SinkRec: Mitigating Semantic State Sink in Long Sequence Recommendation with Memory-Conditioned Gated Delta Networks
Pith reviewed 2026-06-28 07:12 UTC · model grok-4.3
The pith
Linear attention recommenders suffer semantic state sink when repetitive patterns dominate the recurrent state, but SinkRec offloads them to conditional memory so the state tracks only dynamic transitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
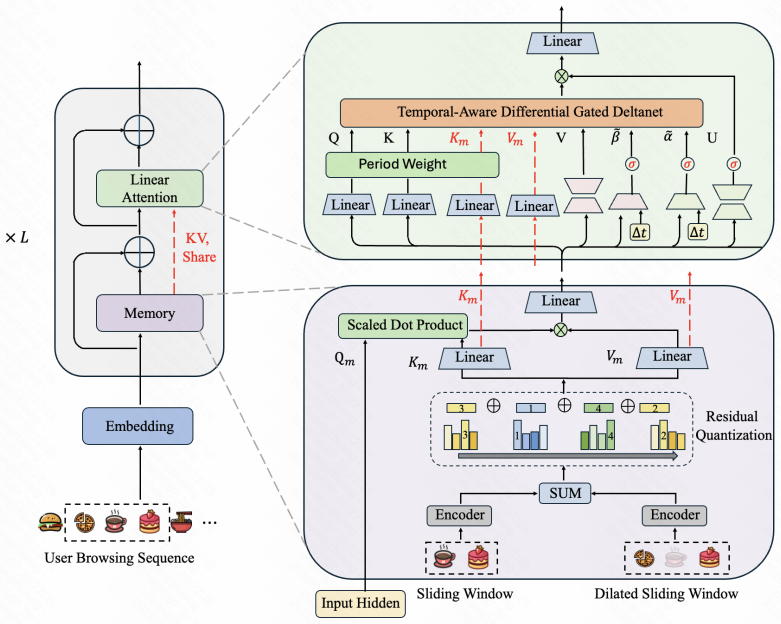
Linear attention provides an efficient backbone for long-sequence recommendation by avoiding quadratic cost, yet its compressed recurrent state becomes dominated by repetitive behavior patterns. The paper names this semantic state sink and proposes SinkRec, a hybrid memory-transition looped architecture that decouples collaborative behavioral pattern storage from dynamic transition modeling. SinkRec externalizes recurring local patterns into a learnable conditional memory through residual vector quantization, reinjects the retrieved codes, and exposes memory key-value pairs to the attention block. It further introduces TDGD, which uses memory to purify recurrent writing and reading by suppre
What carries the argument
Temporal-Aware State-Relation Differential Gated DeltaNet (TDGD) paired with residual vector quantization into conditional memory, which suppresses memory-covered state updates and removes memory-aligned readout responses to isolate dynamic transitions.
If this is right
- The recurrent state focuses on dynamic transitions rather than being occupied by repetitive patterns.
- Recurring local patterns become retrievable from external memory instead of competing inside the state.
- Linear-time efficiency is preserved while handling longer sequences.
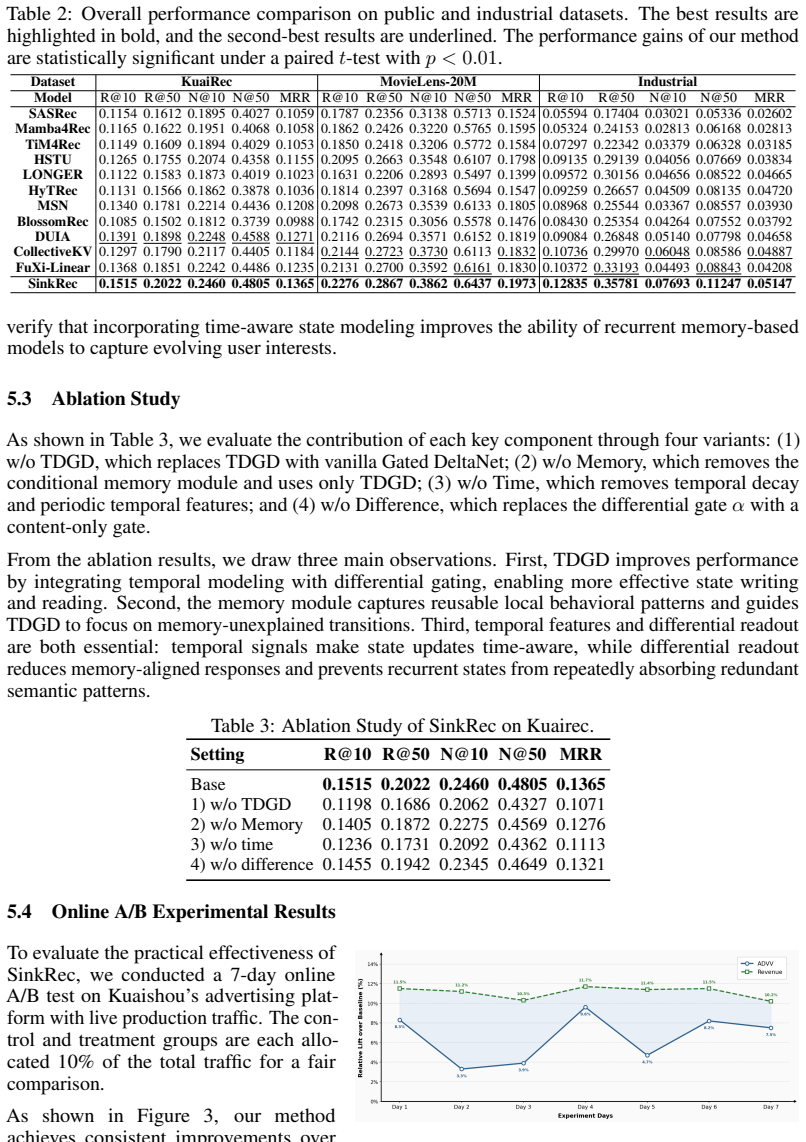
- Performance improves on both public benchmarks and industrial recommendation datasets.
Where Pith is reading between the lines
- The same memory-purification pattern could be tested in linear-attention language models where repetitive phrases might similarly sink the state.
- Combining this with other state-compression techniques might further extend effective sequence length without quadratic cost.
- The TDGD gating logic might generalize to any recurrent model that mixes external memory with internal state updates.
Load-bearing premise
Recurring semantics over-occupy the recurrent state and bias subsequent readouts in linear attention models, and external memory plus TDGD can convert those patterns into retrievable codes without introducing new biases or performance regressions.
What would settle it
An ablation that removes the conditional memory and TDGD components and measures whether long-sequence recommendation metrics fall back to baseline linear-attention levels on the same datasets would directly test the claim.
Figures

read the original abstract
Linear attention provides an efficient backbone for long-sequence recommendation by avoiding the quadratic cost of standard Transformers, but its compressed recurrent state can be dominated by repetitive behavior patterns. We identify this phenomenon as semantic state sink, where recurring semantics over-occupy the recurrent state and bias subsequent readouts. To mitigate semantic state sink, we propose SinkRec, a hybrid memory-transition looped architecture that decouples collaborative behavioral pattern storage from dynamic transition modeling. SinkRec externalizes recurring local patterns into a learnable conditional memory through residual vector quantization, reinjects the retrieved codes, and exposes memory key-value pairs to the attention block. It further introduces Temporal-Aware State-Relation Differential Gated DeltaNet (TDGD), which uses memory to purify recurrent writing and reading by suppressing memory-covered updates and removing memory-aligned readout responses. This design turns recurring semantics from state-competing signals into memory-retrievable patterns, allowing the recurrent state to focus on dynamic transitions and alleviating semantic state sink with linear-time efficiency. Experiments on public and industrial datasets demonstrate the effectiveness and efficiency of SinkRec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies semantic state sink in linear attention models for long-sequence recommendation, where recurring semantics over-occupy the recurrent state and bias readouts. It proposes SinkRec, a hybrid architecture that externalizes recurring patterns via residual vector quantization into a learnable conditional memory, reinjects retrieved codes, exposes memory KV pairs to attention, and introduces TDGD to suppress memory-covered updates and remove memory-aligned readout responses. This allows the recurrent state to focus on dynamic transitions. Experiments on public and industrial datasets demonstrate effectiveness and linear-time efficiency.
Significance. If the empirical claims hold, the work provides a practical mechanism for improving state compression in linear attention recommenders by decoupling pattern storage from transitions via memory and gated differentials. The combination of RVQ-based memory conditioning with TDGD offers a targeted architectural response to repetitive behavior dominance, which could influence efficient long-sequence modeling in recommendation systems.
minor comments (3)
- [§3.2] §3.2: The formal definition of the TDGD update rule would benefit from an explicit equation showing how memory keys suppress the delta term, as the prose description leaves the exact gating computation ambiguous.
- [Table 2] Table 2: The industrial dataset results report relative improvements but omit absolute metrics (e.g., NDCG@10 values) and variance across runs, which weakens direct comparison to baselines.
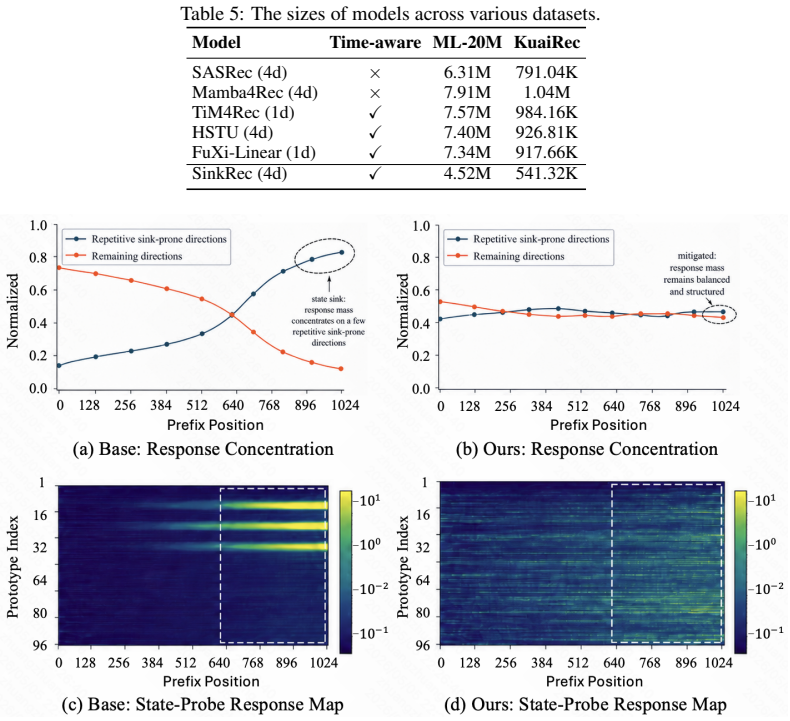
- [Figure 3] Figure 3: The ablation plot for memory size does not include a no-memory baseline, making it difficult to quantify the isolated contribution of the RVQ component.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We appreciate the recognition of the practical value of decoupling pattern storage from transitions via memory-conditioned TDGD in linear attention recommenders.
Circularity Check
No significant circularity; derivation is architectural proposal without self-referential reduction
full rationale
The paper presents an architectural design (RVQ memory + TDGD) to address an empirically identified phenomenon (semantic state sink) in linear attention models. No equations, parameter-fitting steps, or derivation chains are visible in the provided text that reduce a claimed prediction or result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the central mitigation is not asserted via renaming or ansatz smuggling. The design is presented as a proposed solution validated by experiments, remaining self-contained against external benchmarks without circular reduction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
semantic state sink
no independent evidence
-
TDGD
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Memory caching: Rnns with growing memory.arXiv preprint arXiv:2602.24281, 2026
Ali Behrouz, Zeman Li, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, and Vahab Mirrokni. Memory caching: Rnns with growing memory.arXiv preprint arXiv:2602.24281, 2026
-
[2]
Longer: Scaling up long sequence modeling in industrial recommenders
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems, pages 247–256, 2025
2025
-
[3]
Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3785–3794, 2023
2023
-
[4]
Yixiao Chen, Yuan Wang, Yue Liu, Qiyao Wang, Ke Cheng, Xin Xu, Juntong Yan, Shuojin Yang, Menghao Guo, Jun Zhang, et al. Recurrent preference memory for efficient long-sequence generative recommendation.arXiv preprint arXiv:2602.11605, 2026
-
[5]
Zhimin Chen, Chenyu Zhao, Ka Chun Mo, Yunjiang Jiang, Jane H Lee, Khushhall Chandra Mahajan, Ning Jiang, Kai Ren, Jinhui Li, and Wen-Yun Yang. Massive memorization with hundreds of trillions of parameters for sequential transducer generative recommenders.arXiv preprint arXiv:2510.22049, 2025
-
[6]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, et al. Conditional memory via scalable lookup: A new axis of sparsity for large language models.arXiv preprint arXiv:2601.07372, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Tim4rec: An efficient sequential recommendation model based on time-aware structured state space duality model
Hao Fan, Mengyi Zhu, Yanrong Hu, Hailin Feng, Zhijie He, Hongjiu Liu, and Qingyang Liu. Tim4rec: An efficient sequential recommendation model based on time-aware structured state space duality model. Neurocomputing, page 131270, 2025
2025
-
[8]
Kuairec: A fully-observed dataset and insights for evaluating recommender systems
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. Kuairec: A fully-observed dataset and insights for evaluating recommender systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 540–550, 2022
2022
-
[9]
Yizhao Gao, Jianyu Wei, Qihao Zhang, Yu Cheng, Shimao Chen, Zhengju Tang, Zihan Jiang, Yifan Song, Hailin Zhang, Liang Zhao, et al. Hysparse: A hybrid sparse attention architecture with oracle token selection and kv cache sharing.arXiv preprint arXiv:2602.03560, 2026
-
[10]
Mingming Ha, Guanchen Wang, Linxun Chen, Xuan Rao, Yuexin Shi, Tianbao Ma, Zhaojie Liu, Yunqian Fan, Zilong Lu, Yanan Niu, et al. Unimixer: A unified architecture for scaling laws in recommendation systems.arXiv preprint arXiv:2604.00590, 2026
- [11]
-
[12]
Zihao Huang, Yu Bao, Qiyang Min, Siyan Chen, Ran Guo, Hongzhi Huang, Defa Zhu, Yutao Zeng, Banggu Wu, Xun Zhou, et al. Ultramemv2: Memory networks scaling to 120b parameters with superior long-context learning.arXiv preprint arXiv:2508.18756, 2025
-
[13]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE, 2018. 10
2018
-
[14]
Unleashing the potential of sparse attention on long-term behaviors for ctr prediction
Weijiang Lai, Beihong Jin, Di Zhang, Siru Chen, Jiongyan Zhang, Yuhang Gou, Jian Dong, and Xingxing Wang. Unleashing the potential of sparse attention on long-term behaviors for ctr prediction. InProceedings of the ACM Web Conference 2026, pages 8041–8050, 2026
2026
-
[15]
Jingyu Li, Zhaocheng Du, Qianhui Zhu, Zhicheng Zhang, Song-Li Wu, Chaolang Li, Pengwen Dai, et al. Collectivekv: Decoupling and sharing collaborative information in sequential recommendation.arXiv preprint arXiv:2601.19178, 2026
-
[16]
Chengkai Liu, Jianghao Lin, Jianling Wang, Hanzhou Liu, and James Caverlee. Mamba4rec: Towards efficient sequential recommendation with selective state space models.arXiv preprint arXiv:2403.03900, 2024
-
[17]
Peng Liu, Nian Wang, Cong Xu, Ming Zhao, Bin Wang, and Yi Ren. Dynamic user interest augmen- tation via stream clustering and memory networks in large-scale recommender systems.arXiv preprint arXiv:2405.13238, 2024
-
[18]
Large memory network for recommendation
Hui Lu, Zheng Chai, Yuchao Zheng, Zhe Chen, Deping Xie, Peng Xu, Xun Zhou, and Di Wu. Large memory network for recommendation. InCompanion Proceedings of the ACM on Web Conference 2025, pages 1162–1166, 2025
2025
-
[19]
Blossomrec: Block-level fused sparse attention mechanism for sequential recommendations
Mengyang Ma, Xiaopeng Li, Wanyu Wang, Zhaocheng Du, Jingtong Gao, Pengyue Jia, Yuyang Ye, Yiqi Wang, Yunpeng Weng, Weihong Luo, et al. Blossomrec: Block-level fused sparse attention mechanism for sequential recommendations. InProceedings of the ACM Web Conference 2026, pages 6389–6399, 2026
2026
-
[20]
Practice on long sequential user behavior modeling for click-through rate prediction
Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. Practice on long sequential user behavior modeling for click-through rate prediction. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2671–2679, 2019
2019
-
[21]
Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management, pages 2685–2692, 2020
2020
-
[22]
Yifan Pu, Jixuan Ying, Qixiu Li, Tianzhu Ye, Dongchen Han, Xiaochen Wang, Ziyi Wang, Xinyu Shao, Gao Huang, and Xiu Li. Linear differential vision transformer: Learning visual contrasts via pairwise differentials.arXiv preprint arXiv:2511.00833, 2025
-
[23]
Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36: 74530–74543, 2023
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36: 74530–74543, 2023
2023
-
[24]
Shikang Wu, Hui Lu, Jinqiu Jin, Zheng Chai, Shiyong Hong, Junjie Zhang, Shanlei Mu, Kaiyuan Ma, Tianyi Liu, Yuchao Zheng, et al. Msn: A memory-based sparse activation scaling framework for large-scale industrial recommendation.arXiv preprint arXiv:2602.07526, 2026
-
[25]
Lei Xin, Yuhao Zheng, Ke Cheng, Changjiang Jiang, Zifan Zhang, and Fanhu Zeng. Hytrec: A hybrid temporal-aware attention architecture for long behavior sequential recommendation.arXiv preprint arXiv:2602.18283, 2026
-
[26]
Ruochen Yang, Yueyang Liu, Zijie Zhuang, Changxin Lao, Yuhui Zhang, Jiangxia Cao, Jia Xu, Xiang Chen, Haoke Xiao, Xiangyu Wu, et al. Sarm: Llm-augmented semantic anchor for end-to-end live-streaming ranking.arXiv preprint arXiv:2602.09401, 2026
-
[27]
Yufei Ye, Wei Guo, Hao Wang, Luankang Zhang, Heng Chang, Hong Zhu, Yuyang Ye, Yong Liu, Defu Lian, and Enhong Chen. Fuxi-linear: Unleashing the power of linear attention in long-term time-aware sequential recommendation.arXiv preprint arXiv:2602.23671, 2026
-
[28]
Hisac: Hierarchical sparse activation compression for ultra-long sequence modeling in recommenders
Kun Yuan, Junyu Bi, Daixuan Cheng, Changfa Wu, Shuwen Xiao, Binbin Cao, Jian Wu, and Yuning Jiang. Hisac: Hierarchical sparse activation compression for ultra-long sequence modeling in recommenders. arXiv preprint arXiv:2602.21009, 2026
-
[29]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Be- ichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Deep interest network for click-through rate prediction
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1059–1068, 2018
2018
-
[32]
Deep interest evolution network for click-through rate prediction
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 5941–5948, 2019
2019
-
[33]
Yu Zhou, Chengcheng Guo, Kuo Cai, Ji Liu, Qiang Luo, Ruiming Tang, Han Li, Kun Gai, and Guorui Zhou. Gems: Breaking the long-sequence barrier in generative recommendation with a multi-stream decoder.arXiv preprint arXiv:2602.13631, 2026
-
[34]
Rankmixer: Scaling up ranking models in industrial recommenders
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6309–6316, 2025
2025
-
[35]
Mgstdn: Multi- granularity spatial-temporal diffusion network for next poi recommendation
Zhuang Zhuang, Haitao Yuan, Shanshan Feng, Heng Qi, Yanming Shen, and Baocai Yin. Mgstdn: Multi- granularity spatial-temporal diffusion network for next poi recommendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 4560–4570, 2025
2025
-
[36]
Think2go: Generative next poi recommendation with llm reasoning
Zhuang Zhuang, Shanshan Feng, Hangwei Qian, Mingqi Yang, Heng Qi, Yanming Shen, and Baocai Yin. Think2go: Generative next poi recommendation with llm reasoning. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2112–2123, 2026. 12 A Theoretical Analysis of Semantic State Sink We provide a simplified deriva...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.