Coherent Off-Policy Improvement of Large Behavior Models with Learned Rewards
Pith reviewed 2026-06-28 15:44 UTC · model grok-4.3
The pith
Coherent imitation learning from expert data lets large behavior models improve without the usual RL finetuning drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
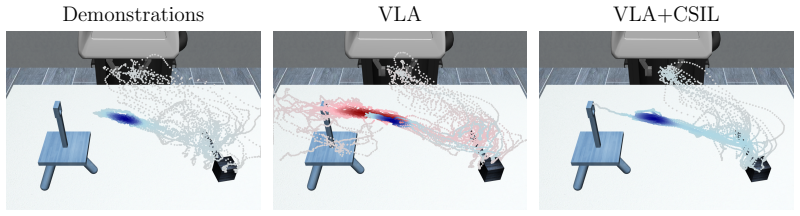
We show that our IRL method maintains or improves the performance of pi-0.5 on all six sparse manipulation tasks and achieves a ≥90% success rate on five out of six complex manipulation tasks, outperforming RL-based baselines using sparse rewards. By ensuring our initial pretrained finetuning policy is optimal for our initial reward and critic, our method circumvents the initial drop commonly seen in RL finetuning and enables faster improvement.
What carries the argument
coherent imitation learning, an IRL method that uses a specific reward formulation with theoretical guarantees to enable improvement of the behavioral cloning policy
Load-bearing premise
Making the initial pretrained finetuning policy optimal for the learned reward and critic circumvents the initial drop commonly seen in RL finetuning and enables faster improvement.
What would settle it
An experiment showing that the IRL-finetuned policy still exhibits an initial performance drop or fails to outperform sparse-reward RL baselines on the six manipulation tasks would falsify the central claim.
Figures

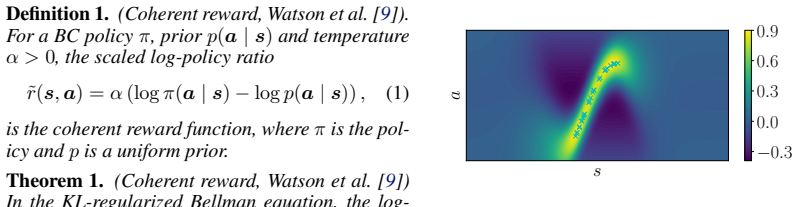




read the original abstract
Distilling expert demonstration data into large generative models using behavioral cloning is a scalable approach to learning capable policies for robotic control, particularly for dexterous manipulation. Reinforcement learning (RL) can be used as a means to finetune these policies further using additional experience. An open question is whether RL is more sample-efficient than collecting more human demonstrations. Prior work has finetuned large pretrained policies in a scalable fashion by applying RL to a smaller residual policy that corrects the pretrained model. However, for the typical sparse reward tasks, RL algorithms can struggle to optimize the behavior in a sample-efficient manner. We explore inverse reinforcement learning, where a dense reward function is learned from expert demonstrations, potentially reducing the challenge of RL finetuning. We specifically consider coherent imitation learning, an IRL method that facilitates improvement of the BC policy through using a specific reward formulation with theoretical guarantees. We show that our IRL method maintains or improves the performance of pi-0.5 on all six sparse manipulation tasks and achieves a $\geq 90\%$ success rate on five out of six complex manipulation tasks, outperforming RL-based baselines using sparse rewards. By ensuring our initial pretrained finetuning policy is optimal for our initial reward and critic, our method circumvents the initial drop commonly seen in RL finetuning and enables faster improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using coherent imitation learning, an IRL method with theoretical guarantees, to learn dense rewards from expert demonstrations. This is applied to finetune large behavior-cloned policies (e.g., pi-0.5) for robotic dexterous manipulation tasks. The central claim is that ensuring the initial pretrained policy is optimal for the learned reward and critic avoids the typical initial performance drop in RL finetuning, enabling faster improvement; empirical results show maintained or improved performance on all six sparse manipulation tasks, with ≥90% success on five of six complex tasks, outperforming sparse-reward RL baselines.
Significance. If the results hold with the promised theoretical grounding and empirical details, the work could advance scalable finetuning of large generative models for robotics by providing a sample-efficient alternative to additional human demonstrations or direct sparse-reward RL. The explicit linkage of coherent IRL's reward formulation to avoiding initial drops is a potentially useful contribution if the optimality condition is shown to hold in practice.
major comments (1)
- Abstract: The claim that 'ensuring our initial pretrained finetuning policy is optimal for our initial reward and critic' circumvents the initial drop is presented as a key mechanism, but without the specific reward formulation, optimality proof, or empirical verification (e.g., performance curves in the first training steps) in the methods or results, it is not possible to assess whether this assumption holds or is load-bearing for the reported gains over RL baselines.
minor comments (1)
- Abstract: Notation such as 'pi-0.5' is used without definition; this should be clarified on first use for readers unfamiliar with the base model.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and address the major comment below. We provide clarifications on the support for the abstract claim while remaining faithful to the manuscript content.
read point-by-point responses
-
Referee: Abstract: The claim that 'ensuring our initial pretrained finetuning policy is optimal for our initial reward and critic' circumvents the initial drop is presented as a key mechanism, but without the specific reward formulation, optimality proof, or empirical verification (e.g., performance curves in the first training steps) in the methods or results, it is not possible to assess whether this assumption holds or is load-bearing for the reported gains over RL baselines.
Authors: The manuscript introduces coherent imitation learning in Section 3 as the IRL method with a specific reward formulation and theoretical guarantees that make the BC policy optimal for the learned reward and critic; this is the basis for the abstract claim. The results in Section 4 report that performance is maintained or improved on all tasks (with ≥90% success on five of six), which is consistent with avoiding an initial drop relative to the sparse-reward RL baselines. If the linkage requires more explicit cross-referencing or early-step curve insets for clarity, we will incorporate a brief methods paragraph and additional figure details in revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical evaluation of an IRL method (coherent imitation learning) for finetuning pretrained policies on robotic manipulation tasks. The abstract and provided text contain no equations, derivations, or load-bearing steps that reduce predictions or results to inputs by construction, self-definition, or self-citation chains. Claims rest on experimental success rates across six tasks rather than any internal mathematical reduction. The reference to 'theoretical guarantees' is not accompanied by a derivation within the visible content that would trigger circularity patterns. This is a standard empirical result with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Driess, F
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. PaLM-E: An embodied multimodal language model. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[2]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
R. S. Sutton and A. G. Barto.Reinforcement Learning: An Introduction. MIT press, 2018
2018
-
[4]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal. From imitation to refinement- residual RL for precise assembly. InIEEE International Conference on Robotics and Automa- tion (ICRA), 2025
2025
-
[5]
X. Yuan, T. Mu, S. Tao, Y . Fang, M. Zhang, and H. Su. Policy decorator: Model-agnostic online refinement for large policy model. InInternational Conference on Learning Representations (ICLR), 2025
2025
- [6]
-
[7]
Eschmann
J. Eschmann. Reward function design in reinforcement learning.Reinforcement learning algorithms: Analysis and Applications, 2021
2021
-
[8]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. Fan, et al. Self- improving vision-language-action models with data generation via residual rl. InInternational Conference on Learning Representation (ICLR), 2026
2026
-
[9]
Watson, S
J. Watson, S. H. Huang, and N. Heess. Coherent soft imitation learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[10]
Palenicek, F
D. Palenicek, F. V ogt, J. Watson, I. Posner, and J. Peters. XQC: Well-conditioned optimization accelerates deep reinforcement learning.International Conference on Learning Representa- tions (ICLR), 2026
2026
-
[11]
A. Ren, J. Lidard, L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InInternational Conference on Learning Representations (ICLR), 2025. 9
2025
-
[12]
K. Chen, Z. Liu, T. Zhang, Z. Guo, S. Xu, H. Lin, H. Zang, X. Li, Q. Zhang, Z. Yu, G. Fan, T. Huang, Y . Wang, and C. Yu.π RL: Online RL fine-tuning for flow-based vision-language- action models, 2026
2026
-
[13]
Wagenmaker, Y
A. Wagenmaker, Y . Zhang, M. Nakamoto, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning. InConfer- ence on Robot Learning (CoRL), 2025
2025
-
[14]
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [15]
-
[16]
Orsini, A
M. Orsini, A. Raichuk, L. Hussenot, D. Vincent, R. Dadashi, S. Girgin, M. Geist, O. Bachem, O. Pietquin, and M. Andrychowicz. What matters for adversarial imitation learning? In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[17]
Z. Sun and S. Song. From prior to pro: Efficient skill mastery via distribution contractive rl finetuning.arXiv preprint arXiv:2603.10263, 2026
work page internal anchor Pith review arXiv 2026
-
[18]
arXiv preprint arXiv:2603.26666 , year=
Z. Zhong, H. Yan, J. Li, J. He, T. Zhang, and H. Li. VLA-OPD: Bridging offline sft and online RL for vision-language-action models via on-policy distillation.arXiv preprint arXiv:2603.26666, 2026
-
[19]
A. Y . Ng, D. Harada, and S. J. Russell. Policy invariance under reward transformations: Theory and application to reward shaping. InInternational Conference on Machine Learning (ICML), 1999
1999
-
[20]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[21]
Meronen, M
L. Meronen, M. Trapp, and A. Solin. Periodic activation functions induce stationarity. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[22]
Rasmussen and C
C. Rasmussen and C. Williams.Gaussian Processes for Machine Learning. MIT Press, 2006
2006
-
[23]
Ioffe and C
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational Conference on Machine Learning (ICML), 2015
2015
-
[24]
C. Lyle, Z. Zheng, K. Khetarpal, J. Martens, H. van Hasselt, R. Pascanu, and W. Dabney. Normalization and effective learning rates in reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[25]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. InNIPS 2016 Deep Learning Symposium, 2016
2016
-
[26]
Palenicek, F
D. Palenicek, F. V ogt, J. Watson, and J. Peters. Scaling off-policy reinforcement learning with batch and weight normalization. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[27]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[28]
Polyanskiy
Y . Polyanskiy. Information theoretic methods in statistics and computer science: Lecture 1 — f-divergences, 2020. 10
2020
-
[29]
Espeholt, H
L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V . Mnih, T. Ward, Y . Doron, V . Firoiu, T. Harley, I. Dunning, S. Legg, and K. Kavukcuoglu. IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[30]
Levine, C
S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research (JMLR), 2016
2016
-
[31]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations (ICLR), 2022
2022
-
[32]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[33]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. MimicGen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning (CoRL), 2023
2023
-
[34]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.