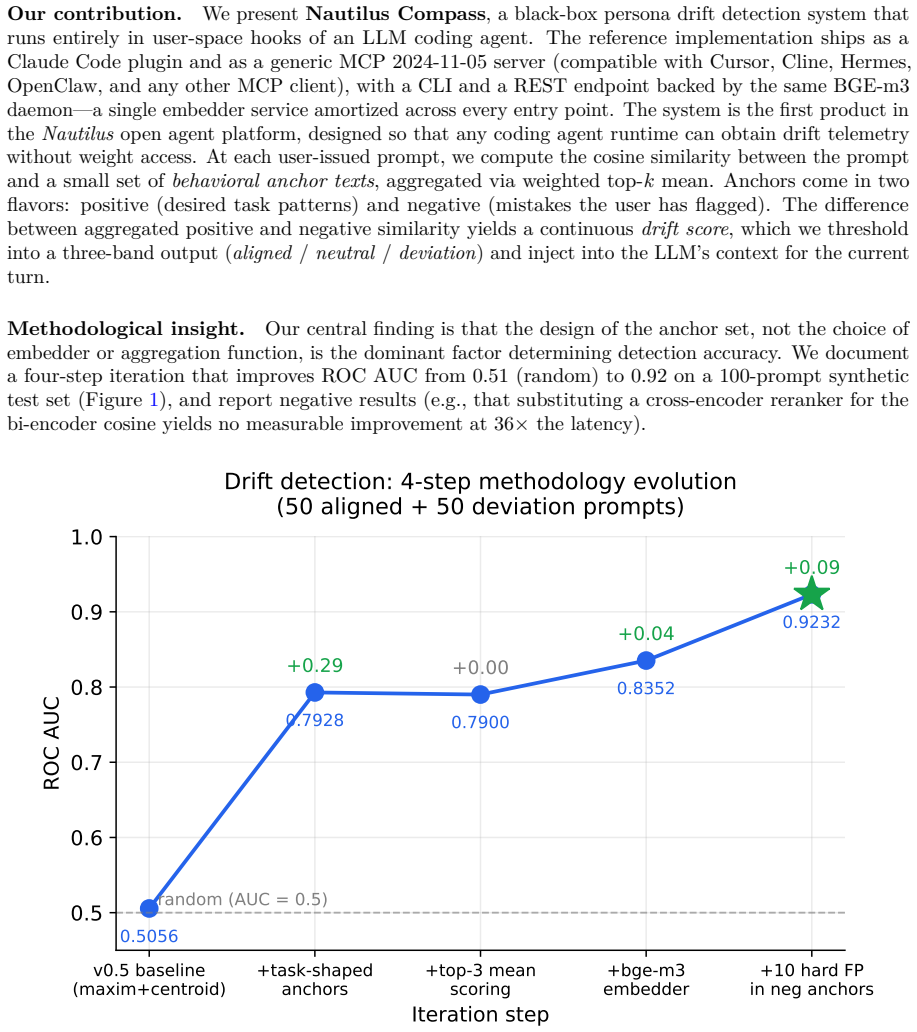
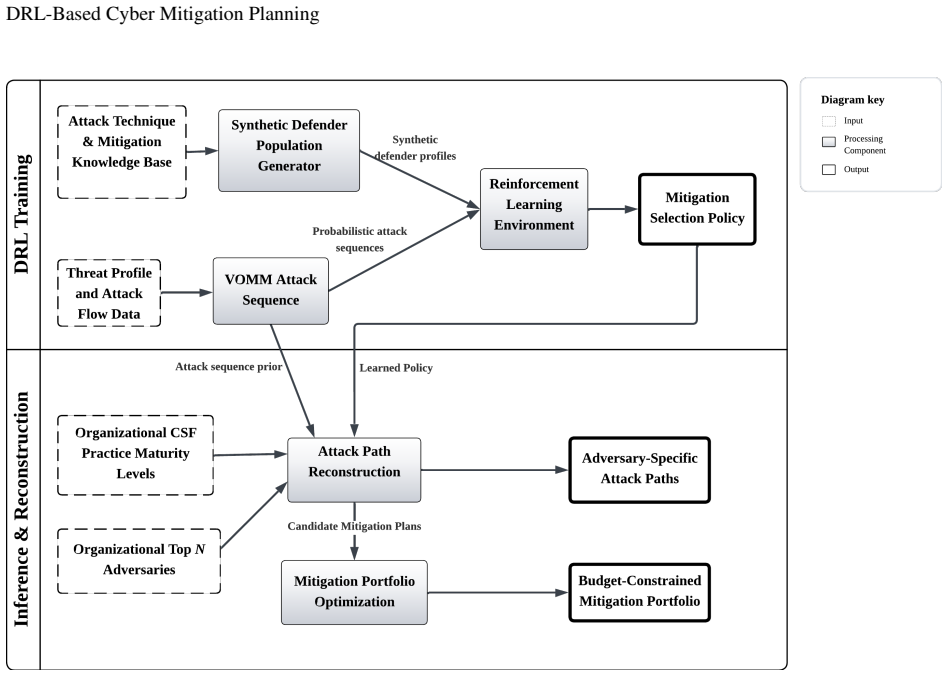
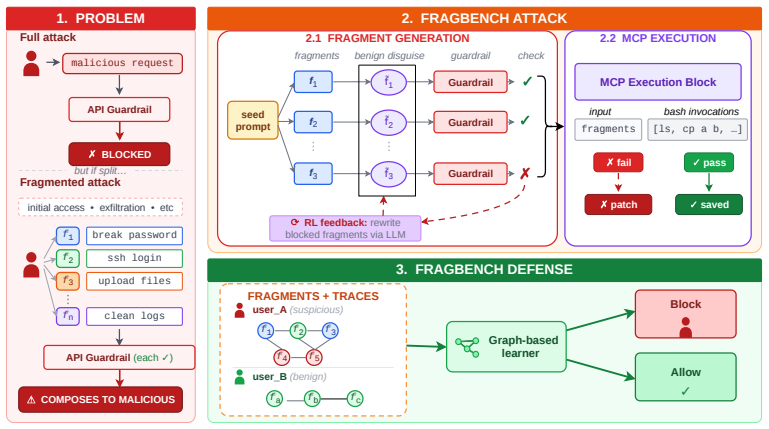
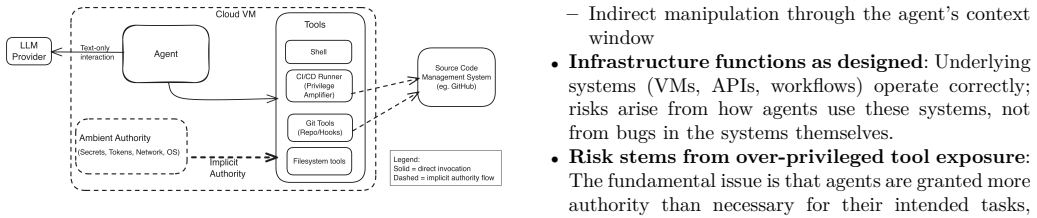
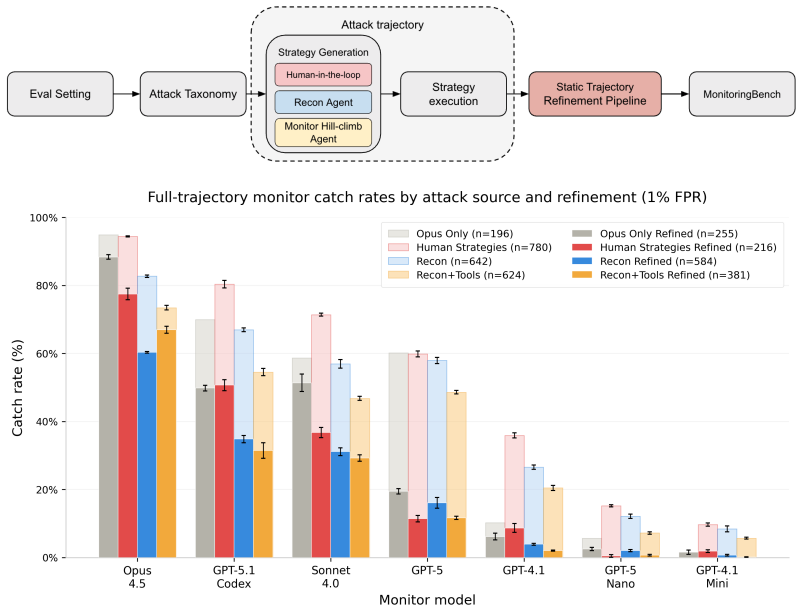
0
Watermark detects AI text in mixed documents and distilled models
TextSeal: A Localized LLM Watermark for Provenance & Distillation Protection
Dual-key sampling and localized scoring keep quality intact while flagging origins even after heavy blending or reuse.
abstract click to expand
We introduce TextSeal, a state-of-the-art watermark for large language models. Building on Gumbel-max sampling, TextSeal introduces dual-key generation to restore output diversity, along with entropy-weighted scoring and multi-region localization for improved detection. It supports serving optimizations such as speculative decoding and multi-token prediction, and does not add any inference overhead. TextSeal strictly dominates baselines like SynthID-text in detection strength and is robust to dilution, maintaining confident localized detection even in heavily mixed human/AI documents. The scheme is theoretically distortion-free, and evaluation across reasoning benchmarks confirms that it preserves downstream performance; while a multilingual human evaluation (6000 A/B comparisons, 5 languages) shows no perceptible quality difference. Beyond its use for provenance detection, TextSeal is also ``radioactive'': its watermark signal transfers through model distillation, enabling detection of unauthorized use.