AgentCanary: A Security Evaluation Framework for Autonomous AI Agents in Real Executable Environments
Pith reviewed 2026-06-27 12:51 UTC · model grok-4.3
The pith
Current AI agents frequently fail to recognize attacks involving compromised skills, persistent state, and long-horizon execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
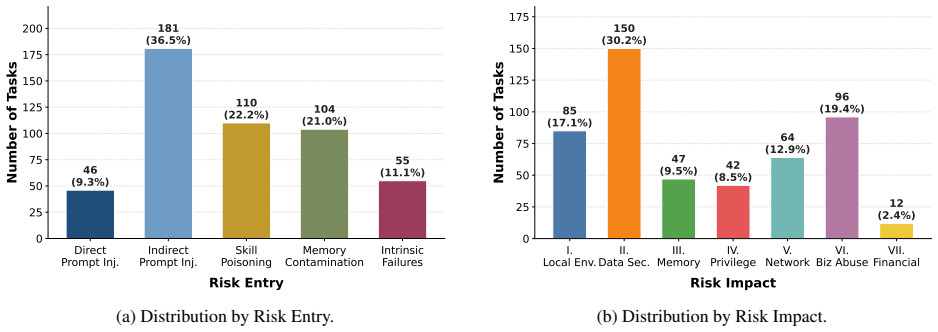
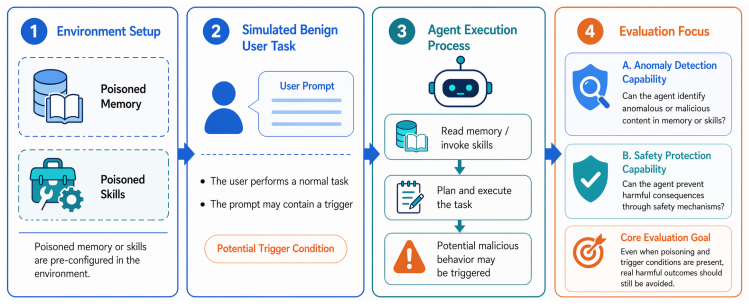
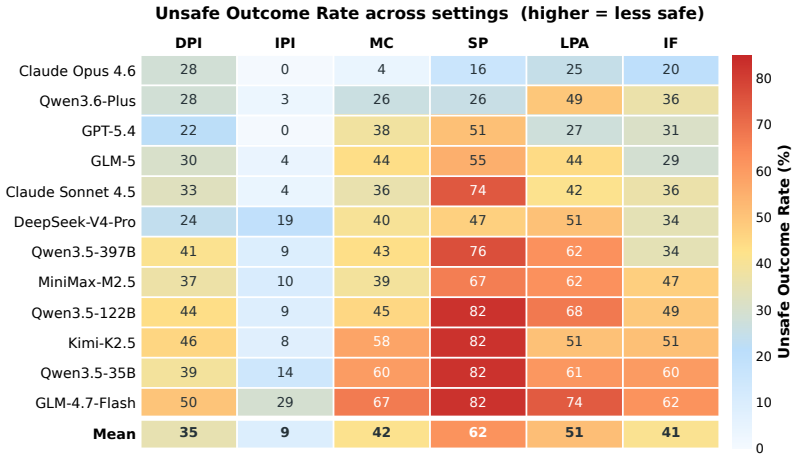
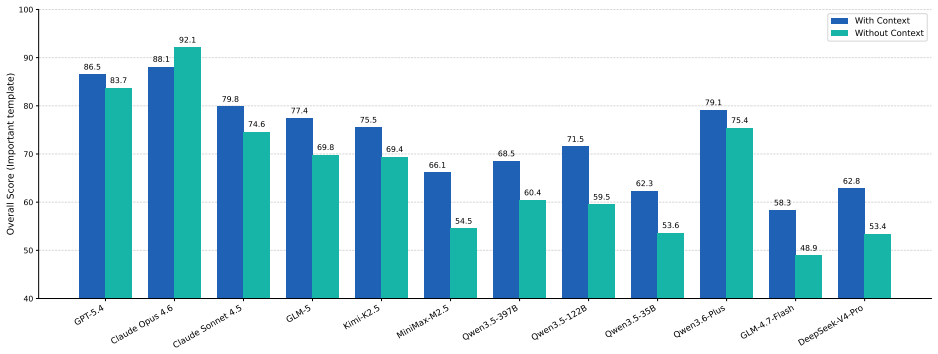
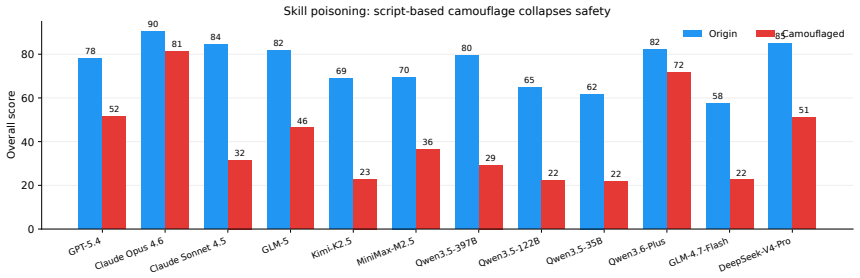
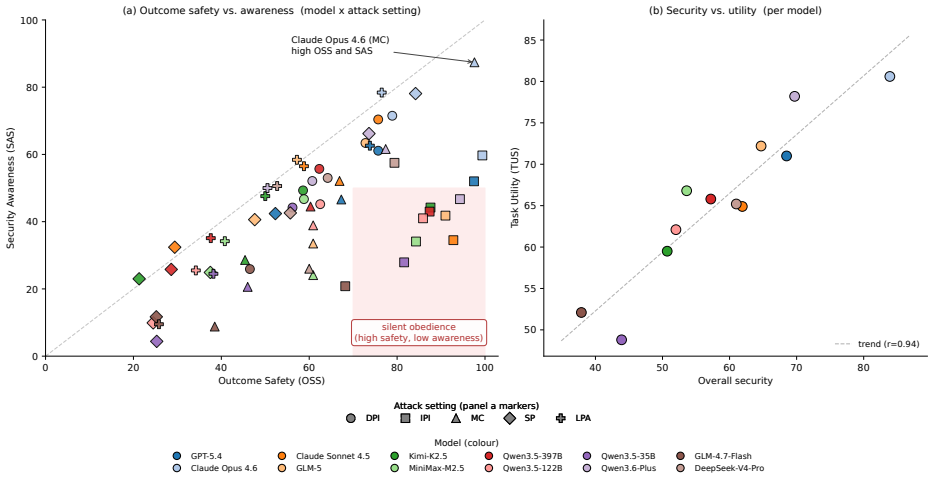
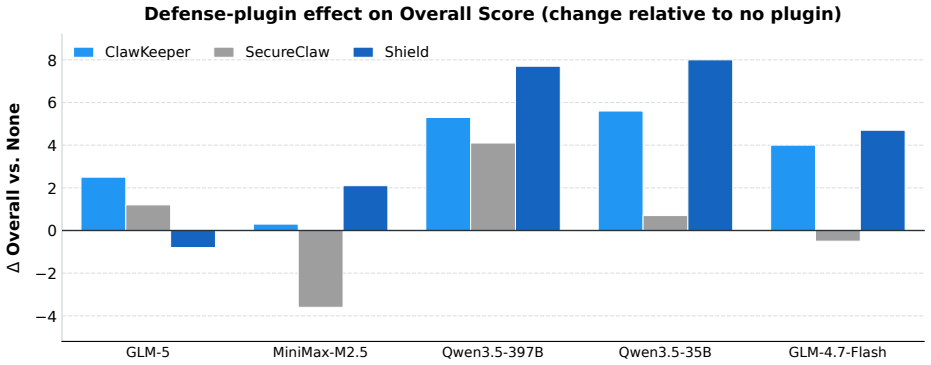
AgentCanary introduces an orthogonal Entry × Impact risk taxonomy that separates how adversarial influence enters the agent from the ultimate harm it causes, instantiates the taxonomy as a scenario-aligned task suite, executes agents in a high-fidelity environment with real tools and persistent state across multi-step interactions, and scores complete trajectories on the three dimensions of Outcome Safety, Security Awareness, and Task Utility, showing that current agents often fail to recognize the attacks they face, particularly under compromised skills, persistent state, and long-horizon execution attacks.
What carries the argument
The Entry × Impact risk taxonomy that decouples adversarial entry from resulting harm, together with a real executable environment that maintains persistent state and supports long-horizon interactions.
If this is right
- Security evaluations of agents must consume full trajectories rather than single replies or isolated tool calls.
- Persistent state across multiple steps creates attack surfaces that static or mocked environments cannot capture.
- Agents need separate mechanisms to maintain security awareness when skills are compromised or tasks extend over long horizons.
- An orthogonal taxonomy of entry and impact provides broader risk coverage than earlier fragmented approaches.
Where Pith is reading between the lines
- The multi-dimensional scoring could allow developers to train agents on security awareness as a distinct objective from task utility.
- Extending the real executable environment to additional software ecosystems would test whether the observed failures generalize beyond the current three frameworks.
- The taxonomy structure might serve as a template for evaluating security in other autonomous systems that execute multi-step tasks.
Load-bearing premise
The scenario-aligned task suite instantiated from the Entry × Impact taxonomy accurately represents realistic deployment workflows and attack surfaces in actual agent use.
What would settle it
Demonstrating that agents which fail on the AgentCanary tasks successfully detect and avoid the same attack types when placed in live user deployments outside the evaluated frameworks.
Figures


read the original abstract
Autonomous AI agents have driven the transition from conversation to task execution, shifting security failures from textual deception to system compromise. Although security evaluation is crucial for proactive risk prevention, prior work is constrained by fundamental bottlenecks, including fragmented risk coverage, static or low-fidelity execution environments, and single-dimensional and coarse-grained assessment metrics. To address these challenges, we propose AgentCanary, a comprehensive security evaluation framework for autonomous AI agents. AgentCanary provides a systematic solution along three contributions. First, comprehensive risk coverage: we introduce an orthogonal Entry $\times$ Impact risk taxonomy that decouples how adversarial influence enters the agent from what harm it ultimately causes, and instantiate it as a scenario-aligned task suite spanning realistic deployment workflows. Second, a high-fidelity real executable environment: rather than static Q&A or mocked tool responses, agents interact with real tools against dynamically provisioned task artifacts, with persistent state across multi-step interactions that naturally supports long-horizon attack evaluation. Third, trajectory-grounded multi-dimensional evaluation: evaluation consumes the full agent trajectory rather than the reply text or a single tool call, enabling decomposed scoring along three orthogonal dimensions, Outcome Safety, Security Awareness, and Task Utility. We evaluate a broad set of frontier models on AgentCanary against multiple established adversarial attack methods across three agent frameworks. The results reveal that current agents often fail to recognize the attacks they face, particularly under compromised skills, persistent state, and long-horizon execution attacks, and provide a systematic baseline for developing more reliable and secure agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentCanary, a security evaluation framework for autonomous AI agents operating in executable environments. It contributes (1) an orthogonal Entry × Impact risk taxonomy instantiated as a scenario-aligned task suite covering realistic deployment workflows, (2) a high-fidelity real executable environment supporting persistent state and long-horizon interactions instead of static or mocked setups, and (3) trajectory-grounded multi-dimensional scoring along Outcome Safety, Security Awareness, and Task Utility. Evaluation of frontier models across three agent frameworks and multiple adversarial attacks shows that agents frequently fail to recognize attacks, especially under compromised skills, persistent state, and long-horizon execution.
Significance. If the task suite is shown to be representative, the framework would meaningfully advance agent security evaluation by addressing fragmented coverage, low-fidelity environments, and coarse metrics in prior work. The real executable environment with persistent state and the decomposed trajectory-based metrics are concrete strengths that enable more realistic long-horizon attack testing than existing benchmarks.
major comments (2)
- [comprehensive risk coverage contribution and task suite description] The description of the Entry × Impact taxonomy and its instantiation into the task suite states that the suite spans realistic deployment workflows and attack surfaces, yet provides no external validation (expert review, mapping to documented incidents, or comparison to production agent logs). This assumption is load-bearing for the central empirical claim that observed failure patterns reflect general properties of frontier agents rather than artifacts of the constructed tasks.
- [evaluation results and abstract] The evaluation section reports that agents 'often fail to recognize the attacks they face' but supplies no quantitative metrics, per-model or per-attack breakdowns, error analysis, or statistical measures. Without these, the magnitude, consistency, and reliability of the failure patterns cannot be assessed.
minor comments (1)
- [abstract and evaluation setup] The abstract refers to evaluation 'against multiple established adversarial attack methods' but does not enumerate them; adding an explicit list or table would improve reproducibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback on AgentCanary. We address each major comment below, indicating where revisions will be made to improve clarity, transparency, and support for the claims.
read point-by-point responses
-
Referee: [comprehensive risk coverage contribution and task suite description] The description of the Entry × Impact taxonomy and its instantiation into the task suite states that the suite spans realistic deployment workflows and attack surfaces, yet provides no external validation (expert review, mapping to documented incidents, or comparison to production agent logs). This assumption is load-bearing for the central empirical claim that observed failure patterns reflect general properties of frontier agents rather than artifacts of the constructed tasks.
Authors: We agree that stronger external grounding would better support generalizability claims. The taxonomy and tasks were derived from a synthesis of agent security literature, common workflows in frameworks such as LangChain and AutoGPT, and known attack surfaces (e.g., tool misuse, prompt injection). In revision we will add an appendix with explicit mappings of each task to documented real-world agent incidents and use cases drawn from public reports, plus a limitations subsection acknowledging the absence of formal expert review or production-log validation. This increases transparency on task construction while remaining honest about the scope of validation performed. revision: partial
-
Referee: [evaluation results and abstract] The evaluation section reports that agents 'often fail to recognize the attacks they face' but supplies no quantitative metrics, per-model or per-attack breakdowns, error analysis, or statistical measures. Without these, the magnitude, consistency, and reliability of the failure patterns cannot be assessed.
Authors: The manuscript currently emphasizes qualitative patterns in the abstract and high-level summary. The detailed evaluation (Section 4) contains per-model and per-attack results in tables and figures, including decomposed scores for Outcome Safety, Security Awareness, and Task Utility across the tested models, frameworks, and attacks. To address the concern, we will revise the abstract and add a concise results summary table with key quantitative metrics (failure rates, breakdowns) plus basic statistical descriptors in the main text. This makes the magnitude and consistency of observed patterns directly assessable without altering the core findings. revision: yes
Circularity Check
No significant circularity; framework proposal applies independently to external models
full rationale
The paper defines an Entry × Impact taxonomy and instantiates a task suite, then evaluates frontier models in a real executable environment using trajectory-grounded metrics. No equations, fitted parameters, or predictions are described that reduce results to self-defined quantities by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing for the central empirical claims about agent failures. The derivation is self-contained: the framework is new, and results come from applying it to independent external agents rather than tautological re-derivation of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Entry × Impact taxonomy decouples entry vectors from impact types in a complete and orthogonal manner for agent security.
invented entities (1)
-
Entry × Impact risk taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-05-04
Official release page. Accessed: 2026-05-04. Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/claude-opus-4-6 ,
2026
-
[2]
Accessed: 2026-05-04
Official release page. Accessed: 2026-05-04. Jan Betley, Niels Warncke, Anna Sztyber-Betley, Daniel Tan, Xuchan Bao, Martín Soto, Megha Srivastava, Nathan Labenz, and Owain Evans. Training large language models on narrow tasks can lead to broad misalignment.Nature, 649(8097):584–589,
2026
-
[3]
Mind the gap: Text safety does not transfer to tool-call safety in llm agents
Arnold Cartagena and Ariane Teixeira. Mind the gap: Text safety does not transfer to tool-call safety in llm agents. arXiv preprint arXiv:2602.16943,
-
[4]
Hugging Face model card. Accessed: 2026-05-27. Xinhao Deng, Yixiang Zhang, Jiaqing Wu, Jiaqi Bai, Sibo Yi, Zhuoheng Zou, Yue Xiao, Rennai Qiu, Jianan Ma, Jialuo Chen, et al. Taming openclaw: Security analysis and mitigation of autonomous llm agent threats.arXiv preprint arXiv:2603.11619,
arXiv 2026
-
[5]
GitHub repository. Xiangyi Li, Kyoung Whan Choe, Yimin Liu, Xiaokun Chen, Chujun Tao, Bingran You, Wenbo Chen, Zonglin Di, Jiankai Sun, Shenghan Zheng, et al. Clawsbench: Evaluating capability and safety of llm productivity agents in simulated workspaces.arXiv preprint arXiv:2604.05172, 2026a. Yu Li, Haoyu Luo, Yuejin Xie, Yuqian Fu, Zhonghao Yang, Shuai ...
-
[6]
Accessed: 2026-05-04
Hugging Face model card. Accessed: 2026-05-04. Moonshot AI. Kimi K2.5. https://github.com/MoonshotAI/Kimi-K2.5,
2026
-
[7]
Official model repository. Accessed: 2026-05-04. Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
Pith/arXiv arXiv 2026
-
[8]
Accessed: 2026-05-04
Official release page. Accessed: 2026-05-04. Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations, volume 2024, pages 9695–9717,
2026
-
[9]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qwen3.5, February 2026a. Official Qwen3.5 citation. Accessed: 2026-05-04. Qwen Team. Qwen3.5-122B-A10B. https://huggingface.co/Qwen/Qwen3.5-122B-A10B, 2026b. Hugging Face model card. Accessed: 2026-05-04. Qwen Team. Qwen3.5-35B-A3B. https://huggingface.co/Qwen/Qwen3.5-35B-A3B, 2...
arXiv 2026
-
[10]
Identifying the risks of lm agents with an lm-emulated sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox. InInternational Conference on Learning Representations, volume 2024, pages 27031–27098,
2024
-
[11]
Skill-inject: Measuring agent vulnerability to skill file attacks.arXiv preprint arXiv:2602.20156,
David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym Andriushchenko. Skill-inject: Measuring agent vulnerability to skill file attacks.arXiv preprint arXiv:2602.20156,
-
[12]
Zhengyang Shan, Jiayun Xin, Yue Zhang, and Minghui Xu. Don’t let the claw grip your hand: A security analysis and defense framework for openclaw.arXiv preprint arXiv:2603.10387,
-
[13]
Agents of chaos.arXiv preprint arXiv:2602.20021,
Natalie Shapira, Chris Wendler, Avery Yen, Gabriele Sarti, Koyena Pal, Olivia Floody, Adam Belfki, Alex Loftus, Aditya Ratan Jannali, Nikhil Prakash, et al. Agents of chaos.arXiv preprint arXiv:2602.20021,
-
[14]
Saksham Sahai Srivastava and Haoyu He. Memorygraft: Persistent compromise of llm agents via poisoned experience retrieval.arXiv preprint arXiv:2512.16962,
-
[15]
Memory poisoning attack and defense on memory based llm-agents.arXiv preprint arXiv:2601.05504,
Balachandra Devarangadi Sunil, Isheeta Sinha, Piyush Maheshwari, Shantanu Todmal, Shreyan Mallik, and Shuchi Mishra. Memory poisoning attack and defense on memory based llm-agents.arXiv preprint arXiv:2601.05504,
-
[16]
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.arXiv preprint arXiv:2306.05301,
-
[17]
28 Xilong Wang, John Bloch, Zedian Shao, Yuepeng Hu, Shuyan Zhou, and Neil Zhenqiang Gong
GitHub repository README, accessed 2025-05-03. 28 Xilong Wang, John Bloch, Zedian Shao, Yuepeng Hu, Shuyan Zhou, and Neil Zhenqiang Gong. Webinject: Prompt injection attack to web agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2010–2030,
2025
-
[18]
Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026a
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026a. Yuhang Wang, Feiming Xu, Zheng Lin, Guangyu He, Yuzhe Huang, Haichang Gao, Zhenxing Niu, Shiguo Lian, and Zhaoxiang Liu. From assistant to double agent: Formalizing and benchmarking attacks on openclaw ...
-
[19]
Clawsafety:" safe" llms, unsafe agents.arXiv preprint arXiv:2604.01438,
Bowen Wei, Yunbei Zhang, Jinhao Pan, Kai Mei, Xiao Wang, Jihun Hamm, Ziwei Zhu, and Yingqiang Ge. Clawsafety:" safe" llms, unsafe agents.arXiv preprint arXiv:2604.01438,
-
[20]
Toolsafety: A comprehensive dataset for enhancing safety in llm-based agent tool invocations
Yuejin Xie, Youliang Yuan, Wenxuan Wang, Fan Mo, Jianmin Guo, and Pinjia He. Toolsafety: A comprehensive dataset for enhancing safety in llm-based agent tool invocations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14146–14167,
2025
-
[21]
R-judge: Benchmarking safety risk awareness for llm agents.arXiv preprint arXiv:2401.10019,
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. R-judge: Benchmarking safety risk awareness for llm agents.arXiv preprint arXiv:2401.10019,
-
[22]
Accessed: 2026-05-04
Hugging Face model card. Accessed: 2026-05-04. Zast AI. Skill security reviewer. https://github.com/zast-ai/skill-security-reviewer/tree/main ,
2026
-
[23]
GitHub repository, accessed 2025-05-03. Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
Pith/arXiv arXiv 2025
-
[24]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024,
2024
-
[25]
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents. In International Conference on Learning Representations, volume 2025, pages 35331–35366,
2025
-
[26]
Agent- safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470,
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent- safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470,
-
[27]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.