AbstRAG: Learning to Abstract for Retrieval Problems
Pith reviewed 2026-06-27 16:39 UTC · model grok-4.3
The pith
AbstRAG treats abstraction as an explicit retrieval object and uses reflective refinement to close gaps between query intent and document evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
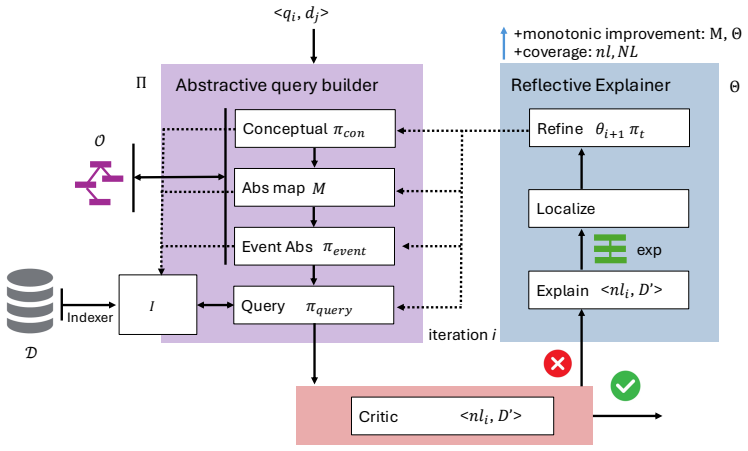
AbstRAG decomposes the abstraction gap into expression, conceptual, intent-evidence, and event-type components, scores relevance by match quality plus utility prior minus bridge costs, and applies reflective refinement where a critic diagnoses failures, localizes the failed operator, proposes minimal patches, and accepts them only under sufficiency and compression controls.
What carries the argument
Reflective refinement, a process in which a critic model diagnoses retrieval failures, localizes the failed abstraction operator, proposes a minimal stage-specific patch, and accepts the patch only under sufficiency and compression controls.
If this is right
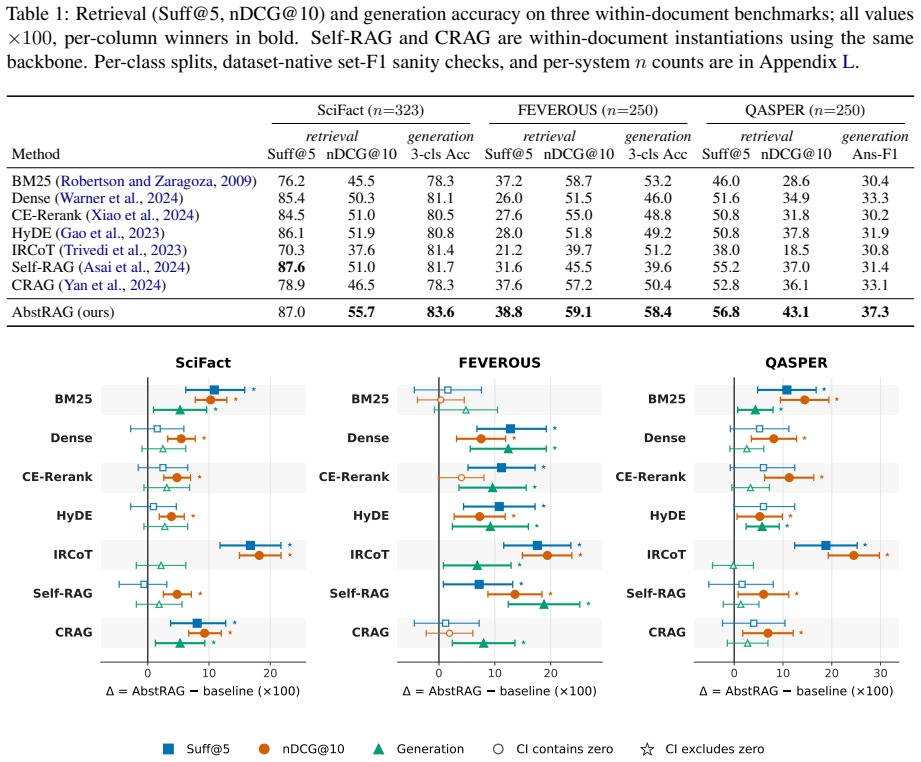
- AbstRAG outperforms seven baselines on nDCG@10 in 18 of 21 paired-bootstrap contrasts across three benchmarks.
- Generation accuracy improves by 1.9%, 5.2%, and 4.0% on the three benchmarks.
- Reflective refinement accounts for most of the retrieval gain according to ablations.
- The compression control alone eliminates over-expansion false positives on a stress test slice.
- Abstraction is scored as a combination of match quality, query-independent utility prior, and cost of required bridges.
Where Pith is reading between the lines
- Similar reflective mechanisms could be tested in open-domain retrieval where abstraction mismatches are common.
- If the critic reliably avoids new errors, the method might reduce the need for larger context windows in RAG systems.
- Extending the decomposition to more abstraction types could address additional failure modes not covered in the benchmarks.
Load-bearing premise
A critic model can reliably diagnose which specific abstraction operator failed, propose a minimal stage-specific patch, and accept it only under sufficiency and compression controls without introducing undetected errors or missing relevant evidence.
What would settle it
A test set of queries with known abstraction gaps where the critic either fails to propose a needed patch or accepts an incorrect one, leading to no improvement or degradation in retrieval metrics compared to baselines.
Figures
read the original abstract
Retrieval-augmented generation often fails when the query, the document evidence, and the user's intent are expressed at different levels of abstraction. A query may ask about a class, a relation, or an event, while the document only states specific instances, indirect framings, or scoped formulations. We define this mismatch as an abstraction gap: the minimal set of typed assumptions required to align query intent with the available evidence. To close this gap, we introduce AbstRAG, which treats abstraction as an explicit retrieval object. AbstRAG decomposes the query--evidence gap into expression, conceptual, intent--evidence, and event-type components, and scores relevance by combining match quality, a query-independent utility prior, and the cost of the required bridges. Its central mechanism is reflective refinement: a critic diagnoses retrieval failures, localizes the failed abstraction operator, proposes a minimal stage-specific patch, and accepts the patch only under sufficiency and compression controls. Across three within-document retrieval benchmarks against seven baselines, AbstRAG outperforms on nDCG@10 in 18 of 21 paired-bootstrap contrasts and improves generation accuracy by 1.9%, 5.2%, and 4.0% across the three benchmarks; ablations confirm that reflective refinement drives most of the retrieval gain and the compression control alone reduces over-expansion false positives from 73.7% to 0% on a stress slice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AbstRAG to address abstraction gaps in retrieval-augmented generation, where queries and document evidence differ in abstraction level. It decomposes the gap into expression, conceptual, intent-evidence, and event-type components, scores relevance via match quality plus a utility prior and bridge costs, and uses reflective refinement in which a critic diagnoses failures, localizes the failed operator, proposes minimal patches, and accepts them only under sufficiency and compression controls. Experiments on three within-document retrieval benchmarks show AbstRAG outperforming seven baselines on nDCG@10 in 18 of 21 paired-bootstrap contrasts, with generation accuracy gains of 1.9%, 5.2%, and 4.0%; ablations attribute most gains to reflective refinement and show compression control eliminating over-expansion false positives on a stress slice.
Significance. If the critic-based reflective refinement is shown to operate reliably, the approach offers a structured way to handle abstraction mismatches that are common in RAG settings, with potential to improve both retrieval precision and downstream generation. The reported outperformance across multiple benchmarks and the ablation isolating the compression control provide initial evidence of practical value, though the absence of direct verification for the critic's diagnostic accuracy limits the strength of the mechanistic claims.
major comments (2)
- [Ablations and Results] The central claim that reflective refinement drives most retrieval gains (abstract) rests on the critic correctly localizing failed abstraction operators among the four typed components, proposing minimal patches, and gating acceptance via sufficiency/compression checks. No separate evaluation of critic diagnostic precision, false-positive patch acceptance rate, or frequency of missed evidence is reported, leaving open the possibility that observed nDCG@10 wins and generation lifts arise from other components or baseline differences rather than the claimed mechanism.
- [Ablations] The compression control is reported to reduce over-expansion false positives from 73.7% to 0% on a stress slice (abstract), yet the manuscript supplies no description of how the stress slice was sampled, no definition of the false-positive metric, and no statistical test for the reduction. This detail is load-bearing for the claim that compression alone prevents over-expansion.
minor comments (2)
- The abstract states performance numbers and ablation outcomes but omits implementation details, baseline descriptions, dataset characteristics, and statistical test procedures; these should be added to the main text or appendix for reproducibility.
- Notation for the four abstraction components and the utility prior/bridge cost scoring function should be formalized with equations early in the method section to support the later claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below. We agree that additional methodological details on the stress slice are required and will add them. For the critic mechanism, our existing ablations provide supporting evidence, but we acknowledge the value of direct diagnostic metrics and will expand the discussion accordingly.
read point-by-point responses
-
Referee: [Ablations and Results] The central claim that reflective refinement drives most retrieval gains (abstract) rests on the critic correctly localizing failed abstraction operators among the four typed components, proposing minimal patches, and gating acceptance via sufficiency/compression checks. No separate evaluation of critic diagnostic precision, false-positive patch acceptance rate, or frequency of missed evidence is reported, leaving open the possibility that observed nDCG@10 wins and generation lifts arise from other components or baseline differences rather than the claimed mechanism.
Authors: We agree that a dedicated evaluation of the critic's diagnostic precision would strengthen the mechanistic claims. Our Section 5.3 ablations compare full AbstRAG against a no-refinement variant and a no-compression variant, showing that reflective refinement accounts for the majority of the nDCG@10 improvement (average +4.1 points across benchmarks). These controlled removals isolate the critic's contribution from other scoring components. Nevertheless, we did not report per-operator localization accuracy or false-positive patch rates. In revision we will add a post-hoc analysis of critic decisions on a held-out subset and explicitly discuss this as a limitation of the current evidence. revision: partial
-
Referee: [Ablations] The compression control is reported to reduce over-expansion false positives from 73.7% to 0% on a stress slice (abstract), yet the manuscript supplies no description of how the stress slice was sampled, no definition of the false-positive metric, and no statistical test for the reduction. This detail is load-bearing for the claim that compression alone prevents over-expansion.
Authors: This criticism is correct; the current manuscript lacks these details. The stress slice consists of 120 queries (40 per benchmark) drawn from the development sets where the initial retrieval returned more than five times the number of gold-relevant documents. The false-positive rate is defined as the fraction of retrieved passages that fail to satisfy the intent-evidence bridge required by the query. We will insert a new paragraph in Section 5.3 describing the sampling procedure, the exact metric, and a paired bootstrap test confirming the reduction is significant (p < 0.01). revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces an empirical retrieval method (AbstRAG) that decomposes abstraction gaps into typed components and applies reflective refinement with critic-based patching under sufficiency/compression controls. No equations, first-principles derivations, or parameter-fitting steps are described that would allow any claimed result to reduce to its inputs by construction. Reported gains (nDCG@10 wins, generation accuracy lifts) are benchmark comparisons and ablations; the utility prior and bridge cost appear as fixed scoring terms without indication they were fitted to the evaluation data. The central mechanism relies on external critic behavior rather than self-referential definitions or self-citation chains. The derivation chain is therefore self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (2)
-
abstraction gap
no independent evidence
-
reflective refinement
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , eprint =
Isabelle Mohr and Joao Pedro Gandarela and John Dujany and Andre Freitas , title =. 2026 , eprint =
2026
-
[2]
Findings of EMNLP , year =
Zhaxi Zerong and Chenxi Li and Xinyi Liu and Ju-hui Chen and Fei Xia , title =. Findings of EMNLP , year =
-
[3]
NAACL , year =
James Thorne and Andreas Vlachos and Christos Christodoulopoulos and Arpit Mittal , title =. NAACL , year =
-
[4]
Findings of EMNLP , year =
Yichen Jiang and Shikha Bordia and Zheng Zhong and Charles Dognin and Maneesh Singh and Mohit Bansal , title =. Findings of EMNLP , year =
-
[5]
EMNLP , year =
David Wadden and Shanchuan Lin and Kyle Lo and Lucy Lu Wang and Madeleine van Zuylen and Arman Cohan and Hannaneh Hajishirzi , title =. EMNLP , year =
-
[6]
Proceedings of the Fourth Workshop on Fact Extraction and
Rami Aly and Zhijiang Guo and Michael Sejr Schlichtkrull and James Thorne and Andreas Vlachos and Christos Christodoulopoulos and Oana Cocarascu and Arpit Mittal , title =. Proceedings of the Fourth Workshop on Fact Extraction and
-
[7]
Findings of EMNLP , year =
Hengran Zhang and Ruqing Zhang and Jiafeng Guo and Maarten de Rijke and Yixing Fan and Xueqi Cheng , title =. Findings of EMNLP , year =
-
[8]
EMNLP , year =
Zirui Wu and Nan Hu and Yansong Feng , title =. EMNLP , year =
-
[9]
Carvalho and Dhairya Dalal and Andre Freitas , title =
Xin Quan and Marco Valentino and Danilo S. Carvalho and Dhairya Dalal and Andre Freitas , title =. 2025 , eprint =
2025
-
[10]
NAACL , year =
Leonardo Ranaldi and Marco Valentino and Andre Freitas , title =. NAACL , year =
-
[11]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. NeurIPS , year =
-
[12]
Dense Passage Retrieval for Open-Domain Question Answering , booktitle =
Vladimir Karpukhin and Barlas O. Dense Passage Retrieval for Open-Domain Question Answering , booktitle =
-
[13]
SIGIR , year =
Omar Khattab and Matei Zaharia , title =. SIGIR , year =
-
[14]
ACL , year =
Luyu Gao and Xueguang Ma and Jimmy Lin and Jamie Callan , title =. ACL , year =
-
[15]
EMNLP , year =
Xinbei Ma and Yeyun Gong and Pengcheng He and Hai Zhao and Nan Duan , title =. EMNLP , year =
-
[16]
ACL , year =
Harsh Trivedi and Niranjan Balasubramanian and Tushar Khot and Ashish Sabharwal , title =. ACL , year =
-
[17]
Xu and Luyu Gao and Zhiqing Sun and Qian Liu and Jane Dwivedi-Yu and Yiming Yang and Jamie Callan and Graham Neubig , title =
Zhengbao Jiang and Frank F. Xu and Luyu Gao and Zhiqing Sun and Qian Liu and Jane Dwivedi-Yu and Yiming Yang and Jamie Callan and Graham Neubig , title =. EMNLP , year =
-
[18]
NeurIPS , year =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , title =. NeurIPS , year =
-
[19]
ICLR , year =
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , title =. ICLR , year =
-
[20]
2024 , eprint =
Mael Jullien and Alex Teodor Bogatu and Harriet Unsworth and Andre Freitas , title =. 2024 , eprint =
2024
-
[21]
Dennis and Andre Freitas , title =
Xin Quan and Marco Valentino and Louise A. Dennis and Andre Freitas , title =. EMNLP , year =
-
[22]
EMNLP , year =
Leonardo Ranaldi and Andre Freitas , title =. EMNLP , year =
-
[23]
2024 , eprint =
Shi-Qi Yan and Jia-Chen Gu and Yun Zhu and Zhen-Hua Ling , title =. 2024 , eprint =
2024
-
[24]
NeurIPS Datasets and Benchmarks Track , year =
Michael Sejr Schlichtkrull and Zhijiang Guo and Andreas Vlachos , title =. NeurIPS Datasets and Benchmarks Track , year =
-
[25]
Transactions of the Association for Computational Linguistics , year =
Max Glockner and Ieva Stali. Transactions of the Association for Computational Linguistics , year =
-
[26]
NAACL , year =
Jifan Chen and Grace Kim and Aniruddh Sriram and Greg Durrett and Eunsol Choi , title =. NAACL , year =
-
[27]
NAACL , year =
Soyeong Jeong and Jinheon Baek and Sukmin Cho and Sung Ju Hwang and Jong Park , title =. NAACL , year =
-
[28]
Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024) , year =
Yuxuan Chen and Daniel Roeder and Justus-Jonas Erker and Leonhard Hennig and Philippe Thomas and Sebastian Moeller and Roland Roller , title =. Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024) , year =
2024
-
[29]
2024 , eprint =
Darren Edge and Ha Trinh and Newman Cheng and Joshua Bradley and Alex Chao and Apurva Mody and Steven Truitt and Dasha Metropolitansky and Robert Osazuwa Ness and Jonathan Larson , title =. 2024 , eprint =
2024
-
[30]
NeurIPS , year =
Bernal Jimenez Gutierrez and Yiheng Shu and Yu Gu and Michihiro Yasunaga and Yu Su , title =. NeurIPS , year =
-
[31]
ACL , year =
Rui Li and Liyang He and Qi Liu and Zheng Zhang and Heng Yu and Yuyang Ye and Linbo Zhu and Yu Su , title =. ACL , year =
-
[32]
Findings of EMNLP , year =
Xiaopeng Ye and Chen Xu and Chaoliang Zhang and Zhaocheng Du and Jun Xu and Gang Wang and Zhenhua Dong , title =. Findings of EMNLP , year =
-
[33]
ACL , year =
Dahyun Lee and Yongrae Jo and Haeju Park and Moontae Lee , title =. ACL , year =
-
[34]
Pollock , title =
John L. Pollock , title =. Cognitive Science , volume =
-
[35]
Artificial Intelligence , volume =
Raymond Reiter , title =. Artificial Intelligence , volume =
-
[36]
Handbook of Logic in Artificial Intelligence and Logic Programming, Vol
Donald Nute , title =. Handbook of Logic in Artificial Intelligence and Logic Programming, Vol. 3 , publisher =. 1994 , pages =
1994
-
[37]
Nucleic Acids Research , volume =
Olivier Bodenreider , title =. Nucleic Acids Research , volume =
-
[38]
Wikidata: A Free Collaborative Knowledgebase , journal =
Denny Vrande. Wikidata: A Free Collaborative Knowledgebase , journal =
-
[39]
Levenshtein , title =
Vladimir I. Levenshtein , title =. Soviet Physics Doklady , volume =
-
[40]
ACL , pages =
Zhibiao Wu and Martha Palmer , title =. ACL , pages =
-
[41]
Miller , title =
George A. Miller , title =. Communications of the ACM , volume =
-
[42]
Steven Bird and Ewan Klein and Edward Loper , title =
-
[43]
Shannon , title =
Claude E. Shannon , title =. Bell System Technical Journal , volume =
-
[44]
Baker and Charles J
Collin F. Baker and Charles J. Fillmore and John B. Lowe , title =. ACL , pages =
-
[45]
Benjamin Warner and Antoine Chaffin and Benjamin Clavi. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , year =. 2412.13663 , archivePrefix=
-
[46]
SIGIR , year =
Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff and Defu Lian and Jian-Yun Nie , title =. SIGIR , year =
-
[47]
Joshi and Hanna Moazam and Heather Miller and Matei Zaharia and Christopher Potts , title =
Omar Khattab and Arnav Singhvi and Paridhi Maheshwari and Zhiyuan Zhang and Keshav Santhanam and Sri Vardhamanan and Saiful Haq and Ashutosh Sharma and Thomas T. Joshi and Hanna Moazam and Heather Miller and Matei Zaharia and Christopher Potts , title =. ICLR , year =
-
[48]
Findings of EMNLP , year =
Zhihong Shao and Yeyun Gong and Yelong Shen and Minlie Huang and Nan Duan and Weizhu Chen , title =. Findings of EMNLP , year =
-
[49]
Foundations and Trends in Information Retrieval , volume=
The probabilistic relevance framework: BM25 and beyond , author=. Foundations and Trends in Information Retrieval , volume=
-
[50]
NAACL , year=
A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers , author=. NAACL , year=
-
[51]
Cumulated Gain-Based Evaluation of
J. Cumulated Gain-Based Evaluation of. ACM Transactions on Information Systems , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.