid inference 'is not reliably beneficial and can be worse' is presented without error bars, dataset sizes, number of runs, or statistical tests. This makes it impossible to determine whether observed differences exceed variability or arise from post-hoc truncation choices.
Authors: We agree that explicit reporting of variability is necessary. The experiments are performed on the standard Darcy flow dataset (1000 training samples, 200 test samples). In the revision we will add error bars from 5 independent runs with different random seeds, report the number of runs explicitly, and confirm that the performance gaps between direct fine-grid inference and the upsampling baseline remain consistent across seeds. revision: yes
-
Referee: Abstract and layerwise spectra discussion: the step from the Darcy-specific performance gap to the general claim that 'nonlinear aliasing [is] a key obstacle to zero-shot resolution equivariance' lacks controls (e.g., varying truncation levels or high-frequency content to modulate the direct-vs-upsample gap) or results on additional PDEs. Without such evidence the causal link between the observed spectra and the resolution-shift behavior remains unsecured.
Authors: The layerwise spectra are presented as a mechanistic explanation for the Darcy results under Fourier truncation. We will add new experiments that vary the number of retained modes to demonstrate how the direct-vs-upsample gap changes with truncation level, thereby tightening the connection between the spectral observations and the resolution-shift behavior. The abstract claim is scoped to FNOs; we will qualify the wording to reflect that the evidence is drawn from this architecture and benchmark. revision: partial
- Results on PDEs other than Darcy flow.
Circularity Check
No circularity: purely empirical comparison and spectral observation
full rationale
The paper reports experimental results on Darcy flow (direct fine-grid inference vs. low-resolution plus upsampling) and layerwise Fourier spectra under truncation. No derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations appear in the provided text. Claims rest on observed performance differences and energy concentration patterns rather than any reduction of outputs to inputs by construction. The generalization to 'nonlinear aliasing as obstacle' is an interpretive step, not a tautological one.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Fourier Neural Operator for Parametric Partial Differential Equations , author=. International Conference on Learning Representations , year=
-
[2]
arXiv preprint arXiv:2506.10973 , year=
Principled Approaches for Extending Neural Architectures to Function Spaces for Operator Learning , author=. arXiv preprint arXiv:2506.10973 , year=
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Discretization-invariance? on the discretization mismatch errors in neural operators , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
The Fourteenth International Conference on Learning Representations , year=
The False Promise of Zero-Shot Super-Resolution in Machine-Learned Operators , author=. The Fourteenth International Conference on Learning Representations , year=
-
[5]
Dieleman, Sander , title =
-
[6]
Journal of Machine Learning Research , volume=
Neural operator: Learning maps between function spaces with applications to pdes , author=. Journal of Machine Learning Research , volume=
-
[7]
arXiv preprint arXiv:2512.01421 , year=
Fourier Neural Operators Explained: A Practical Perspective , author=. arXiv preprint arXiv:2512.01421 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.